







原始数据集文件结构如下:
-
设置文件夹路径
# 设置要遍历的文件夹路径 folder_paths = ['nodule_malignancy_db\\test_set\\benign', 'nodule_malignancy_db\\test_set\\malignant', 'nodule_malignancy_db\\train_set\\benign', 'nodule_malignancy_db\\train_set\\malignant'] -
定义一个空的DataFrame用于保存特征、创建特征提取器
features_dfs = pd.DataFrame() # 用于最后保存特征为csv文件 extractor = featureextractor.RadiomicsFeatureExtractor() -
遍历文件夹中的所有文件,并将特征合并到 features_dfs 中
for folder_path in folder_paths: if folder_path.endswith('malignant'): label = 1 else: label = 0 # 遍历文件夹中的所有文件 for filename in os.listdir(folder_path): # 判断是否为raw文件 if filename.endswith('raw.npy'): # 构造掩码文件的路径 mask_filename = filename[:-7] + 'mask.npy' mask_filepath = os.path.join(folder_path, mask_filename) # 构造raw文件的路径 raw_filepath = os.path.join(folder_path, filename) # 加载raw文件和mask文件 raw_array = np.load(raw_filepath) mask_array = np.load(mask_filepath) # 转换为 SimpleITK.Image类型的数据 inputImage = sitk.GetImageFromArray(raw_array) maskImage = sitk.GetImageFromArray(mask_array) # 提取影像组学特征 features = extractor.execute(inputImage, maskImage) # 将特征转化为DataFrame # 将字典转换为Series features_series = pd.Series(features) # 将Series转换为DataFrame features_df = pd.DataFrame(features_series, columns=['value']).transpose() # 在第一列加上文件名称,最后一列加上分类 benign-0,malignant-1 features_df.insert(0, 'file_name',filename) features_df['label'] = label # 合并到总df中 features_dfs = features_dfs.append(features_df) -
保存特征为 csv 文件
features_dfs.to_csv('feature.csv')
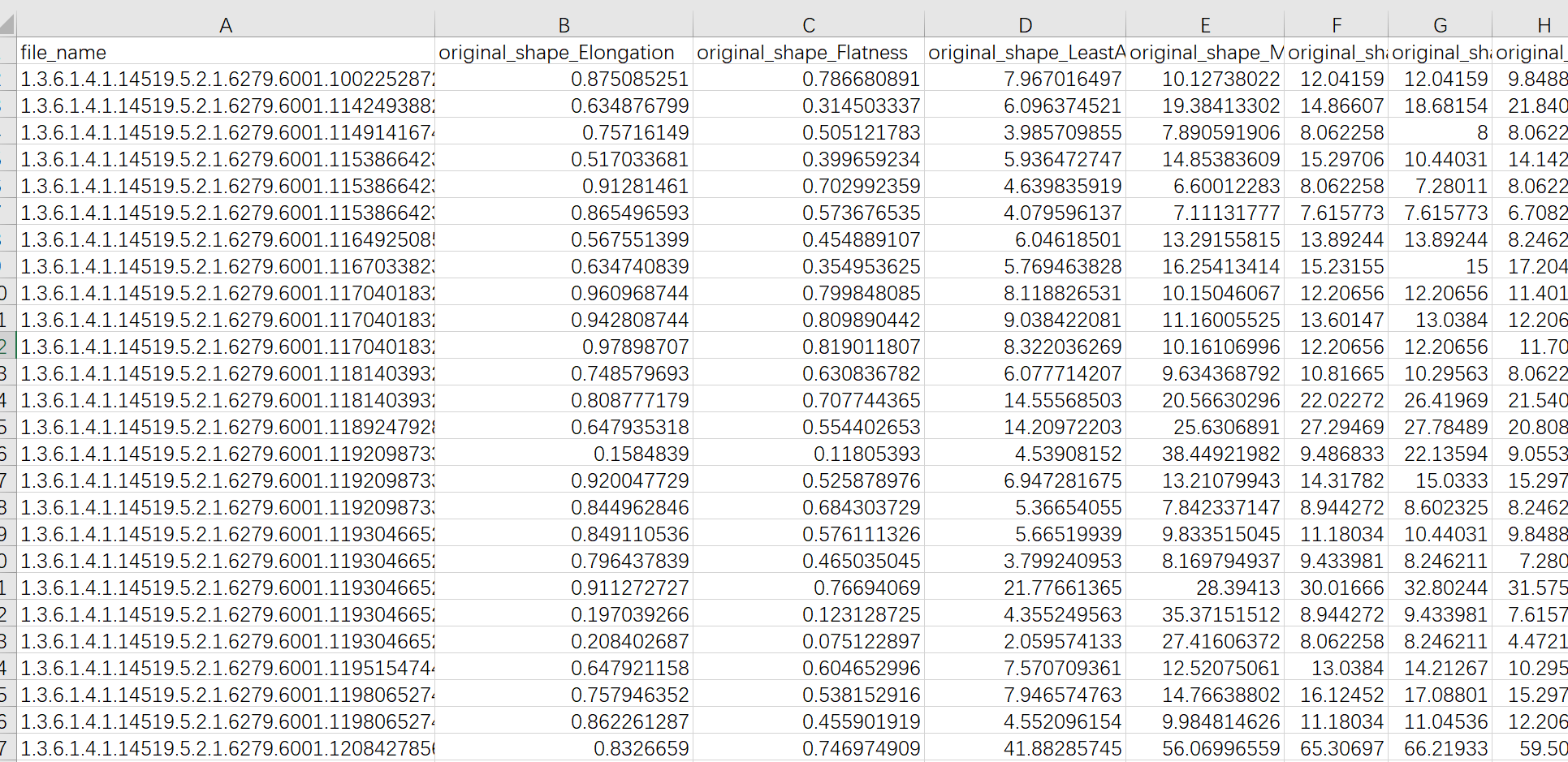
删除不需要的列,部分数据如下:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









