






看之前首先要懂两个基本条件:
1. 什么是向量
2. 会使用向量的检索
3. 知道至少一种向量的索引
这里我们拿比较的流行的HNSW算法来进行分析:
最直接的做法是根据向量在给定数据集中采用KNN来找到K个最近的向量。但在实际应用中,待检索的数据往往是千万甚至亿级,KNN的计算量过大。因此,通常采用ANN(Approximate Nearest Neighbor,相似近邻)来快速相似检索
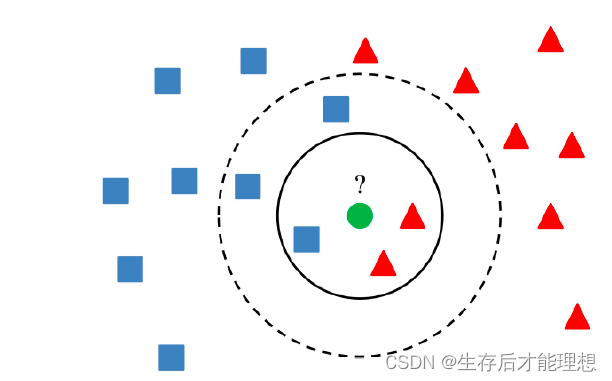
相似性检索:
在NSW中,构建图的阶段通过节点的随机插入来引入随机性,构建出一个small world graph,从而实现快速检索。但NSW构造的图并不稳定,节点之间的差异较大:
-
先插入的顶点,其连接的邻居节点,基本都比较远(弱连接属性强)
-
后插入的顶点,其连接的邻居节点,基本都比较近(弱连接属性弱)
-
对于具有聚类效应的点,由于后续插入的点可能都和其建立连接,对应节点的度可能会比较高
如何构造具有更稳定的small world graph呢?HNSW算法就在NSW基础之上引入了分层图的思想,通过对图进行分层,实现由粗到细的检索。
1、图构造
HNSW在构造图时如下图所示:
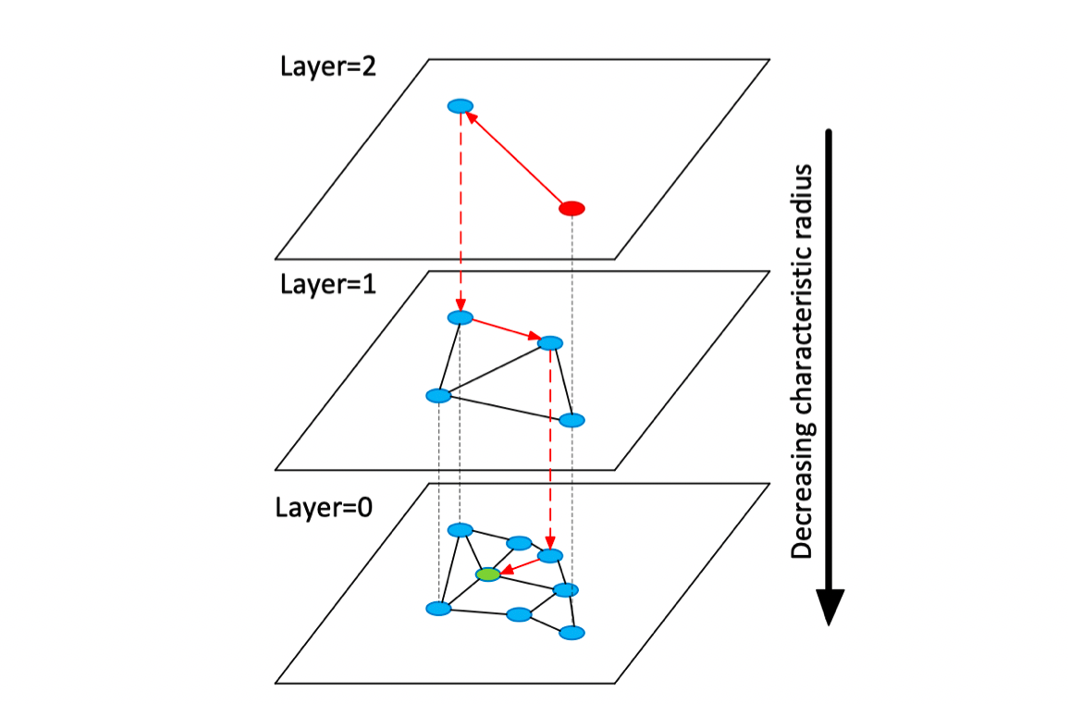
核心如下:
-
layer=0层包含了数据集中的所有点 -
layer=l层是以50%的概率随机从layer=l-1层中选择的点构成的。因此,最大层数为 -
插入构图时,先计算新顶点可以深入到第几层(),在每层的NSW图中查找m个近邻,然后连接它们
2、图检索
对HNSW进行查询时,从最高层开始检索,逐层往下,从而实现快速搜索
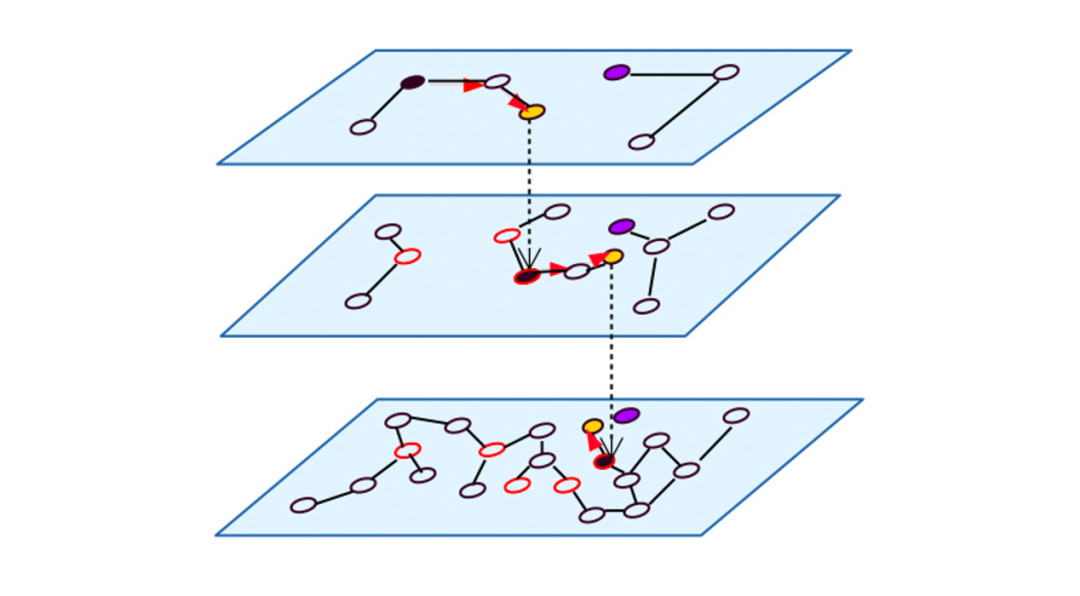
总结:想要更高性能的相似性检索需要需要依赖索引,比如HNSW,当我们使用索引检索时它和暴力检索不同的的是:
1. 暴力检索会遍历所有节点,然后进行一 一返回
2. 使用索引检索时,它返回的是ANN 所有的近邻节点,返回近邻节点的时候它并不会按照从最相似的开始返回,而是将所有近邻结果全部返回,返回之后在进行排序。
3. 要返回多少近邻节点是算法中的参数,可以进行调节。当然,也可以返回之后在进行过滤。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









