









文章目录
MapReduce 序列化案例
一、案例需求
1、需求:
统计每一个手机号耗费的总上行流量,下行流量,总流量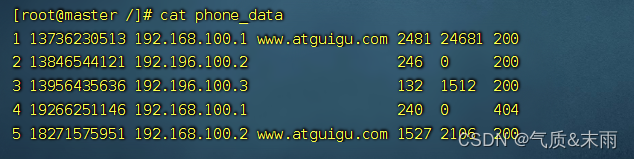
2、输入数据格式:

3、期望输出数据格式

二、案例分析
具体流程可以看下面这个流程图,首先是读取输入进来的数据,然后期望得到什么格式的数据,然后map阶段进行切分子字段,抽取字段,Reducer阶段只需要将上行流量和下行流量进行相加就可以得到总的流量了

map 阶段
map 阶段需要读取出一行,然后切分出字段,然后抽取出字段,只需要手机号码,上行流量,下行流量这三个字段就行了,其他的都不需要。然后以手机号为key,bean对象为value输出,即context.write(手机号,bean),然后bean对象想要能够传输,必须要实现序列化接口
Reduce 阶段
Reduce 阶段,将相同手机号的上行流量 + 下行流量 累加求和 = 总流量
三、代码实现
1、编写流量统计的Bean对象
因为等下map阶段的时候就要用到这个bean对象,所以先写他
首先是要先定义三个属性,upFlow,downFlow,sumFlow 上行流量下行流量和总流量的,然后下面是一个空参构造,这个是必须要写的,然后下面一个有参数的构造函数可写可不写,然后下面是重写序列化和反序列化方法,序列化的顺序和反序列化的顺序一定要一致,然后重写toString方法 用 "\t"来进行分割
字段然后下面就是setter和getter方法了,
package com.aex.mr;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//实现Writable接口
public class FlowBean implements Writable {
//接下来定义它的属性
private long upFlow; //上行流量
private long downFlow; //下行流行
private long sumFlow; //总流量
//想要实现序列化,得重写一个空参构造,为了后面反射用
public FlowBean(){
super();
}
//再要一个有参数的构造函数只有上行流量和下行流量,方便后面使用
public FlowBean(long upFlow, long downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
sumFlow = upFlow + downFlow; //这一句话写出来,直接就是sumFlow = upFlow+downFlow
}
//它要想实现序列化,需要重写一个空参构造
@Override //要求重写这两个方法,序列化方法
public void write(DataOutput out) throws IOException {
//注意顺序问题,序列化的顺序和反序列化的顺序得是一样的
out.writeLong(upFlow); //我们的数据是long类型的,然后写进来就是writeLong
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
@Override //反序列化方法
public void readFields(DataInput in) throws IOException {
//必须要求和序列化方法循序一致
upFlow = in.readLong(); //接收的时候又把他们转换回去
downFlow = in.readLong();
sumFlow = in.readLong();
}
@Override //重写一下toString 切割的时候都统一使用这个"\t" 来进行切割了
public String toString() {
return upFlow + "\t"+ downFlow + "\t" +sumFlow;
}
//下面再生产set和get方法
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
}
2、Mapper阶段代码
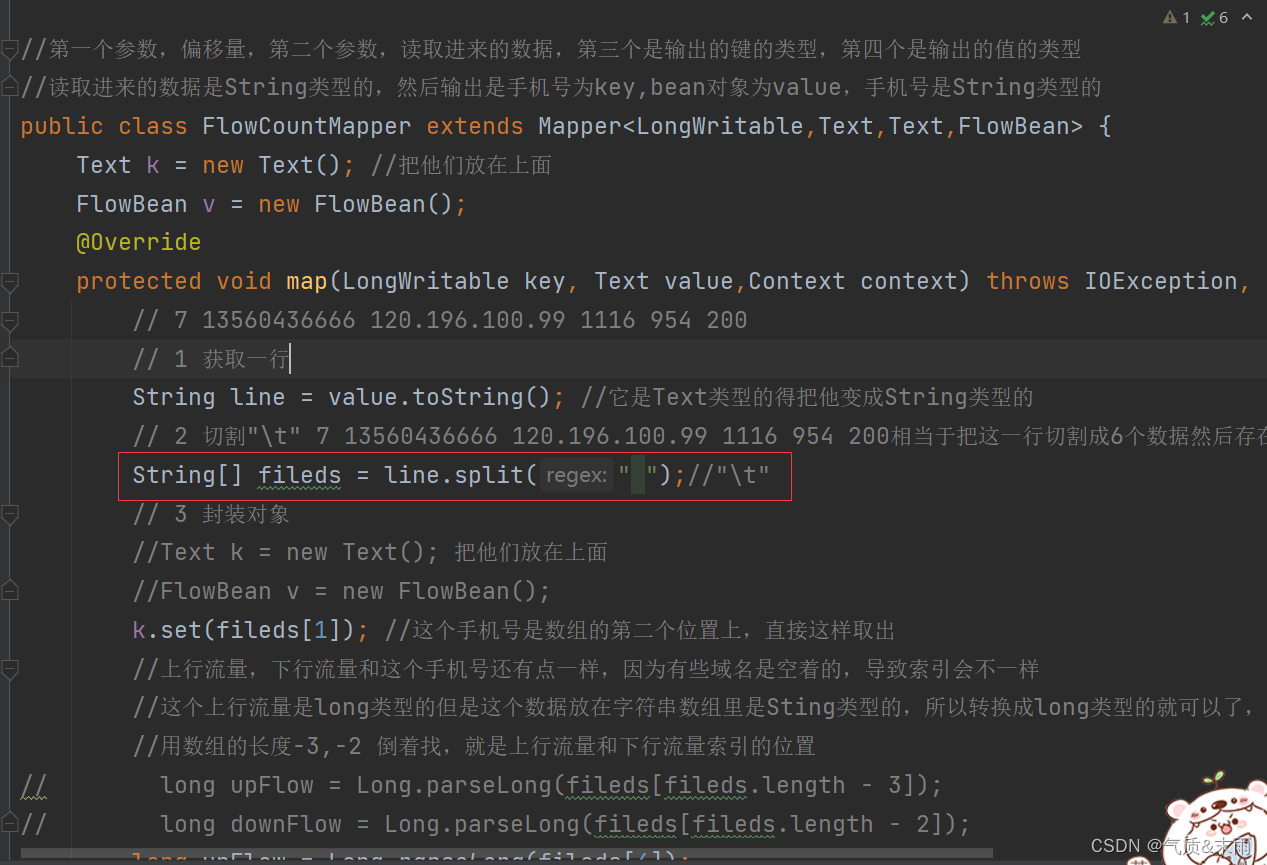
首先获取一行数据,转换成String类型进行操作,然后使用split方法,用"\t"进行切割成六个数据。然后返回到字符串数组filesd里面去,然后封装对象,电话号码是key bean对象是value,手机号就是数组的第二个位置fileds[1],就可以取出来了,这个上行流量和下行流量有点不一样,因为有些域名这个字段是空的导致索引有些有变化,那就倒着从数组里面找,fileds[fileds.lenght - 3],fileds[fileds.lenght - 2] 就可以找到上行流量和下行流量了,最后见他们写出,context,write() 第一个参数是键,也就是手机号,第二个参数是值也就是bean对象
package com.aex.mr;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//第一个参数,偏移量,第二个参数,读取进来的数据,第三个是输出的键的类型,第四个是输出的值的类型
//读取进来的数据是String类型的,然后输出是手机号为key,bean对象为value,手机号是String类型的
public class FlowCountMapper extends Mapper<LongWritable,Text,Text,FlowBean> {
Text k = new Text(); //把他们放在上面
FlowBean v = new FlowBean();
@Override
protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException {
// 7 13560436666 120.196.100.99 1116 954 200
// 1 获取一行
String line = value.toString(); //它是Text类型的得把他变成String类型的
// 2 切割"\t" 7 13560436666 120.196.100.99 1116 954 200相当于把这一行切割成6个数据然后存在这个字符串数组fileds里
String[] fileds = line.split("\t");
// 3 封装对象
//Text k = new Text(); 把他们放在上面
//FlowBean v = new FlowBean();
k.set(fileds[1]); //这个手机号是数组的第二个位置上,直接这样取出
//上行流量,下行流量和这个手机号还有点一样,因为有些域名是空着的,导致索引会不一样
//这个上行流量是long类型的但是这个数据放在字符串数组里是Sting类型的,所以转换成long类型的就可以了,
//用数组的长度-3,-2 倒着找,就是上行流量和下行流量索引的位置
long upFlow = Long.parseLong(fileds[fileds.length-3]);
long downFlow = Long.parseLong(fileds[fileds.length-2]);
v.setUpFlow(upFlow);
v.setDownFlow(downFlow);
// 4 写出
context.write(k,v); //手机号,bean对象
}
}
3、Reduce 阶段代码
Reduce 阶段主要是对上行流量和下行流量进行求和,把上行流量下行流量和总流量都放在bean对象里面,然后以手机号为key,bean对象为value
package com.aex.mr;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
//第一个和第二个参数是Mapper类的输出的类型,Text,FlowBen手机号码,bean对象
//第二个参数,最终输出的类型,第一个参数是手机号码,第二个参数是上行流量下行流量和总流量
//怎么才能三个装在一个里面呢,是可以的因为Map阶段的时候重写toString方法把他们三个写在一起的
public class FlowCountReducer extends Reducer<Text,FlowBean,Text,FlowBean> {
FlowBean v = new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
long sum_upFlow = 0;
long sum_downFlow = 0;
// 1 累加求和
for(FlowBean flowBean:values){ //还是遍历这个bean对象的数组
sum_upFlow += flowBean.getUpFlow();
sum_downFlow += flowBean.getDownFlow();
}
//封装对象,第一个key本来就是手机号码,所以不用封装了,要封装的sum 把它写在最上面
//FlowBean v = new FlowBean();
v.set(sum_upFlow,sum_downFlow); //吧上行流量和下行流量写入进去就是总的流量结果
// 2 写出
context.write(key,v); //然后把key和value写出
}
}
4、Driver 阶段代码
package com.aex.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class FlowCountDriver {
public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException, ClassNotFoundException {
// 1 获取job对象
Configuration conf = new Configuration(); //先创建配置对象
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true"); //这个重中之重,一定要设置,不然汇报I/O错误
Job job = Job.getInstance(conf); //然后把配置对象放在job对象的getInstance里面
// 2 设置jar存放路径
job.setJarByClass(FlowCountDriver.class); //这个不搞就不能吧包放在linux上面跑
// 3 关联Mapper和Reduce类
job.setMapperClass(FlowCountMapper.class); //让Mapper阶段和Reduce阶段跟job产生联系
job.setReducerClass(FlowCountReducer.class);
// 4 设置map阶段输出数据的key和value类型
job.setMapOutputKeyClass(Text.class); //分别是Text和IntWritable
job.setOutputValueClass(FlowBean.class);
// 5 设置最终数据输出的key和value类型
job.setOutputKeyClass(Text.class); //没说的是Reduce说的是最终 这个案例Reduce其实就是最终的输出
job.setOutputValueClass(FlowBean.class);
// 6 设置输入路径和输出路径
//使用着两个方法args[0],args[1] 方法也可以但是我比较喜欢下面直接把路径写出来
//FileInputFormat.setInputPaths(job,new Path(args[0]));
//FileOutputFormat.setOutputPath(job,new Path(args[1]));
//6.1 定义统一资源标识符
String uri = "hdfs://master:9000";
//6.2 创建输入路径
Path inputpath = new Path(uri+"/phone_dataa/phone_data");
//6.3 创建输出路径,输出路径事先是不能存在的
Path outputpath = new Path(uri + "/phone_datab");
// 获取文件系统
FileSystem fs = FileSystem.get(new URI(uri), conf);
// 删除输出目录(第二个参数设置是否递归)
fs.delete(outputpath, true);
// 给作业添加输入目录(允许多个)
FileInputFormat.addInputPath(job, inputpath); //添加输入目录
// 给作业设置输出目录(只能一个)
FileOutputFormat.setOutputPath(job, outputpath); //添加输出目录
// 7 提交job
job.waitForCompletion(true); //等待提交完成,里面这个true要是提交完了后会打印一些信息,为false只是不打印信息而已仅此而已
// 输出统计结果 将结果打印在输出台 不然只有把jar包上传到linux运行才能看到结果
System.out.println("======统计结果======");
FileStatus[] fileStatuses = fs.listStatus(outputpath);
for (int i = 1; i < fileStatuses.length; i++) {
// 输出结果文件路径
System.out.println(fileStatuses[i].getPath());
// 获取文件系统数据字节输入流
FSDataInputStream in = fs.open(fileStatuses[i].getPath());
// 将结果文件显示在控制台
IOUtils.copyBytes(in, System.out, 4096, false);
}
}
}
5、运行程序,查看结果
会发现运行程序出现了异常,因为我们之前分割字段的时候是用的制表符"\t",把他改成用空格分割就好了
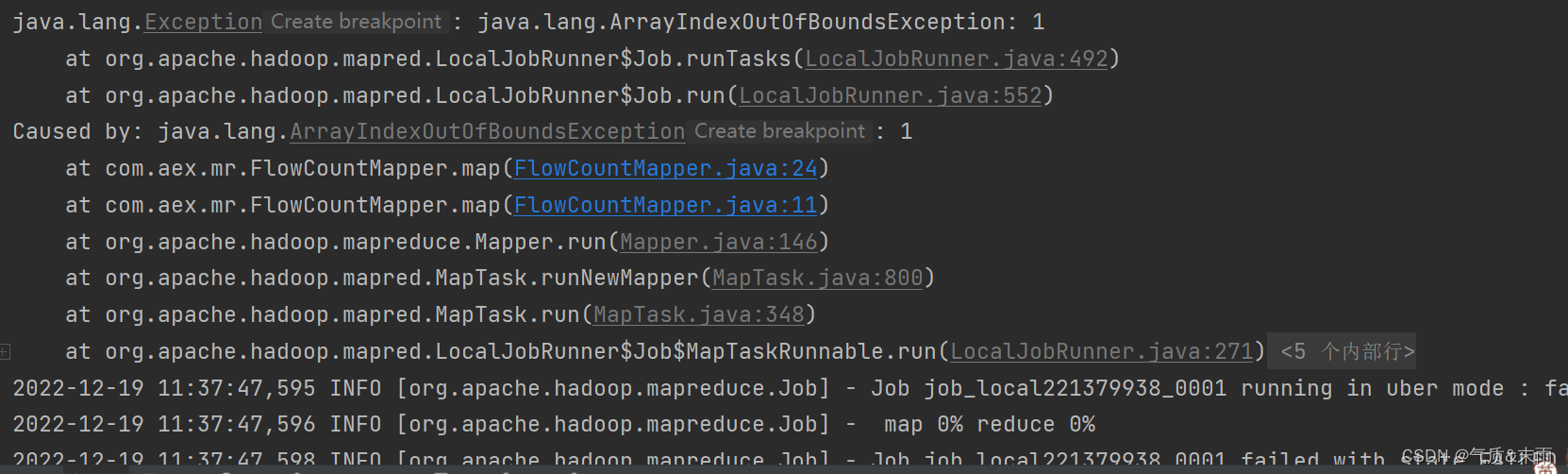
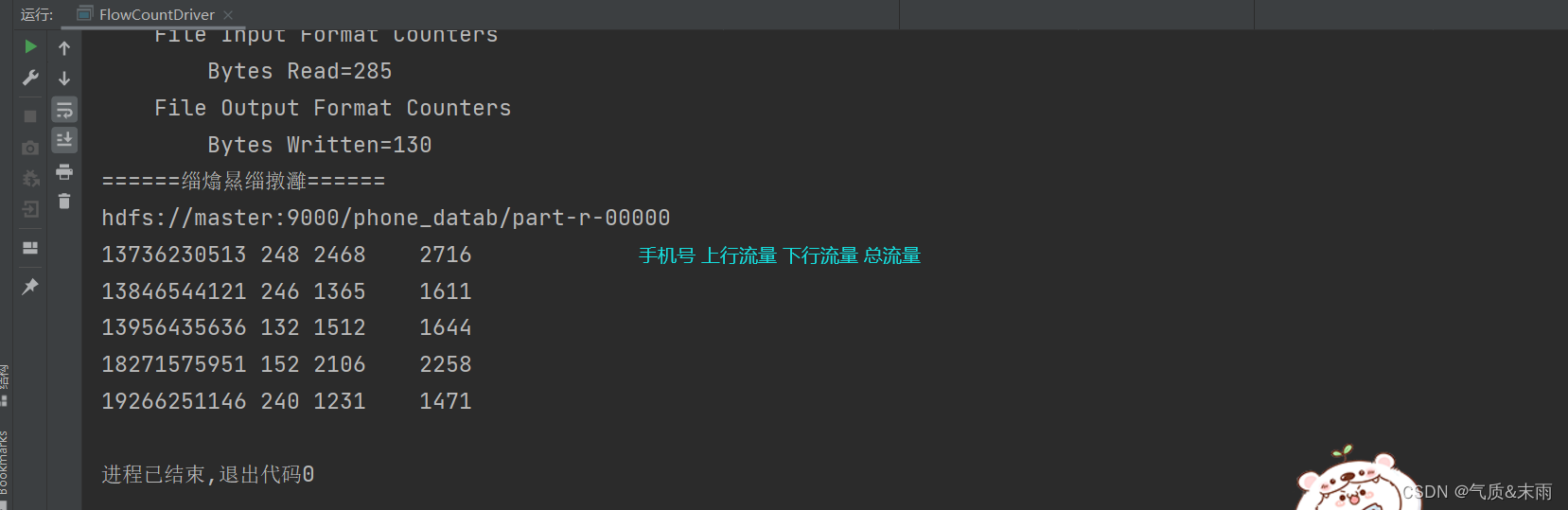
此时再运行程序 可以看到结果出来了,统计出了每一个手机号耗费的总上行流量,下行流量,总流量















 536
536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









