







承接文章Liunx系统使用超详细(四)~文件/文本相关命令1http://t.csdnimg.cn/f7G6S
目录
一、awk命令(三剑客之一)
在 Linux 中,awk 是一种强大的文本处理工具,用于从输入文件中提取和操作数据。它以行为单位读取文件,并根据指定的规则对每行进行处理。之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
和sed命令的区别:
-
功能定位:
awk(或称为gawk)是一种强大的文本处理工具,可以用于数据提取、处理和报告生成。它是一种编程语言,支持处理结构化文本,并使用列与行进行操作。sed(Stream Editor)是一种流式文本编辑工具,主要用于对文本进行替换、删除、插入和编辑操作。它根据正则表达式匹配模式来实现对文本的修改。
-
处理方式:
awk以行为单位解析文件,并按照指定的字段分隔符(默认为空格)切分每行,然后对每个字段进行处理。它通过使用变量、条件语句、循环等编程元素来进行高级文本处理。sed按行从输入流中读取文本,并对每一行应用预定义的命令,如替换、删除、插入等。它通过使用正则表达式和命令来执行基本的文本编辑操作。
-
功能举例:
awk适合处理结构化数据,例如CSV文件的解析和处理。它可以根据特定条件筛选和提取数据,并对数据执行计算和转换。还可以生成报告和统计数据。sed适合进行文本替换、删除和插入操作。它可以在文本中查找并替换特定模式,删除指定行或行范围,以及在特定位置插入新内容。
总结:
awk更适合处理结构化数据和进行复杂的文本处理,而sed则更适合进行简单的文本编辑和替换操作。
1.1工作原理
工作原理基于模式匹配和动作执行。以下是 awk 的工作原理:
-
读取输入:
awk从输入文件、标准输入或管道中逐行读取数据。 -
分割字段:默认情况下,
awk使用空格或制表符作为字段分隔符来将每一行分割成多个字段。您也可以使用-F选项指定其他自定义字段分隔符。 -
模式匹配:对于每一行,
awk会尝试将该行与预定义的模式进行匹配。模式可以是正则表达式、字符串匹配等。如果模式匹配成功,则执行相应的动作;否则,跳过该行继续处理下一行。 -
执行动作:如果模式匹配成功,则执行与之关联的动作。动作可以是打印、计算、赋值、条件判断等。您可以在动作中使用内置变量、函数和操作符进行高级处理。
-
重复处理:
awk继续读取下一行,重复以上步骤,直到所有行都被处理完毕。 -
输出结果:根据动作的要求,
awk可以在屏幕上打印输出、写入文件或进行其他自定义操作。
awk 还提供了许多内置变量和函数,以及各种选项和参数,可以帮助我们更灵活地处理文本数据。可以使用这些功能来实现复杂的文本处理任务,如计算统计信息、按条件筛选数据、转换格式等。
换个思路理解:
其实awk的工作模式就类似于游标循环,逐行进行调取,操作,输出:
1.先调取文件的第一行,存入内置变量$0中
2.使用内置的分隔符FS或管理员指定的分隔符,切割这一行,存入$1-$100中 ,只能切99次,多了都放在 $100中
3.输出时,使用内置的输出分隔符OFS或指定的分隔符输出
4.继续调取下一行,处理完一行再处理下一行
默认的FS和OFS都是空格
1.2工作流程
在进行文本处理时,按行读取输入文件,并对每一行应用模式(pattern)和操作(action)。流程如下:
awk读取一行文本。- 根据指定的分隔符(默认为空白字符),将行分割成字段。
- 执行模式匹配:如果模式匹配成功,则执行相关操作;否则,跳过该行。
- 执行操作:可以是打印、计算、字符串处理等。
- 重复以上步骤,直到所有行都被处理完毕。
1.3语法格式
--格式一、
awk 'pattern { action }' input_file
或理解为:
Awk 选项 ‘[定址][动作]’文件名
--格式二、
awk 'BEGIN { actions } pattern { actions } END { actions }' filename
或理解为:
awk 'BEGIN{动作}定址{动作}END{动作}' 文件名1.3.1格式注释:
'pattern'是一个条件模式,用于匹配要处理的行。{ action }是在满足条件模式的行上执行的操作。input_file是要处理的输入文件。
1.3.2模式(pattern)的类型:
- 正则表达式模式:使用正则表达式来匹配文本。
- 字符串匹配模式:直接匹配字符串进行比较。
- 布尔表达式模式:使用逻辑运算符(如逻辑与 &&、逻辑或 ||)构建复杂的条件判断。
1.3.3动作(action)的类型:
- 打印操作:打印整行或指定字段的内容。
- 赋值操作:将值赋给变量,用于后续计算或处理。
- 条件语句操作:根据条件执行不同的操作,如 if-else、switch 语句。
- 循环操作:用于循环处理行或执行特定操作,如 for、while 循环。
- 算术和字符串操作:对数据进行数学计算或字符串处理。
- 内置函数调用:调用内置函数进行各种操作,如字符串处理、日期时间处理等。
1.3.4选项参数:
- -F:指定输入分隔符, 默认分隔符是空格
1.4用法示例
1.4.1~1.4.7均为awk语法格式 一的示例用法
1.4.1换行打印print
print是换行打印,相当于每一行的最后自带一个换行。换行写作\n ,因为它自带换行 ,所以不需要我们写;
格式:
awk 选项 '[定址]{动作}' 文件名
#打印文件的所有行
awk '{ print }' file.txt
--比如:
--打印h全文本
awk '{ print }' h结果如下:

#打印指定字段
awk '{ print $1, $3 }' file.txt
--比如:
--打印h文本的第1和第3个字段
awk '{ print $1, $3 }' h
结果如下:
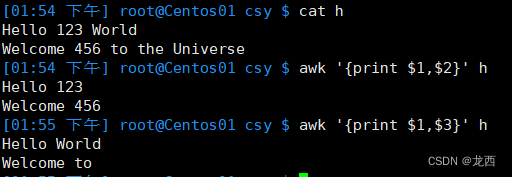
假如使用
awk '{ print $1, $3 }' h命令的结果和原文一模一样,可能是因为在文件 h 中每一行的字段(以空格或制表符分隔的部分)与$1和$3对应的字段索引相符。
#可以打印常量 数值直接写 字符加引号
--比如:
--打印文件j每一行的第一个字段、第三个字段和第五个字段,然后依次打印常量1和字符串常量"a"
awk '{print $1,$3,$5,1,"a"}' j结果如下:

#可以变量常量一起打出来 自带连接符
--比如:
--使用多个变量和常量来构造输出
awk '{print 1$1,$3"3",$5 5}' j结果如下:
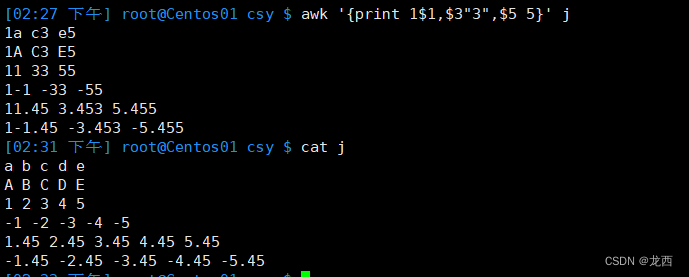
注意:
变量后连接数字要加引号或者空格
#根据上面的方式可以完成如下的要求:
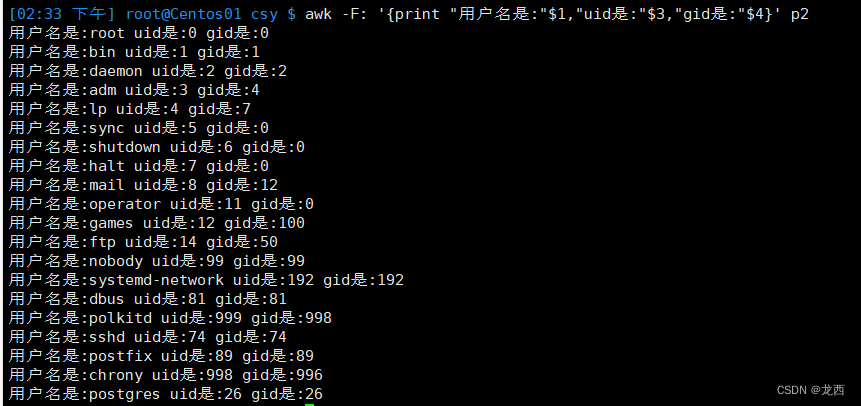
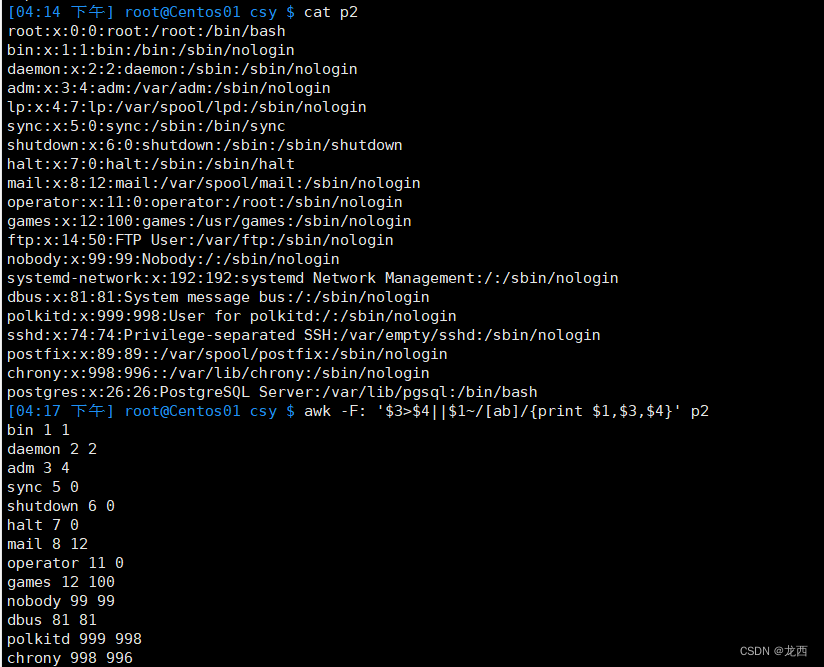
以:为分隔符 打印p2文件的用户名 uid gid
--#格式为 用户名是:xxxxxxx uid是:xxxxxxxx gid是:xxxxxxxx
awk -F: '{print "用户名是:"$1,"uid是:"$3,"gid是:"$4}' p2结果如下:
1.4.2不换行打印printf
printf是不换行打印,每一行的后面都不会自动换行,结果会直接打印成一大行,如果想要正常出结果,需要我们手动给他加上换行 \n
格式:
awk '{printf "格式[\n]",要打印的东西}'
%s 字符型 %d 整数型 字符变成0,小数直接保留整数部分,不会四舍五入 %f 浮点型 字符变成0,再补小数点后面的0,默认6位小数,会四舍五入 默认6位的情况下,字符会转成0.000000
#不换行打印j文件的1,3,5部分
--将文件j的每一行的第一个字段作为字符串,第三个字段作为整数,第五个字段作为浮点数,依次打印出来,并在最后添加换行符
awk '{printf "%s,%d,%f\n",$1,$3,$5}' j结果如下:

# %.数f 可以调整浮点型小数位数
--将文件j的每一行的第一个字段作为字符串,第三个字段作为整数,第五个字段作为保留一位小数的浮点数,依次打印出来,并在最后添加换行符
awk '{printf "%s,%d,%.1f\n",$1,$3,$5}' j%.1f代表保留一位小数的浮点数类型。
结果如下:

1.4.3输出排版调整(附加)
如何使输出分割符和格式保持一致?
即输出排版符合调整左对齐,右对齐
方法:
在%和s/d/f的之间加上一个 “数” 或者 “-数” 就可以完成排版。
其中"数"表示右对齐",“-数"表示左对齐;
数表示的是长度。
以下示例展示用法:
#对j文件按照要求进行格式对齐
awk '{printf "%-10s %-10d %-10.2f\n",$1,$3,$5 }' j-
"%-10s %-10d %-10.2f\n"是格式字符串,包含三个格式说明符:%-10s表示左对齐的字符串类型,占据10个字符的宽度。%-10d表示左对齐的整数类型,占据10个字符的宽度。%-10.2f表示左对齐的保留两位小数的浮点数类型,占据10个字符的宽度。\n代表换行符。
按照指定的格式:将文件j的每一行的第一个字段以左对齐的方式打印为字符串,第三个字段以左对齐的方式打印为整数,第五个字段以左对齐的方式打印为保留两位小数的浮点数,依次打印出来,并在最后添加换行符。每个字段占据10个字符的宽度。
#打印p2文件的用户名 uid gid 格式为用户名是:xxxxxxx uid是:xxxxxx gid是:xxxxxxx;并且排版,用户名15位 uid5位 gid五位
awk -F: '{printf "用户名是: %-15s uid是: %-5d gid是: %-5d\n",$1,$3,$4}' p2结果如下:

1.4.4使用正则
在awk中,斜杠
//用于表示模式匹配。它通常与条件语句一起使用,用于匹配和筛选输入数据。当在斜杠之间放置一个正则表达式时,它将用来匹配每一行的内容。符号注释:
^:表示匹配行的开头。例如,^abc表示以"abc"开头的行。
$:表示匹配行的结尾。例如,xyz$表示以"xyz"结尾的行。
.:表示匹配任意单个字符(除了换行符)。例如,a.c可以配"abc"、"adc"、"afc"等。
*:表示匹配前一个元素零次或多次。例如,ab*c可以匹配"ac"、"abc"、"abbc"等。
[]:用于定义字符集,表示匹配方括号中包含的任意一个字符。例如,[abc]可以匹配"a"、"b"或"c"。
.和[]在方括号内部失去其特殊含义,它们只代表普通的字符。例如,[.]匹配句点字符"."本身。
{}:用于指定匹配重复次数的范围。例如,a{2,4}表示匹配连续出现2到4次的字符"a"。注意:
在awk中使用这些符号时可能需要进行适当的转义或引用,因为它们在awk中也具有特殊的含义。
#打印p2文件包含root的行
awk '/root/{print $0}' p2结果如下:

提示:
在awk中,
$0是一个预定义变量,表示整个输入行的内容。它包含了当前行的所有字段,以分隔符(默认为空格)分隔。 通过{print $0}打印出整个输入行的内容
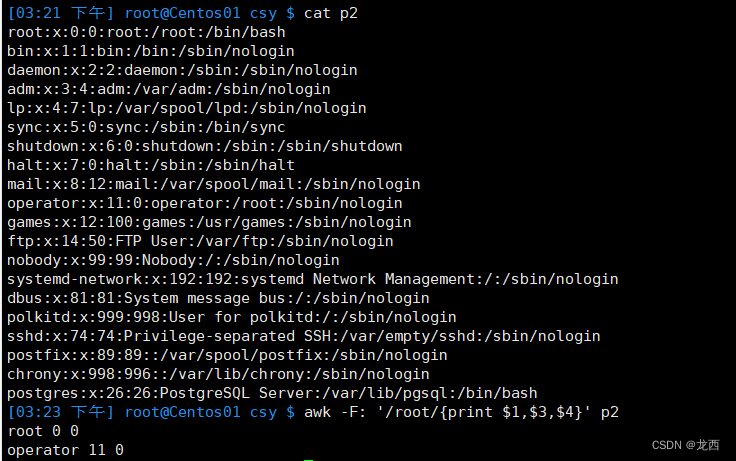
#打印包含root的行的用户名 uid gid
awk -F: '/root/{print $1,$3,$4}' p2结果如下:
#打印uid是0-9的 用户名 uid gid
awk -F: '/:x:[0-9]:/{print $1,$3,$4}' p2结果如下:

# 打印用户名是7位字母的 用户名 uid gid
awk -F: --posix '/^[a-zA-Z]{7}:x:/{print $1,$3,$4}' p2
结果如下:

提示:
在 ASCII 码表中,大写字母的编码小于小写字母的编码,所以
[a-Z]并不会匹配任何字符,要修复这个问题,需要修改为[a-zA-Z]。(这里我就触发这个问题)注意:
awk里面正则不能用{m}表示,如果需要则加上选项 --posix;在上例中我就如此使用。但是为什么呢?
原因就是:在默认情况下,awk使用的是基本正则表达式(BRE),其中不支持使用
{m}来表示重复次数。如果需要使用这种扩展的正则表达式语法,可以通过添加选项--posix来启用POSIX兼容模式。使用
--posix选项后,awk将根据POSIX标准解释正则表达式,并支持更多的语法和功能。为了更好的演示在awk中启用POSIX兼容模式的用法,下面再列举一个示例。
#创建k文件,内容如下:
apple
aaa
bananas
aaba
banana
baaa
展示:

#使用上述awk命令匹配连续出现2到4次的字母"a"的行
awk --posix '/a{2,4}/ {print}' k
结果如下:

1.4.5关系运算符
关系运算符的使用
> >= < <= != ==
~匹配正则表达式
!~不匹配正则表达式
#根据条件打印行
--比如:
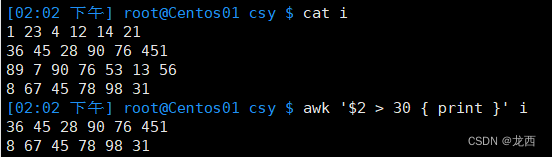
--打印文件i中第二个字段的值大于30的行
awk '$2 > 30 { print }' i结果如下:
#打印j文件第一部分是1的行
awk '$1==1{print $0}' j结果如下:

#打印p2 文件中uid 和 gid 不相等的用户名 uid gid
awk -F: '$3!=$4{print $1,$3,$4}' p2结果如下:

1.4.6逻辑运算符
常用符号:
and → &&
or → ||
not → !
() 改变优先级
#打印p2文件中uid 在 0-5 或者 10-15 的用户名 uid gid
awk -F: '$3~/^[0-5]$/||$3~/^1[0-5]$/{print $1,$3,$4}' p2
/$3~/^1[0-5]$/:表示第三个字段的值必须是两位数,以 1 开头,并且在 10 到 15 之间(包括 10 和 15)
结果如下:

#打印p2 文件uid比gid大 或者用户名包含a或者b的用户名 uid gid
awk -F: '$3>$4||$1~/[ab]/{print $1,$3,$4}' p2结果如下:
1.4.7算术运算符
+ - * /
% 取余 a%b就是a/b的余数
^ 幂运算 次方 a^2 的意思就是 a*a
seq [数1] [数2] 数3 生成序列
数1 省略默认1#初始值
数2 省略默认1#等差
数3 最大值
seq 100 #生成1-100
#打印 10以内所有偶数
seq 10| awk '$1%2==0 {print $0}'结果如下:

#打印100以内所有包含7或者能被7整除的数
seq 100 | awk '{ if ($1 ~ /7/ || $1 % 7 == 0) print $0 }'
结果如下:

#计算两个数值的和
awk '{sum = $1 + $2; print "Sum:", sum}' file.txt
结果如下:
#计算两个数值的差
awk '{diff = $1 - $2; print "Difference:", diff}' file.txt
结果如下:

#计算两个数值的乘机
awk '{product = $1 * $2; print "Product:", product}' file.txt
结果如下:

#计算两个数值的商
awk '{quotient = $1 / $2; print "Quotient:", quotient}' file.txt
结果如下:

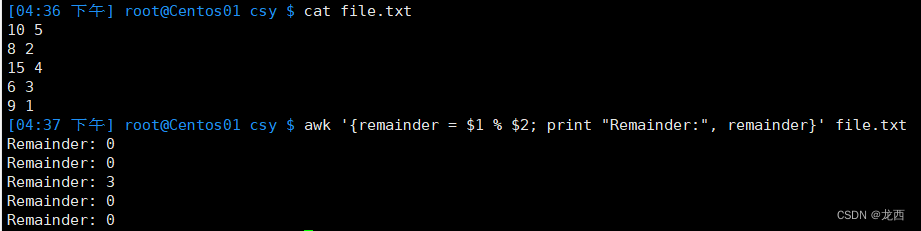
#计算两个数值的余数
awk '{remainder = $1 % $2; print "Remainder:", remainder}' file.txt
结果如下:
1.4.8格式二示例
awk 'BEGIN { actions } pattern { actions } END { actions }' filename解析格式:
语法结构由三个部分组成:
BEGIN块:在处理输入之前执行的动作。它可以用于初始化变量、打印标题等操作。pattern块:用于指定条件或模式。如果模式匹配当前输入行,则执行与该模式关联的动作。END块:在处理完所有输入后执行的动作。它可以用于计算总和、打印汇总信息等操作。在这些块中,
actions表示需要执行的具体动作,可以是赋值、打印、运算等任何有效的awk语句。awk 'BEGIN{动作}定址{动作}END{动作}' 文件名语法结构由三个部分组成:
- BEGIN{动作} 动作只执行一次,处理文件之前要做的事情,如定义分隔符和变量
- 定址{动作} 只要满足定址就去执行动作
- END{动作} 动作只执行一次,处理完文件之后要执行的动作,比如汇总数据
FS 输入分割符 ; OFS 输出分隔符
用下面示例解释:
已知文件包含内容:a,b,c/e/f,g
①如果指定分隔符为, 则得到
$1=a
$2=b
$3=c/e/f
$4=g
②如果指定分隔符为/ 则得到
$1=a,b,c
$2=e
$3=f,g
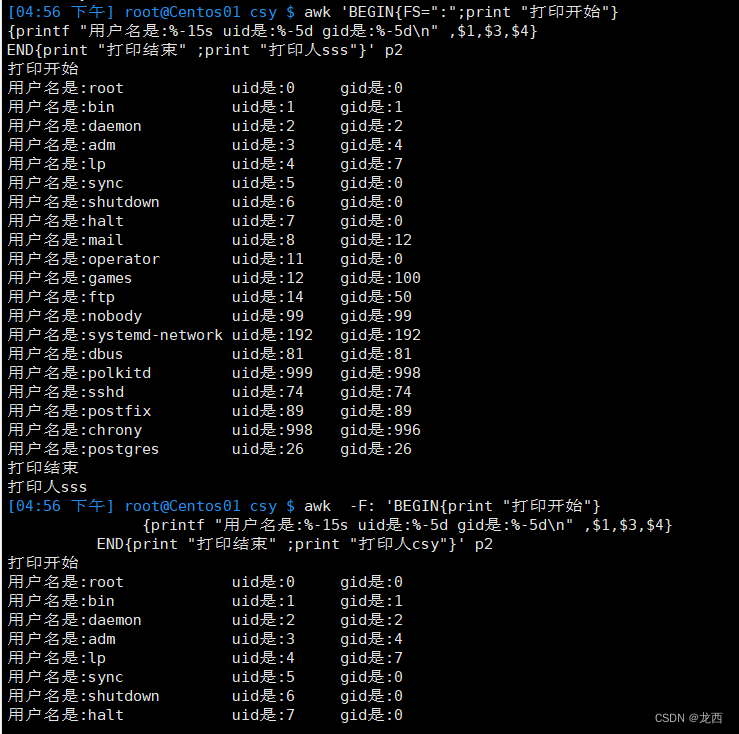
# 打印p文件的用户名,uid,gid
- 要求格式为:用户名是:... uid是:... gid是:....
- 并且排版,用户名15位 uid 5位 gid 5位;
- 打印开始,打印"打印开始",打印结束,打印"打印结束";
- 并且显示打印人。
awk 'BEGIN{FS=":";print "打印开始"}
{printf "用户名是:%-15s uid是:%-5d gid是:%-5d\n" ,$1,$3,$4}
END{print "打印结束" ;print "打印人csy"}' p2
--或者:
awk -F: 'BEGIN{print "打印开始"}
{printf "用户名是:%-15s uid是:%-5d gid是:%-5d\n" ,$1,$3,$4}
END{print "打印结束" ;print "打印人csy"}' p2结果如下:
提示:
%d是整数型 ,详情查看1.4.2中注释。
#以,为分隔符,以\t为输出分隔符,打印l文件的1,3,5部分
awk 'BEGIN{FS=",";OFS="\t"}
{print $1,$3,$5}' l结果如下:
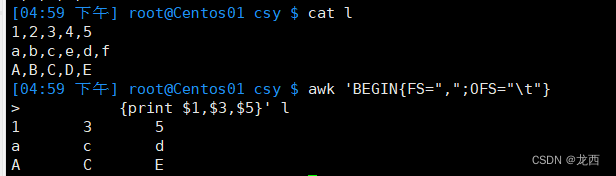
备注:
FS 输入分隔符
OFS 输出分隔符
1.4.9计算行数和列数
备注:
NR 行号
NF 列数,字段数 (部分数)
NR放在 END{}中打印,可以起到统计行数的作用。
awk 'END { print NR,NF }' file.txt
--比如:
--统计i文本的行数和列数
awk 'END { print NR,NF }' i结果如下:

#计算行数和列数,并显示文件内容
awk -F, '{print NR,NF,$0}' file.txt
--比如统计i文件的行数和列数,并展示其内容
awk -F, '{print NR,NF,$0}' i结果如下:

由于i文件内容中没有分隔符,因此会将所有数据统计为一列。
换种写法:
awk -F' ' 'END {print NR,NF}' i结果如下:

i文件以空格符为分隔符即可查询列数
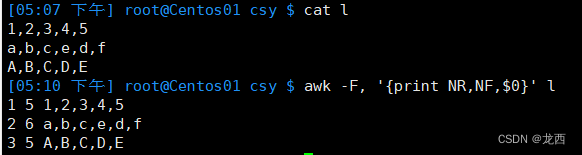
#比如统计l文件的行数和列数,并展示其内容
awk -F, '{print NR,NF,$0}' l结果如下:
#比如统计i文件的行数和列数,并展示其内容
awk -F' ' '{print NR,NF,$0}' i结果如下:

$NF 最后一列
$NF-1 最后一列数值-1
$(NF-1) 倒数第二列
#查找l文件的最后一列,最后一列-1的值和倒数第二列
awk -F, '{print $NF,$NF-1,$(NF-1)}' l结果如下:

这里列举$NF-1和$(NF-1) 为了最对比,明显区分哪个是查找列值。
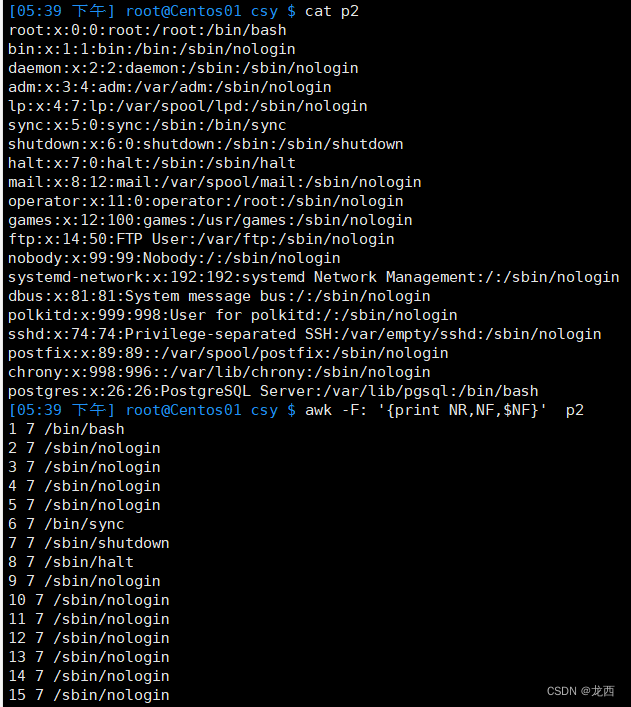
#分别以:和/为分隔符;打印p2文件的行号,列数,最后一个部分
awk -F: '{print NR,NF,$NF}' p2
awk -F/ '{print NR,NF,$NF}' p2结果如下:

1.4.10内置变量
内置变量
$0 一整行
$1-$99 第1列-第99列
$100 第100以及会有的100+
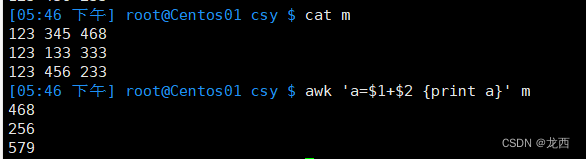
#变量a是$1+$2的和,打印a
awk 'a=$1+$2 {print a}' m结果如下:
#在BEGIN 部分给变量赋初始值
①在处理输入之前执行的BEGIN块,将变量 $a 初始化为0 :
awk 'BEGIN{$a=0}{$a=$1+$2 ;print$a}END{}' m结果如下:

例子中,END块为空,没有额外的动作。当运行上述命令时,它会解析文件 "m" 中的每一行,并将第一个字段和第二个字段相加,并打印出结果。
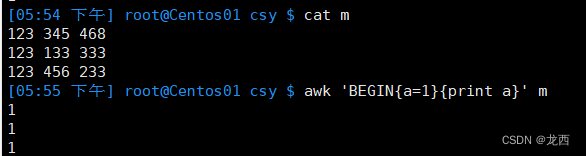
②在处理输入之前执行的BEGIN块,将变量 $a 初始化为1:
--1.
awk 'BEGIN{a=1}{print a}' m
--2.
awk 'BEGIN{a=1} a=a+1 {print a}' m
--3.
awk 'BEGIN{a=1} a=a-1 {print a}' m
--如果不给自定义变量赋值的话,它的初始值为空(0)
--4.
awk 'a=a+1 {print a}' m
--5.
awk 'a=a+10 {print a}' m结果如下:




1.4.11 赋值操作符
以下是在awk中用于更新变量的常见赋值操作符,可以简化对变量执行常见数学运算的过程。
- a=a+1 → a+=1
- a=a-1 → a-=1
- a=a*2 → a*=2
- a=a/2 → a/=2
- a=a^2 → a^=2
- a=a%2 → a%=2
--1.
awk 'BEGIN{a=10}a+=1{print a}' m
--2.
awk 'BEGIN{a=10}a-=1{print a}' m
--3.#设定a,b,c的初始值都是2,a每次递增2,
--b每次乘2,c每次2次方,对p文件,打印行号,a,b,c的值
awk 'BEGIN{a=2;b=2;c=2}(a+=2)(b*=2)(c^=2){print NR,a,b,c}' m结果如下:



1.4.12if 判断
awk 选项 '{if(条件1){动作} else if (条件2){动作} ... else{动作n}}'在awk中,条件可以是任何返回非零值的表达式。
其实在1.4.7算术运算符的例子中已经使用到if判断。
#如果$1+$2>$3 ,打印大,如果$1+$2<$3 ,打印小,否责打印巧了
awk '{if($1+$2>$3){print "大"}
else if ($1+$2<$3){print "小"}
else{print "巧了"}}' m结果如下:

#p2文件如果用户包含a并且包含b 打印"ab:用户名字" ;
如果用户名包含a不包含b打印"a:用户名";
如果包b不包a打印"b:用户名"否则不打印;
awk -F: '{if ($1 ~ /a/ && $1 ~ /b/){print "ab:"$1}
else if($1 ~ /a/ && $1 !~ /b/){print "a:"$1}
else if ($1 !~ /a/ && $1 ~ /b/){print "b:"$1}}' p2
结果如下:

二、more命令
在Linux中,more 是一个用于分页显示文本文件内容的命令行工具。当打开大型文件时,more 会按页显示文件内容,允许用户逐页浏览。
2.1基本语法
more [选项] [文件]
常用的选项包括:
-d:在显示过程中显示提示信息。-f:尝试将控制字符传递给终端。强制显示文件内容,即使文件内容是二进制文件。-c:显示Ctrl-M符号(^M)作为换行符。显示文件内容之前,先清屏。-p:不清除屏幕,而是直接覆盖当前内容。-s:将多个空行压缩为一个空行。
在
more中,可以使用以下命令进行浏览和导航:
Enter:向下滚动一行。
空格键:向下滚动一页。
- Ctrl+F:向下滚动一屏
- Ctrl+B:返回上一屏
q:退出
more命令。- =:输出当前行的行号
- :f :输出文件名和当前行的行号
- !命令:调用Shell,并执行命令
- V:调用vi编辑器
2.2用法示例
首先在Linux中创建一个包含大文本文件,可以使用
echo命令结合重定向符号>>来逐行追加内容。比如:for ((i=1; i<=200; i++)); do echo "This is line $i." >> large_file.txt done该命令将循环执行200次,并将每次循环生成的文本行追加到名为 "large_file.txt" 的文件中。
查看文件:
下面是使用
more命令来分页查看该文件内容的示例:

# 查看文件的内容(按 Enter 键下一行)
more large_file.txt结果如下:



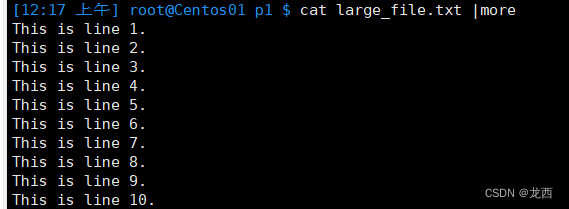
# 使用管道显示文件的内容(按 Enter 键下一行)
cat large_file.txt | more 结果如下:
# 显示文件的内容,并显示提示信息
more -d large_file.txt结果如下:

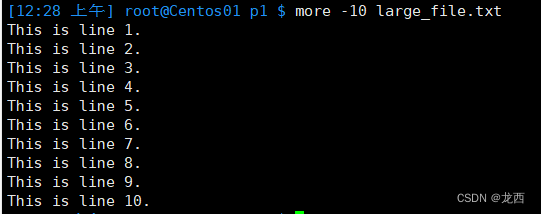
# 指定每页显示的行数为10
more -10 large_file.txt结果如下:
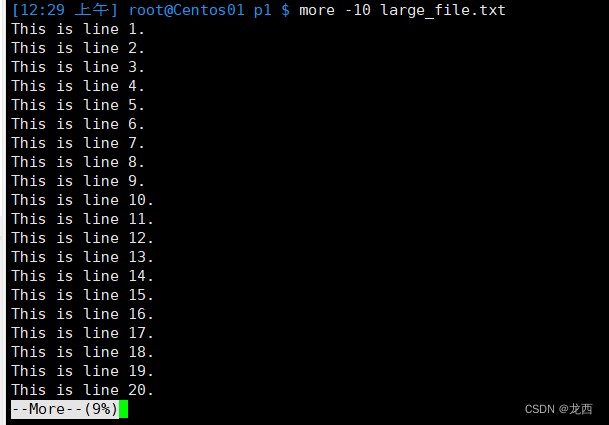
# 指定每页显示的行数为10(使用 空格键:向下滚动一页。)
结果如下:
# 指定每页显示的行数为10(使用Ctrl+B:返回上一屏 )
结果如下:

# 指定每页显示的行数为10(使用Ctrl+F:向下滚动一屏)
结果如下:
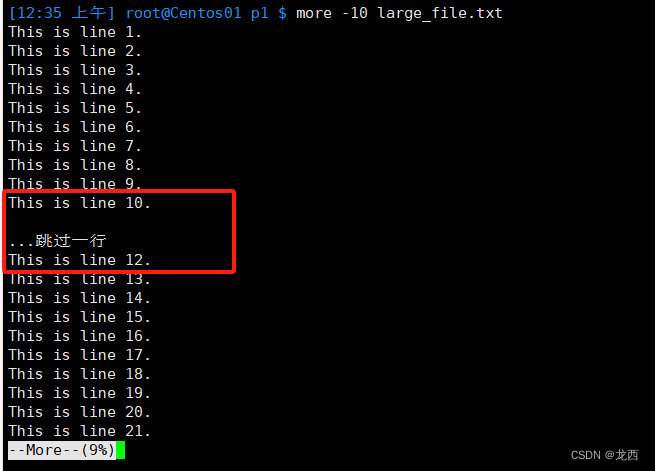
# 指定每页显示的行数为10(使用空格键:向下滚动一页)
结果如下:

对比发现 Ctrl+F和空格键 之间有明显区别!!!
# 指定每页显示的行数为10(使用=:输出当前行的行号)
结果如下:

# 指定每页显示的行数为10(使用 :f :输出文件名和当前行的行号)
结果如下:

总结:
more命令适用于查看较大的文本文件,特别是当文件内容太长以至于无法在终端中一次显示完整时。它提供了一种分页查看文件内容的方式,方便用户逐页浏览并查找特定信息。
三、less命令
在Linux中,less 命令也是一种用于分页显示文本文件内容的工具,类似于 more 命令。与 more 命令不同的是,less 具有更多的功能和灵活性。less 提供了更多的交互功能,例如搜索、前进、后退、跳转等功能,使得浏览大型文件变得更加方便。
3.1基本语法
less [选项] [文件]
常用选项包括:
-
-N:显示行号。 -
-i:忽略搜索时的大小写差异。 -
-F:自动退出显示内容较短的文件。 -
-S:折叠长行以适应终端宽度。 -
-r:将 ANSI 转义码显示为彩色。 -
-q:禁止显示提示信息。 /字符串:向下搜索匹配 字符串的文本。?字符串:向上搜索匹配 字符串 的文本。- -b :<缓冲区大小> 设置缓冲区的大小
- -e :当文件显示结束后,自动离开
- -f :强迫打开特殊文件,例如外围设备代号、目录和二进制文件
- -g :只标志最后搜索的关键词
- -m :显示类似more命令的百分比
- -o <文件名>: 将less 输出的内容在指定文件中保存起来
- -Q :不使用警告音
- -s :显示连续空行为一行
- -x <数字> :将"tab"键显示为规定的数字空格
- n:重复前一个搜索(与 / 或 ? 有关)
- N:反向重复前一个搜索(与 / 或 ? 有关)
- b :向上翻一页
- d :向后翻半页
- h :显示帮助界面
- Q :退出less 命令
- u :向前滚动半页
- y :向前滚动一行
- 空格键 :滚动一页
- 回车键 :滚动一行
- [pagedown]: 向下翻动一页
- [pageup]: 向上翻动一页
less相关使用说明参考文章:Linux less 命令 | 菜鸟教程 (runoob.com)
3.2用法示例
# 查看文件的内容(按 Enter 键滚动一行)
less large_file.txt# 显示文件的内容,并显示行号
less -N large_file.txt#浏览多个文件
less large_file.txt /var/log输入 :n后,切换到 /var/log
输入 :p 后,切换到large_file.txt附加备注:
1.全屏导航
- ctrl + F - 向前移动一屏
- ctrl + B - 向后移动一屏
- ctrl + D - 向前移动半屏
- ctrl + U - 向后移动半屏
2.单行导航
- j - 下一行
- k - 上一行
3.其它导航
- G - 移动到最后一行
- g - 移动到第一行
- q / ZZ - 退出 less 命令
4.其它有用的命令
- v - 使用配置的编辑器编辑当前文件
- h - 显示 less 的帮助文档
- &pattern - 仅显示匹配模式的行,而不是整个文件
5.标记导航
当使用 less 查看大文件时,可以在任何一个位置作标记,可以通过命令导航到标有特定标记的文本位置:
- ma - 使用 a 标记文本的当前位置
- 'a - 导航到标记 a 处
四、head命令
在 Linux 中,head 是一个命令行工具,用于显示文件的开头部分,默认情况下会显示文件的前 10 行。
4.1基本语法
head [选项] [文件]
常用选项包括:
-
-n NUM:显示文件的前 NUM 行。例如,head -n 20 file.txt将显示文件file.txt的前 20 行。 -
-c NUM:显示文件的前 NUM 个字节。例如,head -c 100 file.txt将显示文件file.txt的前 100 个字节。 -
-q:不显示文件名头部。 -
-v:显示文件名头部。
4.2用法示例
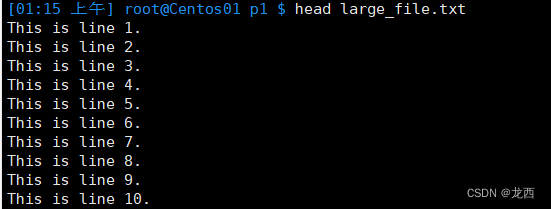
# 查看文件的开头部分,默认显示前10行
head large_file.txt
结果如下:
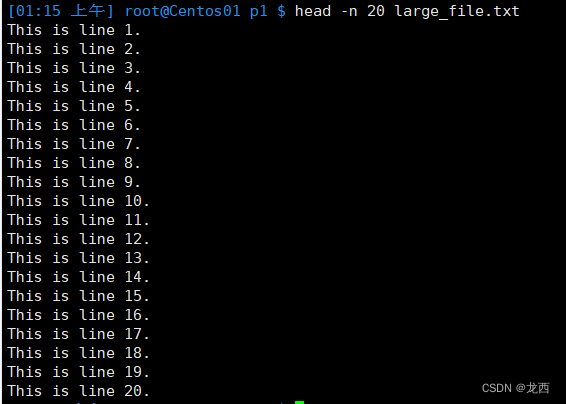
# 显示文件的前20行内容
head -n 20 large_file.txt
结果如下:
#显示文件前 10 个字节
head -c 10 passwd
结果如下:
![]()
五、tail命令
在Linux中,tail命令用于显示文件的末尾内容。它通常用于实时查看日志文件或监视文件的更改。
5.1基本语法
tail [选项] 文件名
常用的选项包括:
-n或--lines:指定要显示的行数。例如,tail -n 10 file.txt将显示文件file.txt的最后 10 行。-f或--follow:实时跟踪文件内容的变化,并持续显示新添加的内容。-q或--quiet:不显示文件名。-v或--verbose:显示文件名。-c或--bytes:指定要显示的字节数。例如,tail -c 100 file.txt将显示文件file.txt的最后 100 个字节。
5.2示例用法
# 显示文件的最后 10 行
tail -n 10 large_file.txt结果如下:

# 想要实时监视文件的更改,可以使用-f选项,实时显示文件的新增内容
tail -f large_file.txt比如给large_file.txt新增多条内容:
for ((i=202; i<=210; i++)); do
echo "This is line $i." >> large_file.txt;
done查看结果如下:
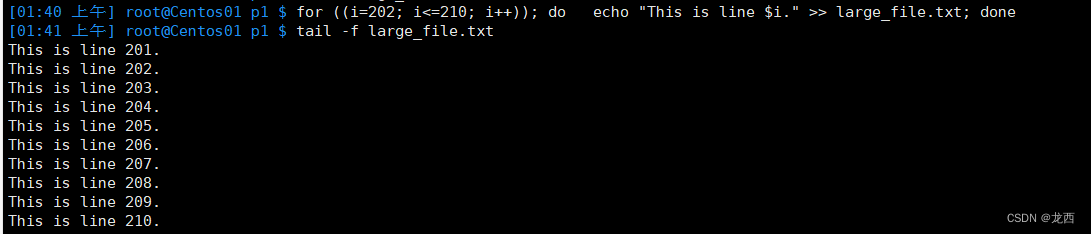
退出
tail -f命令,可以使用以下方法之一:
- 按下组合键
Ctrl + C:这将发送一个中断信号给tail进程,使其停止运行并退出。- 按下组合键
Ctrl + D:这将发送一个文件结束符(EOF)给tail进程,通常也会导致其停止运行并退出。
# 显示文件的最后 100 个字节
tail -c 100 large_file.txt结果如下:
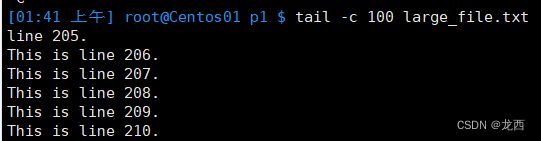
#显示文件 的内容,从第 403 行至文件末尾
cat -n large_file.txt|tail -n +403结果如下:

六、tac命令
在Linux中,tac命令用于逆序显示文件的内容,即从最后一行开始显示,一直到第一行。它的作用类似于反转文件内容的顺序。
6.1基本语法
tac [选项] 文件名
6.2示例用法
# 反转f文件的行顺序并输出结果到标准输出
tac f结果如下:
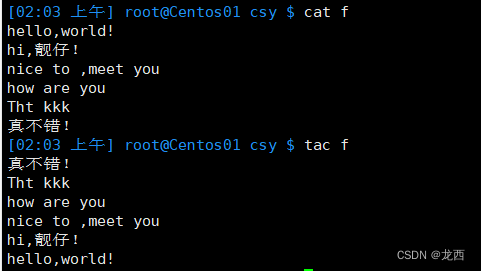
从输出结果可以看出tac命令是将从最后一行开始显示文件内容,然后逐行向上显示,直到第一行。
七、cut命令
在Linux中,cut命令用于从文件中提取指定的列或字段。它可以根据指定的定界符(默认为制表符)或字符位置来切割文本。
7.1基本语法
cut [选项] 文件名
常用的选项包括:
- -c :以字符为单位进行分割,指定要提取的字符位置。(每个字符为一个位置)(-c位置)加了-c之后就不能加-d和-f了
- -d :自定义分隔符,默认为制表符。
- -f :与-d一起使用,指定显示哪个区域。
7.2示例用法
#提取文件o的第一列
cut -d' ' -f1 o
结果如下:
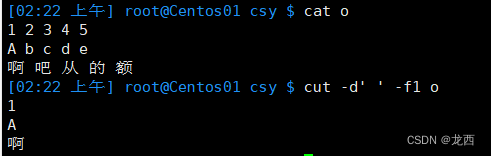
#当以空格为分隔符时要用引号
#提取文件o的第一列到第三列
cut -c1-3 o结果如下:

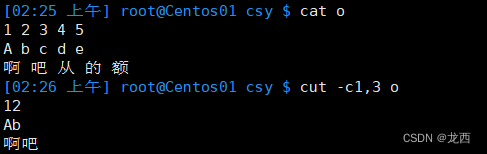
#提取文件o的第一列和第三列
cut -c1,3 o结果如下:
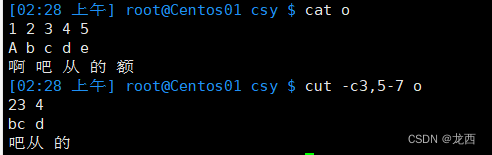
#提取文件o的第3个字符和第5至7个字符
cut -c3,5-7 0
结果如下:
八、sort命令
在Linux中,sort命令用于对文件内容进行排序。它可以按照不同的规则对行进行排序,并将结果输出到标准输出或指定的文件。
8.1基本语法
sort [选项] 文件名
常用的选项包括:
-
-r:以逆序(降序)排序。 -
-n:按数值大小进行排序。 -
-k:指定按照某个字段进行排序。 -
-t:指定字段的分隔符。 -
-u:只显示唯一的行。去重(按照排序列去重)
8.2示例用法
#对文件i进行按数值大小排序
sort -n i结果如下:

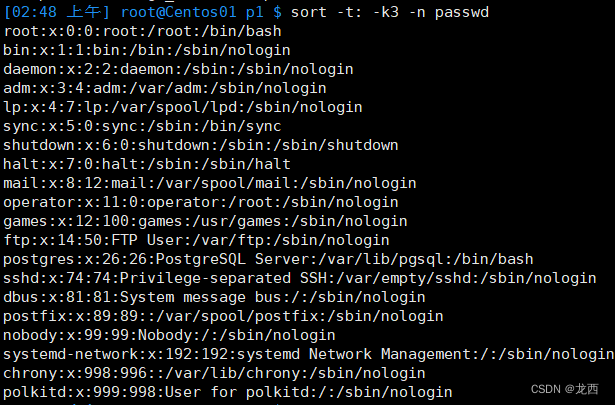
#以:为分隔符 按照/etc/passwd 第三部分的数字顺序排序显示文件
sort -t: -k3 -n passwd结果如下:
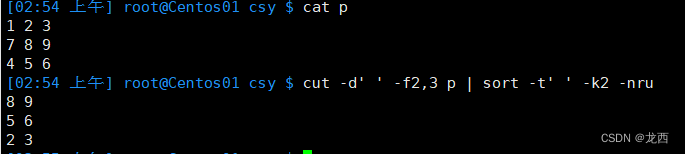
#以空格为分隔符,显示p文件的第2和第3部分,按照第3部分的数字顺序反向排序,去除重复项
cut -d' ' -f2,3 p | sort -t' ' -k2 -nru结果如下:
九、tar命令
在Linux中,tar命令用于创建和提取.tar格式的归档文件,也称为tarball。tar命令通常用于对文件和目录进行打包和解包操作,以便在文件之间进行传输和存档。
9.1基本语法
tar 选项 目标文件 [文件或目录...]
--打包的语法
tar 选项 包名 文件名(可以多个)
--解包语法
tar 选项 包名 -C 路径常用的选项包括:
- c:创建归档文件
- v:显示过程
- z:使用gzip/gunzip(打包的同时用gzip压缩 或者 解包的同时用gunzip解压),(通常与
-c或-x一起使用) - j:使用bzip2/bunzip2(打包的同时用bzip2压缩或者解包的同时用bunzip2解压),(通常与
-c或-x一起使用) - f:指定压缩包名(必须加,并且写在最后面)
- x:解包
- t :列出包里面的内容
- -C:指定路径
#比较常见的组合
zcvf :打包的同时用gzip压缩
jcvf :打包的同时用bzip2压缩
zxvf :解包的同时用gunzip解压
jxvf :解包的同时用bunzip2解压
9.2示例用法
# 创建一个名为 a123.tar 的归档文件,将 a1 ,a2和 a3添加到归档中
tar -cvf a123.tar a1 a2 a3结果如下:

# 提取归档文件a123.tar 中的所有文件
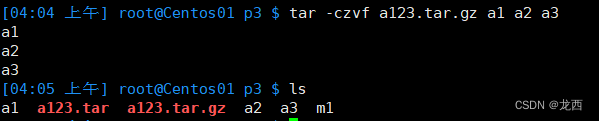
tar -xvf a123.tar#创建使用gzip压缩的归档文件
tar -czvf a123.tar.gz a1 a2 a3结果如下:
#提取使用gzip压缩的归档文件 ,同时指定到aa目录
tar -xzvf a123.tar.gz -C /csy/p3/aa结果如下:
![]()
![]()
#创建使用bzip2压缩的归档文件
tar -jcvf b123.tar.gz a1 a2 a3结果如下:

#提取使用bzip2压缩的归档文件 ,同时指定到bb目录
tar -jxvf b123.tar.gz -C /csy/p3/bb结果如下:

十、comm命令
在Linux中,comm命令用于比较两个已排序的文件,并显示它们之间的共同行、独特行以及仅存在于其中一个文件中的行。comm命令需要两个输入文件作为参数,并且这两个文件都必须事先按照字典顺序排序。
10.1基本语法
comm [选项] 文件1 文件2
常用的选项包括:
-
-1:不显示只存在于第一个文件中的行。 -
-2:不显示只存在于第二个文件中的行。 -
-3:不显示共同的行。
10.2用法示例
a.txt 与 b.txt 的文件内容如下 :
[root@Centos01 csy ]$ cat a.txt 111 222 aaa bbb ccc ddd eee [root@Centos01 csy ]$ cat b.txt aaa bbb ccc hhh jjj ttt
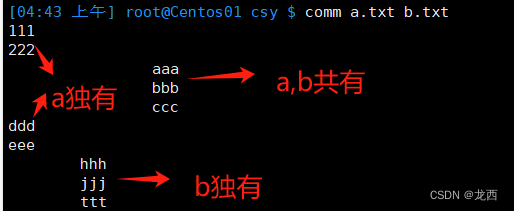
#比较两个文件file1.txt和file2.txt,并显示共同行:
comm a.txt b.txt
结果如下:
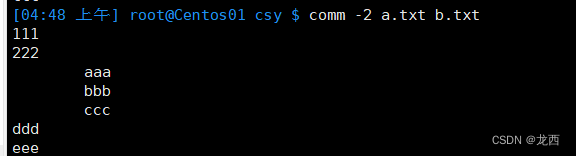
#比较两个文件a.txt和b.txt,并显示只存在于a.txt的行和共同行:
comm -2 a.txt b.txt
结果如下:
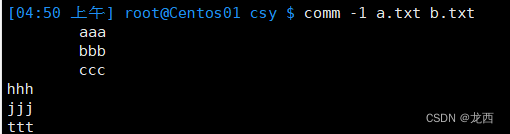
#比较两个文件a.txt和b.txt,并显示只存在于b.txt的行和共同行
comm -1 a.txt b.txt
结果如下:
#比较两个文件a.txt和b.txt,不显示共同行
comm -3 a.txt b.txt结果如下:

#比较两个文件a.txt和b.txt,只显示b.txt独有
comm -13 a.txt b.txt结果如下:

# 比较两个文件a.txt和b.txt,只显示a.txt独有
comm -23 a.txt b.txt结果如下:

十一、diff命令
在Linux中,diff命令用于比较两个文件或目录之间的差异。它会逐行比较文件内容,并显示两个文件之间的不同之处。
11.1基本语法
diff [选项] 文件1 文件2
常用的选项包括:
-
-r:递归比较目录及其子目录。 -
-q:只显示文件是否有差异,而不显示具体的差异内容。 -
-u:以统一的格式显示差异内容。 -
-c:以上下文的格式显示差异内容。 -
-i:忽略大小写差异。 -
-w:忽略空格差异。
11.2示例用法
A1 与 A2的文件内容如下 :
[root@Centos01 csy ]$ cat A1 This is file 1. It has some content. It has more than 10 lines. Line 4. Line 5. Line 6. Line 7. Line 8. Line 9. Line 10. Line 11. Line 12. [root@Centos01 csy ]$ cat A2 This is file 2. It also has some content. It has more than 10 lines. Line 4. Line 5. Line 6. Line 7. Line 8. Line 9. Line 10. Line 11. Line 12.
#比较两个文件file1.txt和file2.txt,并显示差异内容
diff A1 A2结果如下:

#比较两个文件file1.txt和file2.txt,并显示文件是否有差异
diff -q A1 A2结果如下:
![]()
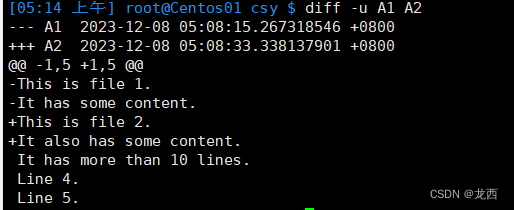
#比较两个文件file1.txt和file2.txt,并以统一的格式显示差异内容
diff -u A1 A2结果如下:
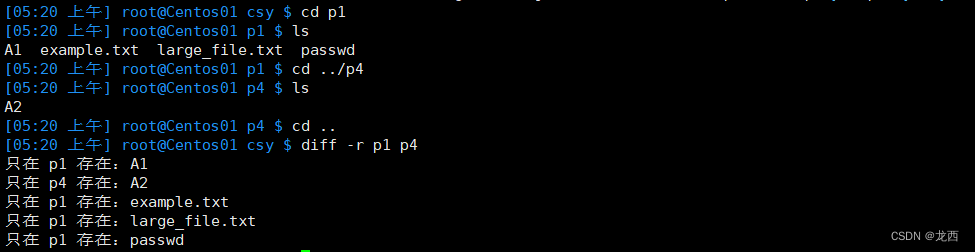
#比较两个目录p1和p4,并显示目录及其子目录中的差异文件
diff -r p1 p4
结果如下:
有关文件/文本的相关常用命令使用方法已总结完毕,这些内容均为我个人的学习笔记,如果有错误的地方还请大家指出,感谢大家的查看!如果对您有一定帮助的话,还请点赞收藏加关注! 非常感谢你们的支持!!!















 863
863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











