






1. 项目背景与目标
背景:B站热榜反映当下最受关注的内容趋势,通过分析热榜数据可挖掘:
-
用户内容偏好
-
热门视频特征规律
-
UP的信息
目标:
✅ 实时获取热榜TOP100数据
✅ 构建可视化看板
✅ 进行数据分析
2. 技术栈与工具
| 技术环节 | 工具/库 | 版本要求 |
|---|---|---|
| 数据爬取 | DrissionPage | ≥4.0.0 |
| 数据存储 | CSV | - |
| 可视化分析 | Power BI Desktop | ≥2023 |
| 开发环境 | Python 3.10 + VSCode | - |
3. 数据爬取实现
3.1 核心代码片段
from DrissionPage import ChromiumPage
from time import sleep
import csv
import datetime
# 实例化浏览器对象
dp = ChromiumPage()
# 监听数据包
dp.listen.start('x/web-interface/popular?')
# 访问网站
dp.get('https://www.bilibili.com/v/popular/all?spm_id_from=333.1007.0.0')
# 滚动到页面底部
dp.scroll.to_bottom()
# dp.scroll.to_location(x=1,y=10000000)
# 等待页面加载新内容
sleep(1)
# 尝试获取响应数据
resp = dp.listen.wait(timeout=5)
json_data = resp.response.body
# pprint.pprint(json_data)
content = json_data['data']['list']
new_data_found = False
for index in content:
dit = {
'博主': index['owner']['name'],
}
csv_writer.writerow(dit)
print(dit)
processed_titles.add(title)技术要点:
-
使用
scroll.down()模拟人工滚动 -
随机等待时间规避反爬
-
通过
listen监听
4. 数据清洗与 Power BI 开始
本节将详细演示如何将原始爬虫数据转化为可用于分析的结构化数据,并重点说明 Power BI 的清洗技巧
4.1 数据清洗全流程
原始数据痛点
-
字段缺失(如城市信息为空)
-
Unix 时间戳可读性差
清洗步骤分解
-
加载数据到 Power B
-
处理缺失
-
时间格式化(Unix → 标准时间)
4.2 看板效果图
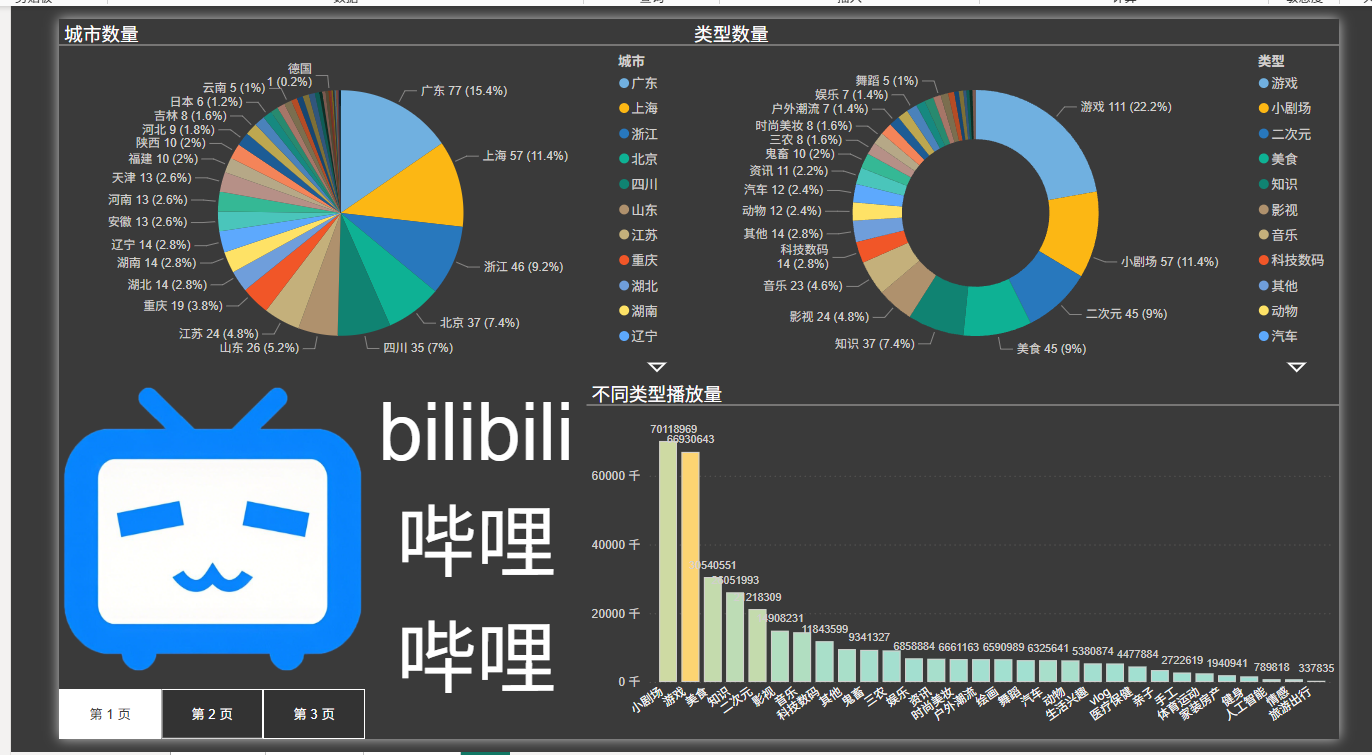
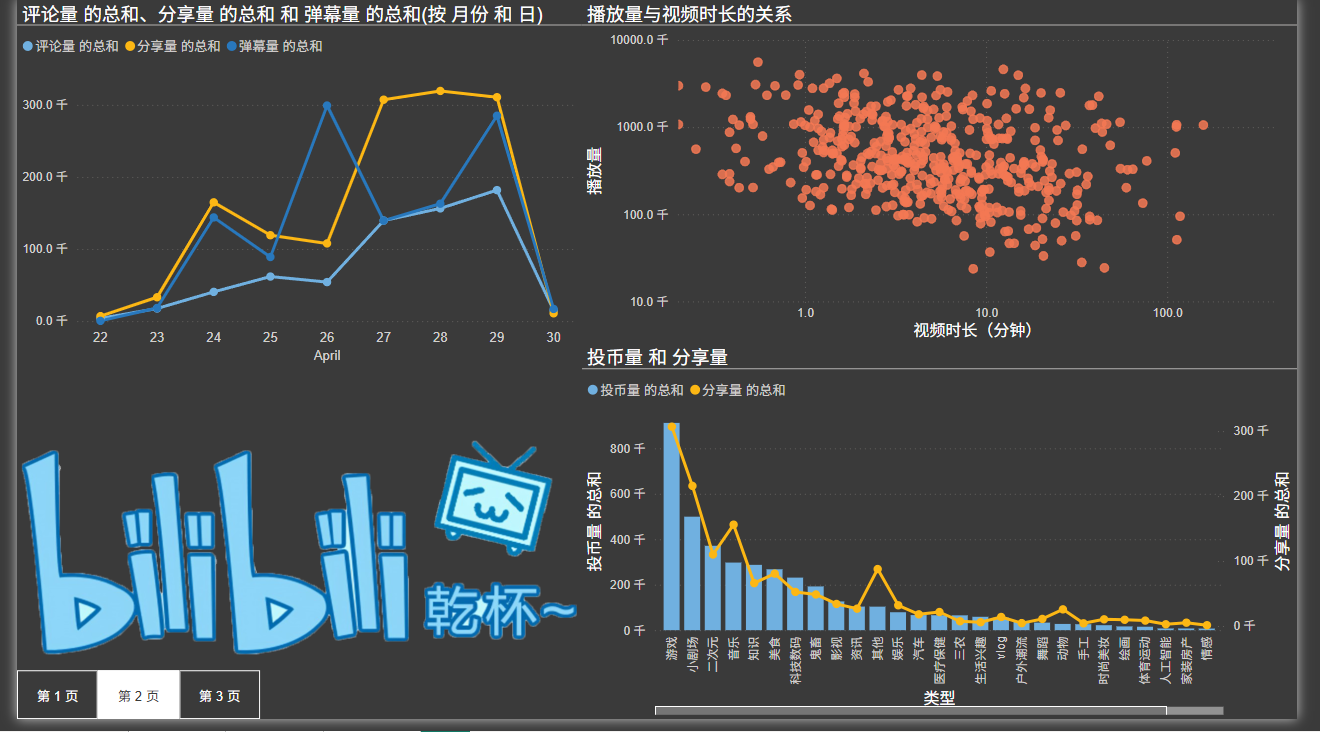

5. 项目总结与优化
5.1 分析结论
- 城市分布:广东、上海、北京、浙江等城市在 bilibili 平台相关数据表现突出,可能是重点市场。
- 视频类型热度:游戏、小剧场、知识等类型播放量较高,是热门视频类型。
5.2 优化方向
- 内容创作:依据热门城市与视频类型,创作者可针对性生产内容,如面向广东、上海等城市受众,制作游戏、知识类视频。
- 平台运营:利用数据分析工具,对热门视频的标题进行深入挖掘,提炼高播放量标题的共性特征,为创作者提供参考;同时加强对热门类型视频的推广资源倾斜。
6. 注意事项
-
法律合规
-
遵守
robots.txt协议(B站robots文件) -
单IP请求频率≤20次/分钟
-
-
反爬策略
-
使用代理IP池轮换
-
禁用浏览器自动化特征
-



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









