






数据结构
第1章 绪论
什么是数据结构
数据结构的定义
数据:描述客观事物的数和字符的集合。
数据项:具有独立含义的数据最小单位,也称为字段或域。
数据对象:性质相同的数据元素的集合,它是数据的一个子集。
数据结构:所有数据元素以及数据元素之间的关系,可以看作相互之间存在着某种特定关系的数据元素的集合。
逻辑结构
数据的逻辑结构:由数据元素之间的逻辑关系构成。
存储结构
数据的存储结构:数据结构及其关系在计算及储存其中的存储表示,也称为数据的物理结构。
数据运算
数据的运算:施加在该数据上的操作。
数据类型与抽象数据类型
抽象数据类型实质上就是对一个求解问题的形式化描述(与计算机无关),程序员可以在理解基础上实现它。
算法及其描述
什么是算法
算法是对特定问题求解步骤的一种描述,它是指令的有限序列。
算法的五个重要的特性:
(1)有穷性:在有穷步之后结束,算法能够停机。
(2)确定性:无二义性。
(3)可行性:可通过基本运算有限次执行来实现,也就是算法中每一个动作能够被机械地执行。
(4)输入:0个或多个输入
(5)输出:1个或多个输出 表示存在数据处理
算法和程序的区别
程序是指使用某种计算机语言对一个算法的具体实现,既具体要怎么做。(不一定满足有穷性)
算法侧重于对解决问题的方法描述,既要做什么。(一定满足有穷性)
算法用计算机语言描述——程序
算法的描述
输入——算法——输出
算法描述的一般格式:
返回值 算法对应的函数名(形参列表)
{ //临时变量的定义
//实现由输入参数到输出参数的操作
...
}
返回值:通常为bool类型,表示算法是否成功执行。
形参列表:由输入型参数和输出型参数构成。
第2章 线性表
线性表及其逻辑结构
1.线性表的九个基本结构
InitList(&L):初始化线性表,构造一个空的线性表L;
DestroyList(&L):销毁线性表,释放为线性表L分配的内存空间;
ListEmpty(L):判断线性表是否为空表,若L为空表,则返回真,否则返回假;
ListLength(L):求线性表的长度,返回L中元素的个数;
DispList(L:输出线性表,当线性表L不为空时顺序输出L中各元素值;
GetElem(L,i,&e):按序号求线性表中元素,用e返回L中第i(1<=i<=n)个元素;
LocateElem(L,e)按元素值查找,返回L中第一个值为e相等的元素序号;
ListInsert(&L,i,e):插入元素,在L的第i(1<=i<=n+1)个位置插入一个新元素i;
ListDelete(&L,i,&e)删除元素,删除L的第i(1<=i<=n)个元素,并用e返回该元素值。
2.顺序表的基本运算算法
//声明
typedef struct
{
ElemTyp data[MaxSize];
int length;
}SqList;
//(1)初始化线性表:InitList(&L)
viod InitList(Sqlist * &L)
{ L=(Sqlist *)malloc(sizeof(Sqlist)); //分配存放线性表的空间
L->length=0; //置空线性表的长度为0
}
// (2)销毁线性表:DestroyList(&L)
viod DestroyList(Sqlist * &L)
{
free(L); //释放L所指的顺序表空间
}
//(3)判断线性表是否为空表:ListEmpty(L)
bool ListEmpty(Sqlist * L)
{
return (L->length=0);
}
// (4)求线性表的长度:ListLength(L)
viod ListLength(Sqlist * L)
{
return (L->length);
}
//(5)输出线性表:DispList(L)
viod Displist(Sqlist * L)
{
for(int i=0,i<L->length,i++) //扫描顺序表输出各元素值
printf("%d",L->data[i]);
printf("\n");
}
//(6)按序号求顺序表中的元素:GetElem(L,i,&e)
bool GetElem(Sqlist * L,int i, ElemType &e)
{
if(i<1 || i>L->length)
return false; //参数i错误时返回false
e=L->data[i-1]; //取元素值
return true; //成功找到元素时返回true
}
//(7)按元素值查找:LocateElem(L,e)
int LocateElem(Sqlist * L,ElemType e)
{
int i=0;
while(i<L->length && L->data[i]!=e)
i++; //查找元素e
if(i>=L->length) //未找到时返回0
return 0;
else
return i+1; //找到后返回器逻辑序号
}
//(8)插入元素数据:ListInsert(&L,i,e)
bool ListInsert(Sqlist * &L, int i,ElemType e)
{
int j;
if(i<1 || i>L->length+1 || L->length==Maxsize)
return false; //参数i错误时返回false
i--; //将顺序表的逻辑序号化为物理序号
for(j=length;j>i;j--) //将data[i]及后面的元素后移一个位置
L->data[j]=L->data[j-1];
L->data[i]=e; //插入元素e
L->length++; //顺序表的长度增1
return true; //成功插入返回true
}
// (9)删除数据元素:ListDelete:(&L,i,&e)
bool ListDelete(Sqlist * &L,int i ,ElemType &e)
{
int j;
if(i<1 || i>L->length) //参数i错误时返回false
return false;
i--; //将顺序表的逻辑序号化为物理序号
e=L->data[i];
for(j=i;j<L->length-1;j++) //将data[i]之后的元素前移一个位置
L->data[j]=L->data[j+1];
L->length--; //顺序表的长度减1
return true; //成功删除返回true
}
- 线性表的基本运算在单链表中的实现
//LinkNode类型声明如下:
typedef struct LNode
{
ElemType data;
struct LNode * next;
}LinkNode;
//(1)初始化线性表:InitList(&L)
void InitList(LinkNode * &L)
{
L=(LinkNode*)malloc(sizeo(LinkNode));
L->next=NULL; //创建头结点,将其next域置为NULL
}
//(2)销毁线性表:DestroyList
void DestroyList(LinkNode * &L)
{
LinkNode * pre=L, * p=l->next; //pre指向结点p的前驱结点
while (p!=NULL) //遍历单链表L
{ free(pre); //释放pre结点
pre=p; //pre、p同步后移一个结点
p=pre->next;
}
free(pre); //循环结束时p为NULL,pre指向尾结点,释放它
}
//(3)判断线性表是否为空表:ListEmpty(L)
bool ListEmpty(LinkNode * L)
{
return(L->next==NULL);
}
//(4)求线性表的长度:ListLength(L)
int ListLength(LinkNode * L)
{
int n=0;
LinkNode * p=L;
while(p->next!=NULL)
{ n++;
p=p->next;
}
return(n);
}
//(5)输出线性表:DispList(L)
viod Displist(Sqlist * L)
{
for(int i=0,i<L->length,i++) //扫描顺序表输出各元素值
printf("%d",L->data[i]);
printf("\n");
}
//(6)按序号求顺序表中的元素:GetElem(L,i,&e)
bool GetElem(Sqlist * L,int i, ElemType &e)
{
if(i<1 || i>L->length)
return false; //参数i错误时返回false
e=L->data[i-1]; //取元素值
return true; //成功找到元素时返回true
}
//(7)按元素值查找:LocateElem(L,e)
int LocateElem(Sqlist * L,ElemType e)
{
int i=0;
while(i<L->length && L->data[i]!=e)
i++; //查找元素e
if(i>=L->length) //未找到时返回0
return 0;
else
return i+1; //找到后返回器逻辑序号
}
//(8)插入元素数据:ListInsert(&L,i,e)
bool ListInsert(Sqlist * &L, int i,ElemType e)
{
int j;
if(i<1 || i>L->length+1 || L->length==Maxsize)
return false; //参数i错误时返回false
i--; //将顺序表的逻辑序号化为物理序号
for(j=length;j>i;j--) //将data[i]及后面的元素后移一个位置
L->data[j]=L->data[j-1];
L->data[i]=e; //插入元素e
L->length++; //顺序表的长度增1
return true; //成功插入返回true
}
// (9)删除数据元素:ListDelete:(&L,i,&e)
bool ListDelete(Sqlist * &L,int i ,ElemType &e)
{
int j;
if(i<1 || i>L->length) //参数i错误时返回false
return false;
i--; //将顺序表的逻辑序号化为物理序号
e=L->data[i];
for(j=i;j<L->length-1;j++) //将data[i]之后的元素前移一个位置
L->data[j]=L->data[j+1];
L->length--; //顺序表的长度减1
return true; //成功删除返回true
}
4.双链表
//DLinkNode类型声明如下:
typedef struct DNode
{
ElemType data;
struct DNode * prior;
struct DNode * next;
}DLinkNode;
(1).插入和删除结点的操作
s->next=p->next;
p->next->prior=s;
s->prior=p;
p->next=s;
(2)建立双链表
//头插法
void CreateListF(DLinkNode * &L,ElemType a[] ,int n)
{
DLinkNode *s;
L=(DLinkNode)malloc(sizeof(DLinkNode));
L->prior=L->next=NULL;
for(int i=0;i<n;i++)
{
s=(DLinkNode *)malloc(sizeof(DLinkNode));
s->data=a[i];
s->next=L->next;
if(L->next!=NULL)
L->next->prior=s;
L->next=s;
s->prior=L;
}
}
//尾插法
void CreateListR(DLinkNode * &L,ElemType a[] ,int n)
{
DLinkNode *s,*r;
L=(DLinkNode)malloc(sizeof(DLinkNode));
r=L;
for(int i=0;i<n;i++)
{
s=(DLinkNode *)malloc(sizeof(DLinkNode));
s->data=a[i];
r->next=s;
s->prior=r;
r=s;
}
r->next=NULL;
}
第3章 栈和队列
1.栈的六个基本运算
InitStack(&s):初始化栈,构造一个空栈s;
DestroyStack(&s):销毁栈,释放为栈s分配的存储空间;
StackEmpty(s):判断栈是否为空表,若栈s为空表,则返回真,否则返回假;
Push(&s,e):进栈,将元素e插入栈s中作为栈顶元素;
Pop(&s,&e):出栈,从栈s中删除栈顶元素,并将其值赋给e;
GetTop(s,&e):取栈顶元素,返回当前的栈顶元素,并将其值赋给e。
- 栈的顺序存储结构及其基本运算的实现
// 声明顺序栈的类型SqStack:
typedef struct
{
ElemType data[Maxsize];
int top;
}SqStack;
//(1)初始化栈:InitStack(&s)
viod InitStack(SqStack * &s)
{ s=(SqStack *)malloc(sizeof(Sqstack));
s->top=-1;
}
//(2)销毁栈:DestroyStack(&s)
viod DestroyStack(SqStack * &s)
{
free(s);
}
//(3)判断栈是否为空表:StackEmpty(s)
bool StackEmpty(SqStack *s)
{
return (s->top==-1);
}
//(4)进栈:Push(&s,e)
bool Push(SqStack * &s,ElemType e)
{
if(s->top==Maxsize-1)
return false;
s->top++;
s->data[s->top]=e;
return true;
}
}
// (5)出栈:Pop(&s,&e)
bool Pop(SqStack * &s, ElemType &e)
{
if(s->top==-1)
return false;
e=s->data[s->top];
s->top--;
return true;
}
//(6)取顶栈元素:GetTop:(s,&e)
bool GetTop(Sqlist * s ,ElemType &e)
{
if(s->top==-1)
return false;
e=s->data[s->top];
return true;
}
3.栈的链式存储结构及其基本运算的实现
//声明顺序栈的类型SqStack:
typedef struct linknode
{
ElemType data;
struck linknode * next;
}LinkStNode;
//(1)初始化栈:InitStack(&s)
viod InitStack(SqStack * &s)
{ s=(LinkStNode *)malloc(sizeof(LinkStNode));
s->next=NULL;
}
//(2)销毁栈:DestroyStack(&s)
viod DestroyStack(LinkStNode * &s)
{
LinkStNode * pre=s, * p=s->next;
while(p!=NULL)
{
free(pre);
pre=p;
p=pre->next;
}
free(pre);
}
//(3)判断栈是否为空表:StackEmpty(s)
bool StackEmpty(LinkStNode * s)
{
return (s->next==NULL);
}
//(4)进栈:Push(&s,e)
bool Push(LinkStNode * &s,ElemType e)
{
LinkStNode *p;
p=(LinkStNode *)malloc(sizeof(LinkStNode));
p->data=e;
p->next=s->next;
s->next=p;
return true;
}
}
//(5)出栈:Pop(&s,&e)
bool Pop(LinkStNode * &s, ElemType &e)
{
LInkStNode *p;
if(s->next==NULL)
return false;
p=s->next;
e=p->data;
s->next=p->next;
free(p);
return true;
}
//(6)取顶栈元素:GetTop:(s,&e)
bool GetTop(LinkStNode * s ,ElemType &e)
{
if(s->next==NULL)
return false;
e=s->next->data;
return true;
}
4.队列的五个基本运算
InitQueue(&q):初始化队列,构造一个空队列q;
DestroyQueue(&q):销毁队列,释放为队列q分配的存储空间;
QueueEmpty(q):判断队列是否为空表,若队列q为空表,则返回真,否则返回假;
enQueue(&q,e):进队列,将元素e进队作为队尾元素;
deQueue(&q,&e):出队列,从队列q中出队一个元素,并将其值赋给e.
5.队列的顺序存储结构及其基本运算的实现
(1)在顺序队中实现队列的基本运算
// 声明顺序队的类型SqQueue:
typedef struct
{
ElemType data[Maxsize];
int front,rear;
}SqQueue;
//(1)初始化队列:InitQueue(&q)
viod InitQueue(SqQueue * &q)
{ q=(SqQueue *)malloc(sizeof(SqQueue));
q->front=q->rear=-1;
}
// (2)销毁队列:DestroyQueue(&q)
viod DestroyQueue(SqQueue * &q)
{
free(q);
}
//(3)判断队列是否为空表:QueueEmpty(q)
bool QueueEmpty(SqQueue *q)
{
return (q->front==q->rear);
}
// (4)进队列:enQueue(&q,e)
bool enQueue(SqQueue * &q,ElemType e)
{
if(q->rear==MaxSize-1)
return false;
q->front++;
q->data[q->rear]=e;
return true;
}
}
//(5)出队列:deQueue(&s,&e)
bool deQueue(SqQueue * &q, ElemType &e)
{
if(q->front==q->rear)
return false;
q->front++;
e=q->data[q->front];
return true;
}
(2)在环形队中实现队列的基本运算
//(1)初始化队列:InitQueue(&q)
viod InitQueue(SqQueue * &q)
{ q=(SqQueue *)malloc(sizeof(SqQueue));
q->front=q->rear=0;
}
```c
// (2)销毁队列:DestroyQueue(&q)
viod DestroyQueue(SqQueue * &q)
{
free(q);
}
// (3)判断队列是否为空表:QueueEmpty(q)
bool QueueEmpty(SqQueue *q)
{
return (q->front==q->rear);
}
// (4)进队列:enQueue(&q,e)
bool enQueue(SqQueue * &q,ElemType e)
{
if((q->rear+1)%1MaxSize==q->front)
return false;
q->rear=(q->rear+1)%1MaxSize;
q->data[q->rear]=e;
return true;
}
}
// (5)出队列:deQueue(&s,&e)
bool deQueue(SqQueue * &q, ElemType &e)
{
if(q->front==q->rear)
return false;
q->front=(q->front+1)%1MaxSize;
e=q->data[q->front];
return true;
}
6.环形队列代码
// 声明环形队列的类型QuType:
typedef struct
{
ElemType data[Maxsize];
int front;
int count;
}QuType;
//对应算法如下:
viod InitQueue(QuType * &qu)
{ qu=(QuType *)malloc(sizeof(QuType));
qu->front=0;
qu->count=0;
}
bool EnQueue(QuType * &qu,ElemType x)
{
int rear;
if( qu->count==MaxSize)
return false;
else
{
rear=(qu->front+qu->count)%MaxSize;
rear=(rear+1)%MaxSize;
qu->data[rear]=x;
qu->count++;
return true;
}
}
bool DeQueue(QuType * &qu, ElemType &e)
{
if( qu->count==0)
return false;
else
{
qu->front=(qu->front+1)%MaxSize;
rear=(rear+1)%MaxSize;
x=qu->data[qu->front];
qu->count--;
return true;
}
}
bool QueueEmpty(QuType *qu)
{
return (qu->count==0);
}
第4章 串
- 顺序串SqString
// 顺序串SqString的类型声明如下:
typedef struct
{
char data[Maxsize];
int length;
}SqString;
子串插入算法,对应算法如下:
比较两个串s和t的大小,对应算法如下:
- 链串结点LinkStrNode
// 链串结点LinkStrNode类型的声明如下:
typedef struct snode
{
char data;
struct snode * next;
}LinkStrNode;
2, Brute-Force算法
BF算法思路:从s的每一个字符开始依次与t的字符进行匹配。
过程:(1)i,j分别扫描字符串s和t;
(2)i从0到s.length-t.length循环。(每趟i保持)
3.KMP算法
KMP算法是D.E.Knuth、J.H.Morris和V.R.Pratt共同提出的,简称KMP算法。该算法较BF算法有较大改进,主要是消除了主串指针的回溯,从而使算法效率有了某种程度的提高。
KMP算法的思路:
- 基于BF算法,采用空间换时间的方式,提取保存有利于匹配的信息。
- 提取s还是t中的信息?每次从s不同字符开始匹配,而t总是从t[0]开始匹配所以只有t中的信息可以利用。
- t中的什么信息?(部分匹配信息)
//对应的KMP算法如下:
int KMPIndex(SqString s,SqString t)
{
int next[MaxSize],i=0,j=0;
GetNext(t,next);
whlie(i<s.length && j<t.length)
{
if(j==-1 || s.data[i]==t.data[j])
{
i++;
j++;
}
else j=next[j];
}
if(j>t.length)
return(i-t.length);
else
return (-1);
}
//模式串t求next值的算法如下:
void GetNext(SqString t,int next[])
{
int j,k;
j=0;k=-1;next[0]=-1;
whlie(j<t.length-1){
if(k==-1 || t.data[j]==t.data[k]){
i++;j++;
next[j]=k;
}
else k=next[k];
}
}
第5章 递归
第6章 数组和广义表
1.数组
2.稀疏矩阵
1.稀疏矩阵的三元组表示
//三元组顺序表的数据类型声明
#define M <稀疏矩阵的行数>
#define N <稀疏矩阵的列数>
#define Maxsize <稀疏矩阵中非零元素的最多个数>
typedef struct
{
int r; //行号
int c; //列号
ElemType d; //元素值
}TupNode; //三元组类型
typedef struct
{
int rows; //行数
int cols; //列数
int nums; //非零元素个数
TupNode data[MaxSize];
}TSMatrix; //三元组顺序表的类型
//1.从一个二维稀疏矩阵创建其三元组表示
void CreateMat(TSMatrix &t,ElemType A[M][N])
{ int i,j;
t.rows=M;t,cols=N;t.nums=0;
for(i=0;i<M;i++)
{ for(j=0;j<N;j++)
if(A[i][j]!=0)
{ t.data[t.nums].r=i;t.data[t.nums].c=j;
t.data[t.nums].d=A[i][j];t.nums++;
}
}
}
//2.三元组元素的赋值
bool Value(TSMatrix &t,ElemType x,int i,int j)
{ int k=0,k1;
if(i>t.rows||j>=t.cols)
return false;
while(k<t.nums && i>t.data[k].r)k++;
while(k<t.nums && i==t.data[k].r && j>t.data[k].c)
k++;
if(t.data[k].r ==i && t.data[k].c==j)
t.data[k].d=x;
else
{ for(k1=t.nums-1;k1>=k;k1--)
{ t.data[k1+1].r=t.data[k1].r;
t.data[k1+1].c=t.data[k1].c;
t.data[k1+1].d=t.data[k1].d;
}
t.data[k].r=i;
t.data[k].c=j;
t.data[k].d=x;
t.nums++;
}
return true;
}
//3.将指定位置的元素值赋给变量
bool Assign(TSMatrix t,ElemType &x,int i,int j)
{ int k=0;
if(i>t.rows||j>=t.cols)
return false;
while(k<t.nums && i>t.data[k].r)k++;
while(k<t.nums && i==t.data[k].r && j>t.data[k].c)
k++;
if(t.data[k].r==i && t.data[k].c==j)
x=t.data[k].d;
else
x=0;
return true;
}
//4.输出三元组
void DispMat(TSMatrix t)
{ int k;
if(t.nums<=0)
return ;
printf("\t%d\t%d\t%d\n",t.rows,t.cols,t.nums);
printf("\t-------------------------------\n");
for(k=0;k<t.nums;k++)
printf("\t%d\t%d\t%d\n",t.data[k].r,t.data[k].c,t.data[k].d);
}
//5.三元组元素的赋值
void TranTat(TSMatrix t,TSMatrix &tb)
{ int k,k1=0,v;
tb.rows=t.cols;
tb.cols=t.rows;
tb.nums=t.nums;
if(t.nums!=0)
{ for(v=0;v<t.cols;v++)
for(k=0;k<t.nums;k++)
if(t.data[k].c==v)
{ tb.data[k1].r=t.data[k].c;
tb.data[k1].c=t.data[k].r;
tb.data[k1].r=d.data[k].d;
k1++;
}
}
}
2.稀疏矩阵的十字链表表示
//稀疏矩阵的十字链表的结点类型MatNode
#define M <稀疏矩阵的行数>
#define N <稀疏矩阵的列数>
#define Max((M)>(N)?(M):(N)) //矩阵行、列的较大者
typedef struct mtxn
{
int row; //行号或行数
int col; //列号或列数
struct mtxn * right, * down; //行、列指针
union
{ ElemType value; //非零元素值
struct mtxn * link; //指向下一个头结点
}tag;
}MatNode; //十字链表的结点类型
//数据结点的类型声明如下:
typedef struct dnode
{ int data;
struct dnode * next;
}DType;
//集合头结点的类型声明如下:
typedef struct hnode
{ DType * next;
struct hnode * next;
}HType;
广义表
1.广义表的定义
广义表是线性表的推广,是有限元素的序列,其逻辑结构采用括号表示法表示如下:CL=(a1,a2,…,ai,…,an)
若n=0时称为空表。
//广义表的基本运算
CreateGl(s):创建广义表g,由括号表示法s创建并返回一个广义表.
DestroyGL(&g):销毁广义表,释放广义表g的存储空间.
GLLength(g):求广义表g的长度.
GLDepth(g):求广义表g的深度.
DispGL(g):输出广义表g.
2.广义表的存储结构
//广义表的结点类型GLNode,其声明如下:
typedef struct lnode
{ int tag; //结点类型标识
union
{ ElemType data; //存放原子值
struct lnode * sublist; //指向子素的指针
} val;
struct lnode * link; //指向下一个元素
}GLNode; //广义表的结点类型
3.广义表的运算
//广义表的算法设计方法 解法一
void fun1(GLNode * g)
{ GLNode * g1=g-> val.sublist;
while(g1!=NULL)
{ if(g1-> tag==1)
fun1(g1);
else
原子处理语句;
g1=g1->link;
}
}
//广义表的算法设计方法 解法二
void fun2(GLNode * g)
{ if(g!=NULL)
{ if(g-> tag==1)
fun2(g-> val.sublist);
else
原子处理语句;
fun2(g->link);
}
}
第7章树和二叉树
树的基本概念
1.树的定义
//1.形式化定义
树:T={D,R}。D是包含n个结点的有限集合(n>=0)。当n=0时为空树,否则关系R满足以下条件:
有仅有一个结点
2.树的存储结构
双亲存储结构:是一种顺序存储结构,用一组连续空间存储树的所有结点,同时在每一个结点中附设一个伪指针指示其双亲结点的位置(因为除了根结点以外,每个结点只有唯一的双亲结点,将根节点的双亲结点的位置设置为特殊值-1)
1.双亲存储结构
typedef struct
{ ElemType data; //存放结点的值
int parent; //存放双亲的位置
}PTree[MaxSize];
2.孩子链存储结构
typedef struct tnode
{ ElemType data; //结点的值
struct tnode* sons[MaxSons]; //指向孩子结点
}TSonNode;
3.孩子兄弟链存储结构
typedef struct tnode
{ ElemType data; //结点的值
struct tnode*hp; //指向兄弟
struct tnode*vp; //指向第一个孩子结点(长子)
}TSBNode;
二叉树的概念和性质
1.二叉树的定义
二叉树是有限的结点集合。这个集合或者为空,或者有一个根结点和两棵互不相交的称为左子树和右子树的二叉树组成。
二叉树的5种基本形态:空二叉树,只含根结点的二叉树,左子树为空的二叉树,右子树为空的二叉树,左右子树均为空的二叉树。
二叉树的逻辑结构:树形表达法,文氏图表达法,凹入表达法,括号表达法。
二叉树的物理结构表示法:顺序,链式。
满二叉树:在一棵二叉树中,所有分支结点都有双分支结点;并且叶结点都集中在二叉树的最下一层。
满二叉树的性质:在一棵二叉树中高度为h的二叉树恰好有2^h-1个结点。
完全二叉树:在一棵二叉树中,最多只有下面两层的结点的度数小于2,并且最下面一层的叶结点都依次排列在该层最左边的位置上。
完全二叉树实际上是对应的满二叉树删除叶结点层最右边若干个结点得到的。
2.二叉树性质
性质1:非空二叉树上叶结点数等于双分支结点数加1.即n_0=n_2
+1。
性质2:非空二叉树上第i层上至多有2^(i-1)个结点(i>=1)
性质3:高度为h二叉树至多有2^h-1个结点(h>=1)
性质4:完全二叉树性质(含n为结点):
第一,n_1=0或者n_1=1.n_1可由n的奇偶性确定;
第二,若i<=n/2,则编号为i的结点为分支结点,否则为叶结点;
第三,除树根结点外,若一个结点的编号为i,则它的双亲结点的编号为i/2。
第四,若编号为i的结点有左孩子结点,则左孩子结点的编号为2i;若编号为i的结点有右孩子结点,则右孩子结点的编号为2i+1。
3.二叉树的存储结构
//二叉树顺序存储结构的类型声明如下
typedef ElemType SqBTree[MaxSize];
SqBTree bt="ABD#C#E######F";
二叉树顺序存储结构的特点
第一:对于完全二叉树来说,其顺序存储是十分适合的。
第二:对于一般的二叉树,特别是对于那些单分支结点较多的二叉树来说是很不合适的,因为可能只有少数存储单元被利用,特别是对退化的二叉树(即每个分支结点都是单分支的),空间浪费更是惊人。
第三:在顺序存储结构中,找一个结点的双亲和孩子都很容易。
//二叉链中结点类型BTNode声明如下
typedef struct node
{ ElemType data; //数据元素
struct node * lchild; //指向左孩子结点
struct node * rchild; //指向右孩子结点
}BTNode;
二叉链存储结构的特点
第一:除了指针外,二叉树比较节省存储空间。占用的存储空间与树形没有关系,只与树中结点个数有关。
第二:在二叉链中,,找一个结点的孩子很容易,但找其双亲不方便。
4.二叉树基本运算及其实现
第一、创建二叉树createBTree(*b,*str):根据二叉树括号表示法字符串str生成对应的二叉链存储结构b。
第二、销毁二叉链存储结构DestroyBTree(b):销毁二叉链b并释放空间。
第三、查找结点FindNode(*b,x):在二叉树b中寻data域值为x的结点并返回指向该结点的指针。
第四、找孩子结点LchildNode(p)和RchildNode(p):分别求二叉树中结点p的左孩子结点和右孩子结点。
第五、求高度BTHeight(*b):求二叉树b的高度。若二叉树为空,则其高度为0;否则,其高度等于左子树与右子树中的最大高度加1。
第六、输出二叉树DispBTree(*b):以括号表示法输出一棵二叉树。
5.二叉树遍历的概念
二叉树遍历:按一定次序访问树中所有结点,并且每个结点仅被访问一次的过程。遍历是二叉树最基本的运算,是二叉树中其他运算的基础。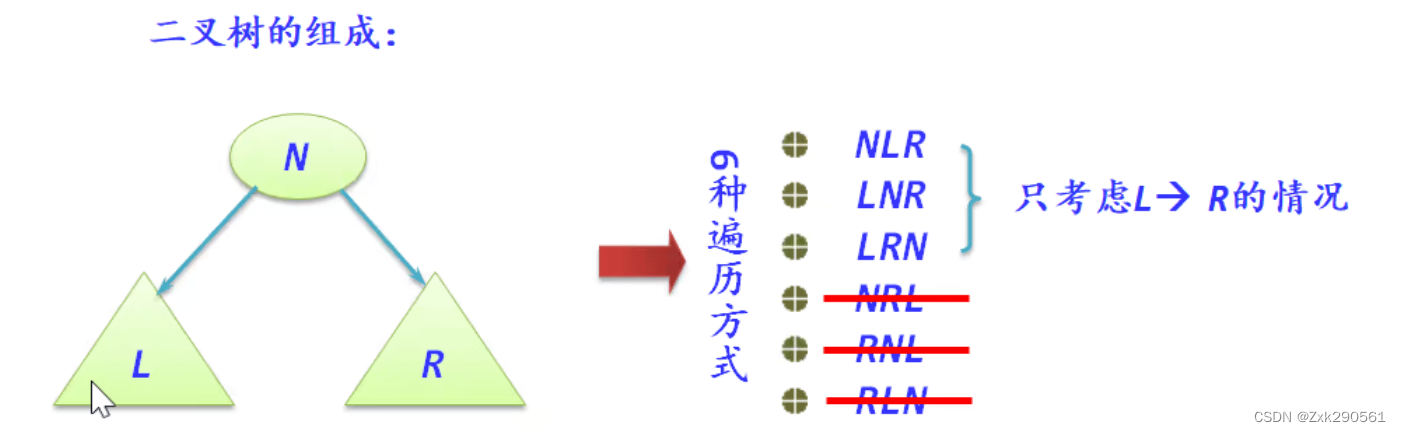
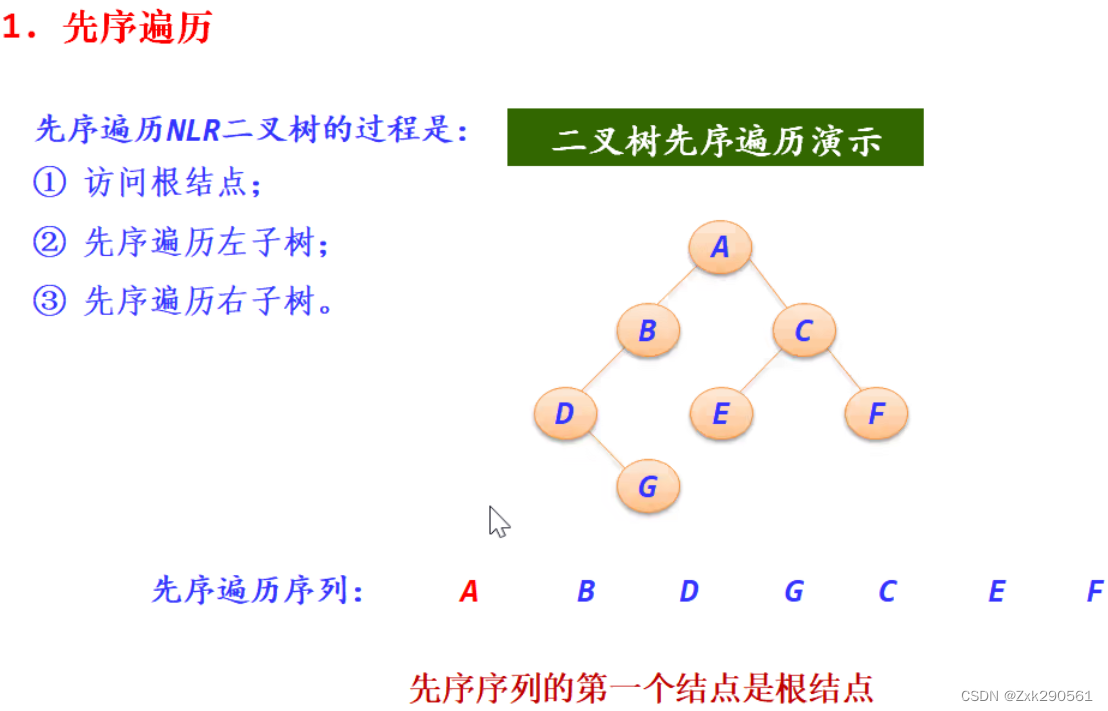
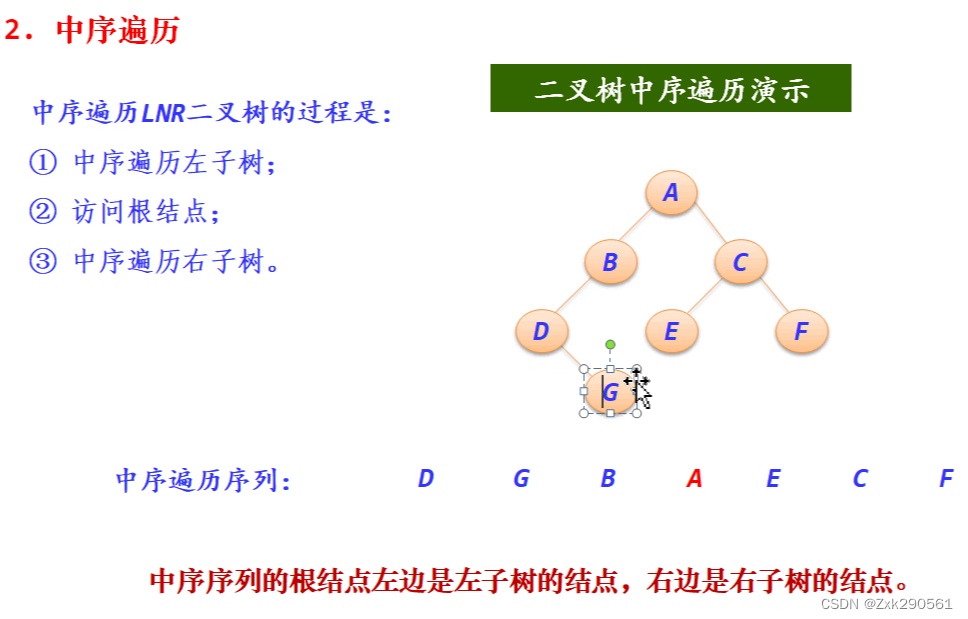
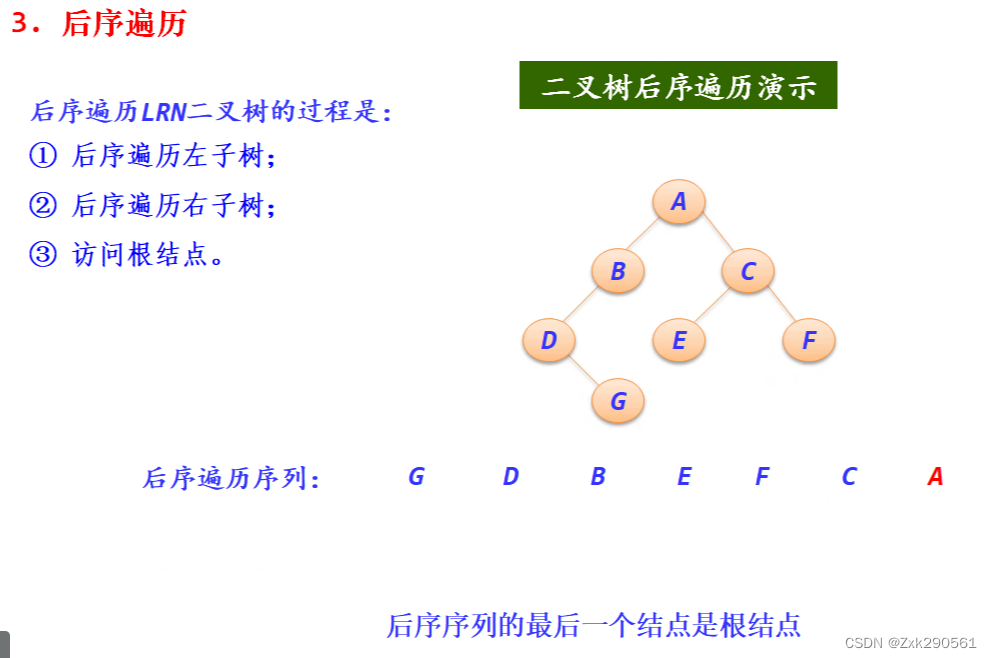
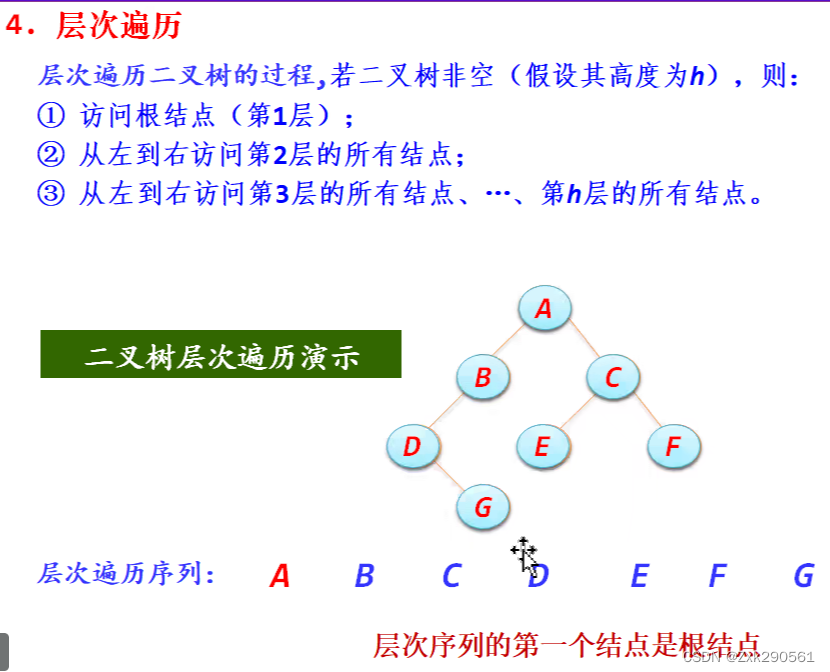
6.先序、中序、后序遍历的递归算法

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









