







上个月8号之后就没有再更新文章了🙈,因为那段期间一直在准备一个篮球比赛哈哈,最后要进决赛的时候结果因为疫情举办终止了,可恶,白费了那么多努力,但是和朋友们每天练习还是很开心的。
之后便开始了学校的网课课程,还有该死的课程设计,就让我python的学习进度一慢再慢。😡😡
如今渐渐的学习又回到了正轨,尽快把落下的学习补上,大家也一起努力鸭💙 💜 ❤️ 💚
一.文件读写
1.文件常识
文件就是储存在某种长期储存设备上的一段数据,可以让程序下一次执行的时候直接使用,而不必再去重新制作一份,省时省力🤤
文件的储存的方式:(本质上还是二进制存储方式)
(1)文本文件:txt、py等,可以使用文本编辑软件查看
(2)二进制文件:图片、音频等,不可以使用文本编辑软件查看
2.文件基础操作:
(1)打开文件:open()
文件中如果是在当前项目中,括号中可以直接使用相对路径。如果不是使用绝对路径
注意open()和close()一定要成对使用,打开后一定要及时关闭
在python中,打开并不意味着可以看到内容,在读取文件后才可以看到内容
f=open("susu.txt") #打开文件,并将其赋给变量
f.close()
(2)访问模式
r:只读模式,文件必须存在,不存在就会报错
w:只写模式,文件存在就会清空原来的内容,再写入新内容,不存在则创新新文件
f=open(r".\susu.txt") #默认为只读模式
print(f.readlines())
print(f.mode) #查看访问模式
f.close()
f=open(r".\susu.txt","w") #只写模式
f.write("111")
print(f.mode) #查看访问模式
f.close()
(3)读文件:
read(n):读取文件
readline():一次读取一行内容,方法执行完,会把指针移动到下一行,准备再次读取
readlines():按照行的方式一次读取所有内容,返回的是一个列表,每一行的数据就是一个元素
write():写入内容
#如果我们想要使用readline来读取全部内容可以使用循环来实现
f=open(r".\susu.txt") #本项目中的文件,可以使用相对路径
while True:
text = f.readline()
print(text)
if text == "":
break
print(text)
f.close()
#如果susu文档中的内容中有回车将内容分隔开会不会退出循环呢
#答案是不会的,因为回车也会有转义字符\n,而不是""
#使用readlines读取全部内容
f=open(r".\susu.txt")
text = f.readlines()
print(text)
f.close()
(4)写文件
根据访问模式中的“w”便可以进行写操作
(5)同时读写文件
使用+可以同时读写文件,但是会影响文件的读写效率,开发中更多时候只会以只读、只写方式来操作文件。
为了饭碗,不能偷得懒还是不能偷懒哦🐾🐾🐾
r+:可读写文件,文件不存在就会报错
w+:先写再读,文件存在就会重新编辑该文件,文件不存在就创建新文件
f=open(r".\susu.txt","w+")
f.write("hello python") #内容重新编辑,原先内容被覆盖
print(f.read()) #没有读取出来,写完之后文件指针在文件内容后面,读取是在指针之后开始读取的
f.close()
(6)追加模式
a:追加模式,不存在就创建新文件进行写入。存在就在原有内容的基础上追加新的内容
f=open(r".\susu.txt","a")
f.write("hello python")
f.close()
如果想要读取内容也可以使用a+来是实现同时读写。
但是运行后会发现同样也读取不出内容,因为指针在文件内容后面
(7)关闭文件
print(f)
print(f.name) #打印文件名
print(f.mode) #打印访问模式 r为read
print(f.closed) #检测关闭状态 未关闭为False,关闭为True
f.close() #关闭文件

(8)指针
文件定位操作:
tell():显示文件指针当前位置
seek():移动文件指针到指定位置
f=open(r".\susu.txt","w+")
f.write("hello python")
print(f.tell()) #12 指针的当前位置
f.seek(0,0) #将指针移动到文件最开头
print(f.read()) #hello python
f.close()
3.编码格式
1.with open()
代码执行完,系统自动调用文件对象的close方法,可以省略文件关闭步骤
大家之后使用这种方法就好,方便还不怕忘记close😋😋😋
with open("susu.txt","w") as f:
f.write("hello world")
print(f.closed) #False
print(f.closed) #True
从结果可以看出来,只有在with下的代码全部执行完之后才会自动调用close方法
2.encoding
file的encoding参数的默认值与平台有关,比如windows上默认字符编码为GBK。
encoding表示编码集,根据文件的实际保存编码进行获取数据,对于我们而言是用更多的是utf-8
with open("susu.txt","w") as f:
f.write("苏钰烯")
#在此时会出现乱码情况
with open("susu.txt","w",encoding="utf-8") as f:
f.write("苏钰烯")
with open("susu.txt", "r", encoding="utf-8") as f:
print(f.readlines())
#当出现中文内容,无论是读还是写都需要设置encoding
3.常用的目录操作
需要对文件进行重命名、删除等操作时,python中的os模块有这些功能
使用前需要先导入os模块 import os
文件重命名:os.rename(旧文件名,新文件名)
删除文件:os.remove(目标文件名)
创建文件夹:os.mkdir(文件夹名)
获取当前目录:os.getcwd()
获取目录列表:os.listdir(目录)
删除文件夹::os.rmdir(文件夹名)
4.练习题:
<1> 将生成的九九乘法表写入文件table.txt 中,再读取文件table.txt 中的内容,并按行输出。
with open("table.txt","w",encoding="utf-8") as f: #最好将读和写模式分开
for i in range(1,10):
for j in range(1,i+1):
f.write(f"{j}*{i}={j*i}\t")
f.write("\n")
#将table文件中的内容都放到content中,再全部输出
with open("table.txt", "r", encoding="utf-8") as f:
content=f.readlines()
for i in content:
print(i)
<2>访客:编写一个程序,提示用户输入其名字;用户作出响应后,将其名字写 入到文件guest.txt 中。
注意:程序判断当用户输入不为q的时候,就执行。
while True: #需要一直输入直到出现q,所以使用循环
name=input("请输入姓名:")
if name=="q":
print("退出程序!")
break
with open("guest.txt","a+",encoding="utf-8") as f: #使用追加模式,并且同时读写
f.write(name+"\t")
f.seek(0,0) #重置指针用来读出内容
print(f.read())
二.线程
1.多任务
指在同一时间内执行多任务,
充分利用cpu资源,提高程序的执行效率
2.多线程
线程是cpu调度的基本单位,程序默认启动会有一个主线程,自己创建的线程为子线程,通过多线程可以完成多任务
需要导入模块 import threading
(1)Thread线程类的常见参数
<1>target:执行的任务名,即运行的函数
<2>args:以元组的形式给执行任务传参,必须要和参数顺序保持一致
<3>kwargs:以字典的形式给执行任务传参,字典中的key必须与参数名保持一致
(2)一般步骤:
<1>导入模块
<2>创建子进程
<4>setDaemon():守护线程,默认为False 主线程执行完了,子线程跟着结束,必须放在start前面
<3>开启子线程:start()
<5>join():阻塞主线程 主线程等待子线程结束后再执行
#<1>导入模块
import time
import threading
def sing():
print("在唱歌")
time.sleep(2)
print("唱歌完了")
def dance():
print("在跳舞")
time.sleep(2)
print("跳舞完了")
#主程序入口
if __name__ == "__main__":
#<2>创建子进程
t1= threading.Thread(target=sing) #任务名后面不需要加括号
t2 = threading.Thread(target=dance)
#<4>setDaemon():守护线程
t1.setDaemon(True)
t2.setDaemon(True)
#<3>开启子线程
t1.start()
t2.start()
#<5>join():阻塞主线程 添加了join()的子线程执行结束,主线程才继续执行,要放在start()后面
t1.join()
t2.join()
print("完美谢幕")
(3)线程执行带有参数的任务
import time
import threading
def sing(name): #引入形参name
print(f"{name}在唱歌")
time.sleep(1)
print(f"{name}唱完了")
def dance(name): #引入形参name
print(f"{name}在跳舞")
time.sleep(1)
print(f"{name}跳完了")
if __name__ == "__main__":
t1=threading.Thread(target=sing,args=("susu",)) #给出实参args,类型为元组,只有一个元素需要加逗号,不然会被识别为四个字符
t2 = threading.Thread(target=dance, kwargs={"name":"susu"})
t1.start()
t2.start()

3.线程执行的无序性
线程执行是根据cpu调度来决定的
import time
import threading
def task():
time.sleep(1)
print("当前启动的线程是:",threading.current_thread())
if __name__ == "__main__":
for i in range(3):
t = threading.Thread(target=task)
t.start()
我们可以看出相同代码,两次运行的结果并不相同。结果显示的也很不规律,这是因为资源的竞争。


4.线程之间共享资源(全局变量)
import time
import threading
li=[]
def wdata():
for i in range(5):
li.append(i)
time.sleep(1)
print("写入的数据为:",li)
def rdata():
print("读出的数据",li)
if __name__ == "__main__":
d1=threading.Thread(target=wdata)
d2 = threading.Thread(target=rdata)
d1.start()
d2.start()

稍加思考我们就可以知道d1进程执行的话需要至少5秒,但是d2几乎就是一瞬间的事。花费的时间不同,所以执行的顺序是先读再写的。如果我们想要先写再读的话我们可以阻塞线程d1
import time
import threading
li=[]
def wdata():
for i in range(5):
li.append(i)
time.sleep(1)
print("写入的数据为:",li)
def rdata():
print("读出的数据",li)
if __name__ == "__main__":
d1=threading.Thread(target=wdata)
d2 = threading.Thread(target=rdata)
d1.start()
d1.join() #阻塞线程, 主线程等待d1执行结束后代码再继续往下执行
d2.start()

5.资源竞争
多个任务共享一个资源时,会产生资源竞争
注意设置的值小显示会是正常的,设置的值较小的话,不会有资源竞争的问题,只有值大的时候,计算机计算不过来,延长时间更明显,在等待的时候可以执行另外一个任务,所以就会有资源竞争问题
import time
import threading
a=0
def add1():
for i in range(1000000):
global a
a+=1
print("第一次结果为",a)
def add2():
for i in range(1000000):
global a
a += 1
print("第二次结果为", a)
if __name__ == "__main__":
t1=threading.Thread(target=add1)
t2 = threading.Thread(target=add2)
t1.start()
t2.start()

5.线程同步
(1)含义
线程A写入,线程B读取线程A写入的内容:线程A先写入,线程B才能读取。线程A与线程B就是一种同步关系。编程是西方发明的,所以在同步和异步的理解上与我们有所偏差
同步:先聊天再听音乐;先烧水再泡面
异步:边聊天边听音乐;边烧水边放调料
(2)实现方式
<1>线程等待join()
也就是阻塞线程,与上面我们使用的方法相同
import time
import threading
a=0
def add1():
for i in range(1000000):
global a
a+=1
print("第一次结果为",a)
def add2():
for i in range(1000000):
global a
a += 1
print("第二次结果为", a)
if __name__ == "__main__":
t1=threading.Thread(target=add1)
t2 = threading.Thread(target=add2)
t1.start()
t1.join() #等待t1子线程执行结束后在继续往下执行
t2.start()
<2>互斥锁
对共享数据进行锁定,保证多个线程访问共享数据不会出现数据错误问题:保证同一时刻只能有一个线程去操作
acquire:上锁 release:释放锁
这两个方法必须成对出现,不然容易出现死锁
互斥锁是多个线程一起去抢,抢到锁的线程先执行,没有抢到的就需要等待,等待互斥锁使用完释放后,其他等待的线程再去抢这个锁
import time
import threading
l=threading.Lock()
a=0
def add1():
l.acquire() #上锁
for i in range(1000000):
global a
a+=1
print("第一次结果为",a)
l.release() #解锁
def add2():
l.acquire() #上锁
for i in range(1000000):
global a
a += 1
print("第二次结果为", a)
l.release() #解锁
if __name__ == "__main__":
t1=threading.Thread(target=add1)
t2 = threading.Thread(target=add2)
t1.start()
t2.start()
弊端:会影响代码的执行效率(因为原本是一个多任务同时执行的,这样就变成了单任务执行),而且如果没有使用好容易出现死锁情况(一直在等待对方释放锁的情况,会造成应用程序停止响应,不能再处理其他任务)
三.进程
进程是操作系统进行资源分配和调度的基本单位,是操作系统结构的基础
一个正在运行的程序,软件都可以是一个进程。
一个运行的程序至少会有一个进程,一个进程默认会有一个线程,进程里面可以创建多个线程,线程是依附在进程里面的,没有进程就没有线程
1.状态
就绪态:运行的条件都已经满足,正在等cpu执行
执行态:cpu正在执行其功能
等待态(阻塞状态):等待某些条件满足 例如time.sleep()
2.进程语法结构
需要引进新的模块
multiprocessing模块提供了一个Process类代表一个进程对象
<1>进程常见属性:
name:当前进程的别名
pid:当前进程的编号
import time
import threading
from multiprocessing import Process
def sing():
print("在唱歌")
time.sleep(1)
print("唱完了")
def dance():
print("在跳舞")
time.sleep(1)
print("跳完了")
if __name__ == "__main__":
#创建子进程
p1=Process(target=sing,name="进程一")
p2=Process(target=dance,name="进程二")
#开启子进程
p1.start()
p2.start()
print(f"p1:",p1.name)
print(f"p2:",p2.name)
print(f"p1子进程编号:",p1.pid)
print(f"p2子进程编号:", p2.pid)
如果进程里面不加其他操作,只是创建开启,会先执行主进程的代码
所以在运行结果中会先执行主线程(先输出两个子线程的名字和编号),再运行两个子线程

进程编号还可以通过os模块中的getpid()方法来获取
os.getpid():访问当前进程编号 os.getppid():访问当前进程的父进程编号
import threading
from multiprocessing import Process
import os
def sing():
print("在唱歌")
print(f"sing子线程编号:{os.getpid()},父进程编号:{os.getppid()}")
def dance():
print("在跳舞")
print(f"dance子线程编号:{os.getpid()},父进程编号:{os.getppid()}")
if __name__ == "__main__":
p1=Process(target=sing)
p2=Process(target=dance)
p1.start()
p2.start()
print(f"主线程编号:{os.getpid()}")
print(f"主线程父进程编号:{os.getppid()}")
子进程的父进程可以理解为这个py文件的主进程。所以我们才看到p1和p2的父进程编号和主线程编号相同,都为38356。

那么主线程的父进程是什么呢?
我们可以使用cmd命令提示符窗口查看电脑内的进程编号,使用命令tasklist就可以查看
我哦们可以看出pycharm64进程编号就是主线程的父进程编号41448

总结:
自己创建的是子进程(函数)➡️子进程的父进程就是主进程(py文件)➡️主进程的父进程就是pycharm软件
<2>进程常见方法与参数:
方法:
start():开启子进程
join():阻塞,主进程等待子进程执行结束
is_alive():判断子进程是否存活,如果存活返回True
参数:
target:子进程要执行的函数,也就是要执行的函数
args:以元组的形式给执行任务传参
kwargs:以字典的形式给执行任务传参
import threading
from multiprocessing import Process
import os
import time
def sing(name):
print(f"{name}在唱歌")
time.sleep(1)
print("唱完了")
def dance(name):
print(f"{name}在跳舞")
time.sleep(1)
print("跳完了")
if __name__ == "__main__":
p1=Process(target=sing,args=("susu",)) #以元组的形式给执行任务传参
p2=Process(target=dance,kwargs={"name":"susu"}) #以字典的形式给执行任务传参
p1.start()
p1.join() #主线程等待p1子线程结束后再继续执行
p2.start()
print("p1:",p1.is_alive())
print("p2:", p2.is_alive())
在这个例子中,p1使用了join方法,主线程就会先等待p1执行结束后再继续执行最下面判断存活状态的代码,p1的存活状态为False,之后接着执行主线程判断p2的存活状态为True,再执行p2.start()

3.进程间不共享资源(全局变量)
在进程中我们也讨论过这个问题,同样的设置一个空数组,一个写函数,一个读函数。因为time.sleep方法所以读函数先运行,就会是读出空数组,在写函数开始后加入的join方法解决了问题。我们将同样的方法运用于在了进程中,但是发现并没有读出数据。
这是因为在进程中是不共享资源的!!!
from multiprocessing import Process
import time
li=[]
def wdata():
for i in range(5):
li.append(i)
time.sleep(1)
print(f"输入数据为:",li)
def rdata():
print(f"输出数据为{li}")
if __name__ == "__main__":
p1=Process(target=wdata)
p2=Process(target=rdata)
p1.start()
p1.join()
p2.start()

4.进程间的通信
<1>Queue队列基本使用
记得引入模块Queue
put():放入数据 get():取出数据 empty():判断队列是否为空
qsize():返回当前队列包含的消息数量 full():判断队列是否已满
from multiprocessing import Process,Queue
import time
q=Queue(3)
q.put("张三")
q.put("李四")
print(q.empty()) #False
print(q.qsize()) #2
print(q.full()) #False
q.get("张三")
q.get("李四")
print(q.empty()) #True
print(q.qsize()) #0
<2>进程操作队列
因为全局变量不共享,所以我们要将数据写进queue来实现进程间的通信
from multiprocessing import Process,Queue
import time
li=["张三","李四","王五"]
def wdata(q):
#把数据写入队列中
for i in li:
print(f"写入数据:{i}")
q.put(i)
time.sleep(0.2)
def rdata(q):
#只要队列中有消息就取出来
while True:
#判断是否有消息
if q.empty():
break
else:
print(f"取出数据",q.get())
if __name__ == "__main__":
q=Queue()
p1=Process(target=wdata,args=(q,))
p2 = Process(target=rdata, args=(q,))
p1.start()
p1.join() #等待p1进程结束再执行p2
p2.start()

5.进程池
<1>作用
如果要实例化几十个甚至上百个进程,需要实例化多个进程对象,使用进程池可以帮我们更好的解决这个问题
<2>常用方法
需要引入新模块Pool
apply_async():异步非阻塞执行,不用等待当前进程执行,随时根据系统调用来进行进程切换(如果 是使用异步提交任务,等进程池内任务都处理完,需要用get()来处理结果)
close():关闭进程池,不再接受新的任务(在创建后一定要先记得关闭)
join():主进程阻塞,等待所有工作的子进程退出,必须在close()之后调用
import time
from multiprocessing import Pool,Process
def task(num):
print("执行任务。。。")
time.sleep(1)
return num*5
if __name__=="__main__":
p=Pool(3) #实例化一个进程池对象,最大进程数为3
li=[]
for i in range(8):
#执行任务:apply_async(执行任务,参数)
res=p.apply_async(task,args=(i,))
print(f"res:",res)
li.append(res)
#关闭进程池
p.close()#注意,如果代码在这行结束,没有下面代码的话,结果只会有8条看不懂的东西。因为会先执行主程序,会关闭进程池而来不及执行子进程。也没有使用get来处理结果
#等到进程中所有子进程执行完毕
p.join()
for i in li: #i就是res,使用循环来把res给get处理
print(i.get())

四.携程
1.含义:
又称为微线程,比线程需要的运行单位更小(需要的资源更少)
线程和进程是由程序除法系统接口,最后的执行者是系统,携程的操作是程序员,可以根据程序员的想法去修改。
2.适用场景
当一个线程中的IO操作较多时,携程比较适用 IO操作:Input、Output(输入输出)
适用于高并发处理
3.实现方式
<1>greenlet
【1】下载
【1】下载
C语言实现的携程模块,通过设置switch()实现任务之间的切换
可以通过cmd命令提示符窗口输入指令:pip install greenlet 进行下载
如果出现Fatal error则为下载失败,可以使用指令: pathon -m pip install greenlet
成功后会出现Successfully installed
通过指令:pathon -m pip uninstall greenlet 可以进行删除
查看已经安装的所有模块:python -m pip list
同样的操作也适用于pycharm中的terminal

如果出现下载成功,在list’中也有greenlie,但是在引用时却不能正常使用时
需要注意下载模块的解释器必须和当前当前程序使用的解释器相同,可以在File-Settings

在这里配置正确的解释器
注意不要将py文件的名称与模块名重名,否则容易引发冲突,导致模块功能无法使用
【2】通过greenlet实现任务切换
【2】通过greenlet实现任务切换
在greenlet中,携程的执行是通过switch来实现的,没有start方法。也是通过switch来实现任务的切换的(即手动切换)。而且参数的传递也是通过switch来传递
from greenlet import greenlet
def sing(name):
print(f"{name}在唱歌")
print("唱完歌了")
def dance(name):
print(f"{name}在跳舞")
print("跳舞完了")
if __name__=="__main__":
g1=greenlet(sing)
g2=greenlet(dance)
g1.switch("susu")
g2.switch("susu")

from greenlet import greenlet
def sing():
print("在唱歌")
g2.switch()
print("唱完歌了")
def dance():
print("在跳舞")
print("跳舞完了")
g1.switch()
if __name__=="__main__":
g1=greenlet(sing)
g2=greenlet(dance)
g1.switch()

先执行主程序,即g1,“在唱歌”后跳到g2,执行“在跳舞”“跳舞完了”,再跳回g1上次执行到的位置继续往下执行,执行“唱完歌了”。
即使是在一个循环中,跳走又跳回来时,也会接着上次的继续执行
<2>gevent
【1】含义
【1】含义:
遇到IO操作,会自动进行切换,属于主动式切换
gevent底层是通过greenlet完成
还是需要自己下载,这次在Terminal进行下载:

之后出现Successfully installed字眼便是成功下载
【2】基本使用
【2】基本使用
spawn():创建携程对象
sleep():耗时操作
join():阻塞,等待某个携程执行完毕
joinall():等待所有的携程都执行完毕再退出,参数是一个携程对象列表
import gevent
import time
def sing():
print(f"在唱歌")
print(f"唱完歌了")
def dance():
print(f"在跳舞")
print(f"跳完舞了")
if __name__=="__main__":
#创建携程对象
g1=gevent.spawn(sing)
g2=gevent.spawn(dance)
#写到这里直接直接运行是不会有结果的,因为主进程运行结束了,携程就不会来帮助运行了
#阻塞,等待携程执行完毕
g1.join()
g2.join()
我们再在函数中加入耗时操作
import gevent
import time
def sing():
print(f"在唱歌")
gevent.sleep(1) #time.sleep不能实现自动切换,需要使用gevent中的sleep
print(f"唱完歌了")
def dance():
print(f"在跳舞")
gevent.sleep(1)
print(f"跳完舞了")
if __name__=="__main__":
g1=gevent.spawn(sing)
g2=gevent.spawn(dance)
g1.join()
g2.join()
gevent模块中有自己的sleep(),使用其时cpu会自动跳转到另一个任务执行,也就是说通过这个耗时函数就可以达到自动切换的效果。
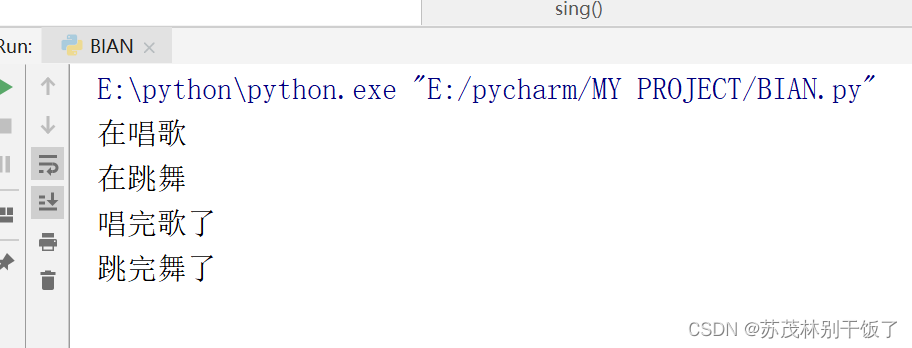
如果使用time.sleep,运行结果就像我们调用函数一样,先运行sing,在运行dance
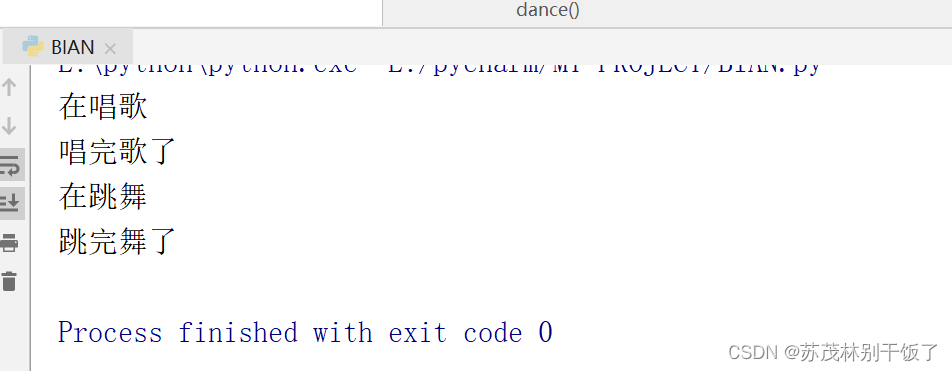
【3】给程序打猴子补丁
【3】给程序打猴子补丁
在模块运行时候,自动将time.sleep()替换为gevent.sleep()
需要引入模块:from gavent import monkey
import gevent
from gevent import monkey
import time
monkey.patch_all() #猴子补丁
def sing():
print(f"在唱歌")
time.sleep(1)
print(f"唱完歌了")
def dance():
print(f"在跳舞")
time.sleep(1)
print(f"跳完舞了")
if __name__=="__main__":
#创建携程对象
g1=gevent.spawn(sing)
g2=gevent.spawn(dance)
g1.join()
g2.join()
【4】基本使用中的joinall()方法
【4】基本使用中的joinall()方法
等待所有的携程执行完毕再退出。
在一些程序中的对象是非常多的,不可能挨着去使用join方法。便可以直接使用joinall方法,在里面进行创建对象、传参等操作。
import gevent
from gevent import monkey
import time
monkey.patch_all() #猴子补丁
def sing(name):
for i in range(3):
print(f"{name}在唱第{i}首歌")
time.sleep(1)
if __name__=="__main__":
gevent.joinall([
gevent.spawn(sing,"su."), #创建对象,传参
gevent.spawn(sing,"su`")
])
五.正则表达式
1.含义
需要导入模块 import re
记录文本规则的代码
特点:语法偏复杂,可读性较差。通用性较强,适用于多种编程语言
2.基本语法:
re.match(pattern,string,flags): 从字符串的开始位置进行匹配,匹配成功返回match对象,匹配失败返回None
pattern:匹配的正则表达式
string:要匹配的字符串
flags:标志位,用于控制正则表达式的匹配方式,多数情况下用不到
import re
res=re.match("s","susu")
print(f"{res}")
print(res.group()) #匹配到的数据需要用group来提取

注意是在字符串的开始位置进行匹配,现在我们将字符串改变一下
import re
res=re.match("s","1susu")
print(f"{res}")
print(res.group())

在首字母发生改变后,我们在尝试一下
import re
res=re.match("s","1susu")
print(f"{res}")
print(res.group())

在改变后字符串匹配失败,返回None。而None是没有group方法的,所以之后会报错。
<1>匹配单个字符
【1】 . :匹配任意一个字符,除\n除外
import re
res=re.match(".","1susu")
print(res.group()) #1
【2】 [] :匹配[]中列举的字符,[]中的可以读取单个字符,还可以填写多个字符,连续的字母或 数字也可以简写[0-9],[A-Z],[a-z],还可以填1-9中除4外的数字[1-35-8]。
import re
res=re.match("[1-9]","56789")
print(res.group()) #5
【3】 \d :匹配数字0-9
import re
res=re.match("\d","56789")
print(res.group()) #5
【4】 \D :匹配非数字
import re
res=re.match("\D","(56789")
print(res.group())
【5】 \s :匹配空白
import re
res=re.match("\s"," 56789")
print(res.group()) #\n \t都可以匹配到
【6】 \S :匹配非空白
import re
res=re.match("\S","我56789")
print(res.group()) #我
【7】 \w :匹配单词字符:a-z、A-Z、_、0-9、汉字
import re
res=re.match("\w","苏56789")
print(res.group()) #苏
【8】 \W :匹配非单词字符
import re
res=re.match("\W","@苏56789")
print(res.group()) #@
<2>匹配多个字符
【1】 * :匹配前一个字符出现0次或无数次,即可有可无
import re
res=re.match("\d*","56789abc")
print(res.group()) #56789
【2】 + :匹配前一个字符出现1次或无数次,即至少有一次
import re
res=re.match("\d+","12abc")
print(res.group()) #12
【3】 ? :匹配前一个字符出现0次或1次,即要么有一次,要么没有
import re
res=re.match("\d?","233335abc")
print(res.group()) #2
【4】{m} :匹配前一个字符出现m次
import re
res=re.match("\d{3}","233335abc")
print(res.group()) #233
【5】{m,n}:匹配前一个字符出现m-n次
import re
res=re.match("\d{2,5}","233335abc")
print(res.group()) #23333
<3>匹配开头和结尾
这两种规则在match方法中很闲的很鸡肋,但是在findall中就会体现到他的作用
【1】 ^ :匹配字符串开头
import re
res=re.match("^\d*","233335abc")
print(res.group()) #233335
在[]中还表示取反
import re
res=re.match("[^abc45]","233335abc")
print(res.group()) #2
【2】 $ :匹配字符串结尾
import re
res=re.match("\w*u$","woshisusu")#表示匹配该字符串以u结尾,并匹配所有的单个字符
print(res.group()) #woshisusu
<4>匹配分组
【1】 | :匹配左右任意一个表达式
import re
res=re.match("\d|\s","13ab")
print(res.group()) #1
【2】 (ab) :将括号中字符作为一个分组
import re
res=re.match("\w*@(qq|126|163)\.com","12345@qq.com")
print(res.group()) #12345@qq.com
【3】 \num :引用分组num匹配到的字符串
res=re.match(r"<(\w*)><(\w*)></\2></\1>","<head><js></js></head>")
print(res.group()) #<head><js></js></head>
#\1可以直接代替第一个括号内的内容,\2同理。从外到内进行排序,编号从1开始
小测试
li=['www.taobao.com','www.jd.cn','www.abc.n','www.python.org']
for i in li:
res=re.match('www\..*\.(com|cn|org)',i)
if res:
print(res.group())
else:
print('网址有错误')
【4】 (?P) :分组起别名
【5】 (?P=name) :引用别名为name分组匹配到的字符串
<5>findall()&贪3婪&非贪婪
re.findall(pattern,string,flags):从头到尾进行匹配,找到所有匹配成功的数据,返回一个列表,如果没有匹配的就返回空列表
import re
res=re.findall("\d","12345acvfd")
print(res) #['1', '2', '3', '4', '5']
res=re.findall("\d{3}","15ac1456v123456789fd")#\d{3}是一个整体,所以匹配的是三个连续数字
print(res) #['145', '123', '456', '789']
贪婪匹配:满足匹配时,匹配尽可能长的字符串,默认情况下采用贪婪匹配
非贪婪匹配:满足匹配时,匹配尽可能短的字符串,使用?来表示非贪婪
import re
res=re.findall("\w+","12345acvfd")
print(res) #['12345acvfd']
res=re.findall("\w+?","12345acvfd")
print(res) #['1', '2', '3', '4', '5', 'a', 'c', 'v', 'f', 'd']
正则表达式我认为我是没有学明白的,感觉还是想没有学一样☹️☹️
因为我意会不到在我的实操中这个东西可以发挥怎么样的作用。在使用HTML时我知道在有些时候会用到正则表达式来限制用户输入的格式。但是当自己来实现这个东西时是一头雾水。
这篇博客就这样结束啦,希望仙女帅哥们多多三连
在2023年1月5日我又回来看正则表达式了,,这次豁然开朗,有了一些补充嘎嘎嘎















 2439
2439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











