







hive 函数
hive 同传统的关系型数据库一样含有大量内置函数,方便用户直接使用,同时hive也支持用户自定义函数,可以根据实际使用场景编写函数如,UDF,UDTF,UDAF
一、hive 内置函数
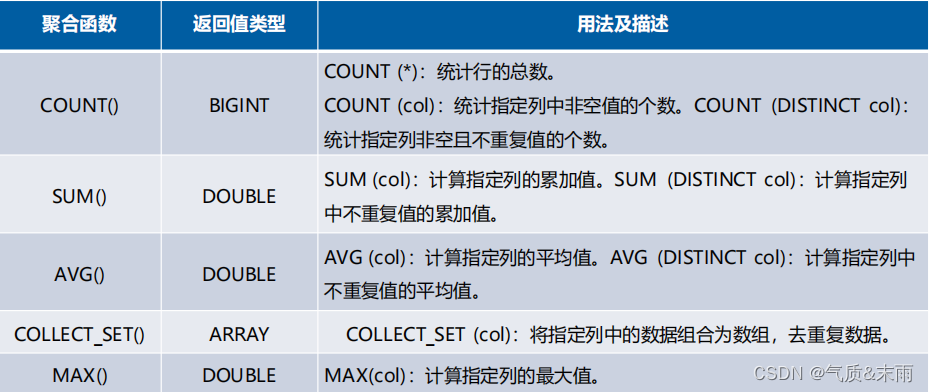
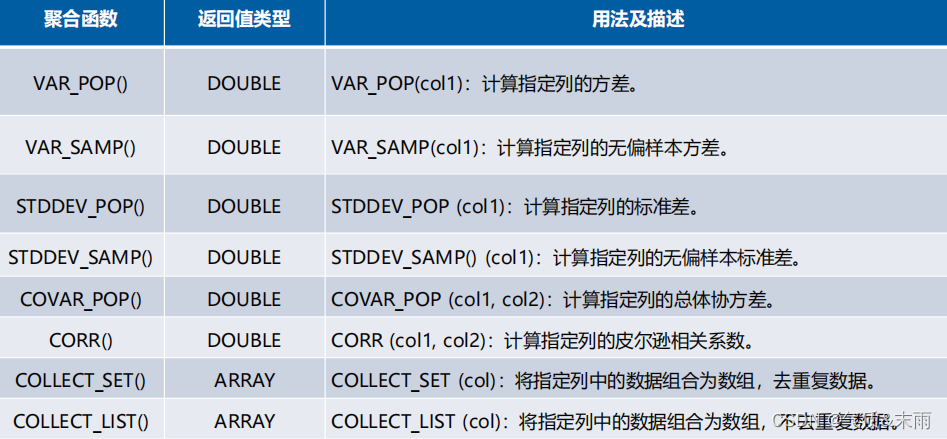
1、聚合函数
聚合函数是按照特定条件对一组值进行计算,通常与select语句的group by 子句一起使用
下面是常用的聚合函数,比如计数,求和,求平均值,求最大值
聚合函数在实际中的如何使用,下面演示count,sum,max,collect_set 等聚合函数的基本使用
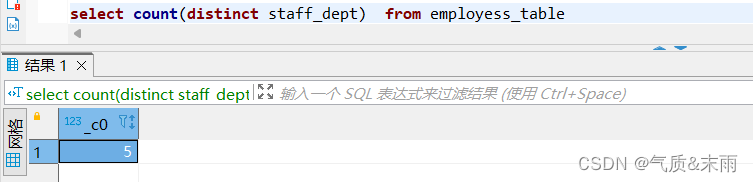
(1)、统计员工信息表employess_table中的部门数
输入命令: select count(distinct staff_dept) from employess_table
使用count 函数 对staff_dept 部门字段进行计数,统计部门前面记得要使用distinct 关键字去重,不然同样的也排进去了,
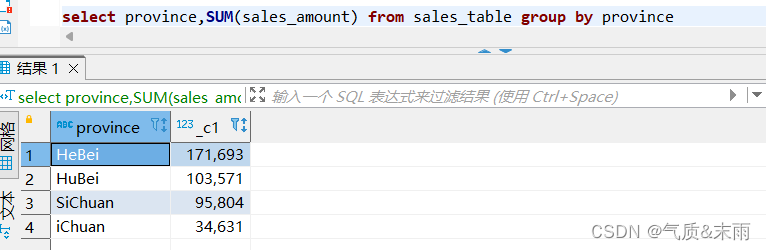
(2)、统计商品销售表sales_table 中每个省份的销售额
输入命令:select province,sum(sales_amount) from sales_table group by province
使用sum函数对销售金额字段 sales_table 求总和 因为是求各个省的所有对省份 province 字段进行分组
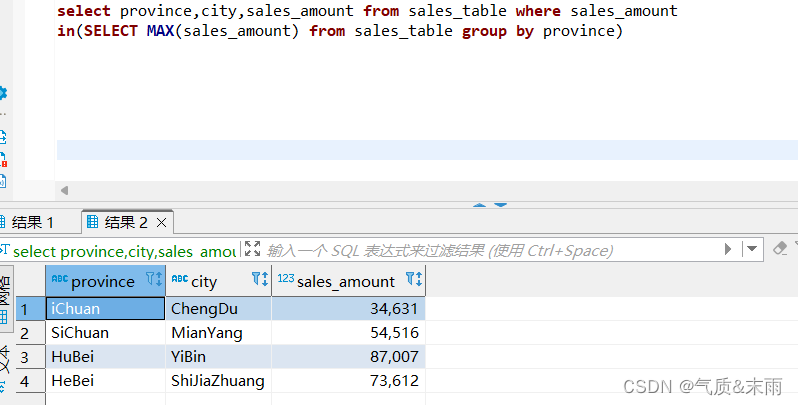
(3)、获取销售额最高的城市
输入命令: select province,city,sales_amount from sale_table where sales_amount in(select max(sales_amount) from sales_table group by province)
先把这个表所有的字段进行查询, 然后where 条件 使用 in函数,括号里面进行子查询 sales_amount 字段求最大值,然后对省份进行分组,因为前面是所有字段所以说有城市这个字段,按照省份分组,有一个最大的值要是匹配到那个城市会显示出来的.
select province,city,sales_amount from sale_table where sales_amount in(select max(sales_amount) from sales_table group by province)
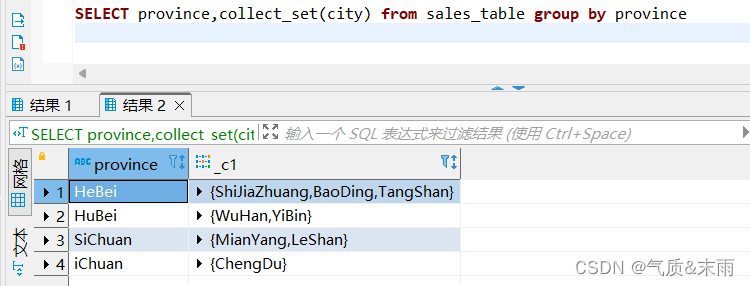
(4)、获取商品销售表sales_table每个省份包含的城市
输入命令: select province,collect_set(city) from sales_table group by province
使用collect_set 函数 以数组的形式返回城市,然后后面对省份进行分组 就可以的到每个省份所包含的城市
2、数学函数
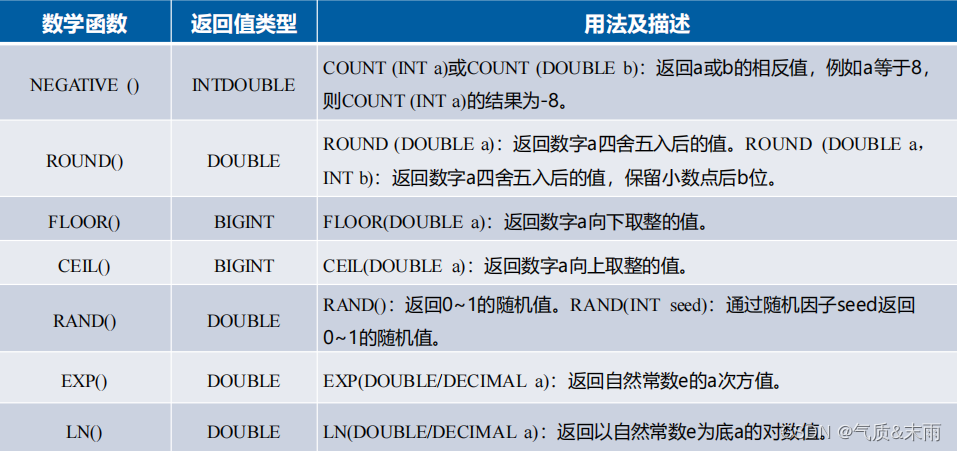
数学函数是针对数字类型的值进行计算
下面是常用的数学函数
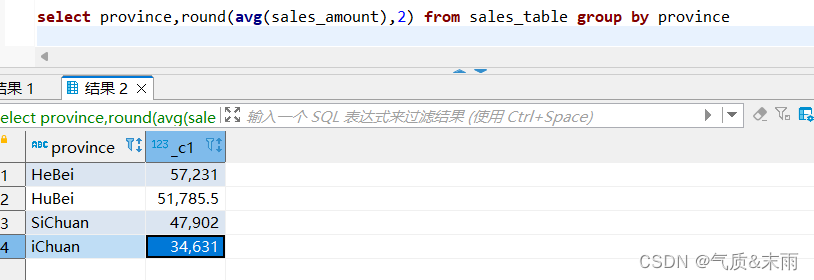
(1)、获取商品销售表sales_table中每个省份的平均销售额
输入命令: select province,round(avg(sales_amount),2) from sales_table group by province
使用 ave 函数 对销售额字段取平均值,然后对省份进行分组, 使用round()函数对销售额平均值,取小数点后2位
3、集合函数
集合函数式针对集合数据类型进行操作
下面是常用的集合函数:
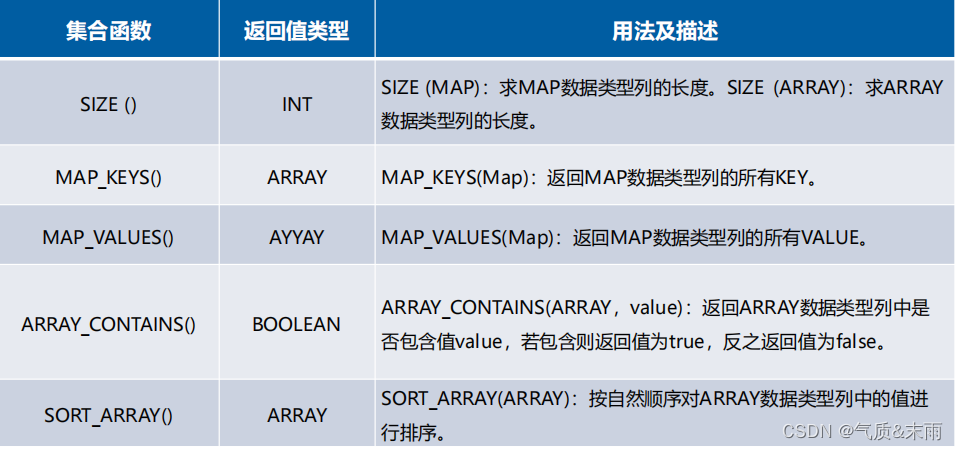
(1)、判断学生考试成绩表 student_exam_table 中意向大学填写了Peking University 的学生
输入命令:select array_contains(intent_university,"Peking University") from student_exam_table
使用 集合函数中的 array_contains() 返回意向大学的那个字段,第一个参数是查询的那个集合的字段,第二个参数是要查询的具体的元素的值,如果有这个值的话会返回v 如果没有的话会返回空列表。 查询出意向大学填写了Peking University 的学生只有两个ndy 和 Ben

4、类型转换函数
类型转换函数是对查询结果的数据类型进行转换,适用于基本数据类型数据的操作

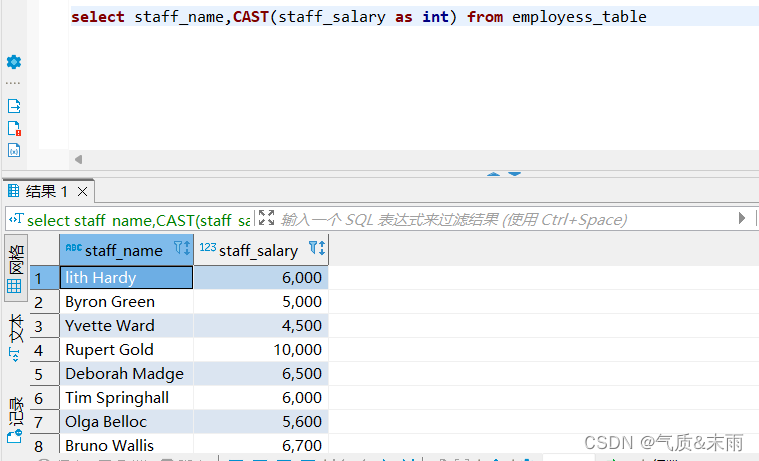
(1)、获取员工信息表 employess_table 中员工薪资的整数数据
输入命令:select staff_name,cast(staff_salary as int) from employess_table
使用 类型转换函数 cast() 对 staff_salary 工资字段函数进行数据转换,第一个参数是要转换的字段as 是表示进行转换,最后那个参数是要转换成什么数据类型,这里是转换成 int 整数类型
5、日期函数
日期函数是对日期数据类型的数据进行操作
下面是常用的日期函数

现在在数据库 hive_database 中创建日期表 date_table
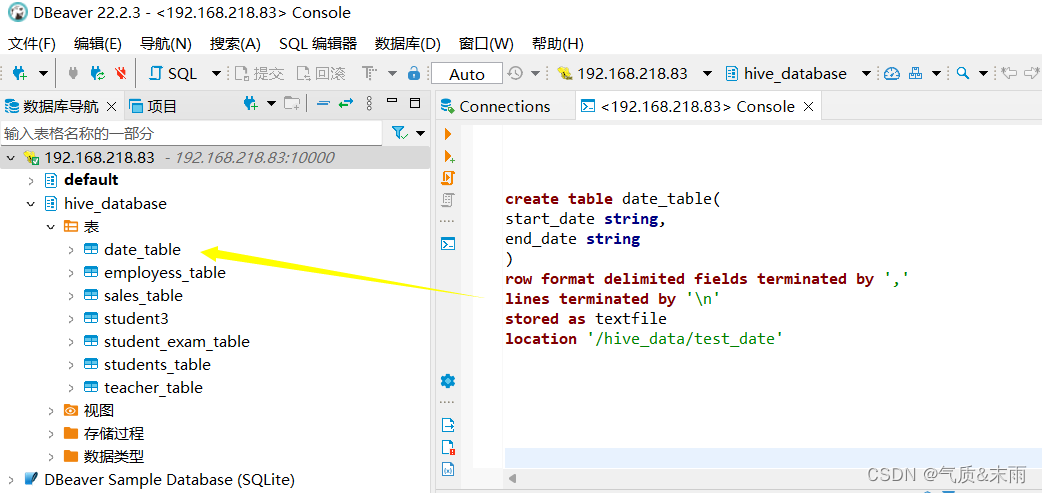
下面是创建日期表的 date_table 的sql语句
create table date_table(
start_date string,
end_date string
)
row format delimited fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/hive_data/test_date'
向日期表date_table 中插入两条数据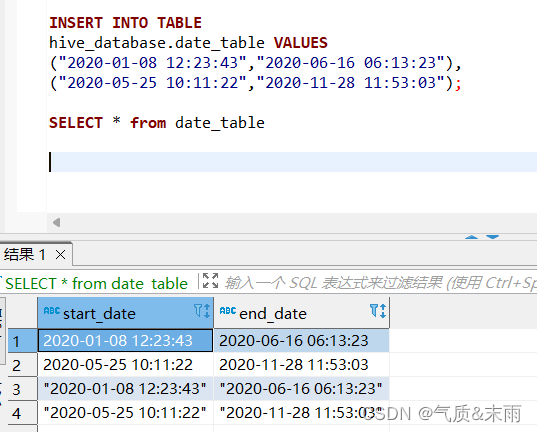
INSERT INTO TABLE
hive_database.date_table VALUES
("2020-01-08 12:23:43","2020-06-16 06:13:23"),
("2020-05-25 10:11:22","2020-11-28 11:53:03");
(1)、计算日期表date_table中,开始日期与结束日期相差的月以及开始日期与当前日期相差的月
使用 current_timestamp() 函数获得当前的时间 然后更名为 now_date字段,然后使用 months_betwwn() 函数 ,里面的两个参数是结束日期和开始日期,一定要用后面的日期减前面的日期不然会有负数,他返回的值是两个年份时间相差的月份,使用round() 函数把返回的结果保留小数点后1位, 最后返回的值更名为 between_start_end_date 字段 可以看到 结束日期和开始日期差了 5.2个月
注意:三个date函数日期均只能为’yyyy-MM-dd’格式 & 'yyyy-MM-dd HH:mm:s’格式
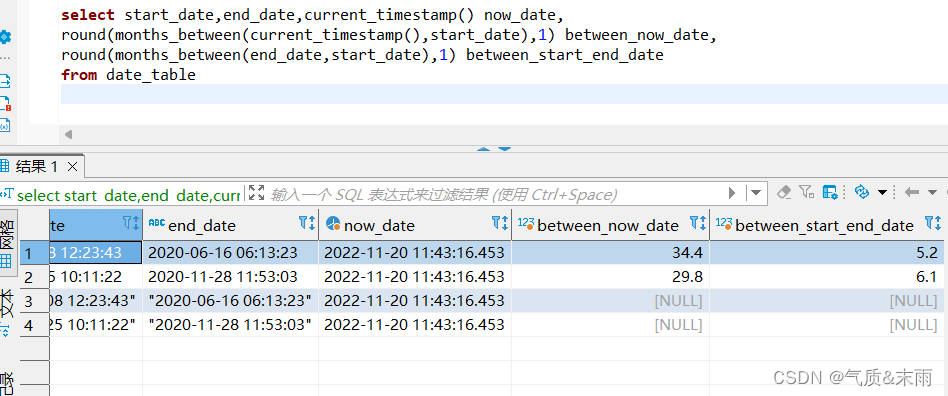
下面是查询现在的日期和开始的日期相差的月和结束日期和开始日期相差的月的sql语句:
select start_date,end_date,current_timestamp() now_date,
round(months_between(current_timestamp(),start_date),1) between_now_date,
round(months_between(end_date,start_date),1) between_start_end_date
from date_table
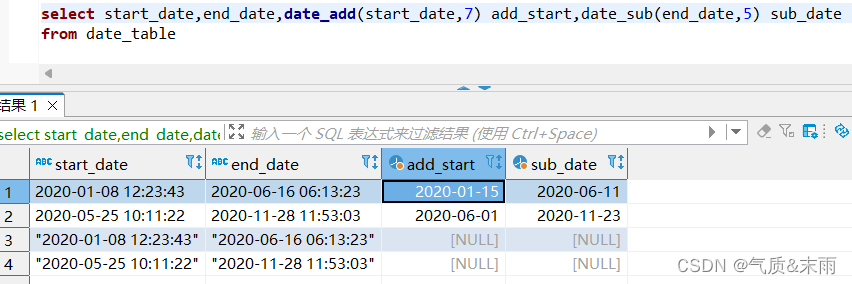
(2)、在日期表date_table 中,将开始日期延迟7天,结束日期提前五天
输入命令:select start_date,end_date,date_add(start_date,7) add_start,date_sub(end_date,5) sub_date from date_table
使用date_add() 函数 将日期参数传入,第二个参数是要延迟的天数, 使用date_sub() 函数将日期传入 ,第二个参数是要提前结束的参数 ,返回的值是计算过后的日期
注意:三个date函数日期均只能为’yyyy-MM-dd’格式 & 'yyyy-MM-dd HH:mm:s’格式
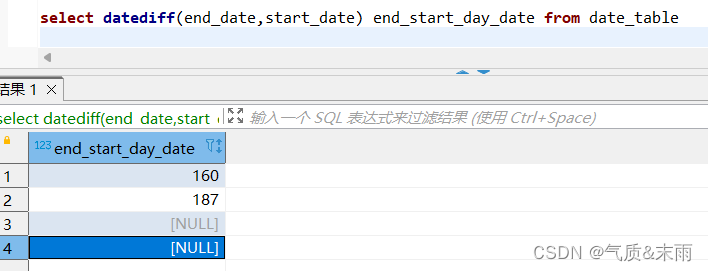
(3)、计算日期表date_table 中,开始日期和结束日期之间相差的天数
输入命令: select datediff(end_date,start_date) end_start_day_date from date_table
使用 datediff() 函数,里面的两个参数 是两个要计算相差时间的参数,返回的是两个时间相差的天数 将这个字段更名为 end_start_day_date 查询出第一个时间相差160 天,第二个时间相差187天
注意:三个date函数日期均只能为’yyyy-MM-dd’格式 & 'yyyy-MM-dd HH:mm:s’格式
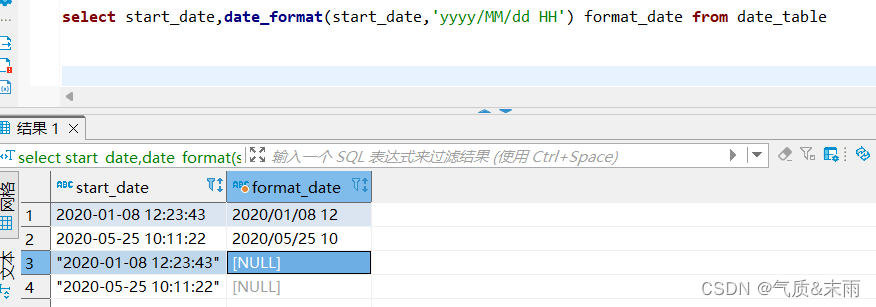
(4)、将日期表date_table中开始日期的时间格式化为yyy/MM/dd HH的形式
输入命令: select start_date,date_format(start_date,'yyyy/MM/dd HH') format_date from date_table
使用 date_format() 函数,第一个参数是是要转换形式的时间参数,第二个参数是要转化为什么形式,将时间之间的- 转换为/
6、条件函数
条件函数式根据条件判断结果返回指定值

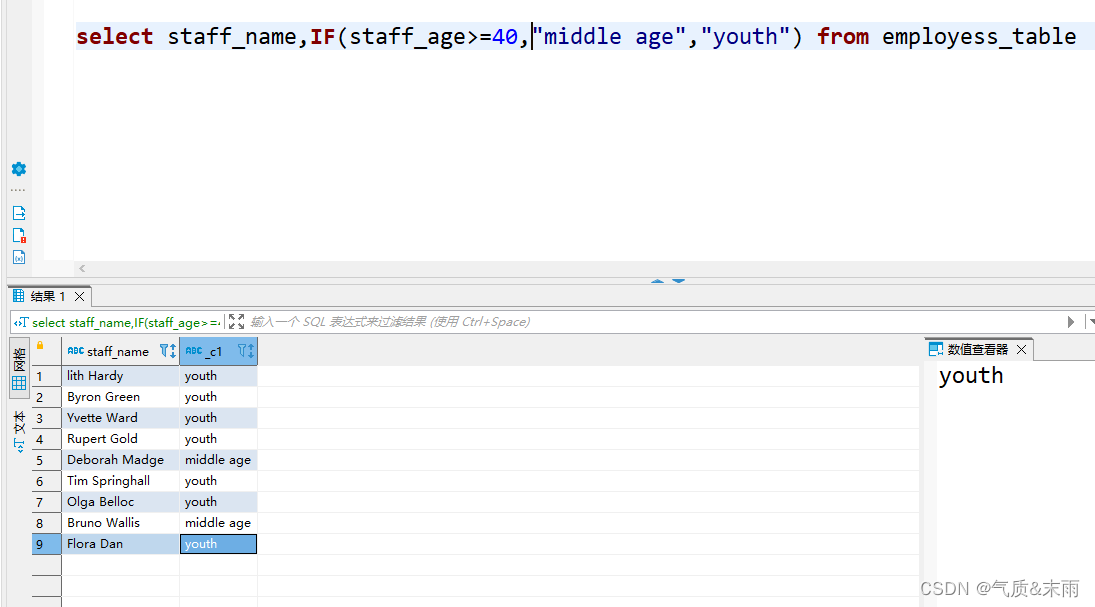
(1)、根据员工信息表employess_table中员工年龄数据,判断员工属于中年还是青年
输入命令:select staff_name,if(staff_age>=40,"middle age","youth")
使用if判断函数,把要进行判断的字段放进去,后面第一个参数是进行判断,如果年龄是大于等于40,那么信息就会被更改为middle age 反之就是else 信息就会被改为 youth 青年
(2)、根据员工信息表eployess_table 中员工薪资数据,判断员工薪资级别
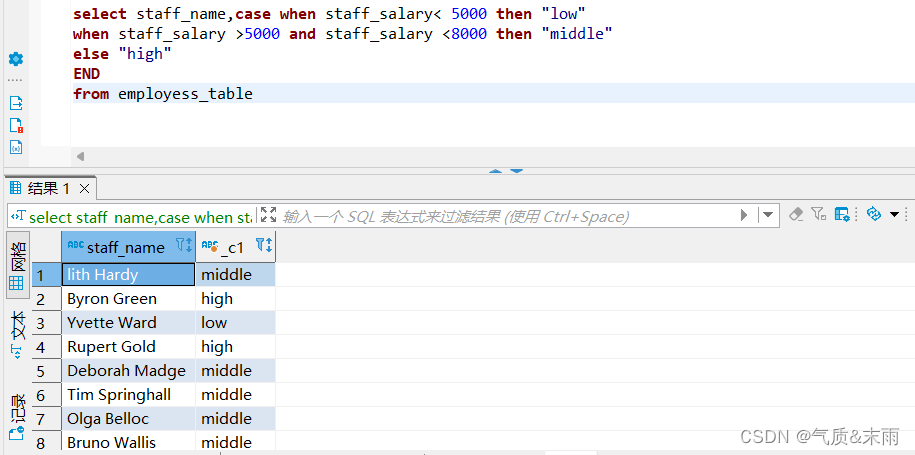
输入命令:
select staff_name,CASE when staff_salary < 5000 then "low"
when staff_salary >= 5000
and staff_salary < 8000 then "middle"
else "high"
end
from employess_table
使用case 进行判断,当staff_salary 员工工资字段小于5000 那么就是low 低等的,当员工工资大于等于5000,小于8000的时候,那么就是中等的,否则就是high 高等的,最后加一个end 结束,from employess_table员工表
7、字符串函数
字符串函数主要针对字符串类型的数据类型的列或数据进行操作
下面是常用的字符串函数

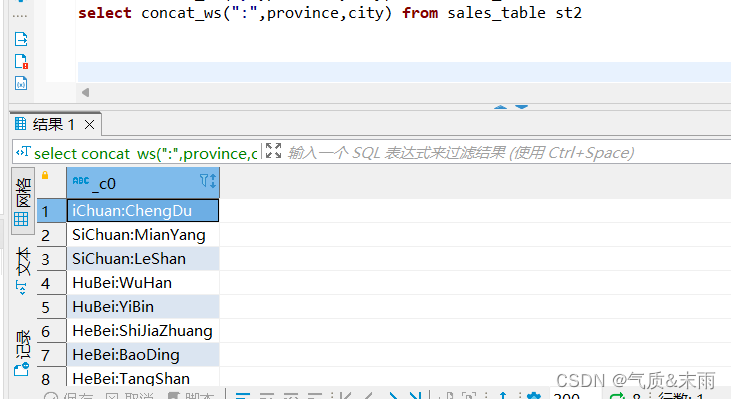
(1)、将商品销售表sales_table 中省份名和城市名拼接在一起
输入命令:select concat_ws(":",province,city) from sales_table
使用字符串函数 concat_ws() ,里面有三个参数,第一个参数是要用什么符号将两个字段进行拼接,后面两个参数是要进行拼接的字段
(2)、去除员工信息表employess_table 中员工姓名中的空格
输入命令:select staff_name,regexp_replace(staff_name,"\\s","") from employess_table
使用字符串函数中的regexp_replace() 里面三个参数,第一个参数是要进行操作的字段,\s是一个空格,第二个\是表示转义,\s 是进行去除空格替换成"",第三个参数是要替换成什么

8、表生成函数
表生成函数是指将指定数据或列中的数据拆分成多行数据,主要应用在集合类型数据
下面是是常用的集合类函数

(1)、拆分学生成绩表student_exam_table 的意向大学数据
输入命令:select intent_university ,university_new from student_exam_table lateral view explode(intent_university) intent_university as university_new

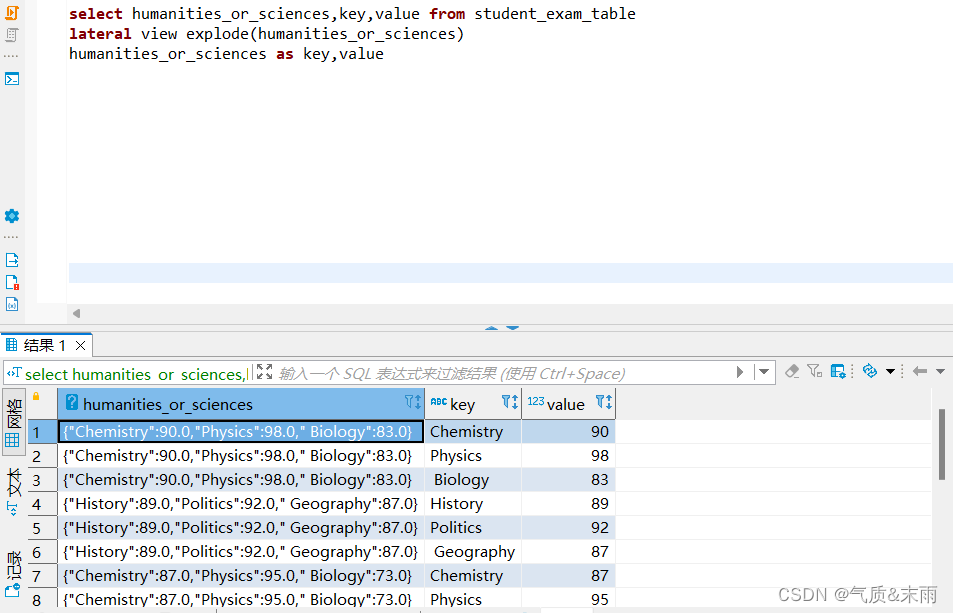
(2)、拆分学生成绩表student_exam_table的文综或理综数据
输入命令:select humanities_or_sciences,key,value from student_exam_table lateral view explode(humanities_or_sciences) humanities_or_sciences as key,value
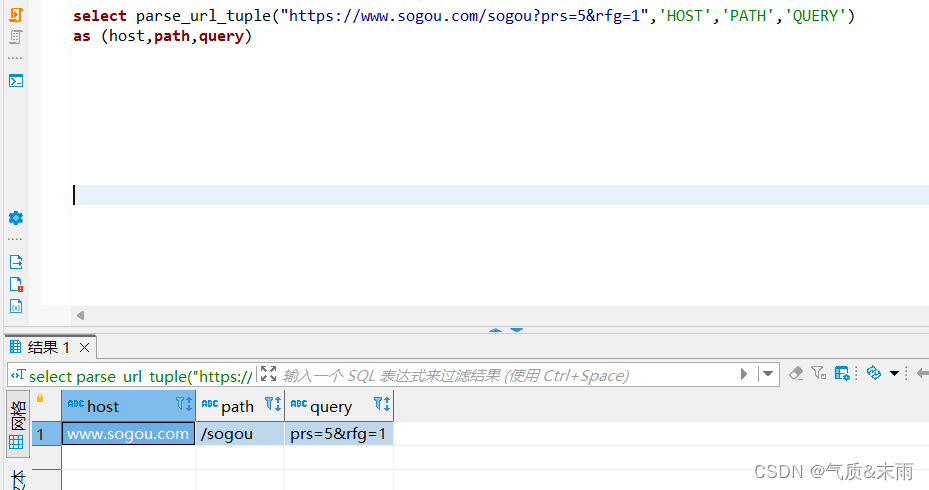
(3)、拆分URL地址数据
输入命令:select parse_url_tuple("https://www.sogou.com/sogou? prs=5&rfg=1",'HOST','PATH','QUERY') as (host,path,query)















 1287
1287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









