







目录
一、Hadoop介绍
1. Hadoop之父:道格 卡丁 (Doug Cutting)
2. 吉祥物: 大象
3. Hadoop 解释:
狭义解释:指的是HDFS、MapReduce、Yarn等框架.
广义解释:指的是Hadoop生态圈,包括但不限于周边所有技术.
4. Hadoop组成:
HDFS(Hadoop distributed file system):Hadoop分布式文件存储系统
MapReduce:分布式计算框架
Yarn:分布式 任务接收和资源调度框架
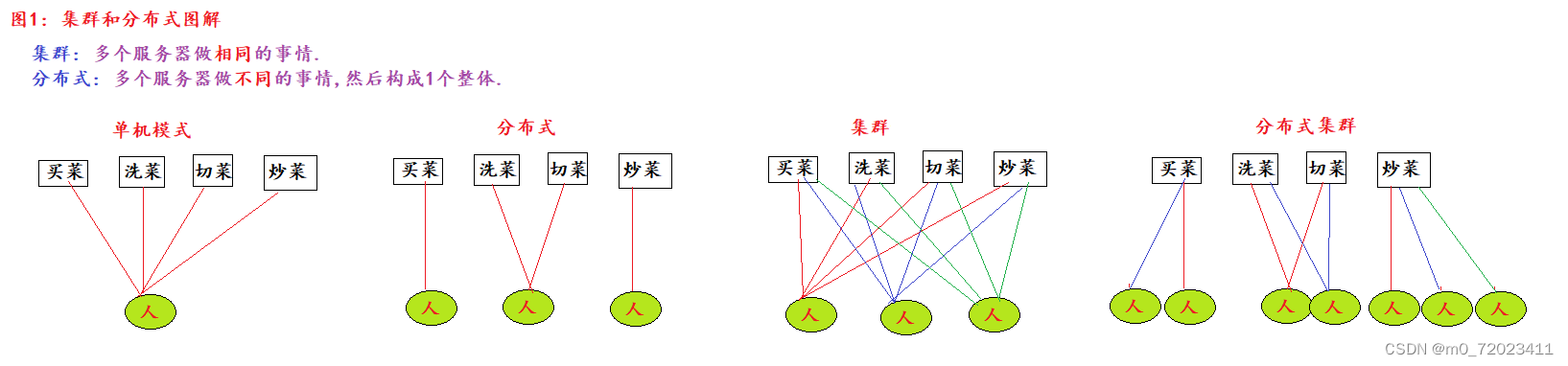
5. 分布式和集群:
分布式:多台机器做不同的事,组成一个整体.
集群: 多台机器做相同的事.
多台机器可以组成 中心化模式 (主从模式),也可以组成 去中心化模式 (主备模式).
二、Hadoop 架构
1、 Hadoop 1.x 架构
Hadoop 1.x = HDFS + MapReduce
HDFS集群中:
namenode 为主节点,负责管理整个HDFS集群 以及 维护和管理元数据.
SecondaryNameNode 为辅助节点,负责辅助namenode管理元数据.
datanode 为从节点,负责维护和管理源文件 、 数据的读、写操作 以及 定时向 namenode 报活.
MapReduce集群中:
JobTracker 为主节点,负责任务的接收、调度、监控 以及 资源的调度和分配.
TaskTracker 为从节点,负责接收并执行 JobTracker 分配过来的计算任务.
元数据:描述数据的数据称之为元数据.
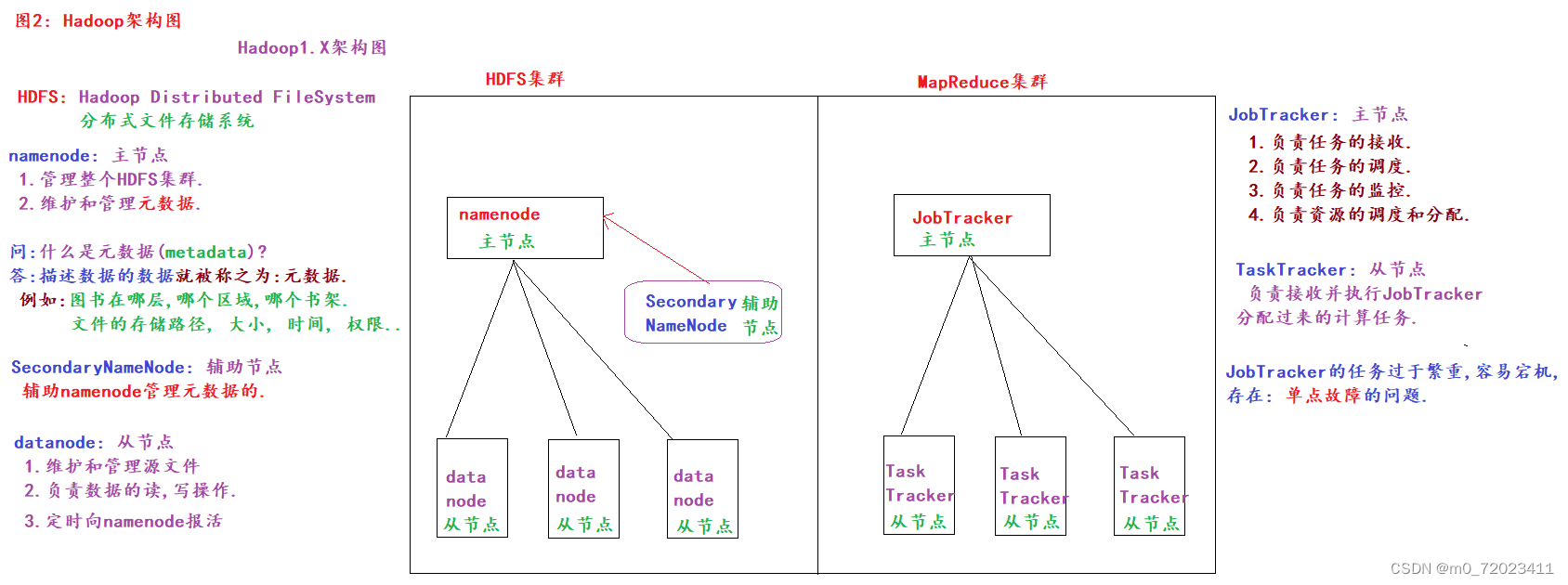
由于 JobTarcker 任务过于繁重,容易宕机. 所以 2.x 3.x 架构有所改变.
2、Hadoop 2.x 3.x 架构
Hadoop 2.x 3.x = HDFS + MapReduce + Ya
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









