









黑马人工智能AI就业班之支持向量机 网盘下载
文章最后 附上视频源码下载地址
支持向量机
学习目标:
1.理解SVM算法的思想
2.知道SVM中的硬间隔
3.理解SVM中的软间隔和惩罚系数
4.知道SVM中核函数的作用
【了解】小故事
在很久以前的情人节,大侠要去救他的爱人,但魔鬼和他玩了一个游戏。
魔鬼在桌子上似乎有规律放了两种颜色的球,说:
“你用一根棍分开它们?要求:尽量在放更多球之后,仍然适用。”
于是大侠这样放,干的不错?
然后魔鬼,又在桌上放了更多的球,似乎有一个球站错了阵营。
怎么办??
把分解的小棍儿变粗。
SVM就是试图把棍放在最佳位置,好让在棍的两边有尽可能大的间隙。
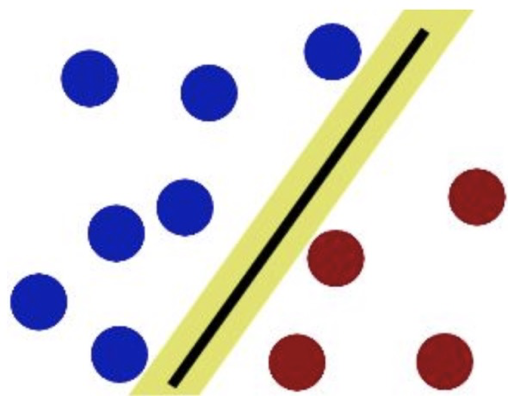
现在即使魔鬼放了更多的球,棍仍然是一个好的分界线。
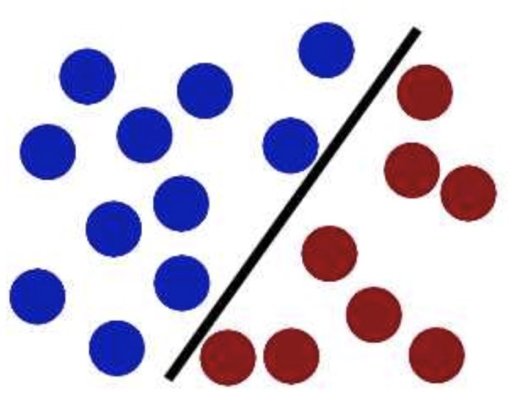
然后,在SVM 工具箱中有另一个更加重要的技巧( trick)。 魔鬼看到大侠已经学会了一个trick,于是魔鬼给了大侠一个新的挑战。
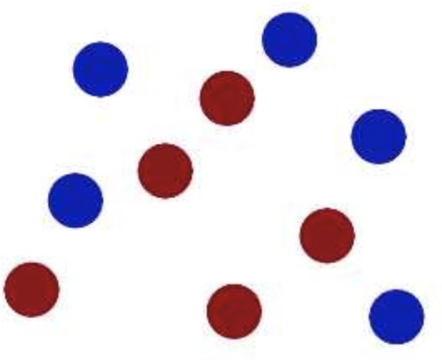
现在,大侠没有棍可以很好帮他分开两种球了,现在怎么办呢?
当然像所有武侠片中一样大侠桌子一拍,球飞到空中。然后,凭借大侠的轻功,大侠抓起一张纸,插到了两种球的中间。
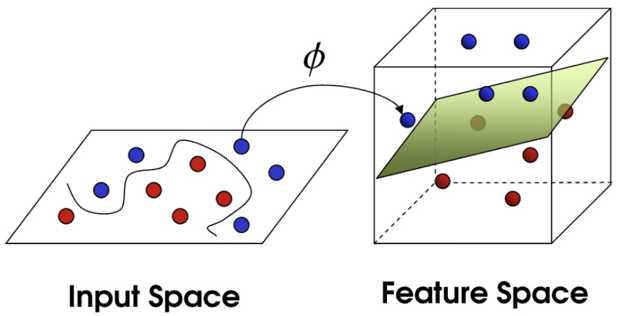
现在,从魔鬼的角度看这些球,这些球看起来像是被一条曲线分开了。
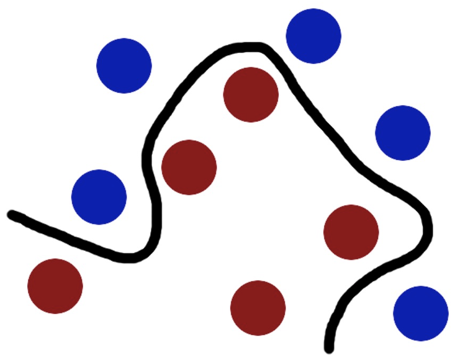
再之后,无聊的大人们,把上面的物体起了别名:
球—— 「data」数据
棍子—— 「classifier」分类
最大间隙——「optimization」最优化
拍桌子——「kernelling」核方法
纸——「hyperplane」超平面
案例来源:http://bytesizebio.net/2014/02/05/support-vector-machines-explained-well/
【理解】SVM的定义
SVM全称是supported vector machine(支持向量机),即寻找到一个超平面使样本分成两类,并且间隔最大。
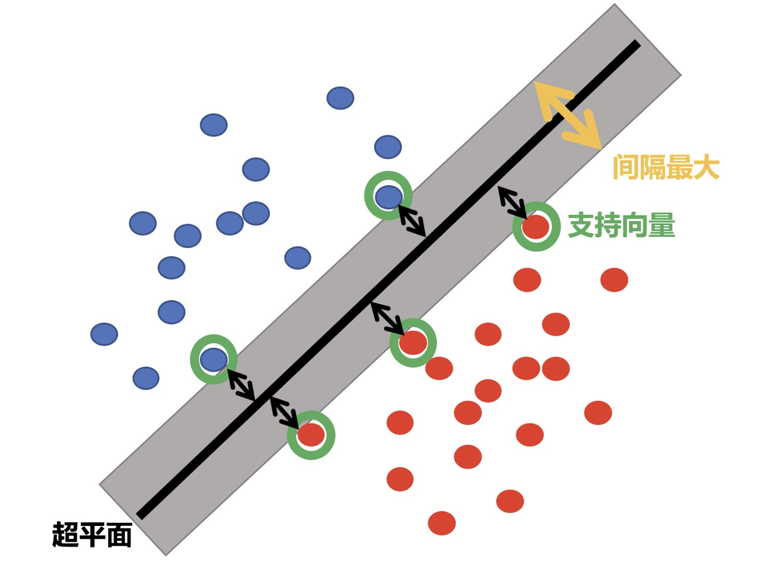
SVM能够执行线性或非线性分类、回归,甚至是异常值检测任务。是机器学习领域最受欢迎的模型之一。SVM特别适用于中小型复杂数据集的分类。
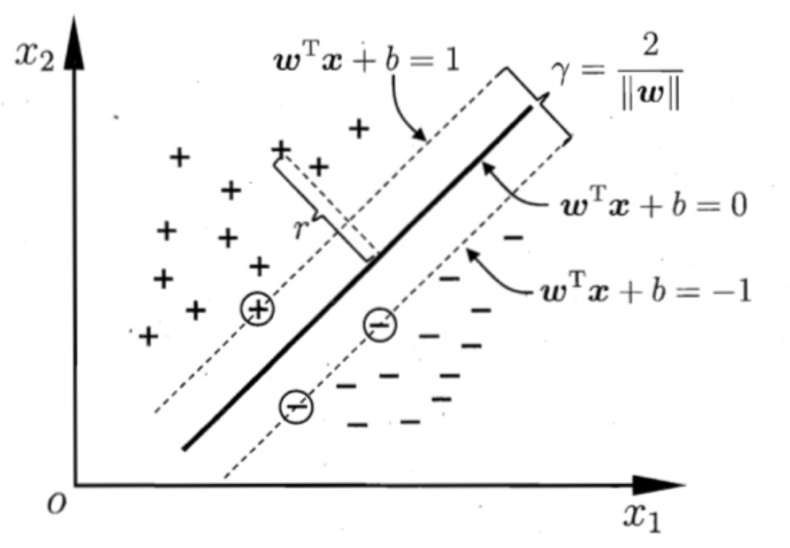
【理解】超平面最大间隔
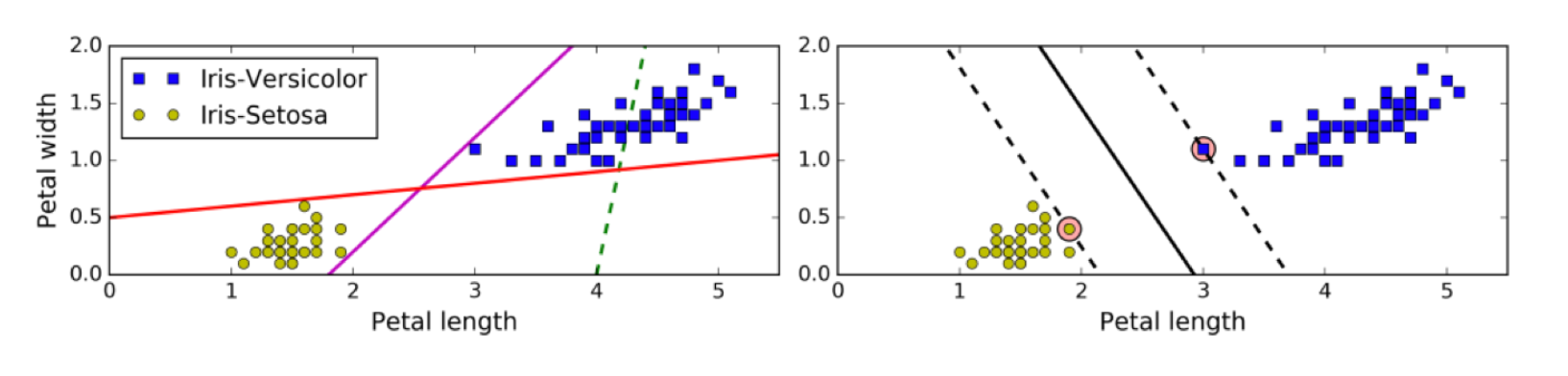
上左图显示了三种可能的线性分类器的决策边界:
虚线所代表的模型表现非常糟糕,甚至都无法正确实现分类。其余两个模型在这个训练集上表现堪称完美,但是它们的决策边界与实例过于接近,导致在面对新实例时,表现可能不会太好。
右图中的实线代表SVM分类器的决策边界,不仅分离了两个类别,且尽可能远离最近的训练实例。
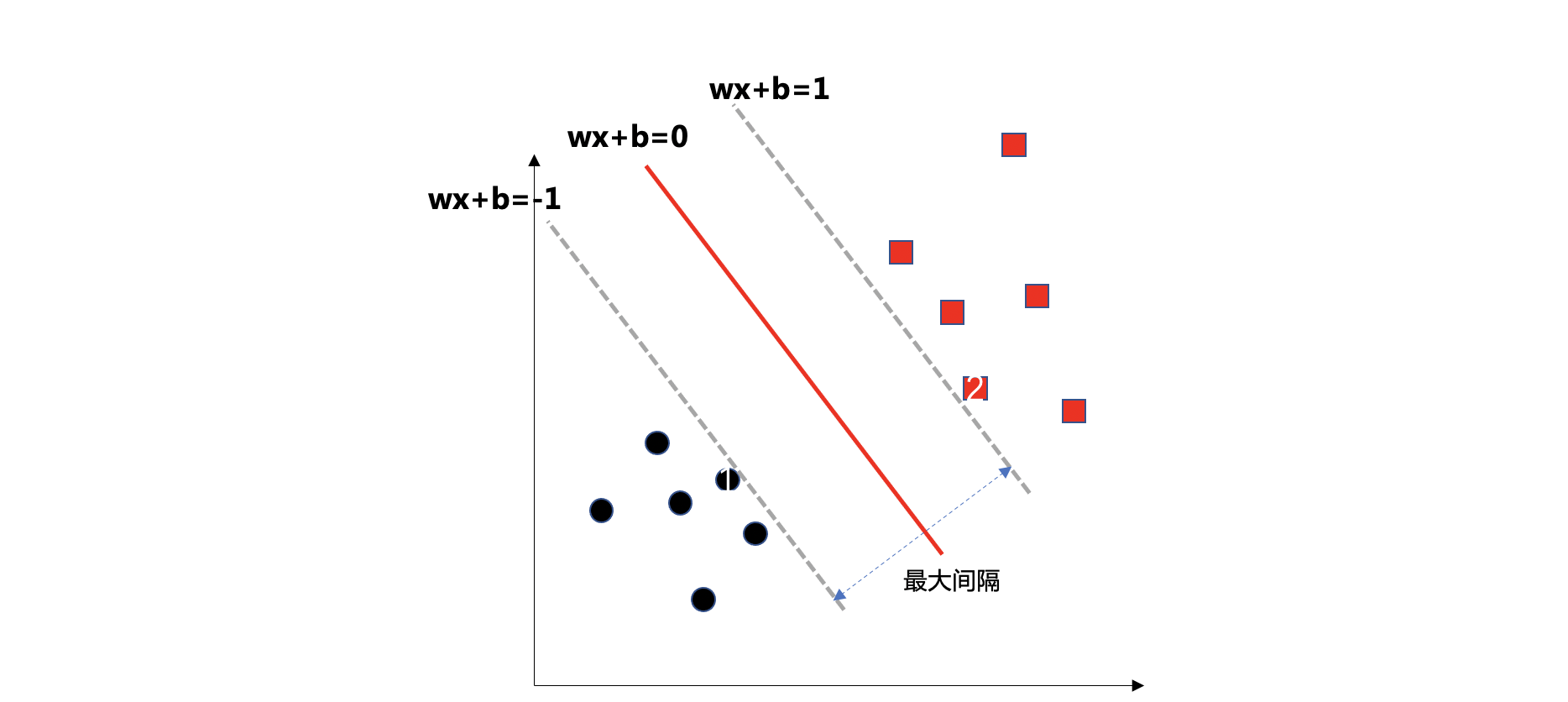
【知道】硬间隔
如果样本线性可分,在所有样本分类都正确的情况下,寻找最大间隔,这就是硬间隔
如果出现异常值、或者样本不能线性可分,此时硬间隔无法实现。
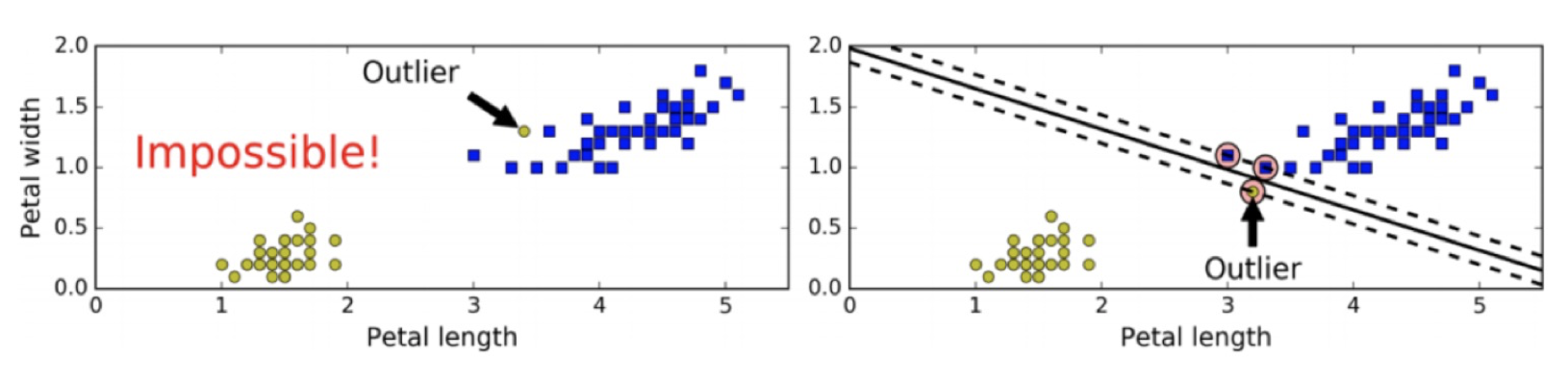
当有一个额外异常值的鸢尾花数据,左图的数据根本找不出硬间隔,而右图最终显示的决策边界与我们之前所看到的无异常值时的决策边界也大不相同,可能无法很好地泛化。
【知道】软间隔和惩罚系数
允许部分样本,在最大间隔之内,甚至在错误的一边,寻找最大间隔,这就是软间隔
目标是尽可能在保持间隔宽阔和限制间隔违例之间找到良好的平衡。
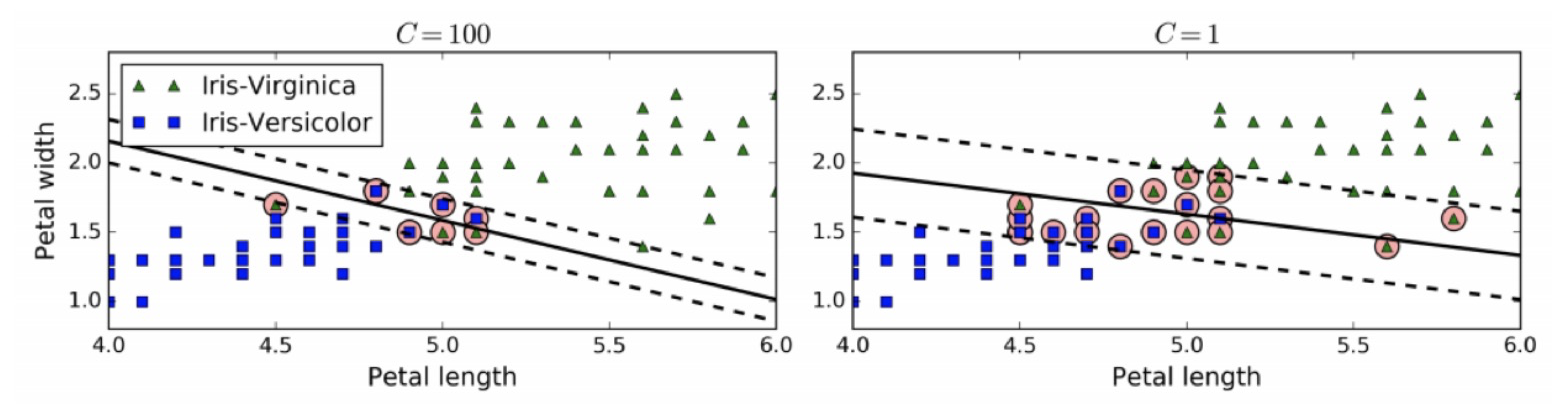
通过惩罚系数C来控制这个平衡:C值越小,则间隔越宽,但是间隔违例也会越多。
左边使用了高C值,分类器的错误样本(间隔违例)较少,但是间隔也较小。
右边使用了低C值,间隔大了很多,但是位于间隔上的实例也更多。
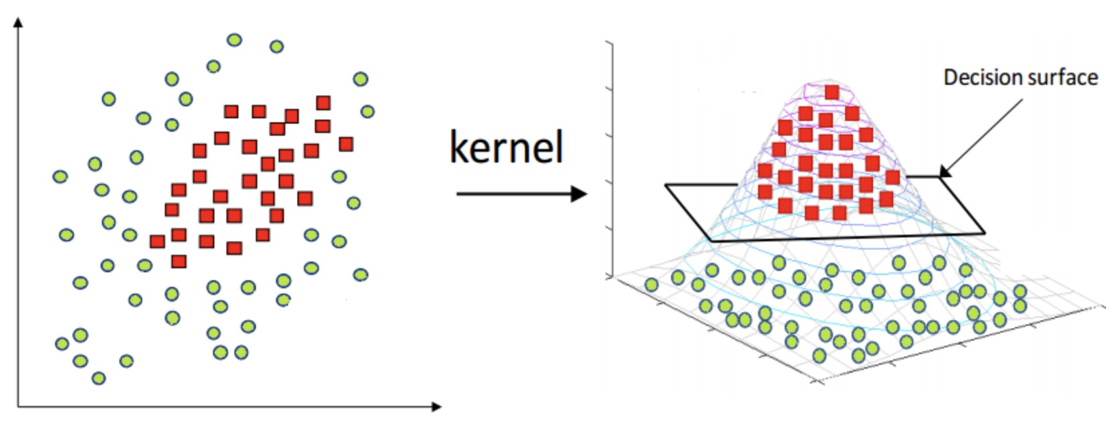
【知道】核函数
核函数将原始输入空间映射到新的特征空间,使得原本线性不可分的样本在核空间可分
支持向量机API使用
学习目标:
- 知道LinearSVC的使用方法
- 理解惩罚系数C的作用
【知道】支持向量机的API
class sklearn.svm.LinearSVC(C=1.0)
C:惩罚系数,类似于线性回归中的正则化系数。
LinearSVC API的使用方式:
from sklearn.svm import LinearSVC
mysvc = LinearSVC(C=30)
mysvc.fit(X_standard, y)
print(mysvc.score(X_standard, y))
【实践】案例实现
加载鸢尾花数据, 使用SVM对鸢尾花数据进行分类。选取前两个类别和前两个特征
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
X,y = datasets.load_iris(return_X_y = True)
X = X[y<2,:2] # 取前两个特征,取前两个类别(二分类)
y = y[y<2]
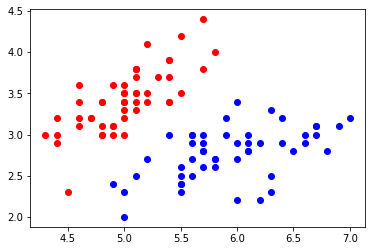
# 数据可视化
plt.scatter(X[y==0,0],X[y==0,1],color = 'red')
plt.scatter(X[y==1,0],X[y==1,1],color = 'blue')
plt.show()
数据标准化
from sklearn.preprocessing import StandardScaler
std_scaler = StandardScaler()
X_standard = std_scaler.fit_transform(X)
训练SVC模型, 首先我们设置一个比较大的C值
from sklearn.svm import LinearSVC
svc = LinearSVC(C=30)
svc.fit(X_standard,y)
绘制决策边界
def plot_decision_boundary(model,axis):
x0,x1 = np.meshgrid(
np.linspace(axis[0],axis[1],int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2],axis[3],int((axis[3]-axis[2])*100)).reshape(-1,1)
)
X_new = np.c_[x0.ravel(),x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_map = ListedColormap(["#EF9A9A","#FFF59D","#90CAF9"])
plt.contourf(x0,x1,zz,linewidth=5,cmap=custom_map)
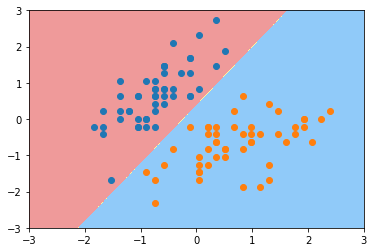
plot_decision_boundary(svc,axis=[-3,3,-3,3])
plt.scatter(X_standard[y==0,0],X_standard[y==0,1])
plt.scatter(X_standard[y==1,0],X_standard[y==1,1])
plt.show()
测试参数C的影响, 将C调小,再次绘制决策边界
svc2 = LinearSVC(C=0.1)
svc2.fit(X_standard,y)
plot_decision_boundary(svc2,axis=[-3,3,-3,3])
plt.scatter(X_standard[y==0,0],X_standard[y==0,1])
plt.scatter(X_standard[y==1,0],X_standard[y==1,1])
plt.show()
svc对象中也有coef_ 和 intercept参数,分别代表特征前面的系数和决策边界的截距
利用这两个参数将间隔区间绘制出来
def plot_decision_boundary_svc(model,axis):
x0,x1 = np.meshgrid(
np.linspace(axis[0],axis[1],int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2],axis[3],int((axis[3]-axis[2])*100)).reshape(-1,1)
)
X_new = np.c_[x0.ravel(),x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_map = ListedColormap(["#EF9A9A","#FFF59D","#90CAF9"])
plt.contourf(x0,x1,zz,linewidth=5,cmap=custom_map)
w= model.coef_[0]
b = model.intercept_[0]
# w0* x0 + w1* x1+ b = 0
#=>x1 = -w0/w1 * x0 - b/w1
plot_x = np.linspace(axis[0],axis[1],200)
up_y = -w[0]/w[1]* plot_x - b/w[1]+ 1/w[1]
down_y = -w[0]/w[1]* plot_x - b/w[1]-1/w[1]
up_index =(up_y >= axis[2])&(up_y <= axis[3])
down_index =(down_y>= axis[2])&(down_y<= axis[3])
plt.plot(plot_x[up_index],up_y[up_index],color="black")
plt.plot(plot_x[down_index],down_y[down_index],color="black")
绘制间隔区间
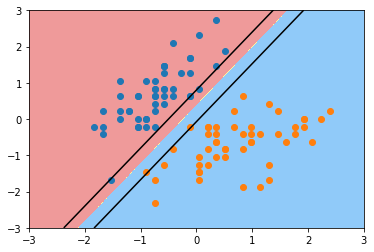
plot_decision_boundary_svc(svc,axis=[-3,3,-3,3])
plt.scatter(X_standard[y==0,0],X_standard[y==0,1])
plt.scatter(X_standard[y==1,0],X_standard[y==1,1])
plt.show()
plot_decision_boundary_svc(svc2,axis=[-3,3,-3,3])
plt.scatter(X_standard[y==0,0],X_standard[y==0,1])
plt.scatter(X_standard[y==1,0],X_standard[y==1,1])
plt.show()
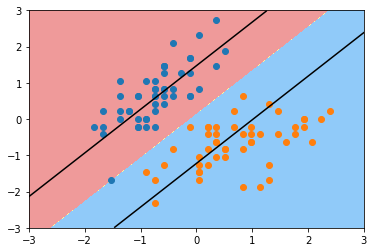
从上面的例子中可以看出, C值变小, 我们的间隔区间变大从hard margin 变成了soft margin
SVM算法原理
学习目标:
- 了解支持向量机的推导过程
- 目标函数确定


- 约束条件优化问题转换

- 对偶问题转换

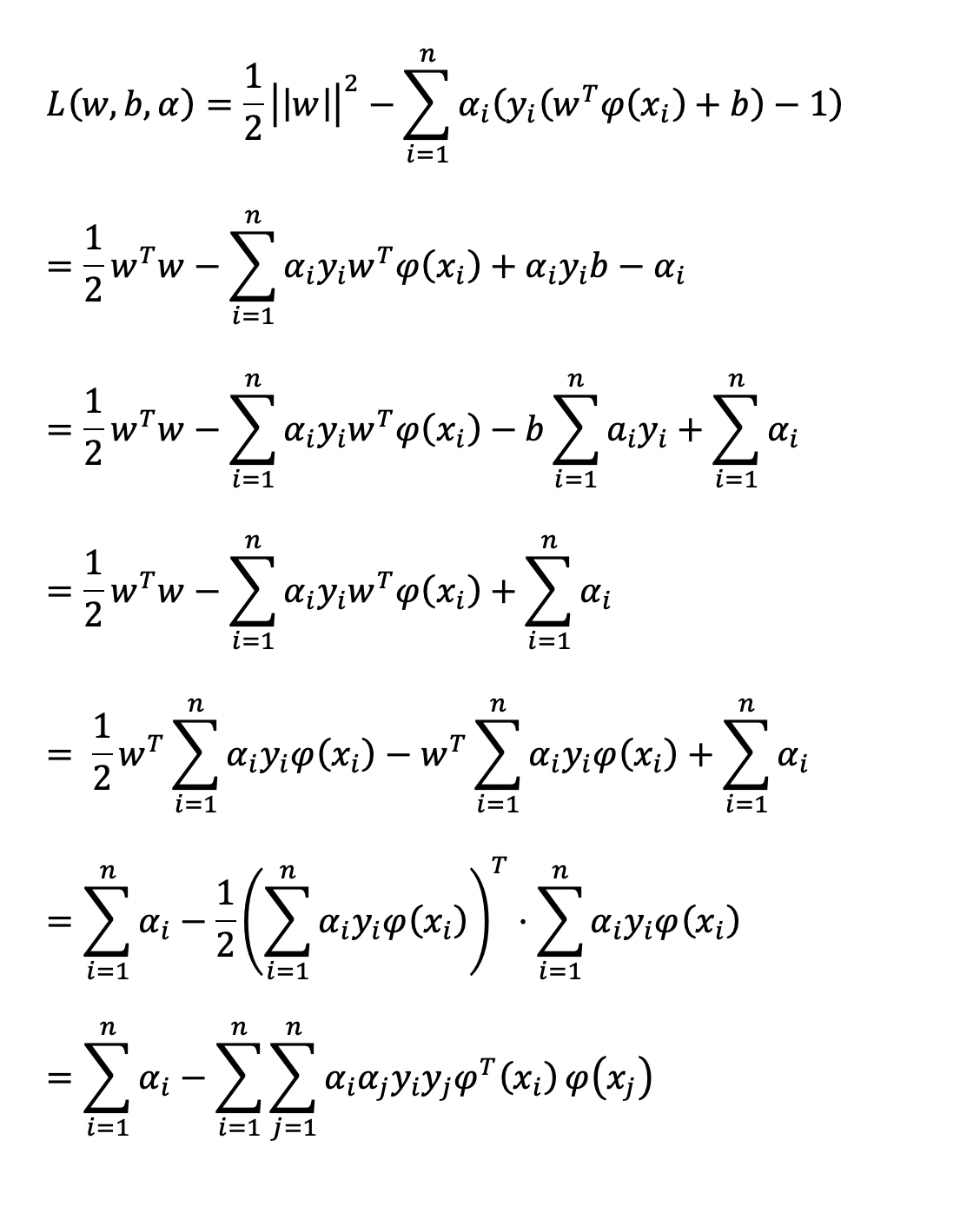
此时,求解当 α 是什么值时,该值会变得很大,当求出 α 值,再求解 w, b 值。此时,就变成了极大极小值问题。
- 确定超平面

核函数
学习目标:
1.理解核函数的作用
2.知道核函数的分类
3.知道高斯核函数
4.实践高斯核函数的API
【知道】核函数的作用
核函数,是将原始输入空间映射到新的特征空间,从而,使得原本线性不可分的样本可能在核空间可分。
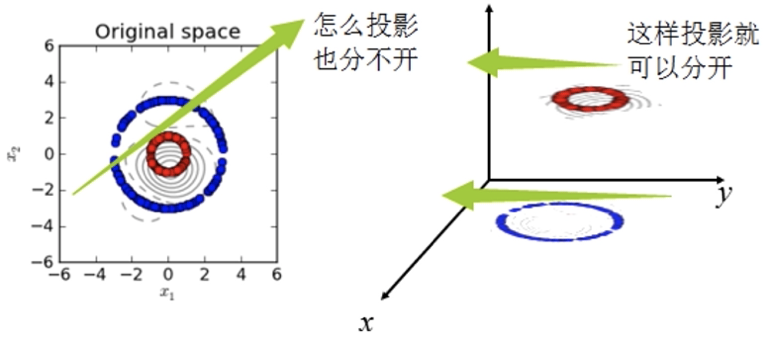
下图所示的两类数据,分别分布为两个圆圈的形状,这样的数据本身就是线性不可分的,此时该如何把这两类数据分开呢?
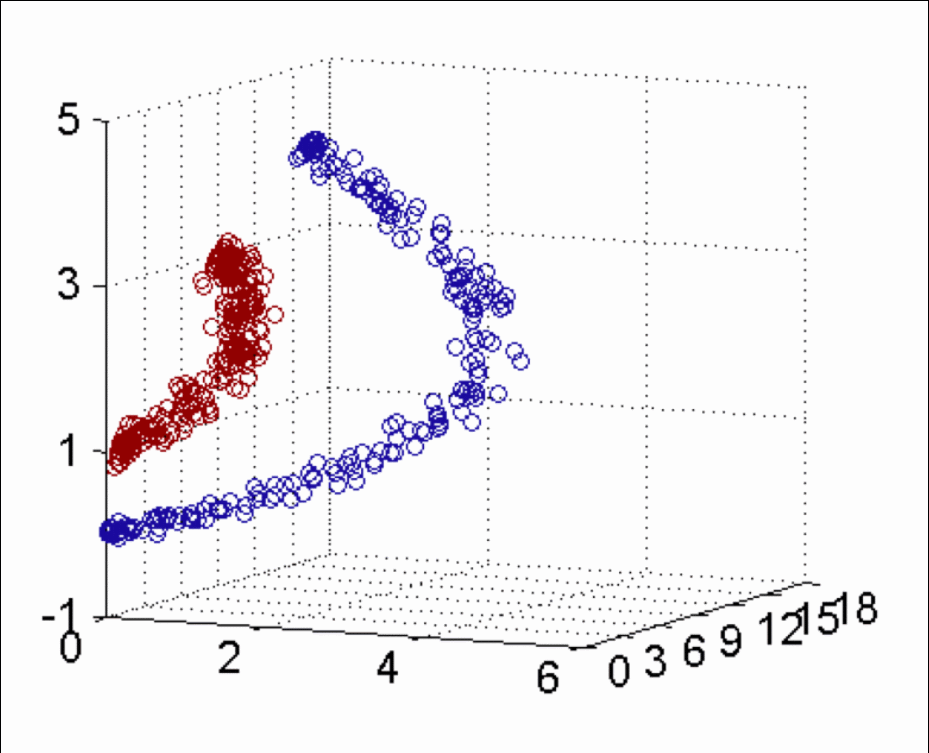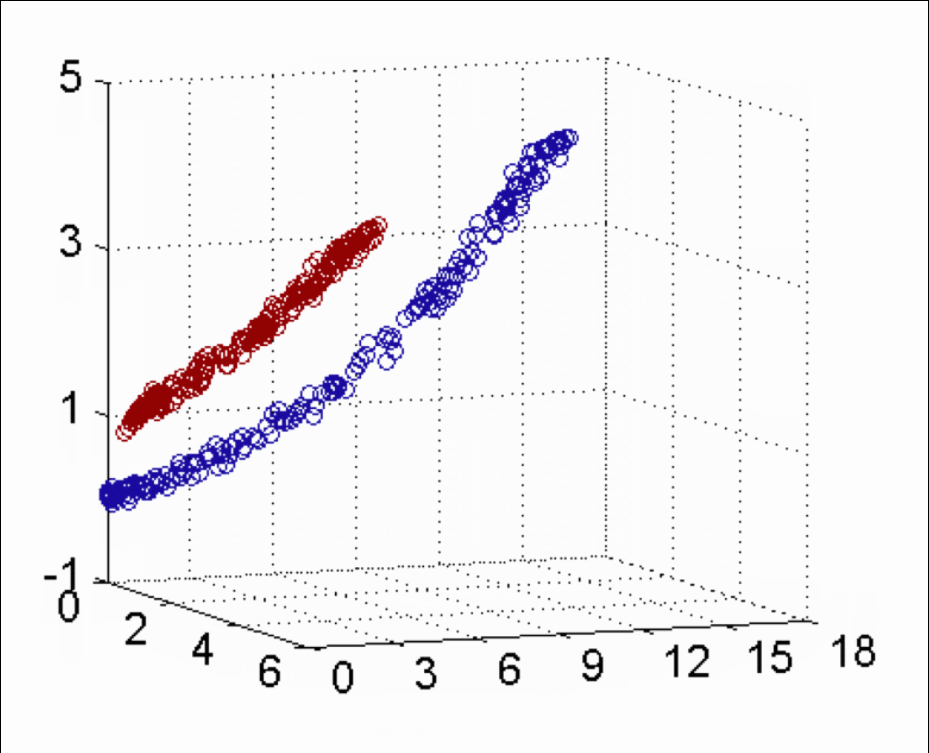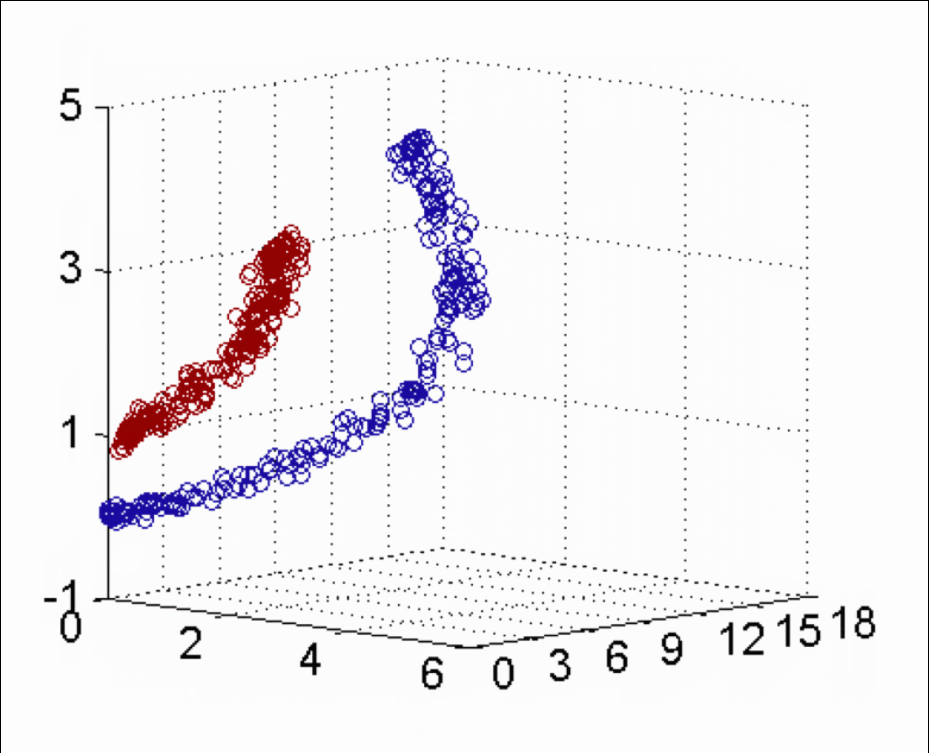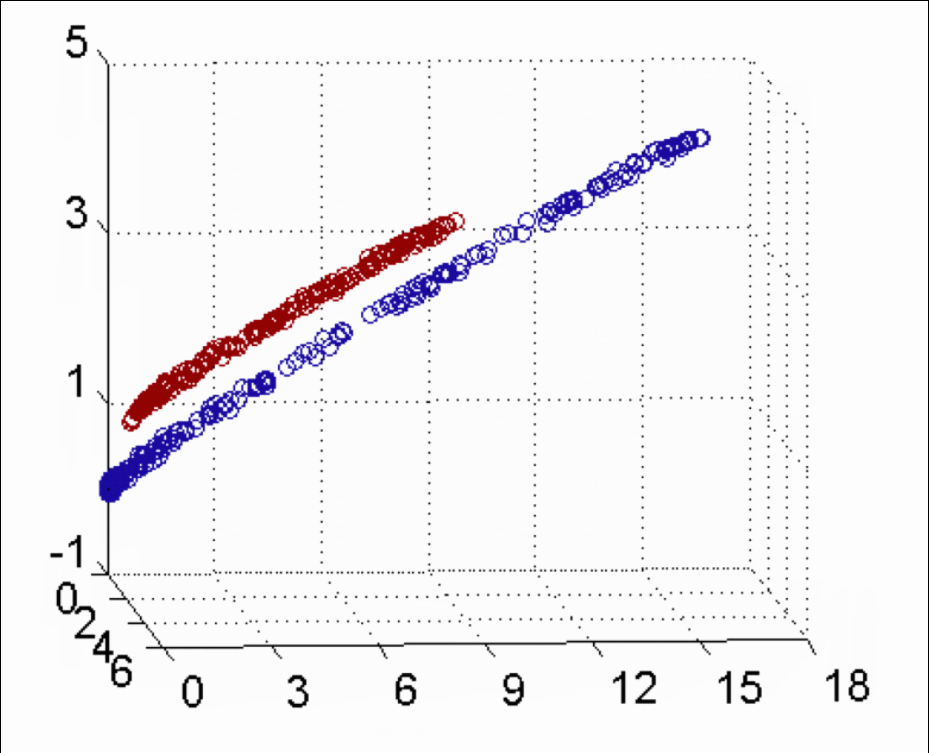
【知道】核函数的分类
当存在线性不可分的场景时,我们需要使用核函数来提高训练样本的维度、或者将训练样本投向高维

高斯核函数使用较多。
- 线性核:一般是不增加数据维度,而是预先计算内积,提高速度
- 多项式核:一般是通过增加多项式特征,提升数据维度,并计算内积
- 高斯核(RBF、径向基函数):一般是通过将样本投射到无限维空间,使得原来不可分的数据变得可分。
【理解】高斯核函数
高斯核函数(RBF),其中γ 为超参数
K ( x , y ) = e − γ ∣ ∣ x − y ∣ ∣ 2 \large K(x,y) = e^{-γ||x-y||^2} K(x,y)=e−γ∣∣x−y∣∣2
gamma是超参数,作用与标准差相反,gamma越大,高斯分布越窄,gamma越小,高斯分布越宽
举个例子:

任务:找到一种方法,用一条线将数据完美分类。如果只从1维的角度考虑,这是一项不可能完成的任务,但可以用升维度的办法来解决问题。
让我们引入一个函数 f(x),图像如下图所示。 将 x 的每个值映射到其对应的输出。使得所有蓝点在Y轴的输出更大,而红点在Y轴的输出偏小。此时,我们可以使用一条水平线将数据完美分类。
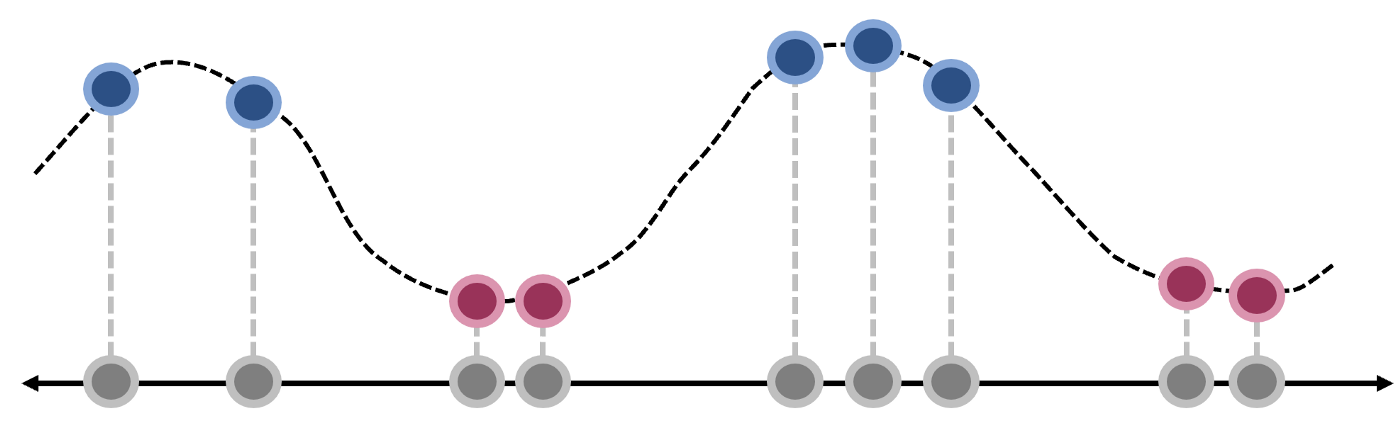
这个解决方案看起来很“巧妙”,我们可以借助径向基函数 (RBF) 来实现
【实践】高斯核的API
准备数据
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
X,y = datasets.make_moons(noise=0.15,random_state=22)
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
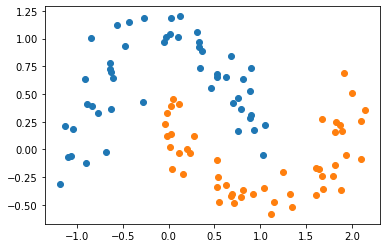
创建Pipeline:数据标准化,创建高斯核SVC对象 gamma默认为1
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
def RBFKernelSVC(gamma = 1.0):
return Pipeline([
('std_scaler',StandardScaler()),
('svc',SVC(kernel='rbf',gamma=gamma))
])
模型训练
svc = RBFKernelSVC(gamma=1.0)
svc.fit(X,y)
Pipeline(steps=[(‘std_scaler’, StandardScaler()), (‘svc’, SVC(gamma=1.0))])
绘制决策边界
def plot_decision_boundary(model,axis):
x0,x1 = np.meshgrid(
np.linspace(axis[0],axis[1],int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2],axis[3],int((axis[3]-axis[2])*100)).reshape(-1,1)
)
X_new = np.c_[x0.ravel(),x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_map = ListedColormap(["#EF9A9A","#FFF59D","#90CAF9"])
plt.contourf(x0,x1,zz,linewidth=5,cmap=custom_map)
plot_decision_boundary(svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
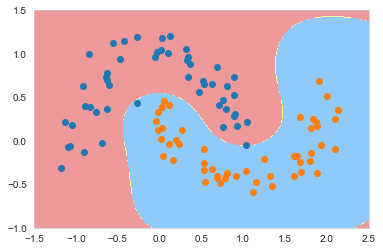
上图结果与多项式核有些类似,我们尝试调整gamma观察效果,首先将gamma调大
svc_100 = RBFKernelSVC(gamma=100)
svc_100.fit(X,y)
plot_decision_boundary(svc_100,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
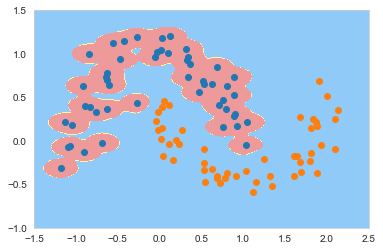
从上面的结果中发现,gamma越大我们的模型对数据点的拟合度越强,上图的结果明显过拟合了,为了进一步验证这个结论,我们稍微调小gamma 让它等于10
svc_10 = RBFKernelSVC(gamma=10)
svc_10.fit(X,y)
plot_decision_boundary(svc_10,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
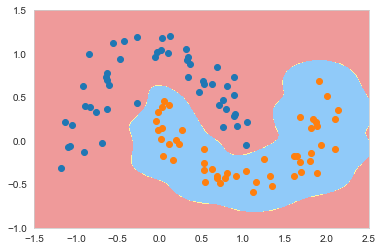
从上面的结果中看出调小gamma之后,过拟合程度有所减弱。我们再次将gamma调小
svc_05 = RBFKernelSVC(gamma=0.5)
svc_05.fit(X,y)
plot_decision_boundary(svc_05,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
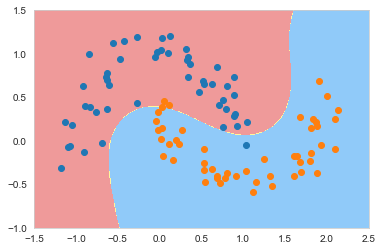
svc_10 = RBFKernelSVC(gamma=0.1)
svc_10.fit(X,y)
plot_decision_boundary(svc_01,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
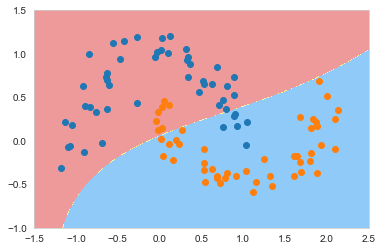
从上面的结果中看出,当gamma=0.1的时候,结果已经接近线性SVC了。此时模型已经欠拟合了。自此我们可以得出结论
- gamma越大,模型过拟合风险越高
- gamma越小,模型欠拟合风险越高
文章最后 附上视频源码下载地址
我用夸克网盘分享了「1016-博学谷-2025年人工智能AI就业班GPT大模型-完结」,点击链接即可保存。打开「夸克APP」,无需下载在线播放视频,畅享原画5倍速,支持电视投屏。
链接:https://pan.quark.cn/s/2e6556fd74f7
提取码:upcy注意:及时转存随时失效。失效+V:x923713获取。资源较大。夸克网盘空间不够请开会员及时转存。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









