







一、什么是爬虫?
简言之,爬虫可以帮助我们把网站上的信息快速提取并保存下来。我们可以把互联网比作一张大网,而爬虫(即网络爬虫)便是在网上爬行的蜘蛛(Spider)。把网上的节点比作一个个网页,爬虫爬到这个节点就相当于访问了该网页,就能把网页上的信息提取出来。
我们可以把节点间的连线比作网页与网页之间的链接关系这样蜘蛛通过一个节点后可以顺着节点连线继续爬行到达下一个节点,即通过一个网页继续获取后续的网页,这样整个网的节点便可以被蜘蛛全部爬行到,网页的数据就可以被抓取下来了。
二、爬虫有什么用?
通过上面的简单了解,你可能大致了解爬虫能够做什么了,但是一般要学一个东西,我们得知道学这个东西是来做什么的吧!
比如,我们在网上看到了很多精美的图片,想要保存下来,但是一次次的右键另存为就显得非常的费时费力,那么我们就可以利用爬虫将这些图片快速的抓取下来,极大地节省时间和精力。比如,我们想收集一些新闻门户上的新闻,看一下每天都发生了哪些事情,我们可以写个爬虫把新闻爬取下来,每天运行一次或者设置定时任务定时运行,这样我们可以不用进入网页就能看到新闻,也可以根据关键词进行热点分析。
另外,大家抢讨的火车票、演唱会门票、茅台等等都可以利用爬虫来实现。所以说爬虫的用处十分强大,每个人都应该会一点爬虫!
三、爬虫的分类
我们常见的爬虫有通用爬虫和聚焦爬虫。
1、通用爬虫:针对于百度、谷歌、必应这类搜索引擎类的爬虫程序
2、聚焦爬虫:又名定向爬虫,就是我们平时写的针对某个需求或者某个问题而写的程序
四、所谓的“爬虫学的好,牢饭吃到饱!"
时不时冒出一两个因为爬虫入狱的新闻,是不是爬虫是违法的呀,爬虫目前来说是灰色地带的东西,所以大家还是要区分好小人和君子,避免牢底坐穿!

那什么是robots协议呢?我们在B站的网址的根目录添加 /robots.txt,
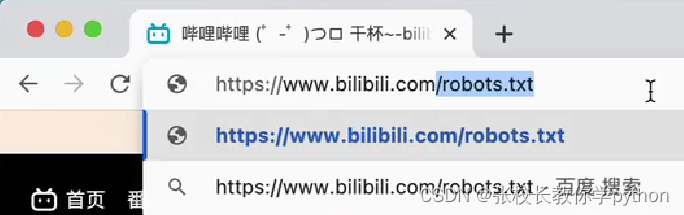
回车,进入新的界面,bot机器人,spider爬虫(大家最好下一个谷歌浏览器,它是我们写爬虫的一个主流工具)

每一个网站都有robots协议,就是让大家输入/robots.txt进入的界面,协议规定了什么样的爬虫能爬哪些页面,这里说了,苹果的、易搜的、360、……这些公司的爬虫,可以爬我的主页面(输入B站的网址进入的首页面),这些都是做引擎的公司,你爬了我的主页面,我去搜的时候能直接把我上面的信息展示在你的搜索引擎拿到的结果上,这对我是有好处的。
虽然规定了robots协议,但是它只是告诉我们哪些可以爬,哪些不可以爬,只是起到公告的作用,没有实际的限制作用。

爬虫的大致流程:获取网页、提取信息、保存数据
在day12下创建一个名为06-HTML简单了解.html的HTML文件
day12 --> new --> HTML File --> 06-HTML简单了解.html
可能会出现一些代码,我们ctrl + A然后把这部分内容删掉(这部分代码是做网页的基础框架,可在英文状态下通过! + Tab生成)
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
</body>
</html>
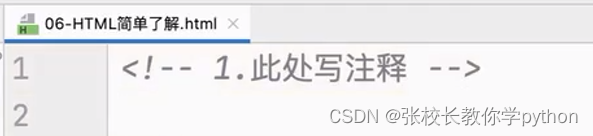
一、我们先敲出数字1,然后再敲ctrl+/,得到的形式就是HTML的注释
---->两端是大小于符号,接着叹号,然后两对减号,中间就可以写注释啦,注释允许回车换行的
二、我们爬的网页,是用HTML代码来写的。我们来简单了解一下网页,这么了解呢?我们试着写一丢丢前端代码(了解前端网页,如果大家想要深入学习,可以通过菜鸟教程学习更多相关知识)
HTML基础
HTML,全称:超文本标记语言,文件后缀名为.html
HTML主要负责显示网页中的内容。除了HTML,构建一个网页还需要:CSS、JavaScript。CSS负责渲染网页,美化网页,对网页进行布局;JavaScript负责实现处理网页上的一些行为。这三要素各司其职,构成一个网页。网页上的内容被写在HTML的一种叫做“标签”的东西里面。网页的标签分为:一般标签、自闭合标签
一般标签(标题标签):由起始标签和结束标签组成,起始标签内可以添加属性,起始标签和结束标签可以添加内容或其他标签。
HTML中一级标题标签:<h1></h1>
起始标签:<h1>
结束标签:</h1>
例如:<h1 属性1=属性值1 属性2=属性值2……>内容或其他标签</h1>
打开哔哩哔哩 ----> 随意页面单击右键 ----> 检查,就会出现一个新的专为程序员设计的小窗口(开发者工具)。
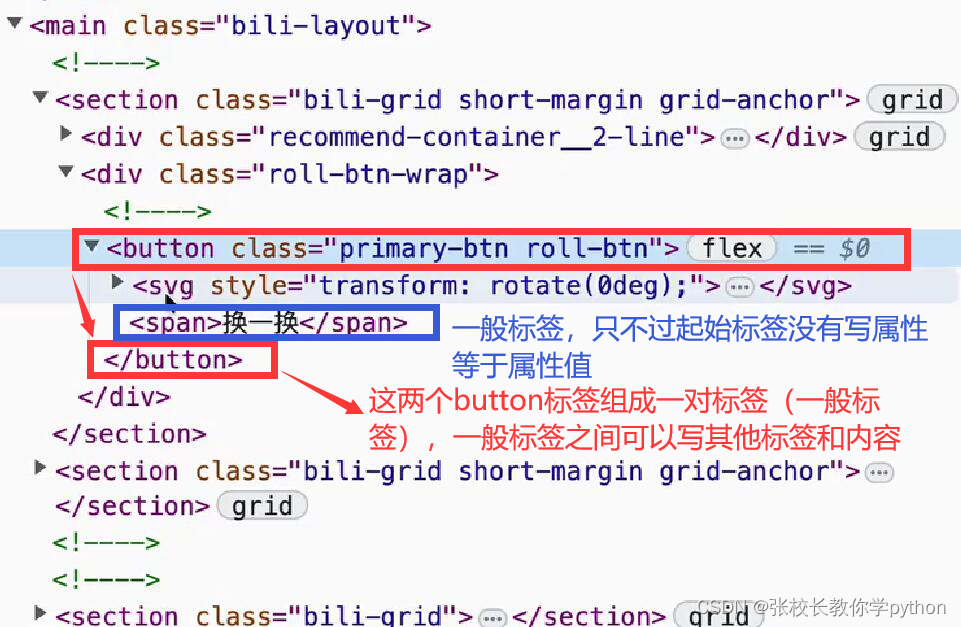
每一段标签代表主页面上的某个组成部分(某段标签代表主页面上的某张图片),也就是说网页是由成千上万标签组成的。
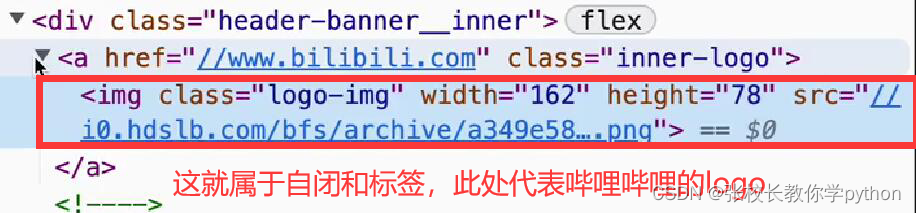
自闭合标签(图片标签):只有一个标签,只能在标签内编写属性。例如:<img 属性1=属性值1 属性2=属性值2……>
在新的一行,英文状态下输入叹号,然后点击tab键(shift上面),就会恢复构成网页框架的代码。
! + Tab就会生成一段代码(有差别,但不大),这是做网站前的框架(很幸运可以一键生成)。
关于缩进,例如第一个子标签head,把第一对子标签全部选中,按Tab键即可,然后同样的方法再对head之间的内容缩进。如果缩进多了,就shift + Tab。
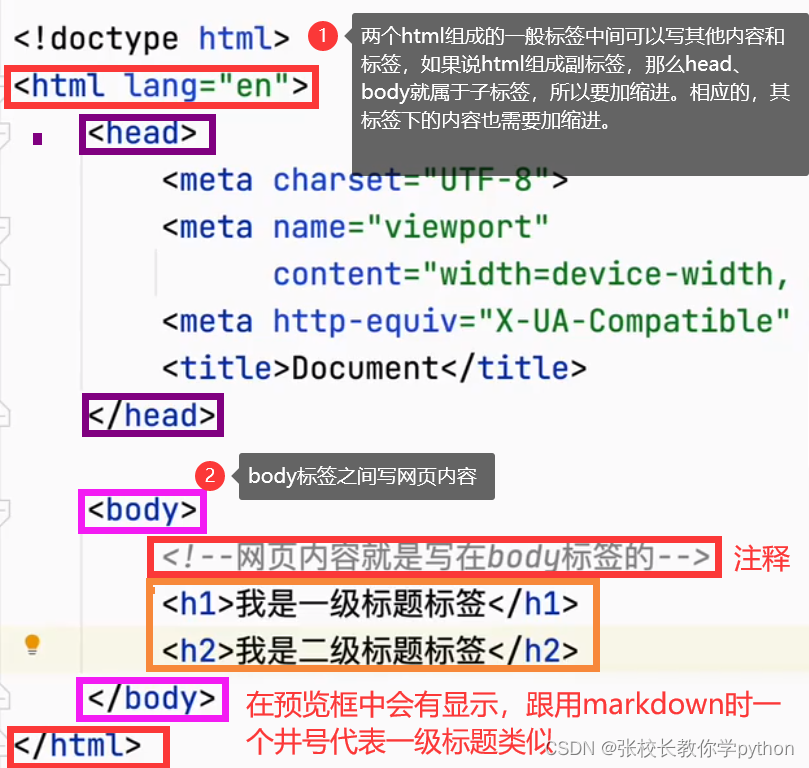
也就说,markdown也可以写前端代码。一个井号代表一级标题……HTML页面右上角,有四个小图标(这是预览的图标,就可以在预览页面查看写的状态)

点击预览即可看到:

这部分我们了解一下html的大致内容,大家想要深入学习可以在菜鸟教程上详细学习html。
接下来,我们接着在body下写子标签(a标签,插入超链接),在预览框中就可以用
<a href="https://www.runoob.com/html/html5-intro.html
" target="_blank">我是超链接标签</a>
在起始标签中添加属性等于属性值,第一个属性是hypertext reference --> href(超文本引用),这时点击“我是超链接标签”,结果只在当前标签页进行跳转网页;这时我们添加第二个属性target="_blank",打开的页面, 每点击一次“我是超链接标签”,打开的是新的标签页去加载网页。
紧接着,我们写一个video标签。
<video controls src="https://video.pearvideo.com/mp4/short/20170908/cont-1151845-10862630-hd.mp4 "></video>>
在预览页就可以欣赏video















 546
546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









