







文章目录
Spark 行动算子
所谓的行动算子,其实就是触发作业执行的方法,之前的转换算子是不能直接触发执行的,形成了一个个新的RDD。行动算子比较少,就那么几个。
注意:
因为行动算子是直接触发执行的,并不是返回RDD,所以不能使用collect()方法,得使用println()打印到控制台
1、reduce
聚集RDD中的所有元素,先聚合分区内数据,再聚合分区间数据。
package com.atguigu.bigdata.spark.core.wc.action
import org.apache.spark.{SparkConf, SparkContext}
// RDD 行动算子 reduce:聚集RDD中的所有元素,先聚合分区内数据,再聚合分区间数据。
class Spark02_RDD_reduce {
}
object Spark02_RDD_reduce{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD行动算子")
val context = new SparkContext(conf)
val rdd = context.makeRDD(List(1, 2, 3, 4))
val reduceRDD = rdd.reduce(_ + _) //reduce 先进行分区内聚合,再分区间聚合
println(reduceRDD)
context.stop()
}
}
2、collect
方法会将不同分区的数据按照分区顺序采集到Driver端内存中,形成数组
3、count
统计数组源中数据的个数
4、first
获取数据源中的第一个元素
5、take
返回一个由RDD的前n个元素组成的数组
6、takeOrdered
返回该RDD排序后的前n个元素组成的数据,这个方法很不错,还可以直接排序
7、代码示例
前面几个方法比较简单,所以把他们放一起了。
package com.atguigu.bigdata.spark.core.wc.action
import org.apache.spark.{SparkConf, SparkContext}
// RDD 行动算子 reduce:聚集RDD中的所有元素,先聚合分区内数据,再聚合分区间数据。
class Spark02_RDD_reduce {
}
object Spark02_RDD_reduce{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD行动算子")
val context = new SparkContext(conf)
val rdd = context.makeRDD(List(1, 2, 3, 5,4))
//reduce:先进行分区内聚合,再分区间聚合
val reduceRDD = rdd.reduce(_ + _)
println(reduceRDD)
//collect:方法会将不同分区的数据按照分区顺序采集到Driver端内存中,形成数组
// val ints = rdd.collect()
// println(ints)
// count:数组源中数据的个数
val count = rdd.count()
println(count)
// first:获取数据源中的第一个元素
val i = rdd.first()
println(i)
//take:返回一个由RDD的前n个元素组成的数组
val ints = rdd.take(3)
println(ints.mkString(","))
//takeOrdered:数据排序后取前n个数据
val ints1 = rdd.takeOrdered(4)
println(ints1.mkString(","))
context.stop()
}
}
8、aggregate
分区的数据通过初始值和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合
val result = rdd.aggregate(0)(_ + _,_+ _) //初始值,分区内计算,分区间计算。
注意:
aggregate 和 aggregateByKey 的区别:
aggregateByKey 初始值只参与分区内计算
aggregate 初始值参与内区内计算,并且和参与分区间计算
package com.atguigu.bigdata.spark.core.wc.action
import org.apache.spark.{SparkConf, SparkContext}
//aggregate:分区的数据通过`初始值`和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合
class Spark03_RDD_aggregate {
}
object Spark03_RDD_aggregate{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD行动算子")
val context = new SparkContext(conf)
val rdd = context.makeRDD(List(1, 2, 3, 4))
//TODO -行动算子 aggregate
//aggregateByKey 是转换算子 aggregate 是行动算子
// aggregateByKey:初始值只会参与分区内计算
// aggregate : 初始值会参与内区内计算,并且和参与分区间计算
val i = rdd.aggregate(10)(_ + _, _ + _)
println(i)
context.stop()
}
}
9、fold
aggregate 的简化版本,只是分区内操作和分区间操作是一样的,可以减少一些。
val result = rdd.fold(0)(_ + _) //前面是初始值,后面是分区内和分区间的计算规则
10、countByValue & countByKey (wordcount重点)
这个方法特别特别好用,做wordcount直接这一个方法就出来了。
countByKey 需要键值对类型的集合,根据key来统计。countByValue 直接普通的集合就可以了,根据value,这里的value不是键值对里面那个value,是单值的意思。
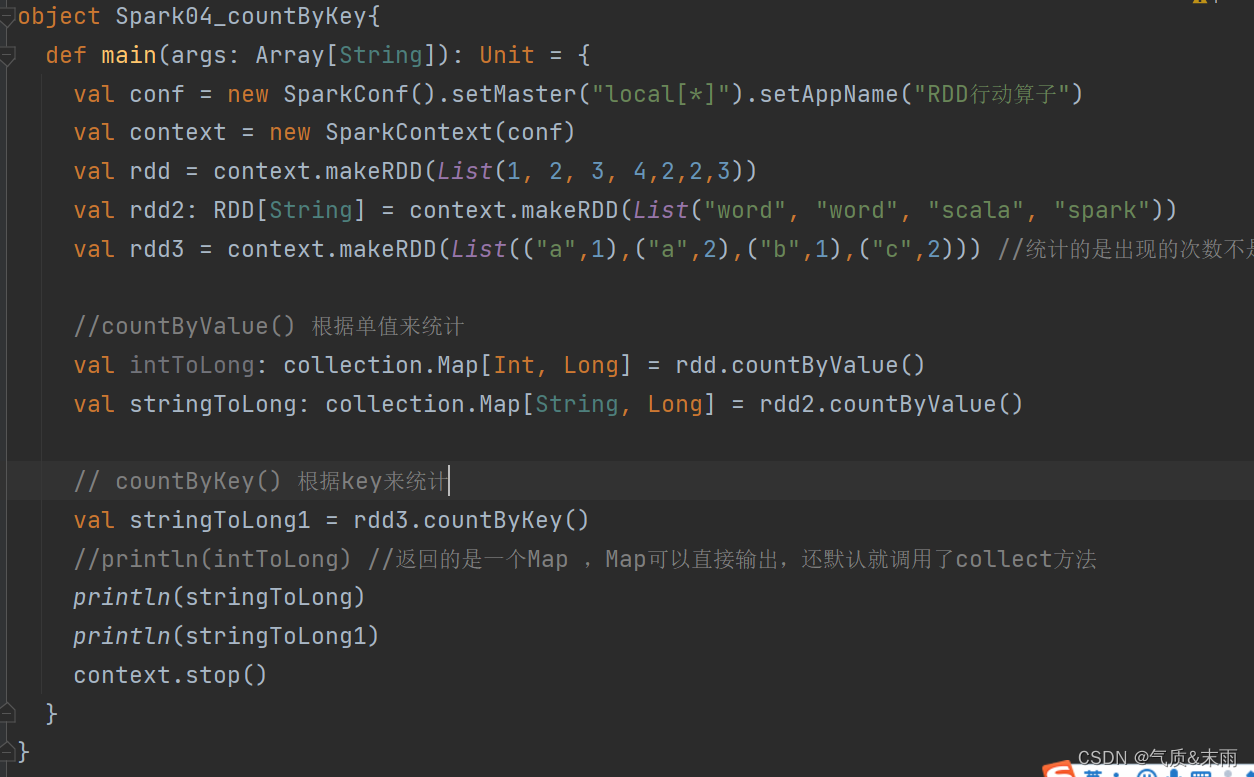

package com.atguigu.bigdata.spark.core.wc.action
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
class Spark04_countByKey {
}
object Spark04_countByKey{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD行动算子")
val context = new SparkContext(conf)
val rdd = context.makeRDD(List(1, 2, 3, 4,2,2,3))
val rdd2: RDD[String] = context.makeRDD(List("word", "word", "scala", "spark"))
val rdd3 = context.makeRDD(List(("a",1),("a",2),("b",1),("c",2))) //统计的是出现的次数不是value
//countByValue() 根据单值来统计
val intToLong: collection.Map[Int, Long] = rdd.countByValue()
val stringToLong: collection.Map[String, Long] = rdd2.countByValue()
// countByKey() 根据key来统计
val stringToLong1 = rdd3.countByKey()
//println(intToLong) //返回的是一个Map ,Map可以直接输出,还默认就调用了collect方法
println(stringToLong)
println(stringToLong1)
context.stop()
}
}
11、sava相关算子
将数据保存到不同格式的文件中
save类型的算子一共有三个:saveAsTextFile 用来保存分区文件,一般都是用这个。
saveAsObjectFile,saveAsSequenceFile 前面两个都是随便用,这个是数据类型必须为k-v类型的。直接用第一个方法保存文件就行了。
package com.atguigu.bigdata.spark.core.wc.action
import org.apache.spark.{SparkConf, SparkContext}
//svae保存文件相关的算子
class Spark06_save {
}
object Spark06_save{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD行动算子")
val context = new SparkContext(conf)
val rdd = context.makeRDD(List(("a",1),("a",2),("a",3)),2)
//TODO -行动算子 save
rdd.saveAsTextFile("output1") // 保存分区文件
rdd.saveAsObjectFile("output2") //
//saveAsSequenceFile 要求数据的格式必须为k-v类型的
rdd.saveAsSequenceFile("output3") //
context.stop()
}
}
12、什么是算子?
什么是算子:Operator (操作)
RDD的方法和Scala集合对象的方法不一样,集合对象的方法都是在同一个节点的内存中完成的,RDD的方法可以将计算逻辑发送到Executor端(分布式节点) 中执行,为了区分不同的处理效果,所以将RDD的方法称之为算子,RDD 的方法外部的操作都是在Driver端执行的,而方法内部的逻辑代码都是在Executor端执行。
13、foreach
分布式遍历RDD中的每一个元素,调用指定函数。
(1) 代码示例
package com.atguigu.bigdata.spark.core.wc.action
import org.apache.spark.{SparkConf, SparkContext}
//foreach 算子:分布式遍历RDD中的每一个元素,调用指定函数。
class Spark07_foreach {
}
object Spark07_foreach{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD行动算子")
val context = new SparkContext(conf)
val rdd = context.makeRDD(List(1, 2, 3, 4))
//foreach: 其实是Driver端内存集合的循环遍历方法
rdd.collect().foreach(println)
println("=============")
//foreach: 其实是Executor端内数据打印
rdd.foreach(println) //foreach 没有顺序的概念
//什么是算子:Operator (操作)
// RDD的方法和Scala集合对象的方法不一样
// 集合对象的方法都是在同一个节点的内存中完成的
// RDD的方法可以将计算逻辑发送到Executor端(分布式节点) 中执行
// 为了区分不同的处理效果,所以将RDD的方法称之为算子
// RDD 的方法外部的操作都是在Driver端执行的,而方法内部的逻辑代码都是在Executor端执行。
context.stop()
}
}
(2) foreach小案例
package com.atguigu.bigdata.spark.core.wc.action
import org.apache.spark.{SparkConf, SparkContext}
class Spark07_foreach2 {
}
object Spark07_foreach2{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD行动算子")
val context = new SparkContext(conf)
val rdd = context.makeRDD(List(1, 2, 3, 4))
val user = new User()
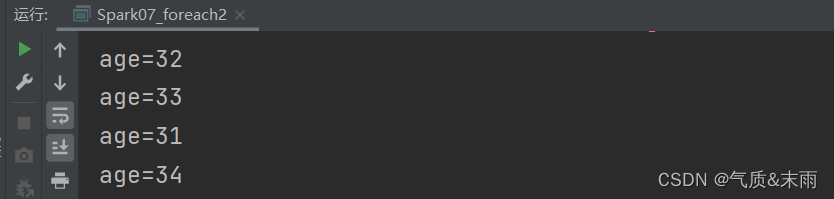
rdd.foreach(
num => {
println("age=" + (user.age + num))
}
)
context.stop()
}
class User{
var age:Int = 30
}
}
执行上面的代码,会发现报错了。报了一个序列化的错误
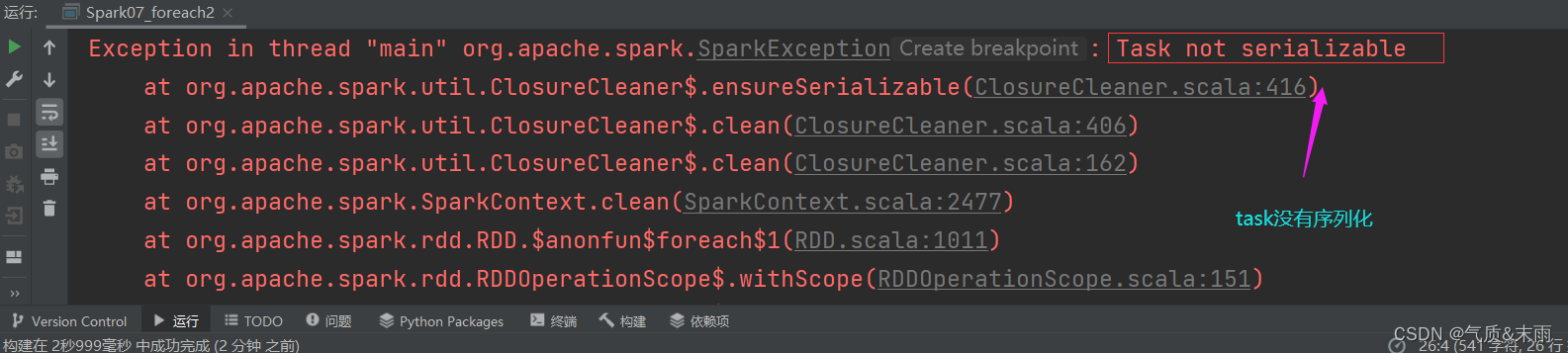
之所以会报错,是因为User 是对象,在Driver端,而将它传入到不同的节点Executor打印,相当于是对象的传输,是需要序列化的,需要 extand Serializable 混入序列化特质,这样就不会报错了。
或者使用样例类也可以,系统在编译时,会自动混入序列化特质。

package com.atguigu.bigdata.spark.core.wc.action
import org.apache.spark.{SparkConf, SparkContext}
class Spark07_foreach2 {
}
object Spark07_foreach2{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDD行动算子")
val context = new SparkContext(conf)
val rdd = context.makeRDD(List(1, 2, 3, 4))
val user = new User() //这个对象是在Driver端的
//RDD算子中传递的函数是会包含闭包操作,那么就会进行检测功能,自动判断是否包含序列化的功能
//闭包:函数把外部的函数引入到内部,形成一个闭合的效果,改变这个变量的生命周期
rdd.foreach( //foreach 是在Driver端
num => {
println("age=" + (user.age + num)) //这个println 是在Ececutor 端
}
)
context.stop()
}
// class User extends Serializable { //需要混入 Serializable 序列化
// var age:Int = 30
// }
//样例类在编译时,会自动混入序列化特质(实现可序列化接口)
case class User(){
var age:Int = 30
}
}















 1171
1171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









