







大数据技术之Zookeeper第二部分
第1章 算法基础
思考:Zookeeper是如何保证数据一致性的?这也是困扰分布式系统框架的一个难题。
1.1 拜占庭将军问题
拜占庭将军问题是一个协议问题,拜占庭帝国军队的将军们必须全体一致的决定是否攻击某一支敌军。问题是这些将军在地理上是分隔开来的,并且将军中存在叛徒。叛徒可以任意行动以达到以下目标:欺骗某些将军采取进攻行动;促成一个不是所有将军都同意的决定,如当将军们不希望进攻时促成进攻行动;或者迷惑某些将军,使他们无法做出决定。如果叛徒达到了这些目的之一,则任何攻击行动的结果都是注定要失败的,只有完全达成一致的努力才能获得胜利。
1.2 Paxos算法
Paxos算法——解决什么问题
Paxos算法:一种基于消息传递且具有高度容错特性的一致性算法。
Paxos算法解决的问题:就是如何快速正确的在一个分布式系统中对某个数据值达成一致,并且保证不论发生任何异常,都不会破坏整个系统的一致性。
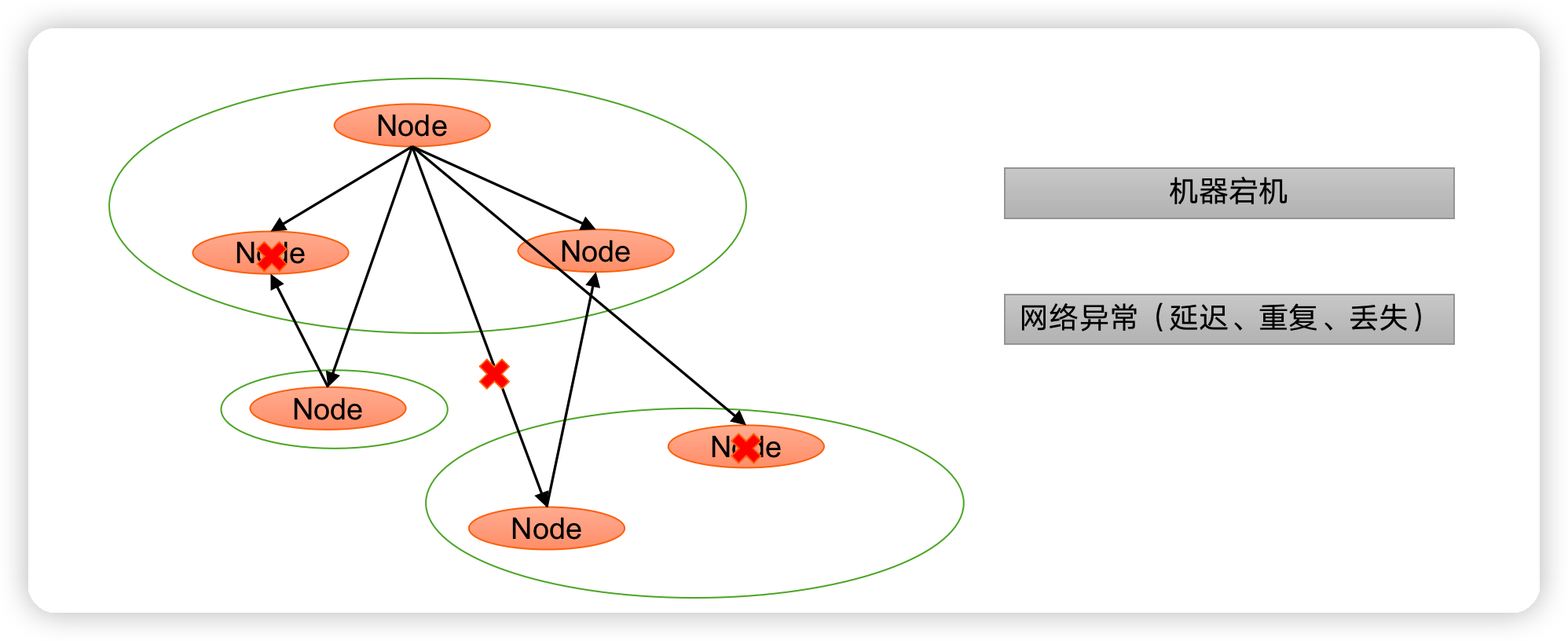
1.2.1 Paxos算法描述
- 在一个Paxos系统中,首先将所有节点划分为Proposer(提议者),Acceptor(接受者),和Learner(学习者)。(注意:每个节点都可以身兼数职)。
一个完整的Paxos算法流程分为三个阶段:
- Prepare准备阶段
- Proposer向多个Acceptor发出Propose请求Promise(承诺)
- Acceptor针对收到的Propose请求进行Promise(承诺)
- Accept接受阶段
- Proposer收到多数Acceptor承诺的Promise后,向Acceptor发出Propose请求
- Acceptor针对收到的Propose请求进行Accept处理
- Learn学习阶段:Proposer将形成的决议发送给所有Learners
1.2.3 Paxos算法流程

(1)Prepare: Proposer生成全局唯一且递增的Proposal ID,向所有Acceptor发送Propose请求,这里无需携带提案内容,只携带Proposal ID即可。
(2)Promise: Acceptor收到Propose请求后,做出“两个承诺,一个应答”。不再接受Proposal ID小于等于(注意:这里是<= )当前请求的Propose请求。不再接受Proposal ID小于(注意:这里是< )当前请求的Accept请求。不违背以前做出的承诺下,回复已经Accept过的提案中Proposal ID最大的那个提案的Value和Proposal ID,没有则返回空值。
(3)Propose: Proposer收到多数Acceptor的Promise应答后,从应答中选择Proposal ID最大的提案的Value,作为本次要发起的提案。如果所有应答的提案Value均为空值,则可以自己随意决定提案Value。然后携带当前Proposal ID,向所有Acceptor发送Propose请求。
(4)Accept: Acceptor收到Propose请求后,在不违背自己之前做出的承诺下,接受并持久化当前Proposal ID和提案Value。
(5)Learn: Proposer收到多数Acceptor的Accept后,决议形成,将形成的决议发送给所有Learner。
下面我们针对上述描述做三种情况的推演举例:为了简化流程,我们这里不设置Learner
情况1:
有A1, A2, A3, A4, A5 5位议员,就税率问题进行决议。
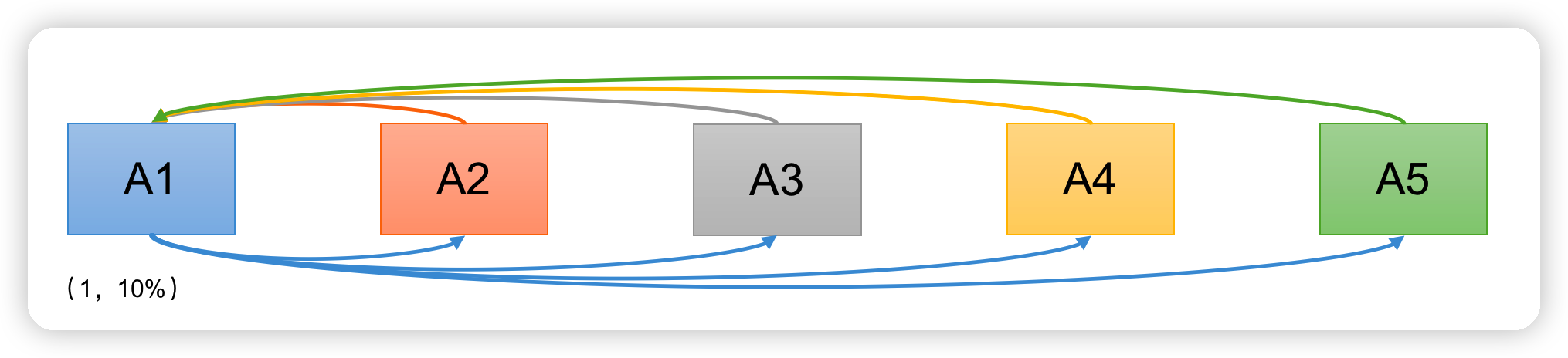
- A1发起1号Proposal的Propose,等待Promise承诺;
- A2-A5回应Promise;
- A1在收到两份回复时就会发起税率10%的Proposal;
- A2-A5回应Accept;
- 通过Proposal,税率10%。
情况2:
现在我们假设在A1提出提案的同时, A5决定将税率定为20%
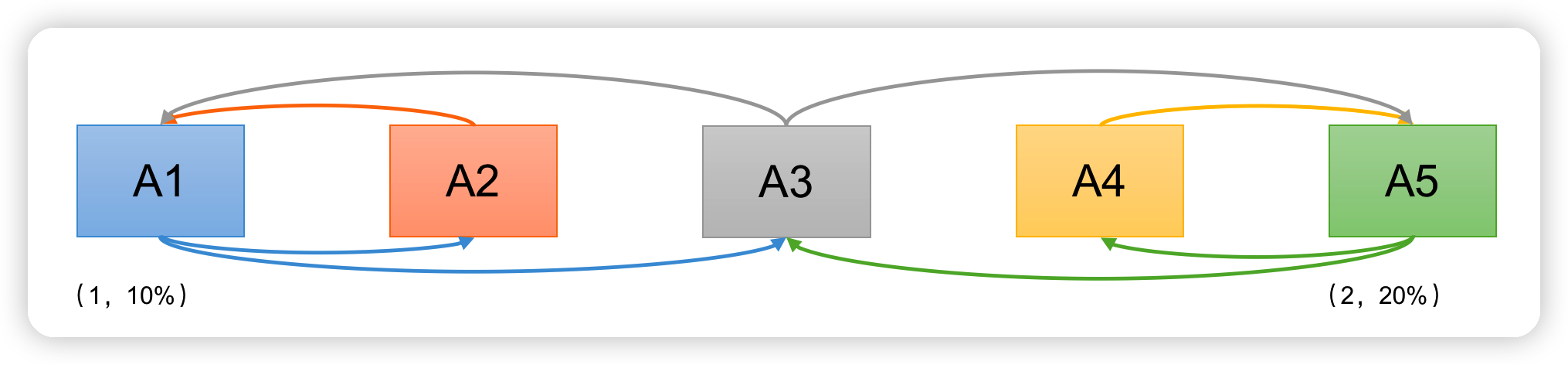
- A1,A5同时发起Propose(序号分别为1,2)
- A2承诺A1,A4承诺A5,A3行为成为关键
- 情况1:A3先收到A1消息,承诺A1。
- A1发起Proposal(1,10%),A2,A3接受。
- 之后A3又收到A5消息,回复A1:(1,10%),并承诺A5。
- A5发起Proposal(2,20%),A3,A4接受。之后A1,A5同时广播决议。
Paxos算法缺陷:在网络复杂的情况下,一个应用Paxos算法的分布式系统,可能很久无法收敛,甚至陷入活锁的情况。
情况3:
现在我们假设在A1提出提案的同时, A5决定将税率定为20%
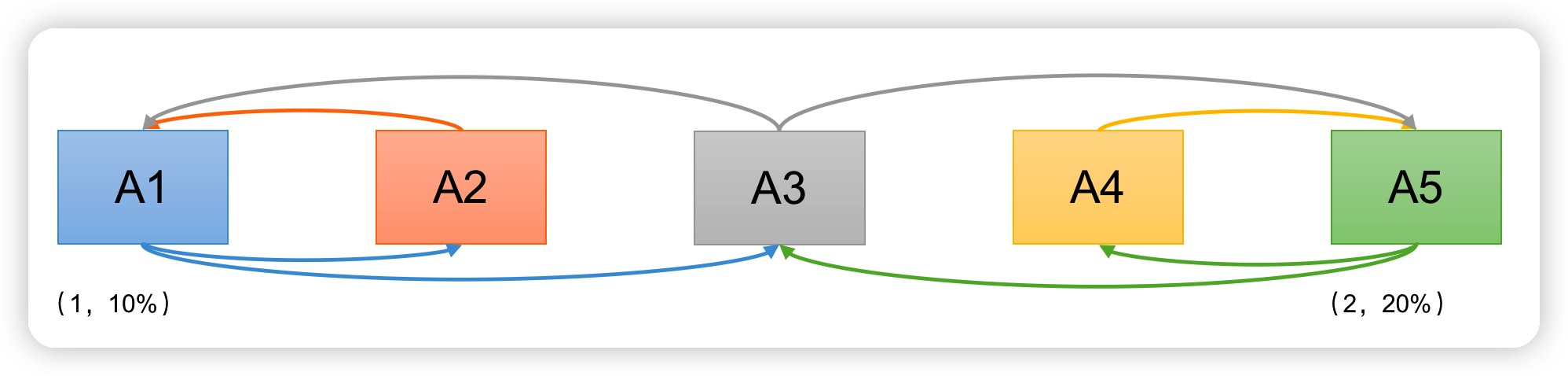
- A1,A5同时发起Propose(序号分别为1,2)
- A2承诺A1,A4承诺A5,A3行为成为关键
- 情况2:A3先收到A1消息,承诺A1。之后立刻收到A5消息,承诺A5。
- A1发起Proposal(1,10%),无足够响应,A1重新Propose (序号3),A3再次承诺A1。
- A5发起Proposal(2,20%),无足够相应。 A5重新Propose (序号4),A3再次承诺A5。
造成这种情况的原因是系统中有一个以上的Proposer,多个Proposers相互争夺Acceptor,造成迟迟无法达成一致的情况。
针对这种情况,一种改进的Paxos算法被提出:从系统中选出一个节点作为Leader,只有Leader能够发起提案。这样,一次Paxos流程中只有一个Proposer,不会出现活锁的情况,此时只会出现例子中第一种情况。
1.3 ZAB协议
1.3.1 什么是ZAB算法
Zab借鉴了Paxos算法,是特别为Zookeeper设计的支持崩溃恢复的原子广播协议。基于该协议,Zookeeper设计为只有一台客户端(Leader)负责处理外部的写事务请求,然后Leader客户端将数据同步到其他Follower节点。即Zookeeper只有一个Leader可以发起提案。
1.3.2 Zab协议内容
Zab协议包括两种基本的模式:消息广播、崩溃恢复。
消息广播
ZAB协议针对事务请求的处理过程类似于一个两阶段提交过程
(1)广播事务阶段
(2)广播提交操作
这两阶段提交模型如下,有可能因为Leader宕机带来数据不一致,比如
(1)Leader发起一个事务Proposal1后就宕机,Follower都没有Proposal1
(2)Leader收到半数ACK宕机,没来得及向Follower发送Commit
怎么解决呢?ZAB引入了崩溃恢复模式。
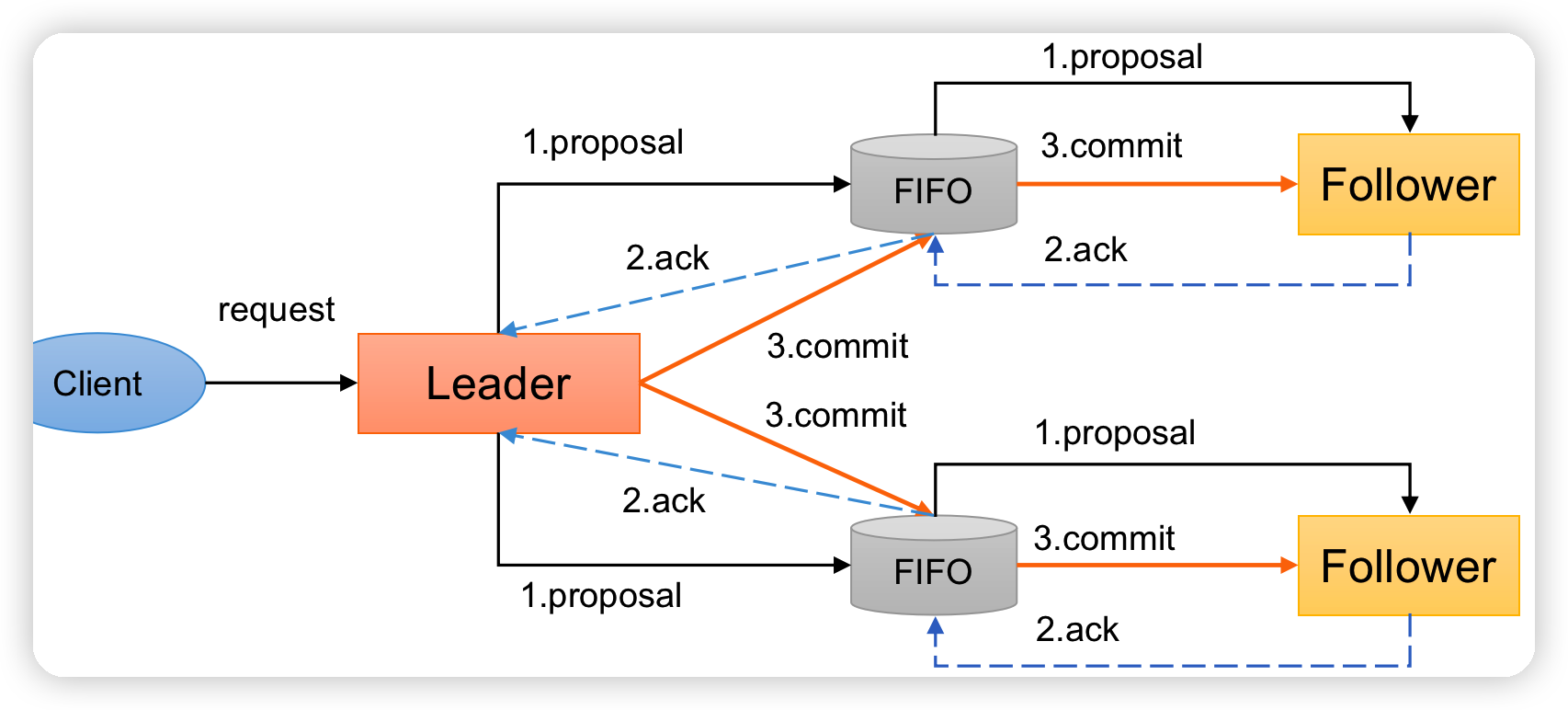
- (1)客户端发起一个写操作请求。
- (2)Leader服务器将客户端的请求转化为事务Proposal 提案,同时为每个Proposal 分配一个全局的ID,即zxid。
- (3)Leader服务器为每个Follower服务器分配一个单独的队列,然后将需要广播的 Proposal依次放到队列中去,并且根据FIFO策略进行消息发送。
- (4)Follower接收到Proposal后,会首先将其以事务日志的方式写入本地磁盘中,写入成功后向Leader反馈一个Ack响应消息。
- (5)Leader接收到超过半数以上Follower的Ack响应消息后,即认为消息发送成功,可以发送commit消息。
- (6)Leader向所有Follower广播commit消息,同时自身也会完成事务提交。Follower 接收到commit消息后,会将上一条事务提交。
- (7)Zookeeper采用Zab协议的核心,就是只要有一台服务器提交了Proposal,就要确保所有的服务器最终都能正确提交Proposal。
崩溃恢复——异常假设
一旦Leader服务器出现崩溃或者由于网络原因导致Leader服务器失去了与过半 Follower的联系,那么就会进入崩溃恢复模式。
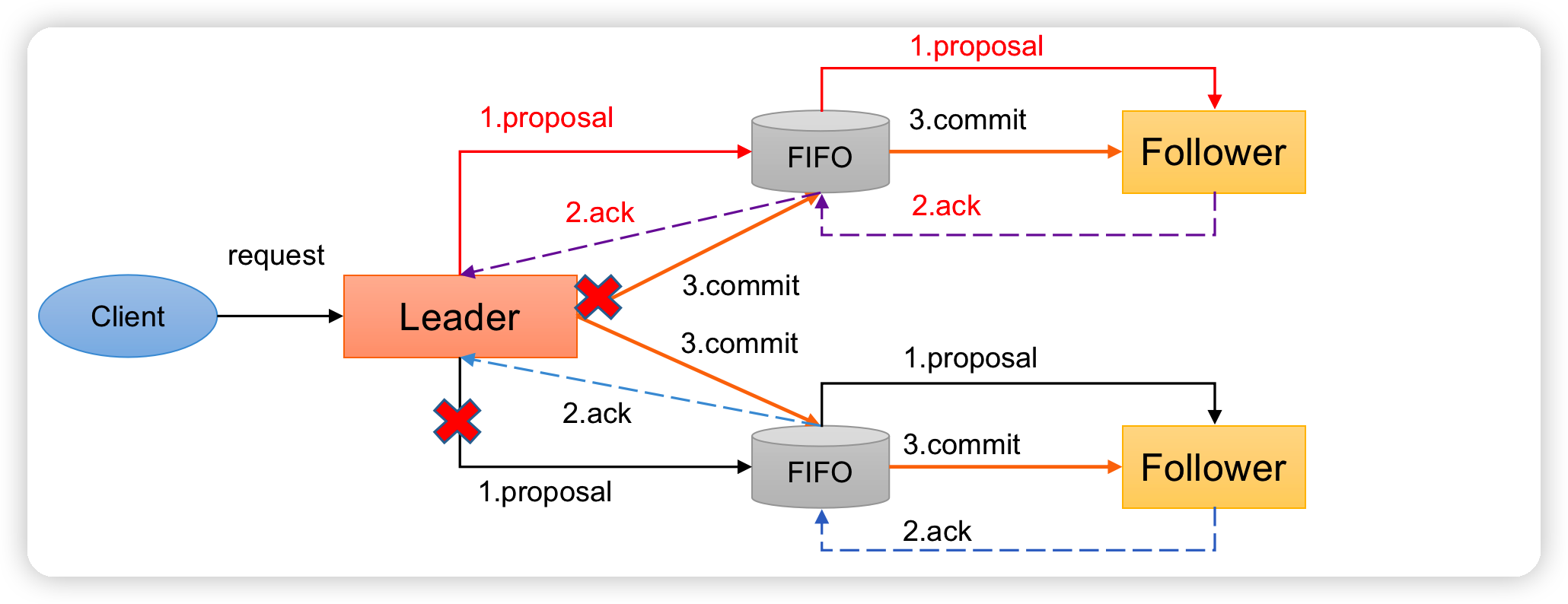
-
假设两种服务器异常情况:
- 假设一个事务在Leader提出之后,Leader挂了。
- 一个事务在Leader上提交了,并且过半的Follower都响应Ack了,但是Leader在Commit消息发出之前挂了。
-
Zab协议崩溃恢复要求满足以下两个要求:
- 确保已经被Leader提交的提案Proposal,必须最终被所有的Follower服务器提交。 (已经产生的提案,Follower必须执行)
- 确保丢弃已经被Leader提出的,但是没有被提交的Proposal。(丢弃胎死腹中的提案)
崩溃恢复——Leader选举
崩溃恢复主要包括两部分:Leader选举和数据恢复。
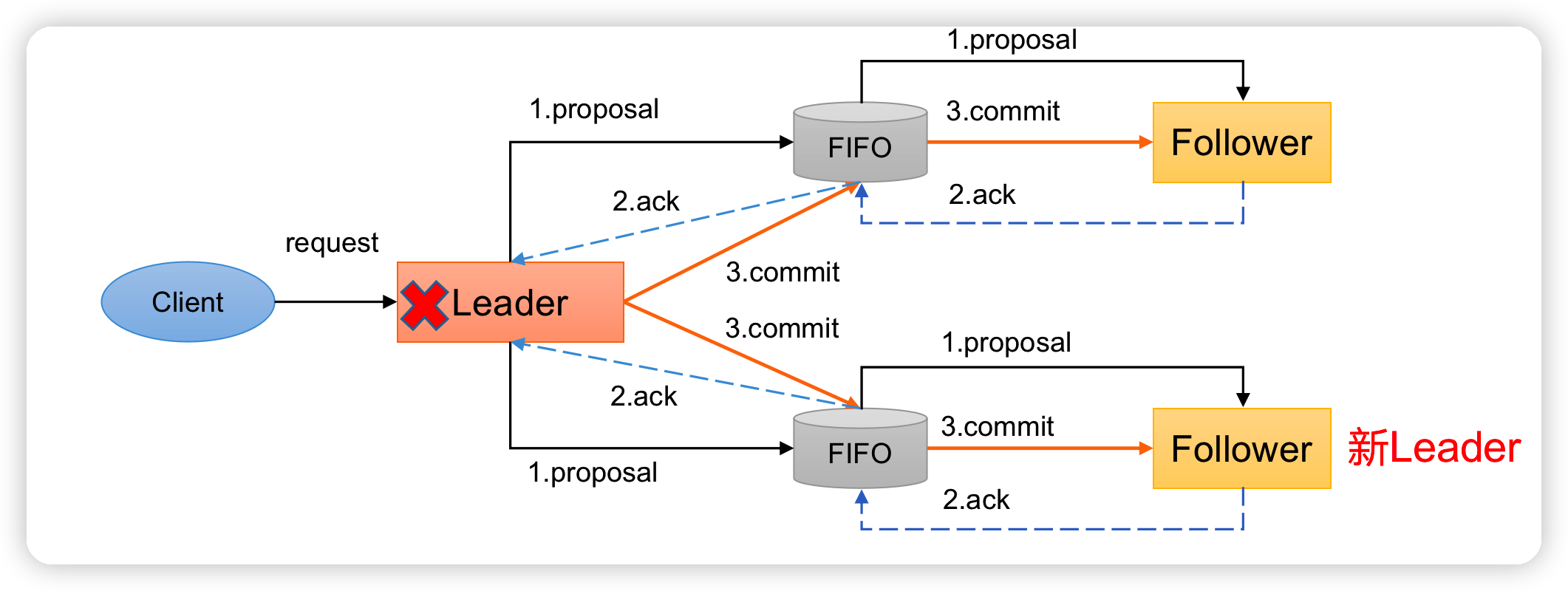
- Leader选举:根据上述要求,Zab协议需要保证选举出来的Leader需要满足以下条件:
- (1)新选举出来的Leader不能包含未提交的Proposal。即新Leader必须都是已经提交了Proposal的Follower服务器节点。
- (2)新选举的Leader节点中含有最大的zxid。这样做的好处是可以避免Leader服务器检查Proposal的提交和丢弃工作。
崩溃恢复——数据恢复
崩溃恢复主要包括两部分:Leader选举和数据恢复。
- Zab如何数据同步:
- (1)完成Leader选举后,在正式开始工作之前(接收事务请求,然后提出新的Proposal),Leader服务器会首先确认事务日志中的所有的Proposal 是否已经被集群中过半的服务器Commit。
- (2)Leader服务器需要确保所有的Follower服务器能够接收到每一条事务的Proposal,并且能将所有已经提交的事务Proposal应用到内存数据中。等到Follower将所有尚未同步的事务Proposal都从Leader服务器上同步过,并且应用到内存数据中以后,Leader才会把该Follower加入到真正可用的Follower列表中。
1.4 CAP
CAP理论告诉我们,一个分布式系统不可能同时满足以下三种
- 一致性(C:Consistency)
- 可用性(A:Available)
- 分区容错性(P:Partition Tolerance)
这三个基本需求,最多只能同时满足其中的两项,因为P是必须的,因此往往选择就在CP或者AP中。
1)一致性(C:Consistency):在分布式环境中,一致性是指数据在多个副本之间是否能够保持数据一致的特性。在一致性的需求下,当一个系统在数据一致的状态下执行更新操作后,应该保证系统的数据仍然处于一致的状态。
2)可用性(A:Available):可用性是指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。
3)分区容错性(P:Partition Tolerance):分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。
ZooKeeper保证的是CP
(1)ZooKeeper不能保证每次服务请求的可用性。(注:在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果)。所以说,ZooKeeper不能保证服务可用性。
(2)进行Leader选举时集群都是不可用。
第2章 源码详解
2.1 辅助源码
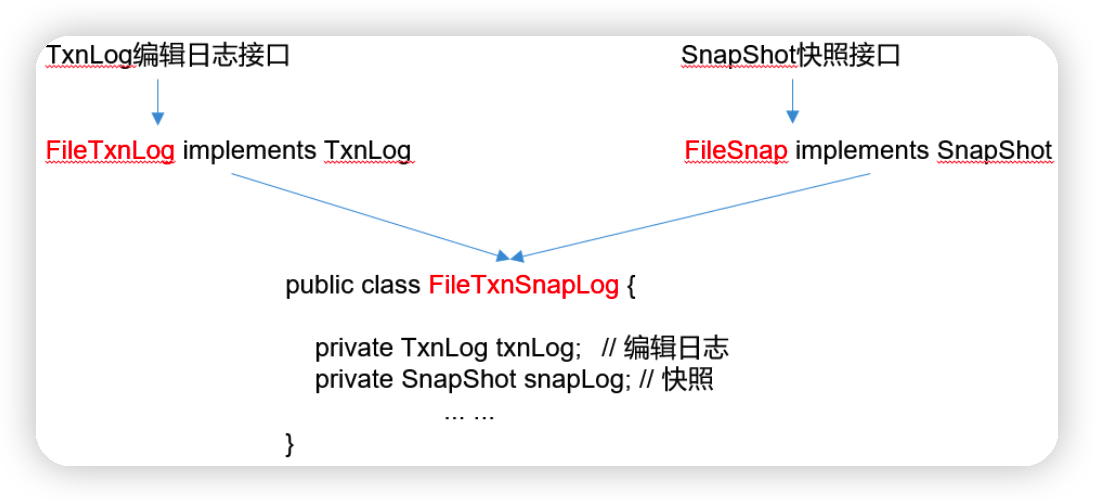
2.1.1 持久化源码
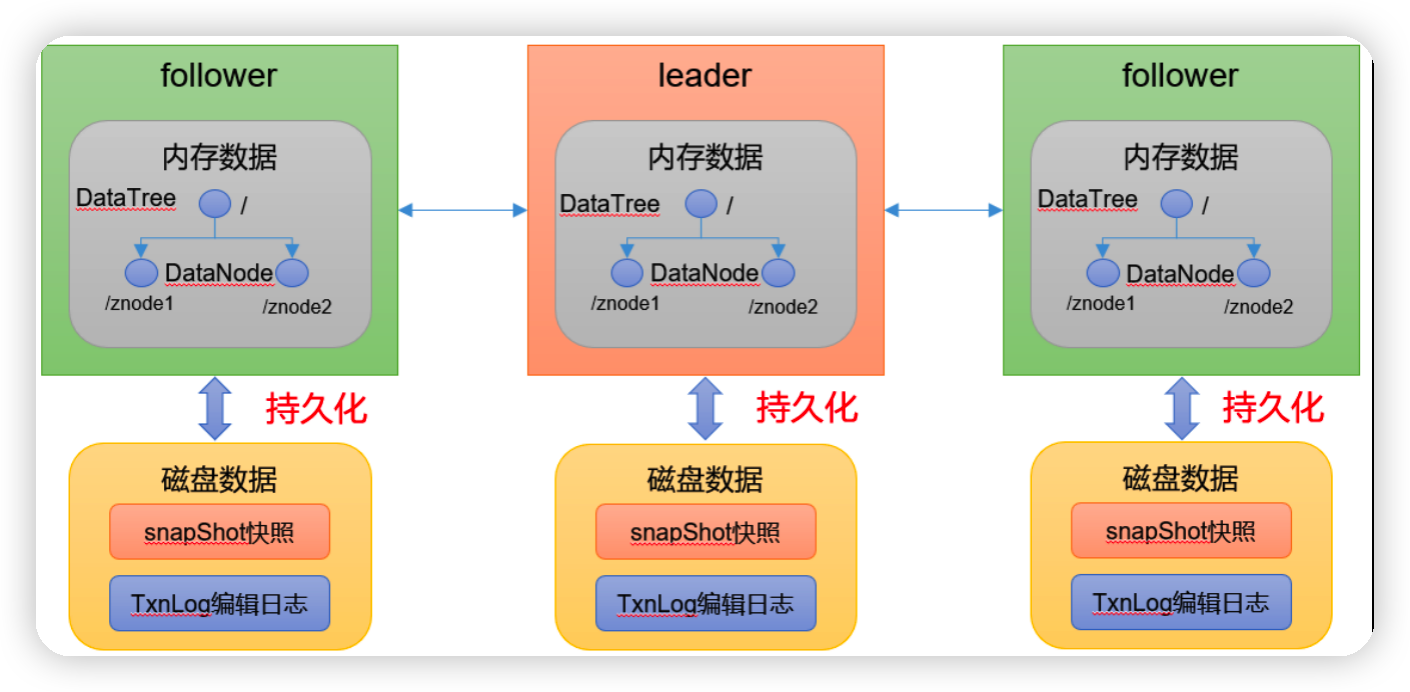
Leader和Follower中的数据会在内存和磁盘中各保存一份。所以需要将内存中的数据持久化到磁盘中。
在org.apache.zookeeper.server.persistence包下的相关类都是序列化相关的代码。
1)快照
public interface SnapShot {
// 反序列化方法
long deserialize(DataTree dt, Map<Long, Integer> sessions)
throws IOException;
// 序列化方法
void serialize(DataTree dt, Map<Long, Integer> sessions,
File name)
throws IOException;
/
* find the most recent snapshot file
* 查找最近的快照文件
*/
File findMostRecentSnapshot() throws IOException;
// 释放资源
void close() throws IOException;
}
2)操作日志
public interface TxnLog {
// 设置服务状态
void setServerStats(ServerStats serverStats);
// 滚动日志
void rollLog() throws IOException;
// 追加
boolean append(TxnHeader hdr, Record r) throws IOException;
// 读取数据
TxnIterator read(long zxid) throws IOException;
// 获取最后一个zxid
long getLastLoggedZxid() throws IOException;
// 删除日志
boolean truncate(long zxid) throws IOException;
// 获取DbId
long getDbId() throws IOException;
// 提交
void commit() throws IOException;
// 日志同步时间
long getTxnLogSyncElapsedTime();
// 关闭日志
void close() throws IOException;
// 读取日志的接口
public interface TxnIterator {
// 获取头信息
TxnHeader getHeader();
// 获取传输的内容
Record getTxn();
// 下一条记录
boolean next() throws IOException;
// 关闭资源
void close() throws IOException;
// 获取存储的大小
long getStorageSize() throws IOException;
}
}
3)处理持久化的核心类
2.1.2 序列化源码
zookeeper-jute代码是关于Zookeeper序列化相关源码
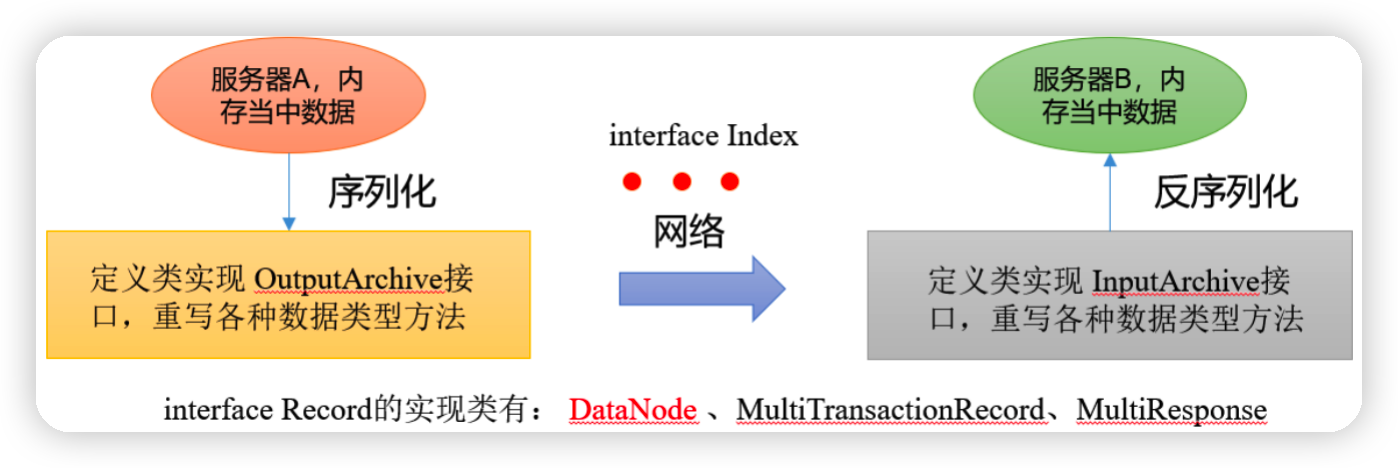
1)序列化和反序列化方法
public interface Record {
// 序列化方法
public void serialize(OutputArchive archive, String tag)
throws IOException;
// 反序列化方法
public void deserialize(InputArchive archive, String tag)
throws IOException;
}
2)迭代
public interface Index {
// 结束
public boolean done();
// 下一个
public void incr();
}
3)序列化支持的数据类型
/
* Interface that alll the serializers have to implement.
*
*/
public interface OutputArchive {
public void writeByte(byte b, String tag) throws IOException;
public void writeBool(boolean b, String tag) throws IOException;
public void writeInt(int i, String tag) throws IOException;
public void writeLong(long l, String tag) throws IOException;
public void writeFloat(float f, String tag) throws IOException;
public void writeDouble(double d, String tag) throws IOException;
public void writeString(String s, String tag) throws IOException;
public void writeBuffer(byte buf[], String tag)
throws IOException;
public void writeRecord(Record r, String tag) throws IOException;
public void startRecord(Record r, String tag) throws IOException;
public void endRecord(Record r, String tag) throws IOException;
public void startVector(List<?> v, String tag) throws IOException;
public void endVector(List<?> v, String tag) throws IOException;
public void startMap(TreeMap<?,?> v, String tag) throws IOException;
public void endMap(TreeMap<?,?> v, String tag) throws IOException;
}
4)反序列化支持的数据类型
/
* Interface that all the Deserializers have to implement.
*
*/
public interface InputArchive {
public byte readByte(String tag) throws IOException;
public boolean readBool(String tag) throws IOException;
public int readInt(String tag) throws IOException;
public long readLong(String tag) throws IOException;
public float readFloat(String tag) throws IOException;
public double readDouble(String tag) throws IOException;
public String readString(String tag) throws IOException;
public byte[] readBuffer(String tag) throws IOException;
public void readRecord(Record r, String tag) throws IOException;
public void startRecord(String tag) throws IOException;
public void endRecord(String tag) throws IOException;
public Index startVector(String tag) throws IOException;
public void endVector(String tag) throws IOException;
public Index startMap(String tag) throws IOException;
public void endMap(String tag) throws IOException;
}
2.2 ZK服务端初始化源码解析
ZK服务端初始化源码解析
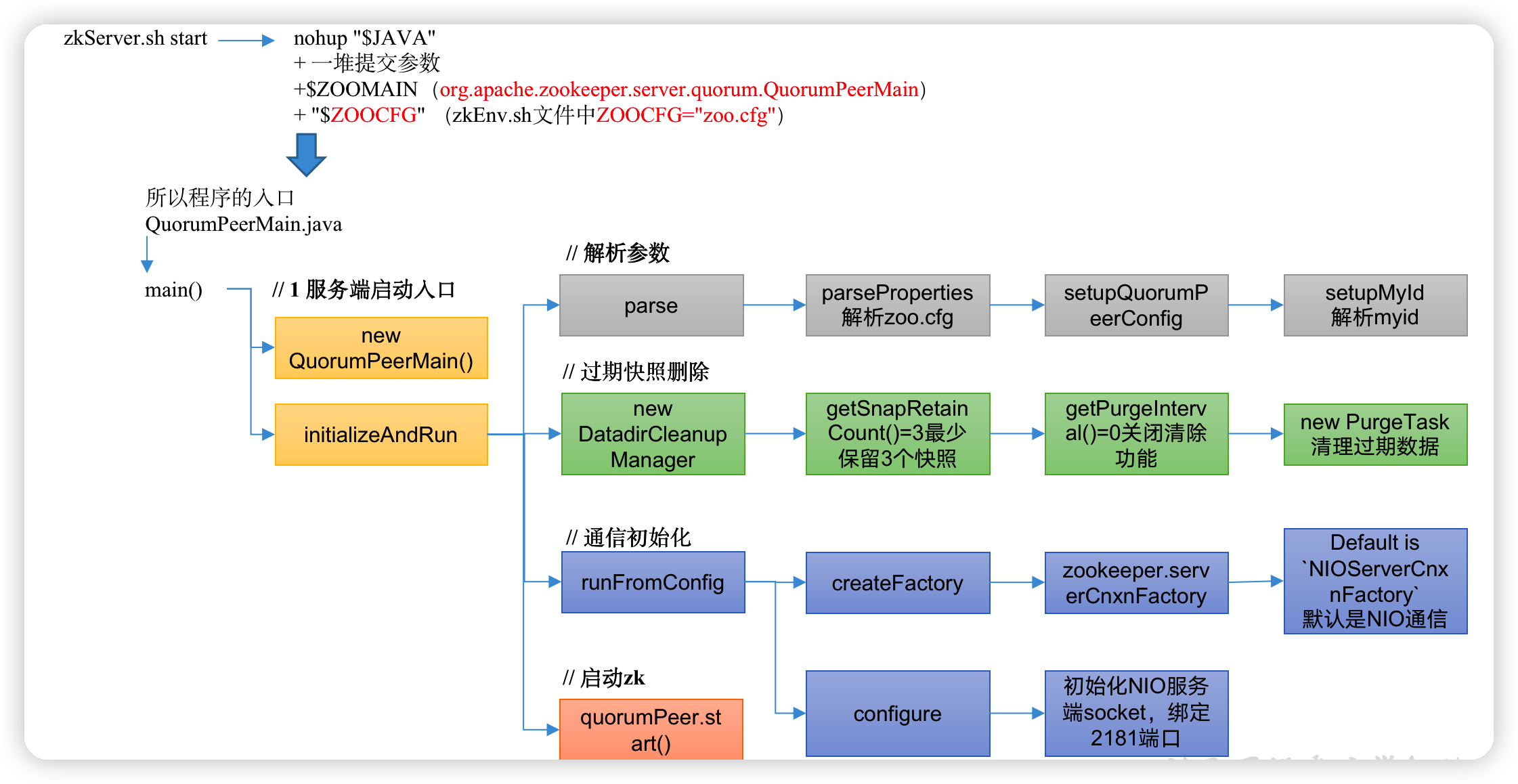
2.2.1 ZK服务端启动脚本分析
1)Zookeeper服务的启动命令是zkServer.sh start
zkServer.sh
#!/usr/bin/env bash
# use POSTIX interface, symlink is followed automatically
ZOOBIN="${BASH_SOURCE-$0}"
ZOOBIN="$(dirname "${ZOOBIN}")"
ZOOBINDIR="$(cd "${ZOOBIN}"; pwd)"
if [ -e "$ZOOBIN/../libexec/zkEnv.sh" ]; then
. "$ZOOBINDIR"/../libexec/zkEnv.sh
else
. "$ZOOBINDIR"/zkEnv.sh //相当于获取zkEnv.sh中的环境变量(ZOOCFG="zoo.cfg")
fi
# See the following page for extensive details on setting
# up the JVM to accept JMX remote management:
# http://java.sun.com/javase/6/docs/technotes/guides/management/agent.html
# by default we allow local JMX connections
if [ "x$JMXLOCALONLY" = "x" ]
then
JMXLOCALONLY=false
fi
if [ "x$JMXDISABLE" = "x" ] || [ "$JMXDISABLE" = 'false' ]
then
echo "ZooKeeper JMX enabled by default" >&2
if [ "x$JMXPORT" = "x" ]
then
# for some reason these two options are necessary on jdk6 on Ubuntu
# accord to the docs they are not necessary, but otw jconsole cannot
# do a local attach
ZOOMAIN="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.local.only=$JMXLOCALONLY org.apache.zookeeper.server.quorum.QuorumPeerMain"
else
if [ "x$JMXAUTH" = "x" ]
then
JMXAUTH=false
fi
if [ "x$JMXSSL" = "x" ]
then
JMXSSL=false
fi
if [ "x$JMXLOG4J" = "x" ]
then
JMXLOG4J=true
fi
echo "ZooKeeper remote JMX Port set to $JMXPORT" >&2
echo "ZooKeeper remote JMX authenticate set to $JMXAUTH" >&2
echo "ZooKeeper remote JMX ssl set to $JMXSSL" >&2
echo "ZooKeeper remote JMX log4j set to $JMXLOG4J" >&2
ZOOMAIN="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=$JMXPORT -Dcom.sun.management.jmxremote.authenticate=$JMXAUTH -Dcom.sun.management.jmxremote.ssl=$JMXSSL -Dzookeeper.jmx.log4j.disable=$JMXLOG4J org.apache.zookeeper.server.quorum.QuorumPeerMain"
fi
else
echo "JMX disabled by user request" >&2
ZOOMAIN="org.apache.zookeeper.server.quorum.QuorumPeerMain"
fi
if [ "x$SERVER_JVMFLAGS" != "x" ]
then
JVMFLAGS="$SERVER_JVMFLAGS $JVMFLAGS"
fi
… …
case $1 in
start)
echo -n "Starting zookeeper ... "
if [ -f "$ZOOPIDFILE" ]; then
if kill -0 `cat "$ZOOPIDFILE"` > /dev/null 2>&1; then
echo $command already running as process `cat "$ZOOPIDFILE"`.
exit 1
fi
fi
nohup "$JAVA" $ZOO_DATADIR_AUTOCREATE "-Dzookeeper.log.dir=${ZOO_LOG_DIR}"
"-Dzookeeper.log.file=${ZOO_LOG_FILE}" "-Dzookeeper.root.logger=${ZOO_LOG4J_PROP}"
-XX:+HeapDumpOnOutOfMemoryError -XX:OnOutOfMemoryError='kill -9 %p'
-cp "$CLASSPATH" $JVMFLAGS $ZOOMAIN "$ZOOCFG" > "$_ZOO_DAEMON_OUT" 2>&1 < /dev/null &
… …
;;
stop)
echo -n "Stopping zookeeper ... "
if [ ! -f "$ZOOPIDFILE" ]
then
echo "no zookeeper to stop (could not find file $ZOOPIDFILE)"
else
$KILL $(cat "$ZOOPIDFILE")
rm "$ZOOPIDFILE"
sleep 1
echo STOPPED
fi
exit 0
;;
restart)
shift
"$0" stop ${@}
sleep 3
"$0" start ${@}
;;
status)
… …
;;
*)
echo "Usage: $0 [--config <conf-dir>] {start|start-foreground|stop|restart|status|print-cmd}" >&2
esac
2)zkServer.sh start底层的实际执行内容
nohup "$JAVA"
+ 一堆提交参数
+ $ZOOMAIN(org.apache.zookeeper.server.quorum.QuorumPeerMain)
+ "$ZOOCFG" (zkEnv.sh文件中ZOOCFG="zoo.cfg")
3)所以程序的入口是QuorumPeerMain.java类
2.2.2 ZK服务端启动入口
1)ctrl + n,查找QuorumPeerMain
QuorumPeerMain.java
public static void main(String[] args) {
// 创建了一个zk节点
QuorumPeerMain main = new QuorumPeerMain();
try {
// 初始化节点并运行,args相当于提交参数中的zoo.cfg
main.initializeAndRun(args);
} catch (IllegalArgumentException e) {
... ...
}
LOG.info("Exiting normally");
System.exit(0);
}
2)initializeAndRun
protected void initializeAndRun(String[] args)
throws ConfigException, IOException, AdminServerException
{
// 管理zk的配置信息
QuorumPeerConfig config = new QuorumPeerConfig();
if (args.length == 1) {
// 1解析参数,zoo.cfg和myid
config.parse(args[0]);
}
// 2启动定时任务,对过期的快照,执行删除(默认该功能关闭)
// Start and schedule the the purge task
DatadirCleanupManager purgeMgr = new DatadirCleanupManager(config
.getDataDir(), config.getDataLogDir(), config
.getSnapRetainCount(), config.getPurgeInterval());
purgeMgr.start();
if (args.length == 1 && config.isDistributed()) {
// 3 启动集群
runFromConfig(config);
} else {
LOG.warn("Either no config or no quorum defined in config, running "
+ " in standalone mode");
// there is only server in the quorum -- run as standalone
ZooKeeperServerMain.main(args);
}
}
2.2.3 解析参数zoo.cfg和myid
QuorumPeerConfig.java
public void parse(String path) throws ConfigException {
LOG.info("Reading configuration from: " + path);
try {
// 校验文件路径及是否存在
File configFile = (new VerifyingFileFactory.Builder(LOG)
.warnForRelativePath()
.failForNonExistingPath()
.build()).create(path);
Properties cfg = new Properties();
FileInputStream in = new FileInputStream(configFile);
try {
// 加载配置文件
cfg.load(in);
configFileStr = path;
} finally {
in.close();
}
// 解析配置文件
parseProperties(cfg);
} catch (IOException e) {
throw new ConfigException("Error processing " + path, e);
} catch (IllegalArgumentException e) {
throw new ConfigException("Error processing " + path, e);
}
... ...
}
QuorumPeerConfig.java
public void parseProperties(Properties zkProp)
throws IOException, ConfigException {
int clientPort = 0;
int secureClientPort = 0;
String clientPortAddress = null;
String secureClientPortAddress = null;
VerifyingFileFactory vff = new VerifyingFileFactory.Builder(LOG).warnForRelativePath().build();
// 读取zoo.cfg文件中的属性值,并赋值给QuorumPeerConfig的类对象
for (Entry<Object, Object> entry : zkProp.entrySet()) {
String key = entry.getKey().toString().trim();
String value = entry.getValue().toString().trim();
if (key.equals("dataDir")) {
dataDir = vff.create(value);
} else if (key.equals("dataLogDir")) {
dataLogDir = vff.create(value);
} else if (key.equals("clientPort")) {
clientPort = Integer.parseInt(value);
} else if (key.equals("localSessionsEnabled")) {
localSessionsEnabled = Boolean.parseBoolean(value);
} else if (key.equals("localSessionsUpgradingEnabled")) {
localSessionsUpgradingEnabled = Boolean.parseBoolean(value);
} else if (key.equals("clientPortAddress")) {
clientPortAddress = value.trim();
} else if (key.equals("secureClientPort")) {
secureClientPort = Integer.parseInt(value);
} else if (key.equals("secureClientPortAddress")){
secureClientPortAddress = value.trim();
} else if (key.equals("tickTime")) {
tickTime = Integer.parseInt(value);
} else if (key.equals("maxClientCnxns")) {
maxClientCnxns = Integer.parseInt(value);
} else if (key.equals("minSessionTimeout")) {
minSessionTimeout = Integer.parseInt(value);
}
... ...
}
... ...
if (dynamicConfigFileStr == null) {
setupQuorumPeerConfig(zkProp, true);
if (isDistributed() && isReconfigEnabled()) {
// we don't backup static config for standalone mode.
// we also don't backup if reconfig feature is disabled.
backupOldConfig();
}
}
}
QuorumPeerConfig.java
void setupQuorumPeerConfig(Properties prop, boolean configBackwardCompatibilityMode)
throws IOException, ConfigException {
quorumVerifier = parseDynamicConfig(prop, electionAlg, true, configBackwardCompatibilityMode);
setupMyId();
setupClientPort();
setupPeerType();
checkValidity();
}
QuorumPeerConfig.java
private void setupMyId() throws IOException {
File myIdFile = new File(dataDir, "myid");
// standalone server doesn't need myid file.
if (!myIdFile.isFile()) {
return;
}
BufferedReader br = new BufferedReader(new FileReader(myIdFile));
String myIdString;
try {
myIdString = br.readLine();
} finally {
br.close();
}
try {
// 将解析myid文件中的id赋值给serverId
serverId = Long.parseLong(myIdString);
MDC.put("myid", myIdString);
} catch (NumberFormatException e) {
throw new IllegalArgumentException("serverid " + myIdString
+ " is not a number");
}
}
2.2.4 过期快照删除
可以启动定时任务,对过期的快照,执行删除。默认该功能时关闭的
protected void initializeAndRun(String[] args)
throws ConfigException, IOException, AdminServerException
{
// 管理zk的配置信息
QuorumPeerConfig config = new QuorumPeerConfig();
if (args.length == 1) {
// 1解析参数,zoo.cfg和myid
config.parse(args[0]);
}
// 2启动定时任务,对过期的快照,执行删除(默认是关闭)
// config.getSnapRetainCount() = 3 最少保留的快照个数
// config.getPurgeInterval() = 0 默认0表示关闭
// Start and schedule the the purge task
DatadirCleanupManager purgeMgr = new DatadirCleanupManager(config
.getDataDir(), config.getDataLogDir(), config
.getSnapRetainCount(), config.getPurgeInterval());
purgeMgr.start();
if (args.length == 1 && config.isDistributed()) {
// 3 启动集群
runFromConfig(config);
} else {
LOG.warn("Either no config or no quorum defined in config, running "
+ " in standalone mode");
// there is only server in the quorum -- run as standalone
ZooKeeperServerMain.main(args);
}
}
protected int snapRetainCount = 3;
protected int purgeInterval = 0;
public void start() {
if (PurgeTaskStatus.STARTED == purgeTaskStatus) {
LOG.warn("Purge task is already running.");
return;
}
// 默认情况purgeInterval=0,该任务关闭,直接返回
// Don't schedule the purge task with zero or negative purge interval.
if (purgeInterval <= 0) {
LOG.info("Purge task is not scheduled.");
return;
}
// 创建一个定时器
timer = new Timer("PurgeTask", true);
// 创建一个清理快照任务
TimerTask task = new PurgeTask(dataLogDir, snapDir, snapRetainCount);
// 如果purgeInterval设置的值是1,表示1小时检查一次,判断是否有过期快照,有则删除
timer.scheduleAtFixedRate(task, 0, TimeUnit.HOURS.toMillis(purgeInterval));
purgeTaskStatus = PurgeTaskStatus.STARTED;
}
static class PurgeTask extends TimerTask {
private File logsDir;
private File snapsDir;
private int snapRetainCount;
public PurgeTask(File dataDir, File snapDir, int count) {
logsDir = dataDir;
snapsDir = snapDir;
snapRetainCount = count;
}
@Override
public void run() {
LOG.info("Purge task started.");
try {
// 清理过期的数据
PurgeTxnLog.purge(logsDir, snapsDir, snapRetainCount);
} catch (Exception e) {
LOG.error("Error occurred while purging.", e);
}
LOG.info("Purge task completed.");
}
}
public static void purge(File dataDir, File snapDir, int num) throws IOException {
if (num < 3) {
throw new IllegalArgumentException(COUNT_ERR_MSG);
}
FileTxnSnapLog txnLog = new FileTxnSnapLog(dataDir, snapDir);
List<File> snaps = txnLog.findNRecentSnapshots(num);
int numSnaps = snaps.size();
if (numSnaps > 0) {
purgeOlderSnapshots(txnLog, snaps.get(numSnaps - 1));
}
}
2.2.5 初始化通信组件
protected void initializeAndRun(String[] args)
throws ConfigException, IOException, AdminServerException
{
// 管理zk的配置信息
QuorumPeerConfig config = new QuorumPeerConfig();
if (args.length == 1) {
// 1解析参数,zoo.cfg和myid
config.parse(args[0]);
}
// 2启动定时任务,对过期的快照,执行删除(默认是关闭)
// config.getSnapRetainCount() = 3 最少保留的快照个数
// config.getPurgeInterval() = 0 默认0表示关闭
// Start and schedule the the purge task
DatadirCleanupManager purgeMgr = new DatadirCleanupManager(config
.getDataDir(), config.getDataLogDir(), config
.getSnapRetainCount(), config.getPurgeInterval());
purgeMgr.start();
if (args.length == 1 && config.isDistributed()) {
// 3 启动集群(集群模式)
runFromConfig(config);
} else {
LOG.warn("Either no config or no quorum defined in config, running "
+ " in standalone mode");
// there is only server in the quorum -- run as standalone
// 本地模式
ZooKeeperServerMain.main(args);
}
}
1)通信协议默认NIO(可以支持Netty)
public void runFromConfig(QuorumPeerConfig config)
throws IOException, AdminServerException
{
… …
LOG.info("Starting quorum peer");
try {
ServerCnxnFactory cnxnFactory = null;
ServerCnxnFactory secureCnxnFactory = null;
// 通信组件初始化,默认是NIO通信
if (config.getClientPortAddress() != null) {
cnxnFactory = ServerCnxnFactory.createFactory();
cnxnFactory.configure(config.getClientPortAddress(),
config.getMaxClientCnxns(), false);
}
if (config.getSecureClientPortAddress() != null) {
secureCnxnFactory = ServerCnxnFactory.createFactory();
secureCnxnFactory.configure(config.getSecureClientPortAddress(),
config.getMaxClientCnxns(), true);
}
// 把解析的参数赋值给该zookeeper节点
quorumPeer = getQuorumPeer();
quorumPeer.setTxnFactory(new FileTxnSnapLog(
config.getDataLogDir(),
config.getDataDir()));
quorumPeer.enableLocalSessions(config.areLocalSessionsEnabled());
quorumPeer.enableLocalSessionsUpgrading(
config.isLocalSessionsUpgradingEnabled());
//quorumPeer.setQuorumPeers(config.getAllMembers());
quorumPeer.setElectionType(config.getElectionAlg());
quorumPeer.setMyid(config.getServerId());
quorumPeer.setTickTime(config.getTickTime());
quorumPeer.setMinSessionTimeout(config.getMinSessionTimeout());
quorumPeer.setMaxSessionTimeout(config.getMaxSessionTimeout());
quorumPeer.setInitLimit(config.getInitLimit());
quorumPeer.setSyncLimit(config.getSyncLimit());
quorumPeer.setConfigFileName(config.getConfigFilename());
// 管理zk数据的存储
quorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory()));
quorumPeer.setQuorumVerifier(config.getQuorumVerifier(), false);
if (config.getLastSeenQuorumVerifier()!=null) {
quorumPeer.setLastSeenQuorumVerifier(config.getLastSeenQuorumVerifier(), false);
}
quorumPeer.initConfigInZKDatabase();
// 管理zk的通信
quorumPeer.setCnxnFactory(cnxnFactory);
quorumPeer.setSecureCnxnFactory(secureCnxnFactory);
quorumPeer.setSslQuorum(config.isSslQuorum());
quorumPeer.setUsePortUnification(config.shouldUsePortUnification());
quorumPeer.setLearnerType(config.getPeerType());
quorumPeer.setSyncEnabled(config.getSyncEnabled());
quorumPeer.setQuorumListenOnAllIPs(config.getQuorumListenOnAllIPs());
if (config.sslQuorumReloadCertFiles) {
quorumPeer.getX509Util().enableCertFileReloading();
}
… …
quorumPeer.setQuorumCnxnThreadsSize(config.quorumCnxnThreadsSize);
quorumPeer.initialize();
// 启动zk
quorumPeer.start();
quorumPeer.join();
} catch (InterruptedException e) {
// warn, but generally this is ok
LOG.warn("Quorum Peer interrupted", e);
}
}
static public ServerCnxnFactory createFactory() throws IOException {
String serverCnxnFactoryName =
System.getProperty(ZOOKEEPER_SERVER_CNXN_FACTORY);
if (serverCnxnFactoryName == null) {
serverCnxnFactoryName = NIOServerCnxnFactory.class.getName();
}
try {
ServerCnxnFactory serverCnxnFactory = (ServerCnxnFactory) Class.forName(serverCnxnFactoryName)
.getDeclaredConstructor().newInstance();
LOG.info("Using {} as server connection factory", serverCnxnFactoryName);
return serverCnxnFactory;
} catch (Exception e) {
IOException ioe = new IOException("Couldn't instantiate "
+ serverCnxnFactoryName);
ioe.initCause(e);
throw ioe;
}
}
public static final String ZOOKEEPER_SERVER_CNXN_FACTORY = "zookeeper.serverCnxnFactory";
zookeeperAdmin.md 文件中
* *serverCnxnFactory* :
(Java system property: zookeeper.serverCnxnFactory)
Specifies ServerCnxnFactory implementation.
This should be set to `NettyServerCnxnFactory` in order to use TLS based server communication.
Default is `NIOServerCnxnFactory`.
2)初始化NIO服务端Socket(并未启动)
ctrl + alt +B 查找configure实现类,NIOServerCnxnFactory.java
public void configure(InetSocketAddress addr, int maxcc, boolean secure) throws IOException {
if (secure) {
throw new UnsupportedOperationException("SSL isn't supported in NIOServerCnxn");
}
configureSaslLogin();
maxClientCnxns = maxcc;
sessionlessCnxnTimeout = Integer.getInteger(
ZOOKEEPER_NIO_SESSIONLESS_CNXN_TIMEOUT, 10000);
// We also use the sessionlessCnxnTimeout as expiring interval for
// cnxnExpiryQueue. These don't need to be the same, but the expiring
// interval passed into the ExpiryQueue() constructor below should be
// less than or equal to the timeout.
cnxnExpiryQueue =
new ExpiryQueue<NIOServerCnxn>(sessionlessCnxnTimeout);
expirerThread = new ConnectionExpirerThread();
int numCores = Runtime.getRuntime().availableProcessors();
// 32 cores sweet spot seems to be 4 selector threads
numSelectorThreads = Integer.getInteger(
ZOOKEEPER_NIO_NUM_SELECTOR_THREADS,
Math.max((int) Math.sqrt((float) numCores/2), 1));
if (numSelectorThreads < 1) {
throw new IOException("numSelectorThreads must be at least 1");
}
numWorkerThreads = Integer.getInteger(
ZOOKEEPER_NIO_NUM_WORKER_THREADS, 2 * numCores);
workerShutdownTimeoutMS = Long.getLong(
ZOOKEEPER_NIO_SHUTDOWN_TIMEOUT, 5000);
... ...
for(int i=0; i<numSelectorThreads; ++i) {
selectorThreads.add(new SelectorThread(i));
}
// 初始化NIO服务端socket,绑定2181端口,可以接收客户端请求
this.ss = ServerSocketChannel.open();
ss.socket().setReuseAddress(true);
LOG.info("binding to port " + addr);
// 绑定2181端口
ss.socket().bind(addr);
ss.configureBlocking(false);
acceptThread = new AcceptThread(ss, addr, selectorThreads);
}
2.3 ZK服务端加载数据源码解析
(1)zk中的数据模型,是一棵树,DataTree,每个节点,叫做DataNode
(2)zk集群中的DataTree时刻保持状态同步
(3)Zookeeper集群中每个zk节点中,数据在内存和磁盘中都有一份完整的数据。
-
内存数据:DataTree
-
磁盘数据:快照文件 + 编辑日志
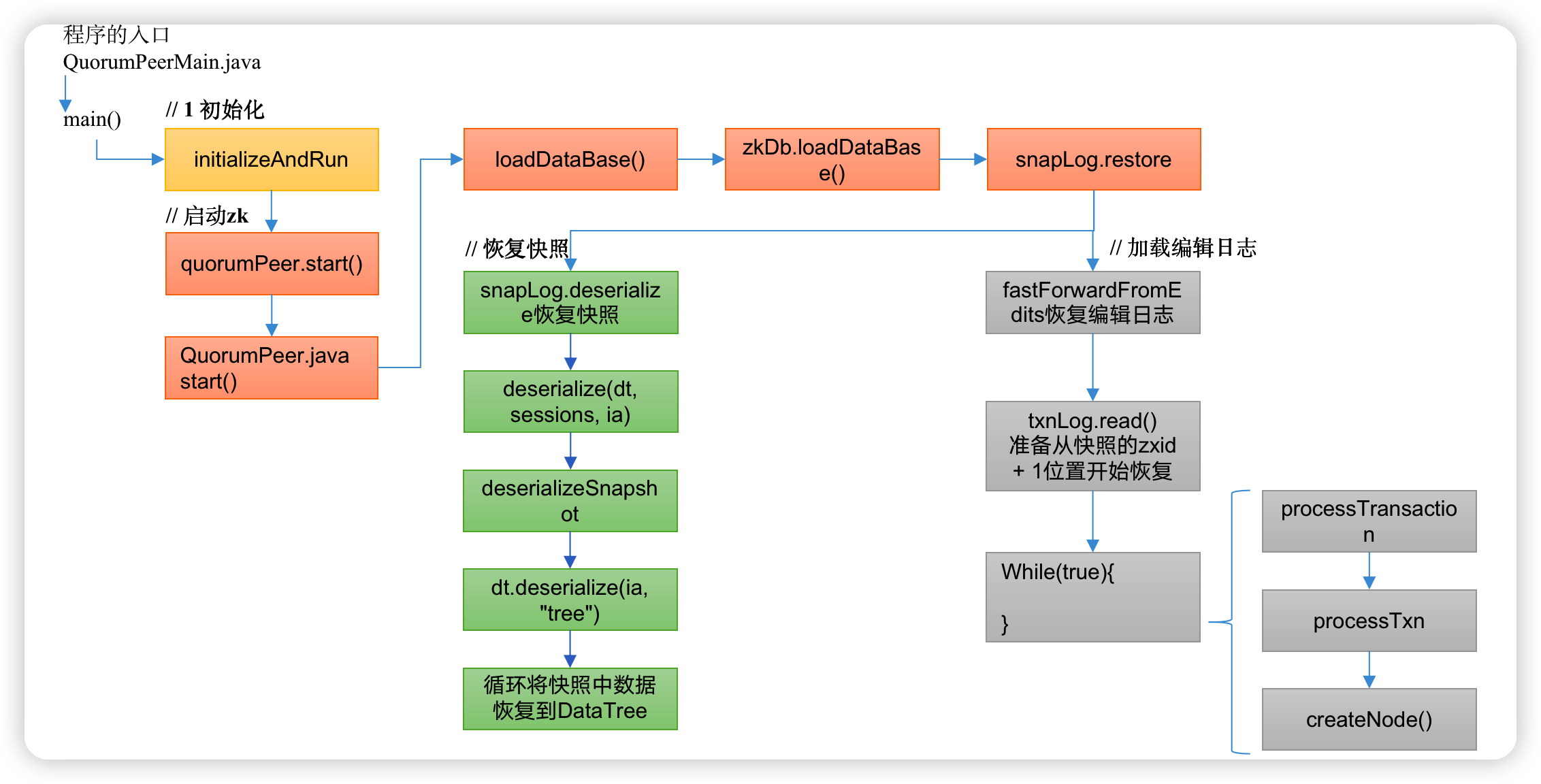
2.3.1 冷启动数据恢复快照数据
1)启动集群
public void runFromConfig(QuorumPeerConfig config)
throws IOException, AdminServerException
{
… …
LOG.info("Starting quorum peer");
try {
ServerCnxnFactory cnxnFactory = null;
ServerCnxnFactory secureCnxnFactory = null;
// 通信组件初始化,默认是NIO通信
if (config.getClientPortAddress() != null) {
cnxnFactory = ServerCnxnFactory.createFactory();
cnxnFactory.configure(config.getClientPortAddress(),
config.getMaxClientCnxns(), false);
}
if (config.getSecureClientPortAddress() != null) {
secureCnxnFactory = ServerCnxnFactory.createFactory();
secureCnxnFactory.configure(config.getSecureClientPortAddress(),
config.getMaxClientCnxns(), true);
}
// 把解析的参数赋值给该Zookeeper节点
quorumPeer = getQuorumPeer();
quorumPeer.setTxnFactory(new FileTxnSnapLog(
config.getDataLogDir(),
config.getDataDir()));
quorumPeer.enableLocalSessions(config.areLocalSessionsEnabled());
quorumPeer.enableLocalSessionsUpgrading(
config.isLocalSessionsUpgradingEnabled());
//quorumPeer.setQuorumPeers(config.getAllMembers());
quorumPeer.setElectionType(config.getElectionAlg());
quorumPeer.setMyid(config.getServerId());
quorumPeer.setTickTime(config.getTickTime());
quorumPeer.setMinSessionTimeout(config.getMinSessionTimeout());
quorumPeer.setMaxSessionTimeout(config.getMaxSessionTimeout());
quorumPeer.setInitLimit(config.getInitLimit());
quorumPeer.setSyncLimit(config.getSyncLimit());
quorumPeer.setConfigFileName(config.getConfigFilename());
// 管理zk数据的存储
quorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory()));
quorumPeer.setQuorumVerifier(config.getQuorumVerifier(), false);
if (config.getLastSeenQuorumVerifier()!=null) {
quorumPeer.setLastSeenQuorumVerifier(config.getLastSeenQuorumVerifier(), false);
}
quorumPeer.initConfigInZKDatabase();
// 管理zk的通信
quorumPeer.setCnxnFactory(cnxnFactory);
quorumPeer.setSecureCnxnFactory(secureCnxnFactory);
quorumPeer.setSslQuorum(config.isSslQuorum());
quorumPeer.setUsePortUnification(config.shouldUsePortUnification());
quorumPeer.setLearnerType(config.getPeerType());
quorumPeer.setSyncEnabled(config.getSyncEnabled());
quorumPeer.setQuorumListenOnAllIPs(config.getQuorumListenOnAllIPs());
if (config.sslQuorumReloadCertFiles) {
quorumPeer.getX509Util().enableCertFileReloading();
}
quorumPeer.setQuorumCnxnThreadsSize(config.quorumCnxnThreadsSize);
quorumPeer.initialize();
// 启动zk
quorumPeer.start();
quorumPeer.join();
} catch (InterruptedException e) {
// warn, but generally this is ok
LOG.warn("Quorum Peer interrupted", e);
}
}
2)冷启动恢复数据
QuorumPeer.java
public synchronized void start() {
if (!getView().containsKey(myid)) {
throw new RuntimeException("My id " + myid + " not in the peer list");
}
// 冷启动数据恢复
loadDataBase();
startServerCnxnFactory();
try {
// 启动通信工厂实例对象
adminServer.start();
} catch (AdminServerException e) {
LOG.warn("Problem starting AdminServer", e);
System.out.println(e);
}
// 准备选举环境
startLeaderElection();
// 执行选举
super.start();
}
private void loadDataBase() {
try {
// 加载磁盘数据到内存,恢复DataTree
// zk的操作分两种:事务操作和非事务操作
// 事务操作:zk.cteate();都会被分配一个全局唯一的zxid,zxid组成:64位: (前32位:epoch每个leader任期的代号;后32位:txid为事务id)
// 非事务操作:zk.getData()
// 数据恢复过程:
// (1)从快照文件中恢复大部分数据,并得到一个lastProcessZXid
// (2)再从编辑日志中执行replay,执行到最后一条日志并更新lastProcessZXid
// (3)最终得到,datatree和lastProcessZXid,表示数据恢复完成
zkDb.loadDataBase();
// load the epochs
long lastProcessedZxid = zkDb.getDataTree().lastProcessedZxid;
long epochOfZxid = ZxidUtils.getEpochFromZxid(lastProcessedZxid);
try {
currentEpoch = readLongFromFile(CURRENT_EPOCH_FILENAME);
} catch(FileNotFoundException e) {
// pick a reasonable epoch number
// this should only happen once when moving to a
// new code version
currentEpoch = epochOfZxid;
LOG.info(CURRENT_EPOCH_FILENAME
+ " not found! Creating with a reasonable default of {}. This should only happen when you are upgrading your installation",
currentEpoch);
writeLongToFile(CURRENT_EPOCH_FILENAME, currentEpoch);
}
if (epochOfZxid > currentEpoch) {
throw new IOException("The current epoch, " + ZxidUtils.zxidToString(currentEpoch) + ", is older than the last zxid, " + lastProcessedZxid);
}
try {
acceptedEpoch = readLongFromFile(ACCEPTED_EPOCH_FILENAME);
} catch(FileNotFoundException e) {
// pick a reasonable epoch number
// this should only happen once when moving to a
// new code version
acceptedEpoch = epochOfZxid;
LOG.info(ACCEPTED_EPOCH_FILENAME
+ " not found! Creating with a reasonable default of {}. This should only happen when you are upgrading your installation",
acceptedEpoch);
writeLongToFile(ACCEPTED_EPOCH_FILENAME, acceptedEpoch);
}
if (acceptedEpoch < currentEpoch) {
throw new IOException("The accepted epoch, " + ZxidUtils.zxidToString(acceptedEpoch) + " is less than the current epoch, " + ZxidUtils.zxidToString(currentEpoch));
}
} catch(IOException ie) {
LOG.error("Unable to load database on disk", ie);
throw new RuntimeException("Unable to run quorum server ", ie);
}
}
public long loadDataBase() throws IOException {
long zxid = snapLog.restore(dataTree, sessionsWithTimeouts, commitProposalPlaybackListener);
initialized = true;
return zxid;
}
public long restore(DataTree dt, Map<Long, Integer> sessions,
PlayBackListener listener) throws IOException {
// 恢复快照文件数据到DataTree
long deserializeResult = snapLog.deserialize(dt, sessions);
FileTxnLog txnLog = new FileTxnLog(dataDir);
RestoreFinalizer finalizer = () -> {
// 恢复编辑日志数据到DataTree
long highestZxid = fastForwardFromEdits(dt, sessions, listener);
return highestZxid;
};
if (-1L == deserializeResult) {
/* this means that we couldn't find any snapshot, so we need to
* initialize an empty database (reported in ZOOKEEPER-2325) */
if (txnLog.getLastLoggedZxid() != -1) {
// ZOOKEEPER-3056: provides an escape hatch for users upgrading
// from old versions of zookeeper (3.4.x, pre 3.5.3).
if (!trustEmptySnapshot) {
throw new IOException(EMPTY_SNAPSHOT_WARNING + "Something is broken!");
} else {
LOG.warn("{}This should only be allowed during upgrading.", EMPTY_SNAPSHOT_WARNING);
return finalizer.run();
}
}
/* TODO: (br33d) we should either put a ConcurrentHashMap on restore()
* or use Map on save() */
save(dt, (ConcurrentHashMap<Long, Integer>)sessions);
/* return a zxid of zero, since we the database is empty */
return 0;
}
return finalizer.run();
}
ctrl + alt +B 查找deserialize实现类FileSnap.java
public long deserialize(DataTree dt, Map<Long, Integer> sessions)
throws IOException {
// we run through 100 snapshots (not all of them)
// if we cannot get it running within 100 snapshots
// we should give up
List<File> snapList = findNValidSnapshots(100);
if (snapList.size() == 0) {
return -1L;
}
File snap = null;
boolean foundValid = false;
// 依次遍历每一个快照的数据
for (int i = 0, snapListSize = snapList.size(); i < snapListSize; i++) {
snap = snapList.get(i);
LOG.info("Reading snapshot "  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 624
624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









