






题目:
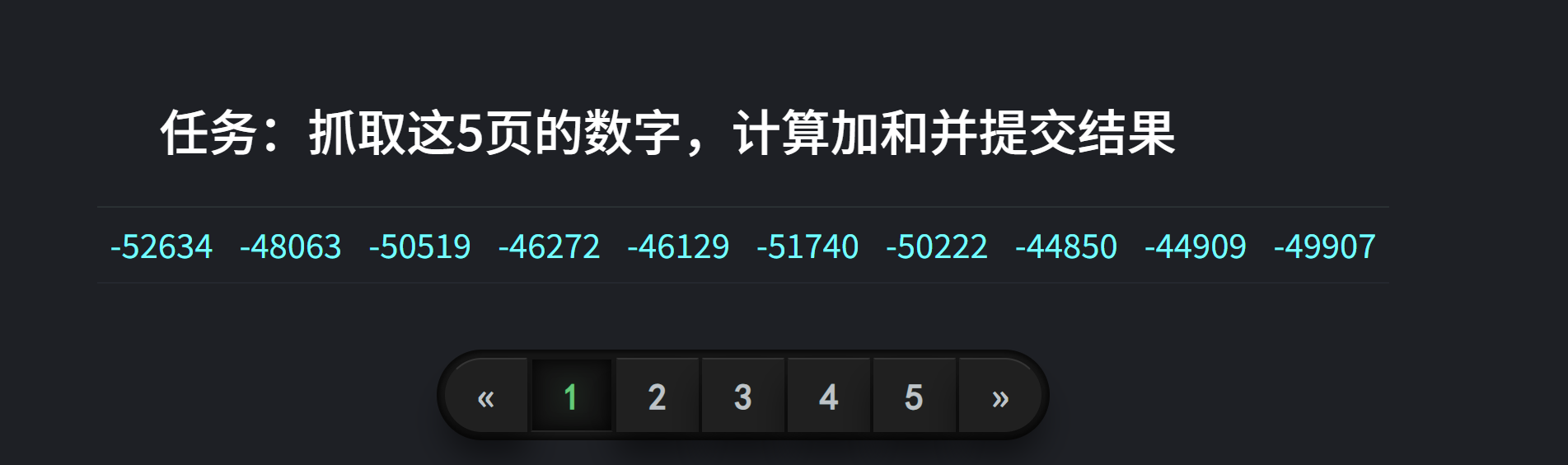
首先,抓取翻页数据包,发现接口为get请求方式,并且可以看出这个参数m被加密,但是现在这个参数m的加密方式或者编码方式我们还不知道,还得做进一步分析才能确定
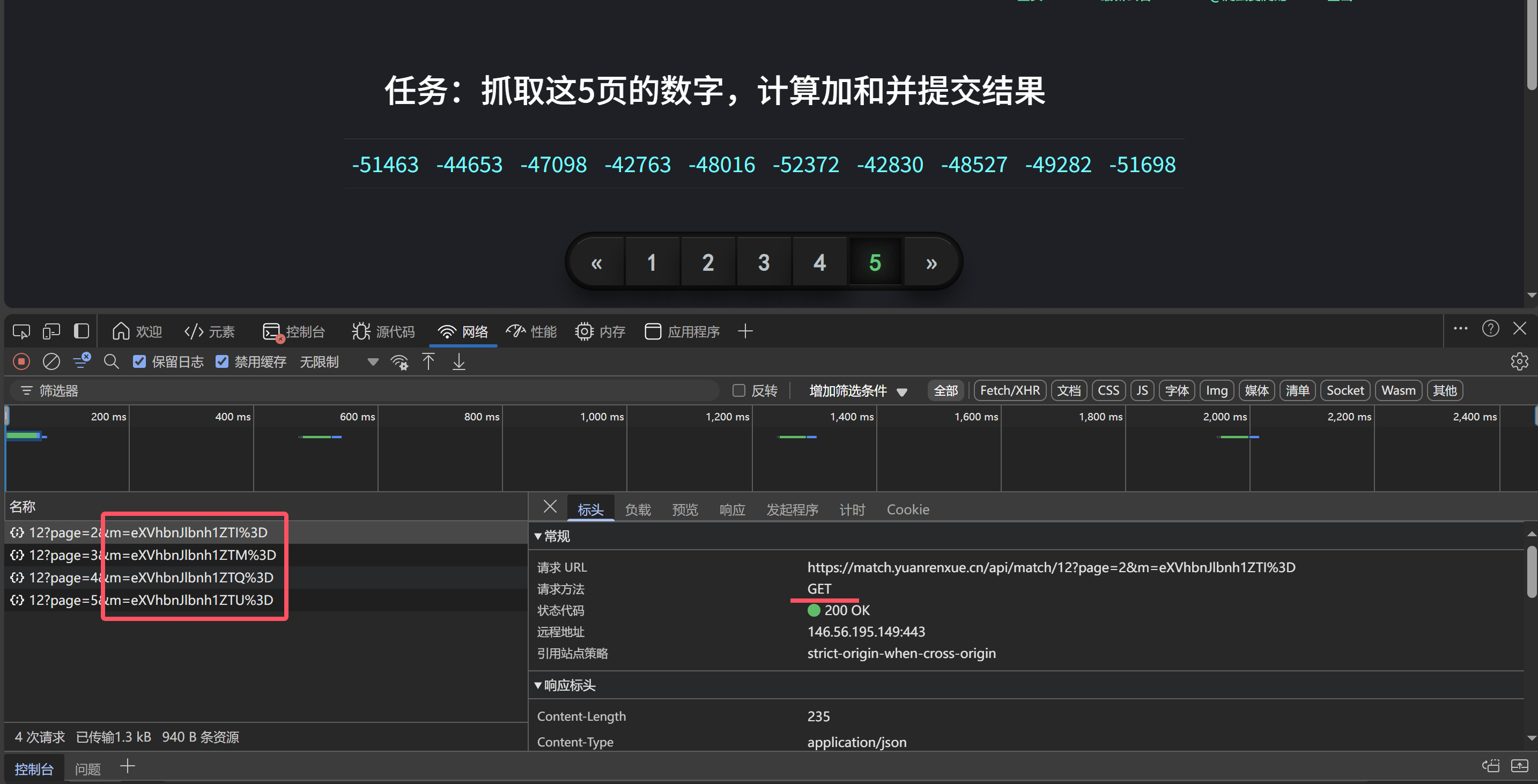
然后,我们在看看接口的数据对不对
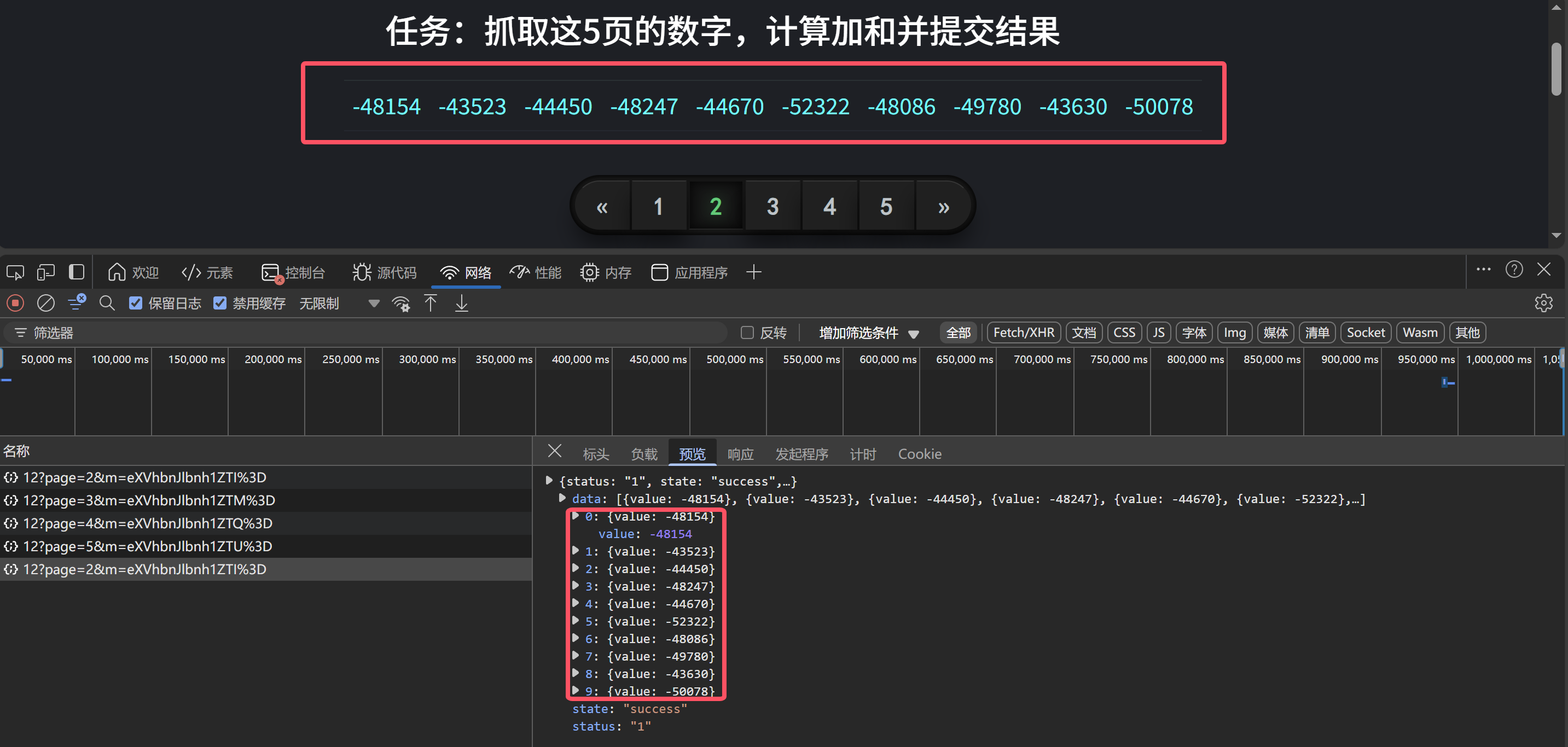
观察对比发现接口数据没有问题,接下来进行下一步操作
我们直接请求一下这个接口试一下,看看能不能请求到数据

直接请求接口,发现可以请求到数据,说明这个题目没有cookie验证
现在好办了,我们直接去看接口的请求调用堆栈,jquery是官方的,基本上不会有网站去魔改jquery,我们直接跳过,看request就行
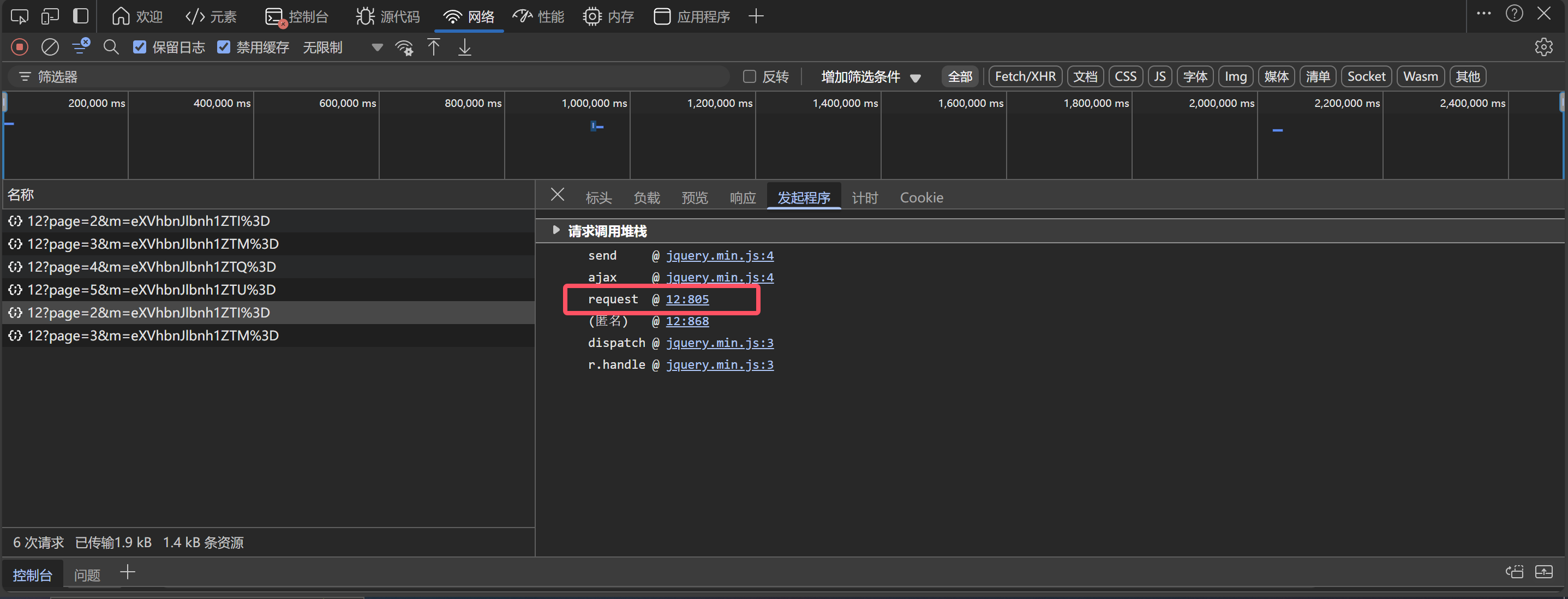
这里我们看到了一个ajax请求,ajax是JS发包的一种形势,现在我们可以在ajax方法处打上一个断点,点击翻页,分析一下加密参数m的生成过程
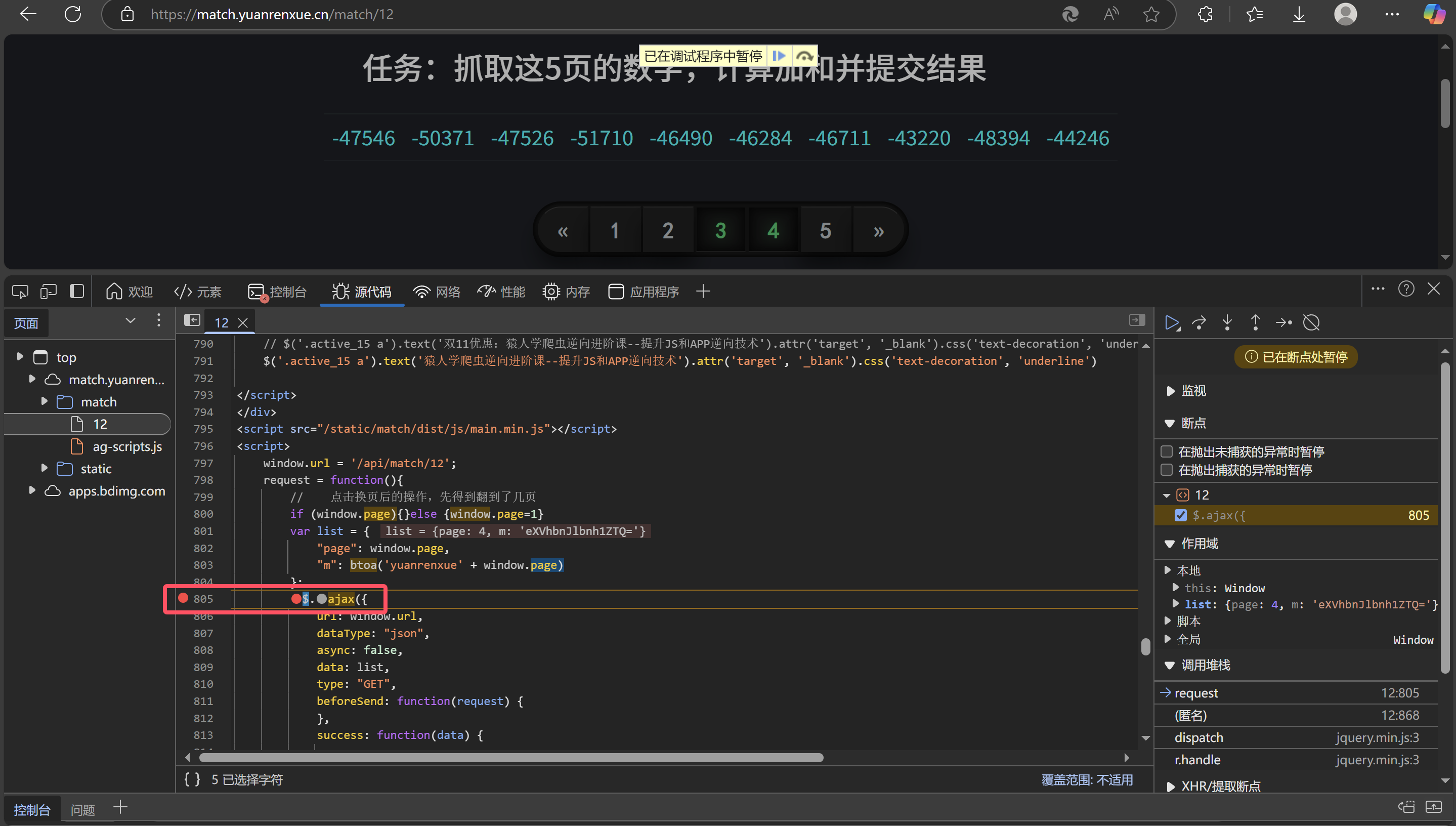
现在我们可以确定加密参数m的生成过程了:
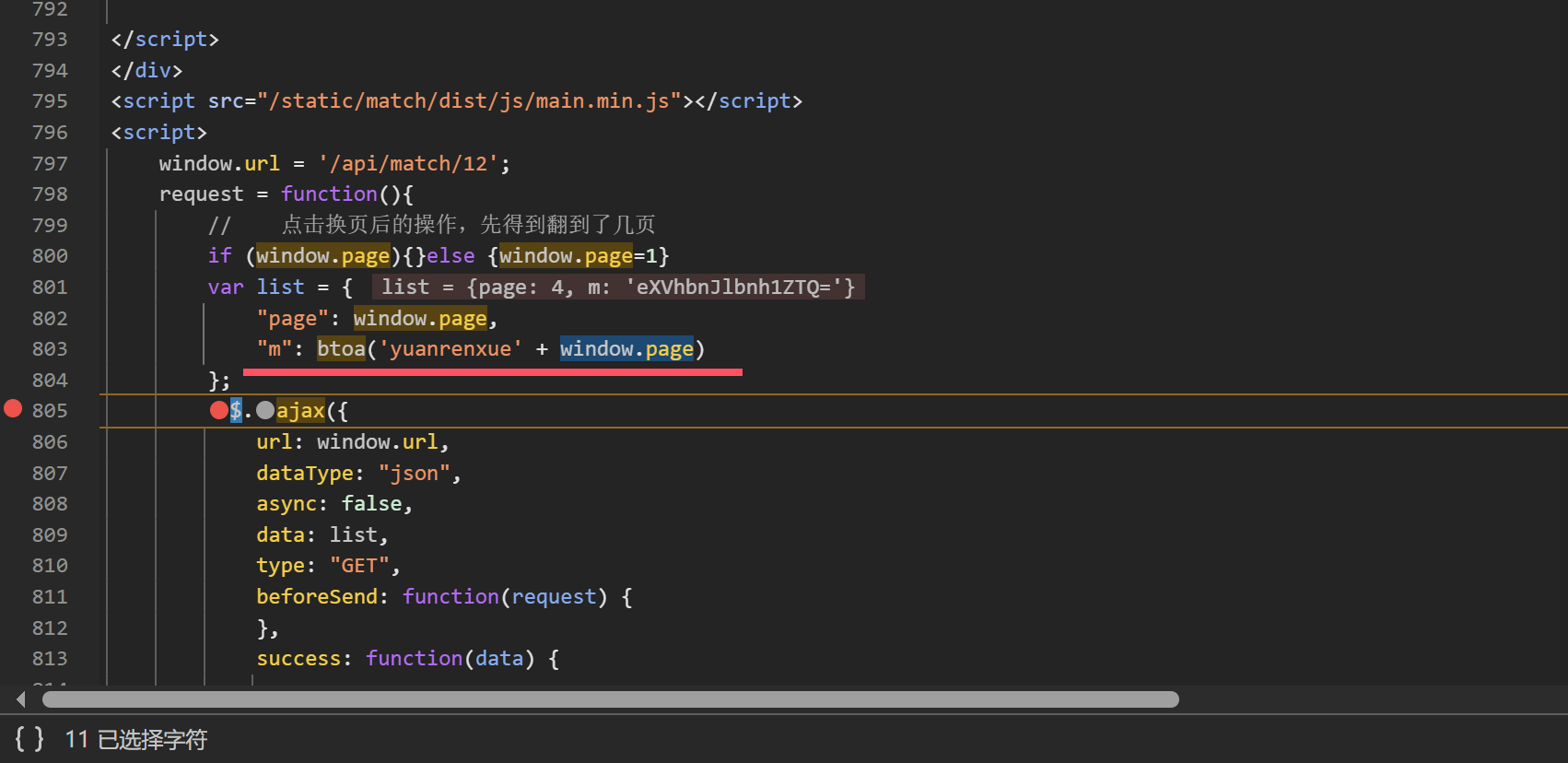
加密参数m是调用了btoa方法,将固定字符串'yuanrenxue'与当前页码window.page拼接生成
btoa()方法是 JS中用于将二进制字符串编码为 Base64 编码的 ASCII 字符串的方法,而base-64 解码使用方法是atob()
我们可以到控制台测试验证一下加密解密是否正确
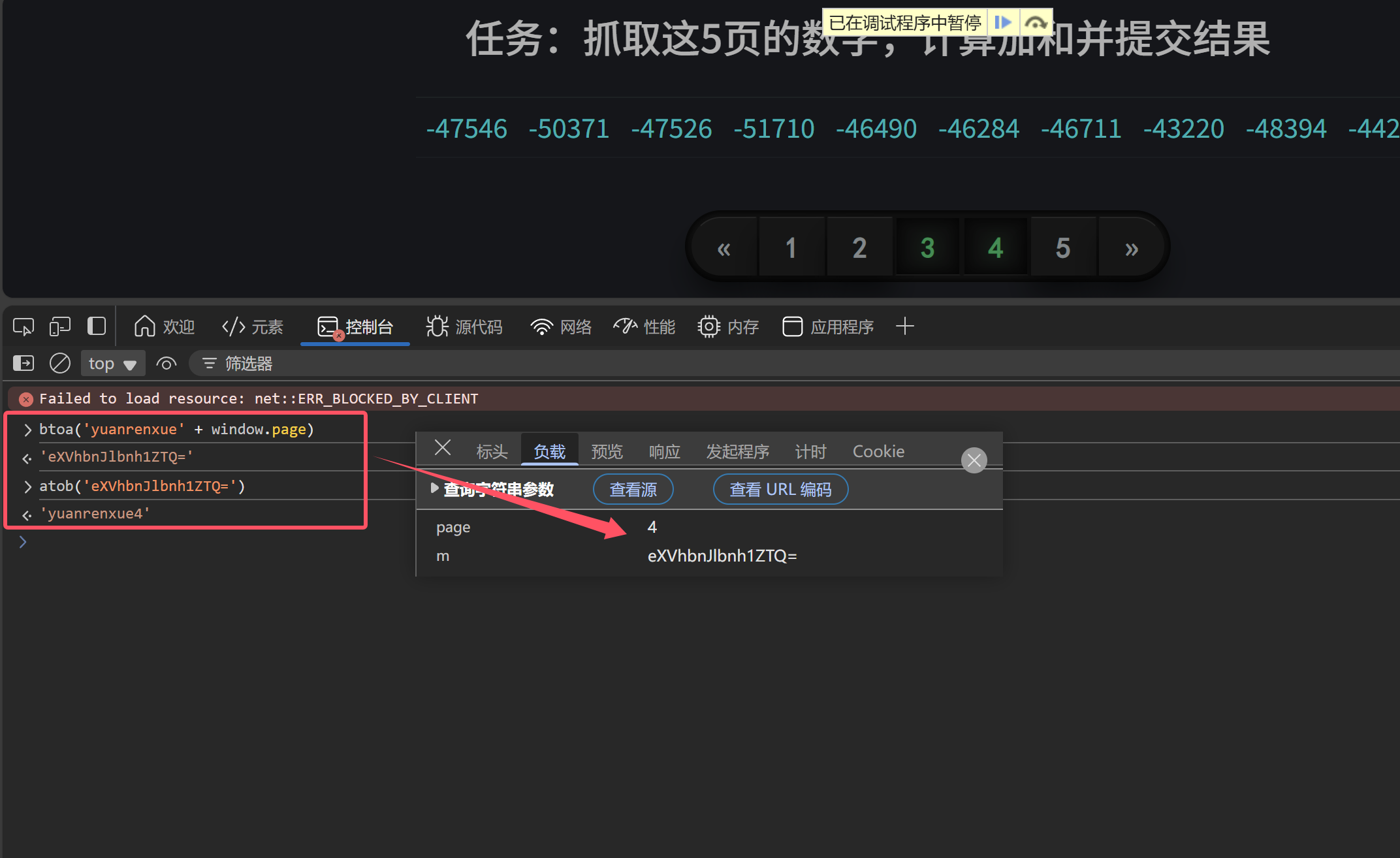
测试验证结果一致,现在整个逆向过程就结束了,接下来就是编写代码,抓数据计算求值
代码展示如下:
import requests
import base64 # 用于Base64编码
# 定义一个Base64编码函数
def btoa(text):
return base64.b64encode(text.encode('utf-8')).decode('utf-8').replace("=", "%3D")
# 主爬虫函数
def myspider(pages):
total_count = 0 # 总数值累
for page in range(1, pages + 1): # 遍历每一页
#构造加密参数
text = "yuanrenxue" + str(page) # 生成原始字符串
btoa_str = btoa(text) # 调用自定义编码函数
print(f"第{str(page)}页的m值为{btoa_str}")
#发送请求
headers = {
'User-Agent': 'yuanrenxue.project',
}
cookies = {
'sessionid': '用你自己的', # 身份验证cookie
}
url = f"https://match.yuanrenxue.com/api/match/12?page={str(page)}&m={btoa_str}"
response = requests.get(url, cookies=cookies, headers=headers)
print(response.text) # 打印原始响应数据
#解析数据
res_json_list = response.json().get('data', '') # 提取data字段
if res_json_list == '': continue # 跳过空数据
#处理当前页数据
per_page_count = 0 # 当前页数值累加
for item in res_json_list:
value0 = item.get('value', '') # 获取value字段
value = 0 if value0 == '' else int(value0) # 处理空值并转为整数
per_page_count += value
print(f"第{page}页的和为:{per_page_count}")
total_count += per_page_count # 累加到总数
return total_count
if __name__ == "__main__":
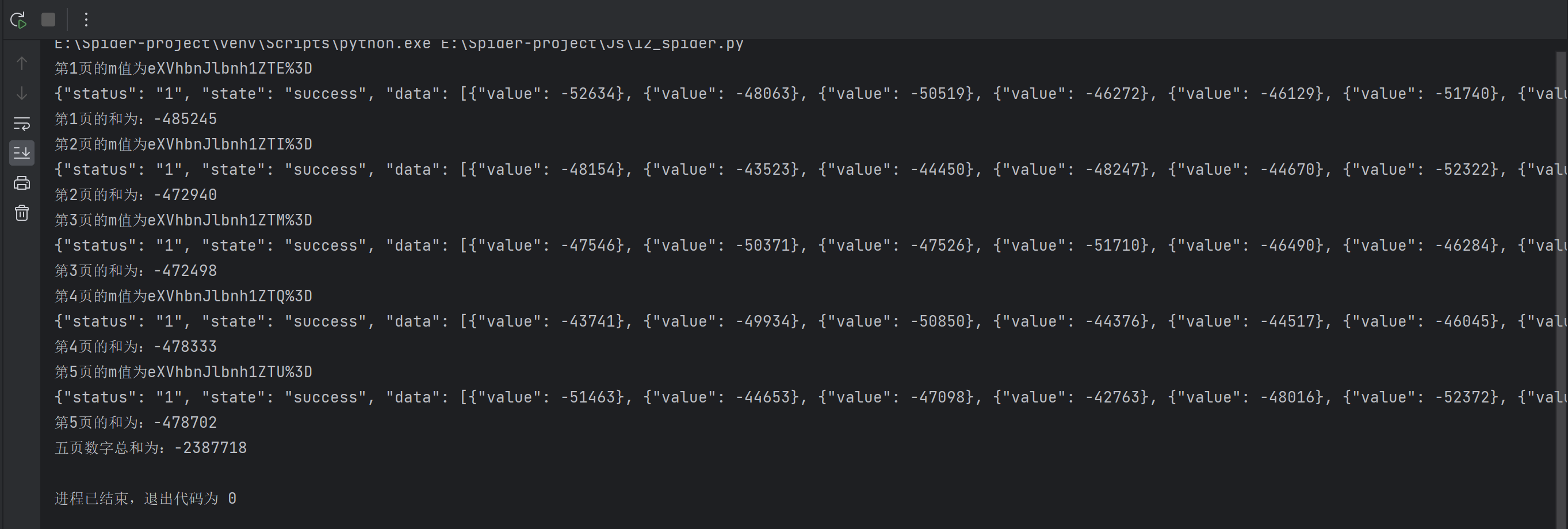
total_count = myspider(5) # 执行爬取5页数据
print(f"五页数字总和为:{total_count}")代码运行结果如下:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









