







目录
二、ELK+Filebeat+Kafka+Zookeeper架构
三、搭建ELK+Filebeat+Kafka+Zookeeper
1、3台机子安装zookeeper 192.168.100.30/40/50
2、安装kafka 192.168.100.30/40/50
3、配置数据采集层filebeat(192.168.100.23)
一、为什么要做日志分析平台?
随着业务量的增长,每天业务服务器将会产生上亿条的日志,单个日志文件达几个GB,这时我们发现用Linux自带工具,cat grep awk 分析越来越力不从心了,而且除了服务器日志,还有程序报错日志,分布在不同的服务器,查阅繁琐。
待解决的问题:
① 大量不同种类的日志成为了运维人员的负担,不方便管理;
② 单个日志文件巨大,无法使用常用的文本工具分析,检索困难;
③ 日志分布在多台不同的服务器上,业务一旦出现故障,需要一台台查看日志。
二、ELK+Filebeat+Kafka+Zookeeper架构
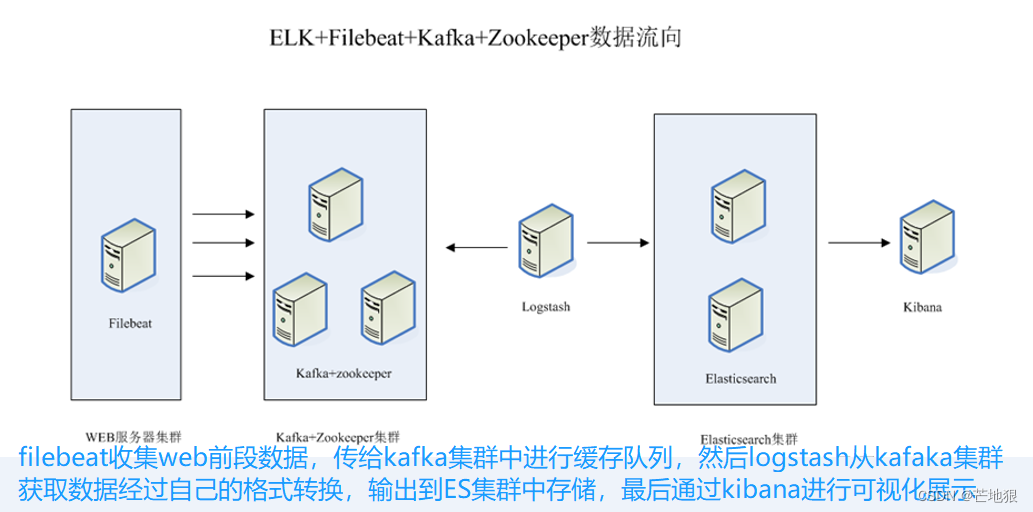
整体的架构如上图所示
这个架构图从左到右,总共分为5层,每层实现的功能和含义分别介绍如下:
第一层、数据采集层
数据采集层位于最左边的业务服务器集群上,在每个业务服务器上面安装了filebeat做日志收集,然后把采集到的原始日志发送到Kafka+zookeeper集群上。第二层、消息队列层
原始日志发送到Kafka+zookeeper集群上后,会进行集中存储,此时,filbeat是消息的生产者,存储的消息可以随时被消费。第三层、数据分析层
Logstash作为消费者,会去Kafka+zookeeper集群节点实时拉取原始日志,然后将获取到的原始日志根据规则进行分析、清洗、过滤,最后将清洗好的日志转发至Elasticsearch集群。第四层、数据持久化存储
Elasticsearch集群在接收到logstash发送过来的数据后,执行写磁盘,建索引库等操作,最后将结构化的数据存储到Elasticsearch集群上。第五层、数据查询、展示层
Kibana是一个可视化的数据展示平台,当有数据检索请求时,它从Elasticsearch集群上读取数据,然后进行可视化出图和多维度分析。
三、搭建ELK+Filebeat+Kafka+Zookeeper
| ip地址 | 所属集群 | 安装软件包 |
| 192.168.100.20 | Elasticsearch | Elasticsearch集群 |
| 192.168.100.21 | Elasticsearch | Elasticsearch集群 |
| 192.168.100.22 | Logstash | 数据转发 |
| 192.168.100.30 | kafka+zookeeper | kafka+zookeeper |
| 192.168.100.40 | kafka+zookeeper | kafka+zookeeper |
| 192.168.100.50 | kafka+zookeeper | kafka+zookeeper |
| 192.168.100.23 | filebeat | 配置数据采集层 |
本实验基于ELFK已经搭好的情况下 Filebeat后续还要更改配置
1、3台机子安装zookeeper 192.168.100.30/40/50
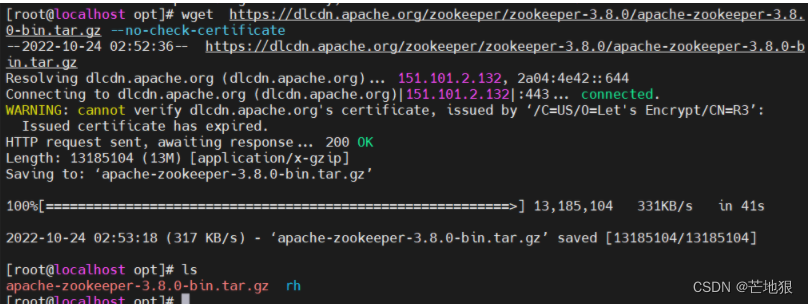
#zookeep下载地址
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz
1.1 解压安装zookeeper软件包
cd /opt
上传apache-zookeeper-3.8.0-bin.tar.gz包
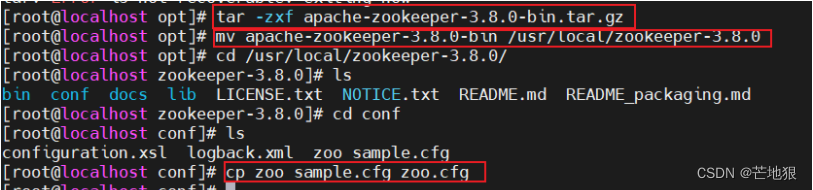
tar zxf apache-zookeeper-3.8.0-bin.tar.gz 解包
mv apache-zookeeper-3.8.0-bin /usr/local/zookeeper-3.8.0 #将解压的目录剪切到/usr/local/
cd /usr/local/zookeeper-3.8.0/conf/
cp zoo_sample.cfg zoo.cfg 备份复制模板配置文件为zoo.cfg
1.2 修改Zookeeper配置配置文件
cd /usr/local/zookeeper-3.8.0/conf #进入zookeeper配置文件汇总
ls 后可以看到zoo_sample.cfg模板配置文件
cp zoo_sample.cfg zoo.cfg 复制模板配置文件为zoo.cfg
vim zoo.cfg
tickTime=2000
#通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
initLimit=10
#Leader和Follower初始连接时能容忍的最多心跳数( tickTime的数量),这里表示为10*2s
syncLimit=5
#Leader和Follower之间同步通信的超时时间,这里表示如果超过5*2s,Leader认为Follwer死掉,并从服务器列表中删除Follwer
dataDir=/usr/local/zookeeper-3.8.0/data
#●修改,指定保存Zookeeper中的数据的目录,目录需要单独创建
dataLogDir=/usr/local/zookeeper-3.8.0/1ogs
#●添加,指定存放日志的目录,目录需要单独创建
clientPort=2181 #客户端连接端口#添加集群信息
server.1=192.168.100.30:3188:3288
server.2=192.168.100.40:3188:3288
server.3=192.168.100.50:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 977
977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









