







一、前言
机器翻译是人工智能领域的重要研究方向,旨在将文本从一种语言自动翻译成另一种语言。利用深度学习技术中的编码器-解码器架构和注意力机制,可以显著提高翻译的准确性。本文将详细介绍这些原理,并展示如何实现一个机器翻译模型。
二、原理介绍
1.编码器-解码器架构
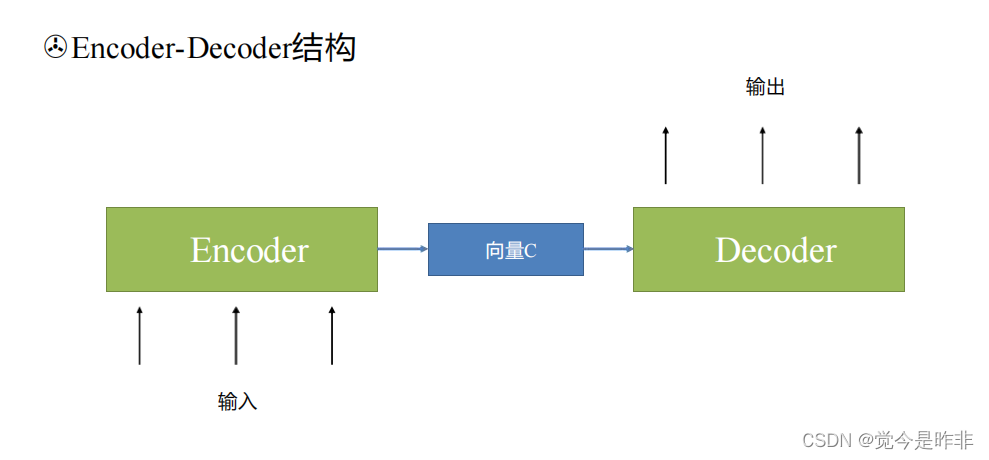
编码器-解码器架构(Encoder-Decoder Architecture)是一种常用于序列到序列(Sequence-to-Sequence)任务的神经网络结构。该架构包括两个主要部分:编码器(Encoder)和解码器(Decoder)。
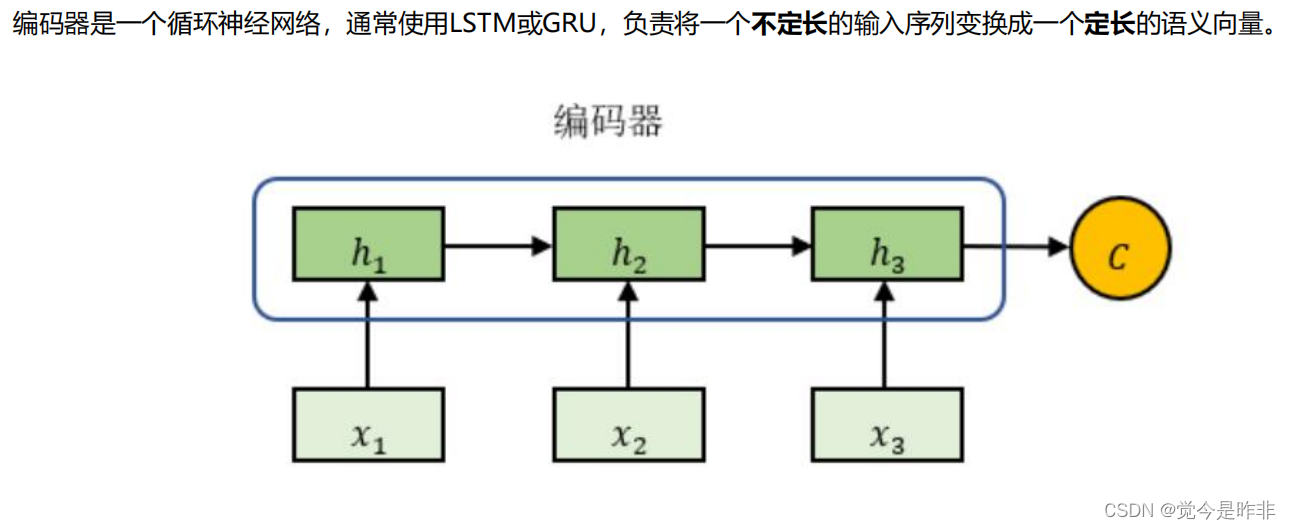
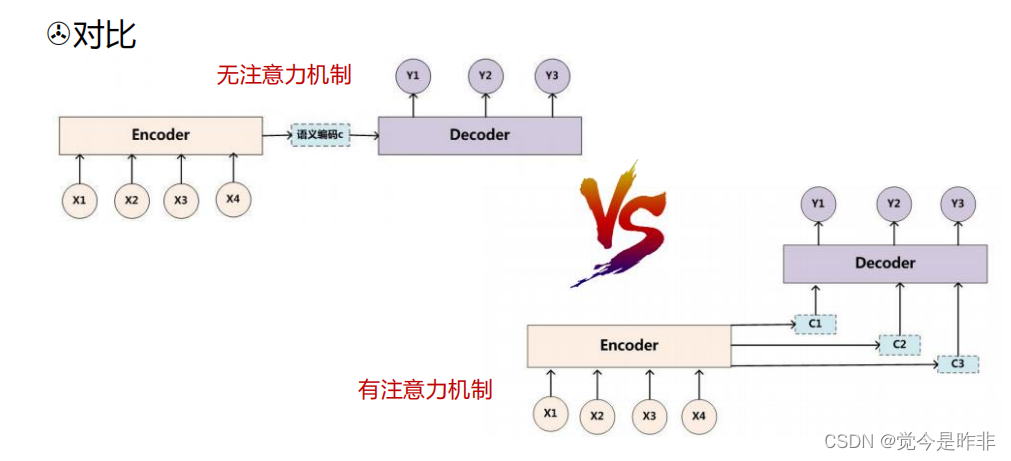
编码器:编码器将输入序列(例如法语句子)转换为一个固定长度的上下文向量(Context Vector)。这个上下文向量包含输入序列中的所有信息。
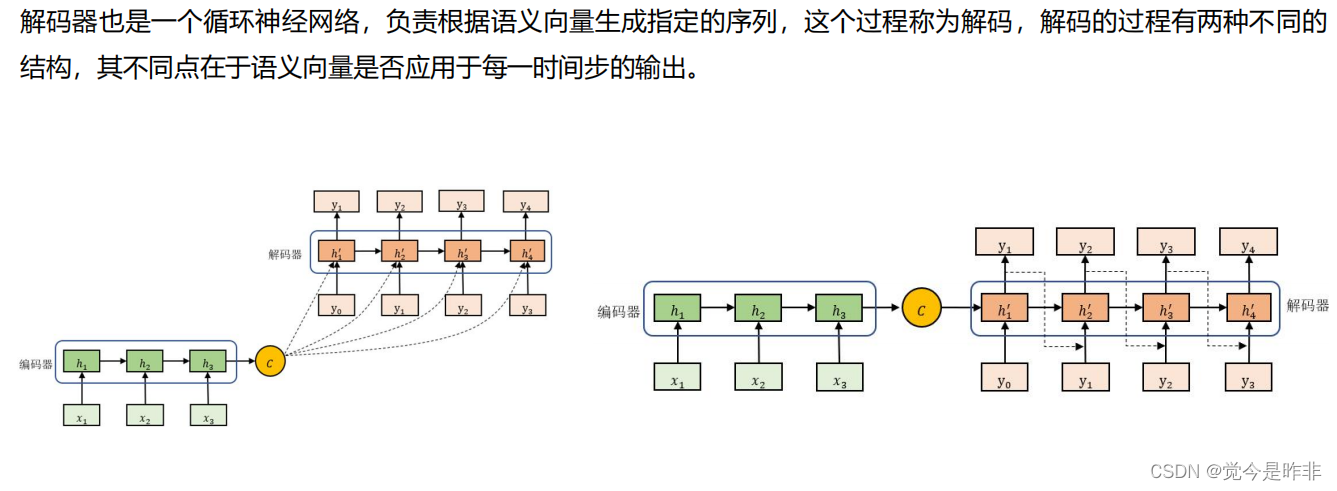
解码器:解码器从这个上下文向量生成输出序列(例如英语句子)。解码器是一个根据上下文向量逐步生成翻译结果的神经网络。
编码器和解码器通常使用循环神经网络(RNN),如LSTM或GRU。
2.注意力机制
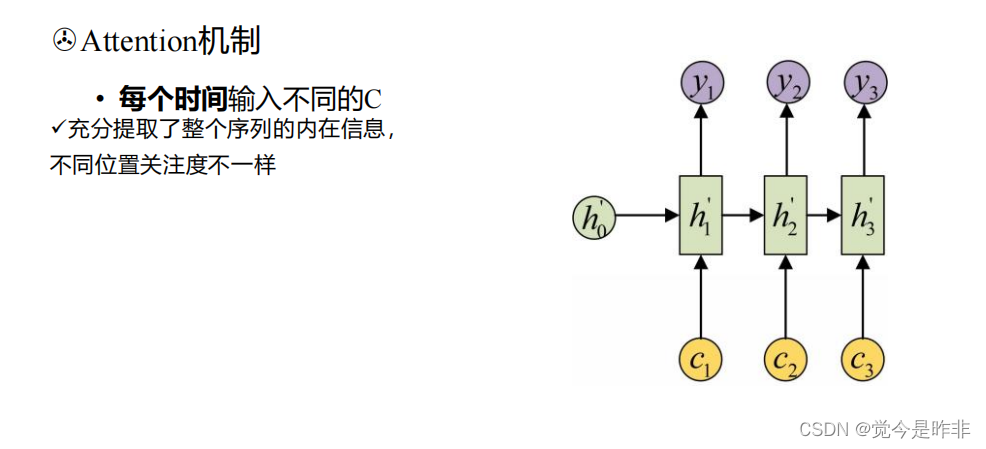
注意力机制(Attention Mechanism)是对编码器-解码器模型的改进。简单的编码器-解码器模型使用一个固定的上下文向量来表示整个输入序列,这对于长序列可能会丢失信息。注意力机制允许解码器在生成每个输出词时,动态地关注输入序列的不同部分。
具体来说,注意力机制包括以下几步:
- 计算注意力权重:对于解码器的每个时间步,计算解码器当前隐藏状态和编码器所有时间步隐藏状态之间的相似性,得到注意力权重。
- 计算背景向量:将注意力权重应用到编码器的隐藏状态上,得到背景向量。背景向量是编码器隐藏状态的加权和。
- 生成当前时间步的输出:将解码器当前时间步的隐藏状态和背景向量结合,生成当前时间步的输出。
这种机制使模型能够在生成每个输出词时,自适应地选择输入序列中最相关的信息。
3.BLEU
评价机器翻译结果通常使用BLEU(Bilingual Evaluation Understudy)[1]。对于模型预测序列中任意的子序列,BLEU考察这个子序列是否出现在标签序列中。
具体来说,设词数为𝑛𝑛的子序列的精度为𝑝𝑛𝑝𝑛。它是预测序列与标签序列匹配词数为𝑛𝑛的子序列的数量与预测序列中词数为𝑛𝑛的子序列的数量之比。举个例子,假设标签序列为𝐴𝐴、𝐵𝐵、𝐶𝐶、𝐷𝐷、𝐸𝐸、𝐹𝐹,预测序列为𝐴𝐴、𝐵𝐵、𝐵𝐵、𝐶𝐶、𝐷𝐷,那么𝑝1=4/5,𝑝2=3/4,𝑝3=1/3,𝑝4=0𝑝1=4/5,𝑝2=3/4,𝑝3=1/3,𝑝4=0。设𝑙𝑒𝑛label𝑙𝑒𝑛label和𝑙𝑒𝑛pred𝑙𝑒𝑛pred分别为标签序列和预测序列的词数,那么,BLEU的定义为
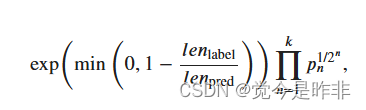
其中𝑘𝑘是我们希望匹配的子序列的最大词数。可以看到当预测序列和标签序列完全一致时,BLEU为1。
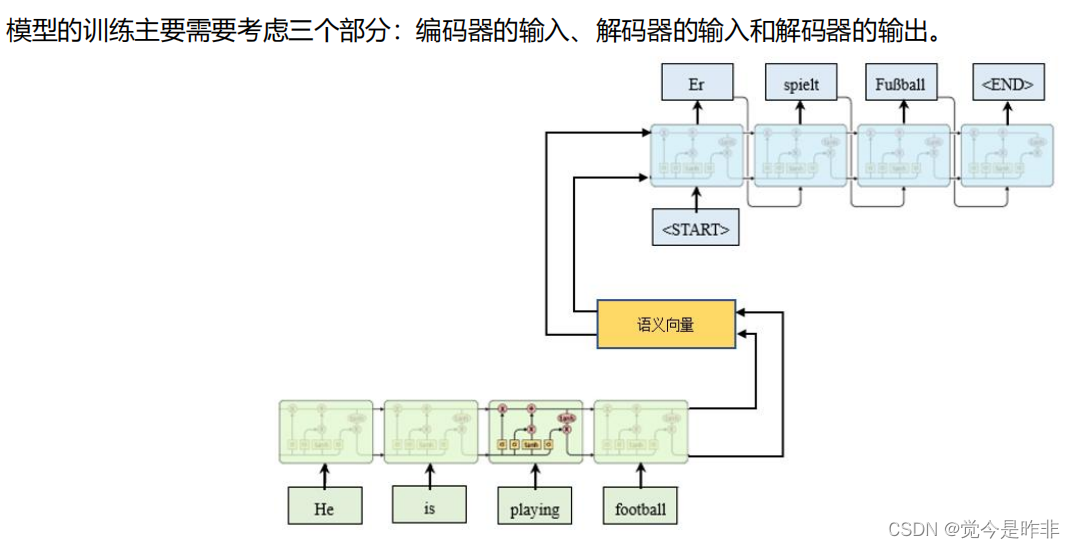
三、过程实现
1.读取和预处理数据
1.1 首先,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









