爬取安居客上义乌二手房房源的信息
解释:
因为我的Chrome浏览器驱动是直接放在python的主目录下的,所以在创建webdriver对象时并没有直接指定Chrome浏览器驱动的路径。
具体代码如下:
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
import pandas as pd
wd = webdriver.Chrome()
wd.maximize_window()
houses = pd.DataFrame(
columns=['所属小区', '所属区域', '户型', '建面', '朝向', '楼层', '装修', '年份', '电梯相关', '地铁相关', '单价', '价格'])
for j in range(1, 33):
print(f"==========================正在爬取第{j}页================================")
url_link = f"https://yiwu.anjuke.com/sale/p{j}/?from=HomePage_TopBar"
wd.get(url_link)
time.sleep(2)
lists = wd.find_element(By.CSS_SELECTOR, "section.list-main > section.list-left > section.list").find_elements(By.CLASS_NAME, "property")
i = 0
while i < len(lists):
item = lists[i]
url = item.find_element(By.CSS_SELECTOR, "a").get_attribute("href")
print(url)
all_house_data = {}
wd.get(url)
time.sleep(2)
house_community = wd.find_element(By.CLASS_NAME, "maininfo-community").find_elements(By.CLASS_NAME, "maininfo-community-item")[0].find_elements(By.CSS_SELECTOR, "a")[0].text
house_area = wd.find_element(By.CLASS_NAME, "maininfo-community").find_elements(By.CLASS_NAME, "maininfo-community-item")[1].find_element(By.CLASS_NAME, "maininfo-community-item-name").text
house_type = wd.find_element(By.CLASS_NAME, "maininfo-model-item.maininfo-model-item-1").find_element(By.CLASS_NAME, "maininfo-model-strong").text
house_acreage = wd.find_element(By.CLASS_NAME, "maininfo-model-item.maininfo-model-item-2").find_element(By.CLASS_NAME, "maininfo-model-strong").text
house_direction = wd.find_element(By.CLASS_NAME, "maininfo-model-item.maininfo-model-item-3").find_element(By.CLASS_NAME, "maininfo-model-strong-text").text
house_floor = wd.find_element(By.CLASS_NAME, "maininfo-model-item.maininfo-model-item-1").find_element(By.CLASS_NAME, "maininfo-model-weak").text
house_fitment = wd.find_element(By.CLASS_NAME, "maininfo-model-item.maininfo-model-item-2").find_element(By.CLASS_NAME, "maininfo-model-weak").text
house_year = wd.find_element(By.CLASS_NAME, "maininfo-model-item.maininfo-model-item-3").find_element(By.CLASS_NAME, "maininfo-model-weak").text
list_tags = wd.find_element(By.CLASS_NAME, "maininfo-tags").find_elements(By.CLASS_NAME, "maininfo-tags-item")
length_list_tags = len(list_tags)
elevator_correlation = 0
subway_correlation = 0
if length_list_tags > 0:
for item in list_tags:
if item.text == "有电梯":
elevator_correlation = item.text
elif item.text == "近地铁":
subway_correlation = item.text
print(elevator_correlation)
print(subway_correlation)
unit_price = wd.find_element(By.CLASS_NAME, "maininfo-avgprice-price").text
print(unit_price)
total_price = wd.find_element(By.CLASS_NAME, "maininfo-price-wrap").find_element(By.CLASS_NAME, "maininfo-price-num").text
print(total_price)
all_house_data["所属小区"] = house_community
all_house_data["所属区域"] = house_area
all_house_data["户型"] = house_type
all_house_data["建面"] = house_acreage
all_house_data["朝向"] = house_direction
all_house_data["楼层"] = house_floor
all_house_data["装修"] = house_fitment
all_house_data["年份"] = house_year
all_house_data["电梯相关"] = elevator_correlation
all_house_data["地铁相关"] = subway_correlation
all_house_data["单价"] = unit_price
all_house_data["价格"] = total_price
houses = houses._append(all_house_data, ignore_index=True)
print(all_house_data)
wd.back()
time.sleep(2)
lists = wd.find_element(By.CSS_SELECTOR, "section.list-main > section.list-left > section.list").find_elements(By.CLASS_NAME, "property")
i += 1
excel_file_path = "old_house_data.xlsx"
houses.to_excel(excel_file_path, index=False)
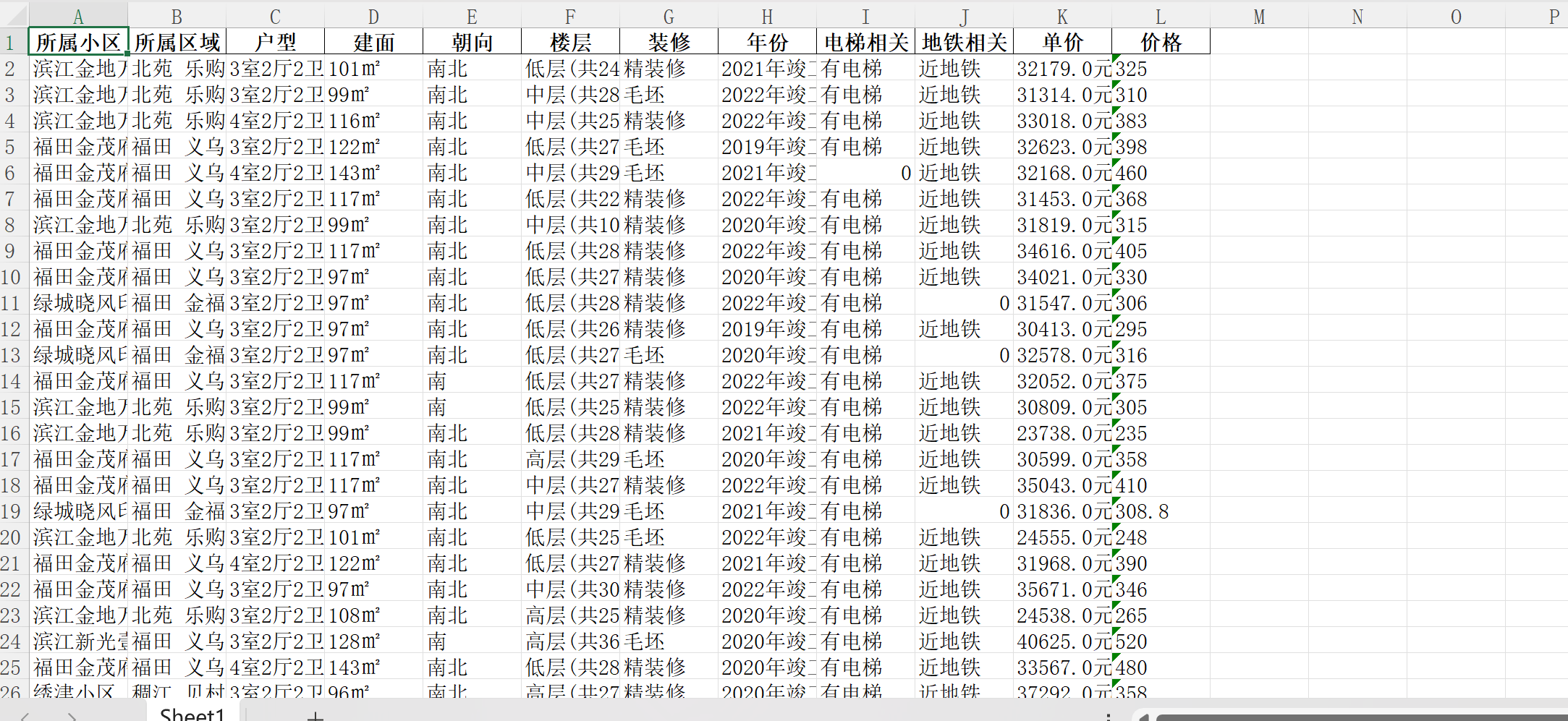
爬下来的数据长这样:


























 1671
1671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









