







文章目录
Spark SQL 核心编程
学习如何使用 Spark SQL 提供的 DataFrame 和 DataSet 模型进行编程,以及了解他们之间的关系和转换,关于具体的SQL书写不是我们的重点。
1、新的起点
Spark Core 中,如果想要执行应用程序,需要首先构建上下文环境对象,SparkContext,Spark SQL 其实可以理解为对 Spark Core的一种封装,不仅仅在模型上进行了封装,上下文环境对象也进行了封装。
在老的版本中,SparkSQL提供两种 SQL 查询起始点,一个叫 SQLContext,用于 Spark 自己提供的 SQL 查询,一个叫 HiveContext,用于连接 Hive 查询。
SparkSession 是 Spark 最新的 SQL 查询起点,实质是上 SQLContext 和 HiveContext 的组合,所以在 SQLContext 和 HiveContext 上可用的API在 SparkSession 上同样是可以使用的。SparkSession 内部封装了 SparkContext,所以实际上是由sparkContext 完成的。当我们使用 spark-shell 的时候,spark 框架会自动创建一个名称叫做spark的SparkSession对象,就像我们以前可以自动获取到一个sc来表示SparkContext对象一样。
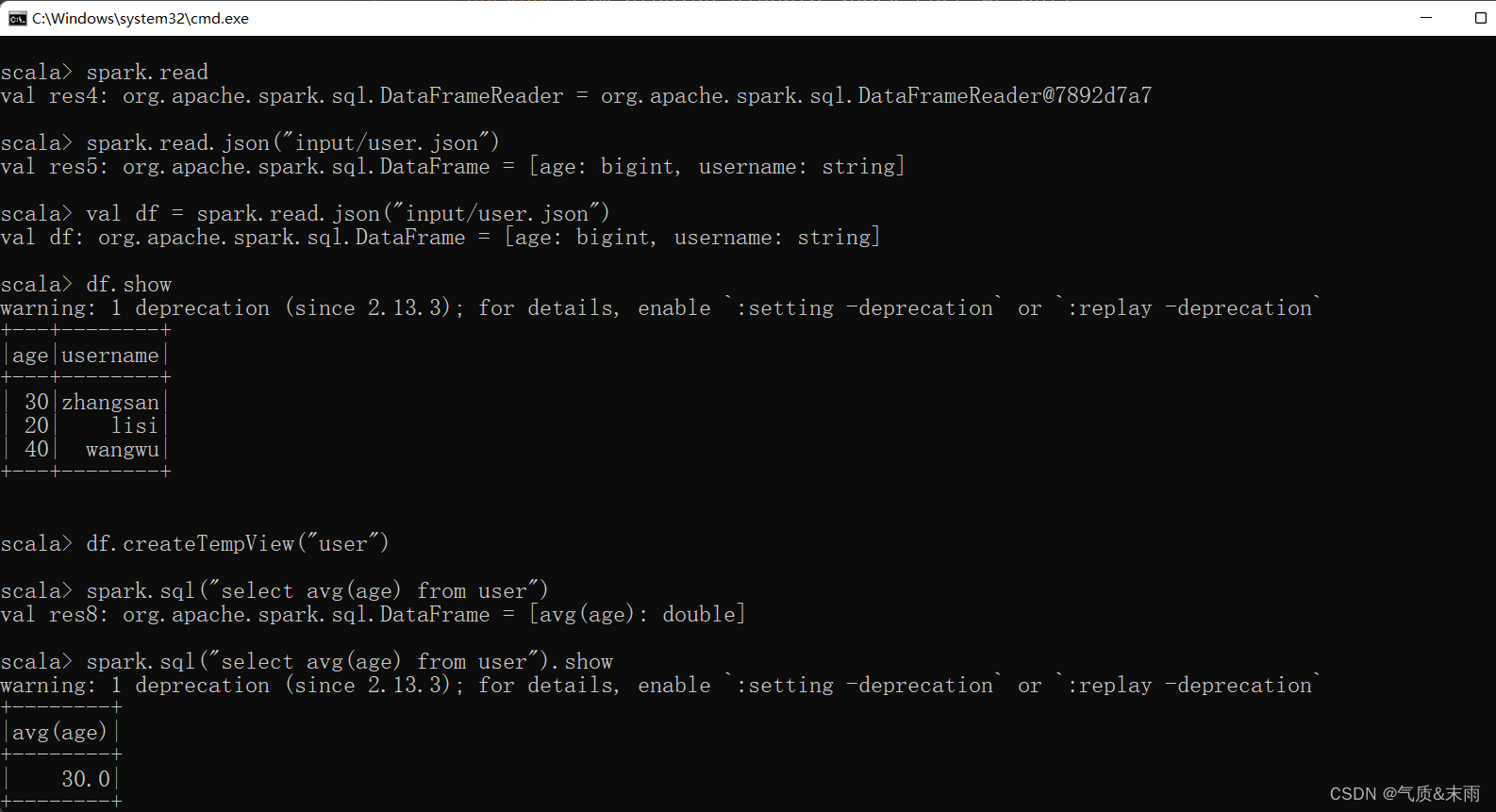
这下面是在终端命令行简单的演示,是怎么用spark 执行sql语句执行的。
读取json文件创建DataFrame:
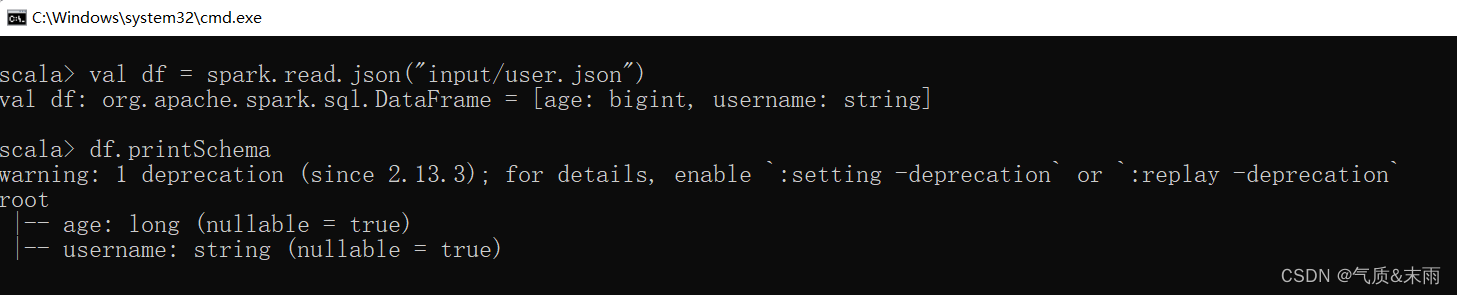
val df = spark.read.json("input/user.json")

注意:
从内存中获取数据,spark 可以知道数据具体是什么。如果是数字,默认作为 Int 处理,但是从文件中读取的数字,不能确定是什么类型,所以用 bigint(大整形) 接收,可以和 Long 类型转换,但是和 Int 不能进行转换。
2、SQL 语法
SQL 语法风格是指我们查询数据的时候使用 SQL 语句来查询,这种风格的查询必须要有临时视图或者全局视图来辅助。
1) 读取 json 文件创建 DataFrame

2) 对 DataFrame 创建一个临时表
要想用sql语句,那肯定首先就要有个表,所以将DataFrame转换为一个临时表,就可以用sql语句了。创建临时表使用 createReplaceTempView("pepole"),创建临时视图使用 createTempView("pepole")

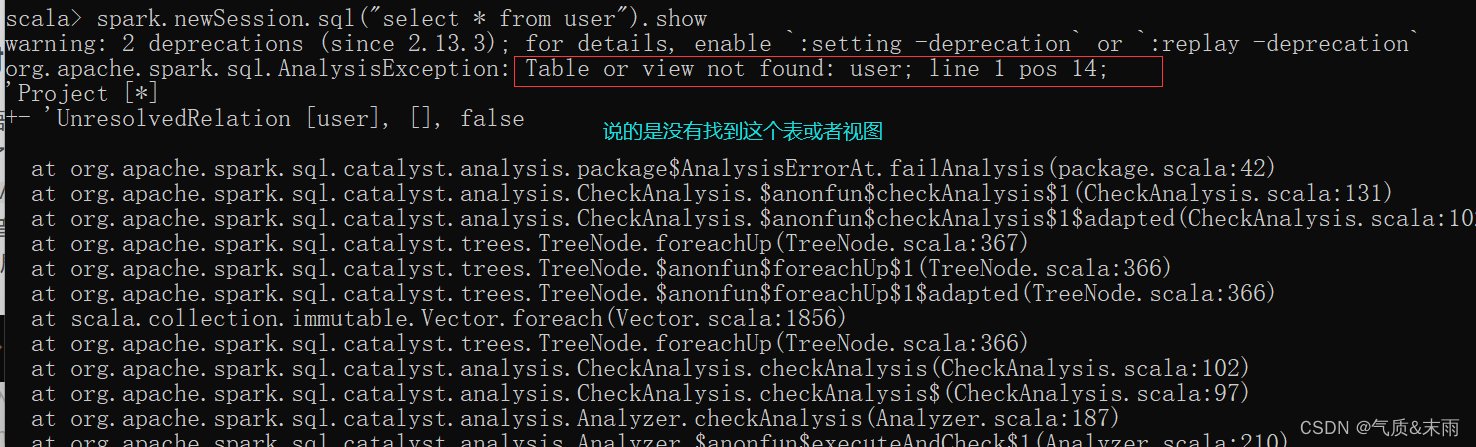
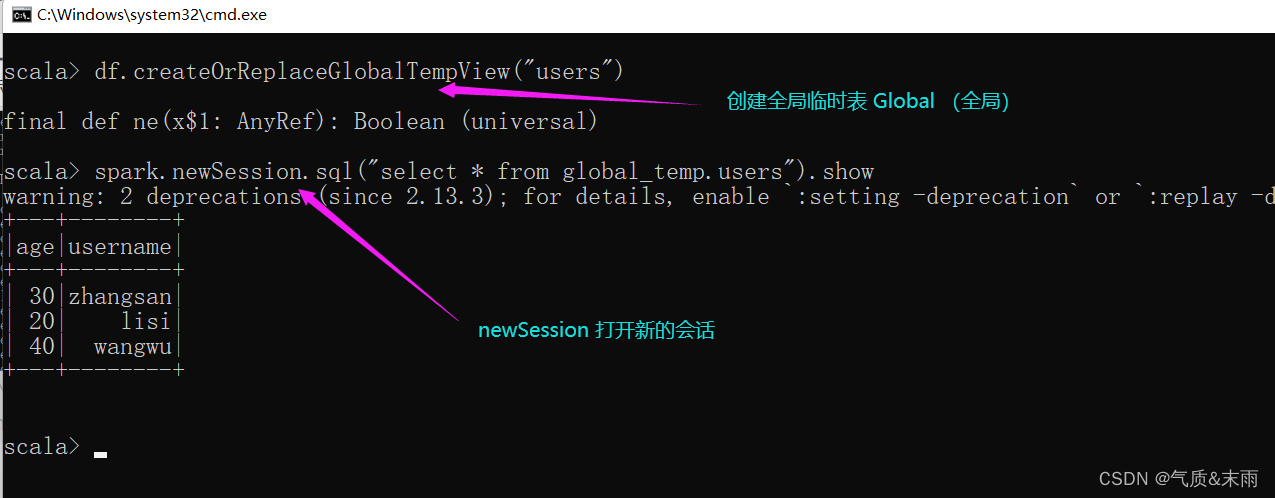
注意:普通临时表是Session范围内的,如果想应用范围内有效,可以使用全局临时表。使用全局临时表时需要全路径访问。
比如下面这里就是newSession 开启了一个新的会话,之前那个临时表就用不了了,找不到。
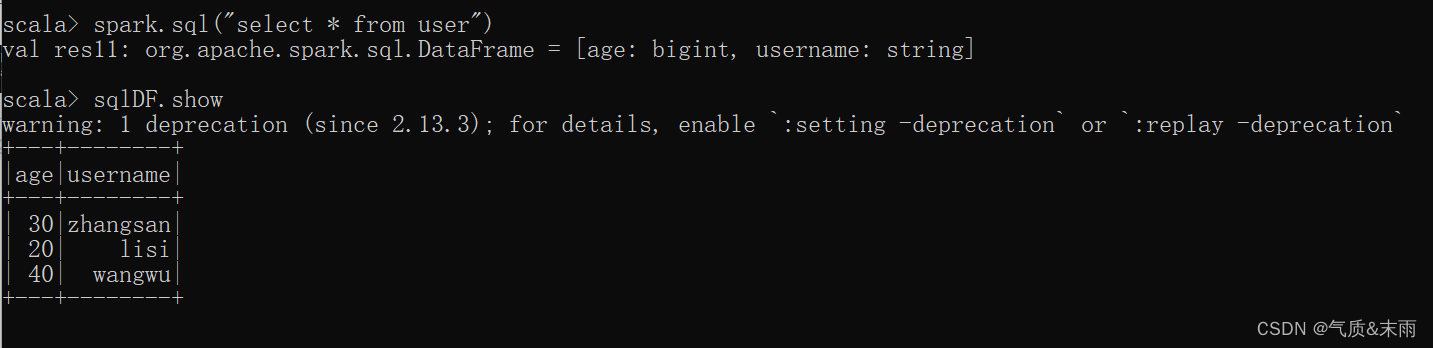
3) 通过SQL语句实现查询全表
spark 查询语句:spark.sql("select * from user") 这个user就是上面创建的临时视图,必须要创建个这样的对象,才能进行sql 语句查询。

这个就是查询的结果
3、DSL 语法
DataFrame 提供一个特定领域语言(domain-specific language,DSL)去管理结构化数据。可以在 Scala,Java,Python,和 R 中使用 DSL,使用 DSL 语法风格不必去创建临时视图了。
1) 创建一个DataFrame
val df = spark.read.json("input/user.json")

2) 查看DataFrame的Schema信息
df.printSchema 用这个看到看信息,说明spark的那些方法都是可以用的。
这里可以看到,这种DSL 不需要创建什么表,这个是可以直接用 DataFrame对象直接进行select的查询
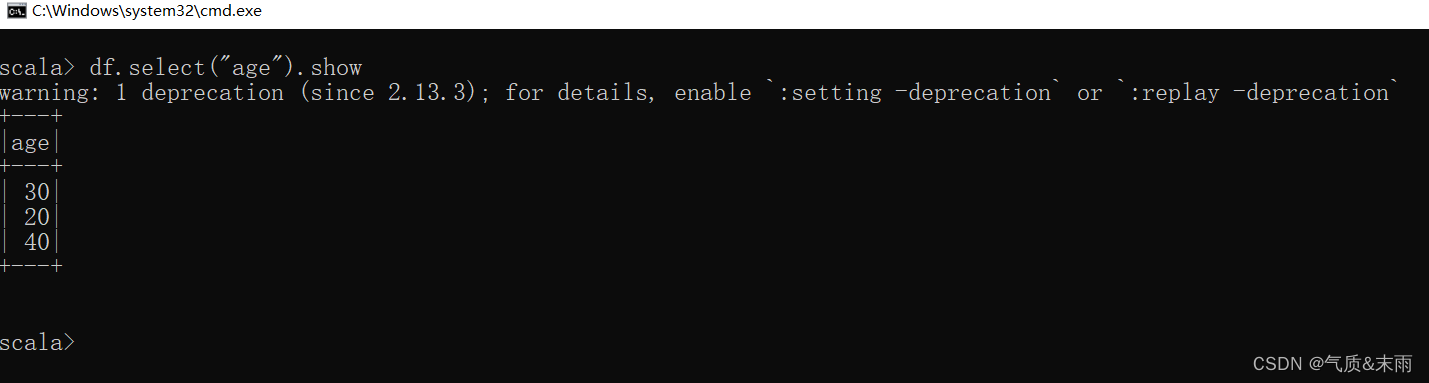
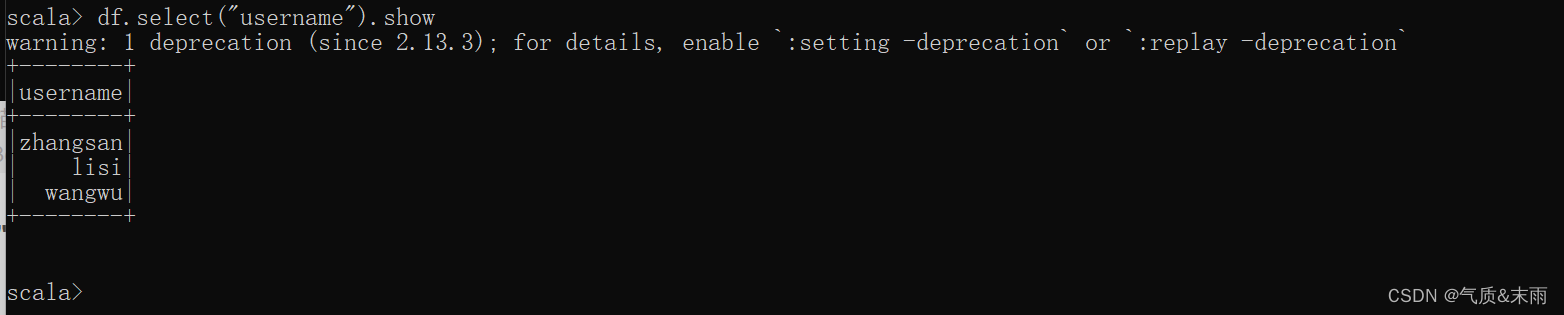
3) 只查看"username"列数据
df.select("username").show
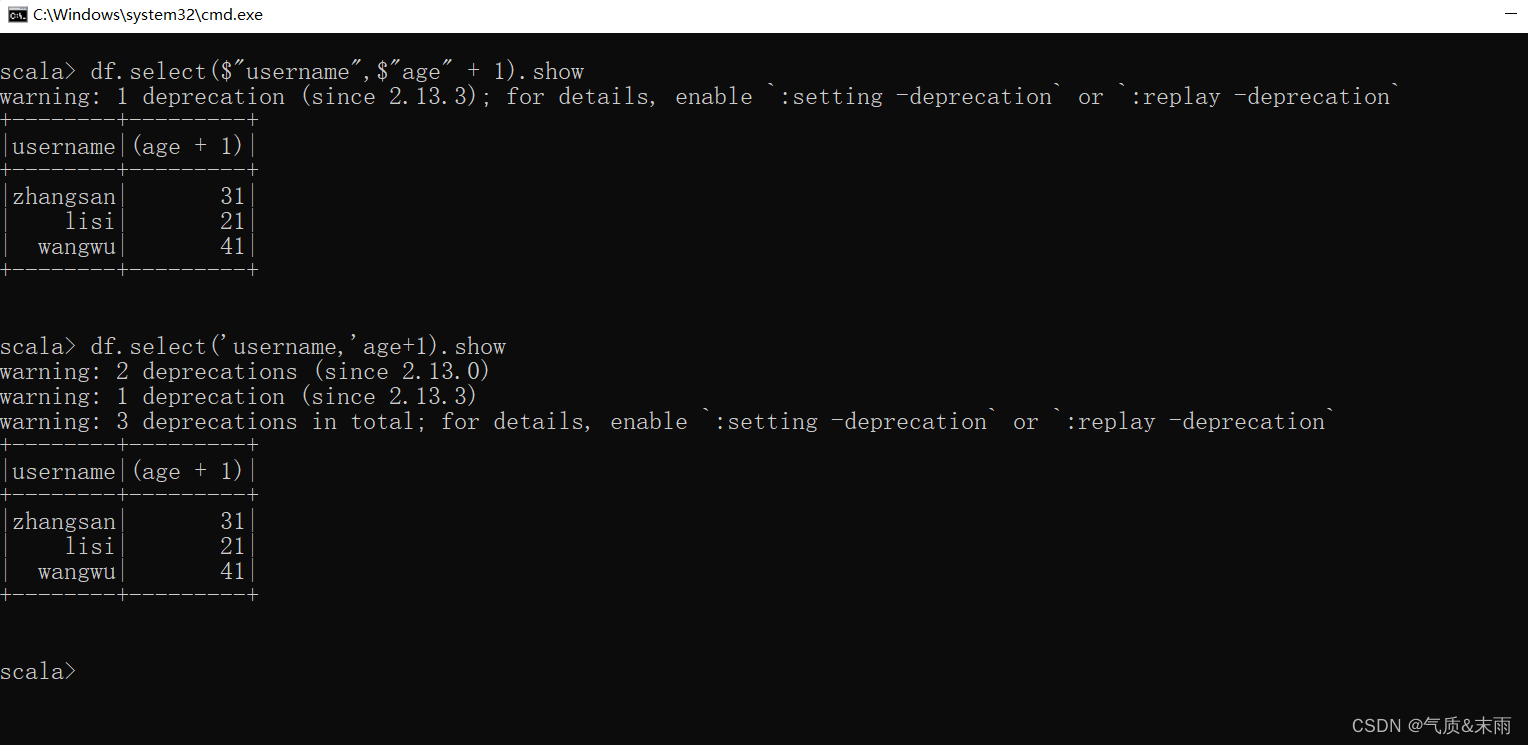
4) 查看"username"列以及"age"+1数据
df.select($"username",$"age" + 1)
df.select('username,'age + 1)
注意:涉及到运算的时候,每列都必须使用$,或者采用引号表达式:单引号+字段名

或者不要双引号,在每个字段的前面加上一个单引号也是可以的。
5) 查看"age"大于"20"的数据
就不是select了,使用filter进行筛选过滤。
df.filter($"age">20).show
注意:这里这个大于20,上面那个20+1那个是不算的。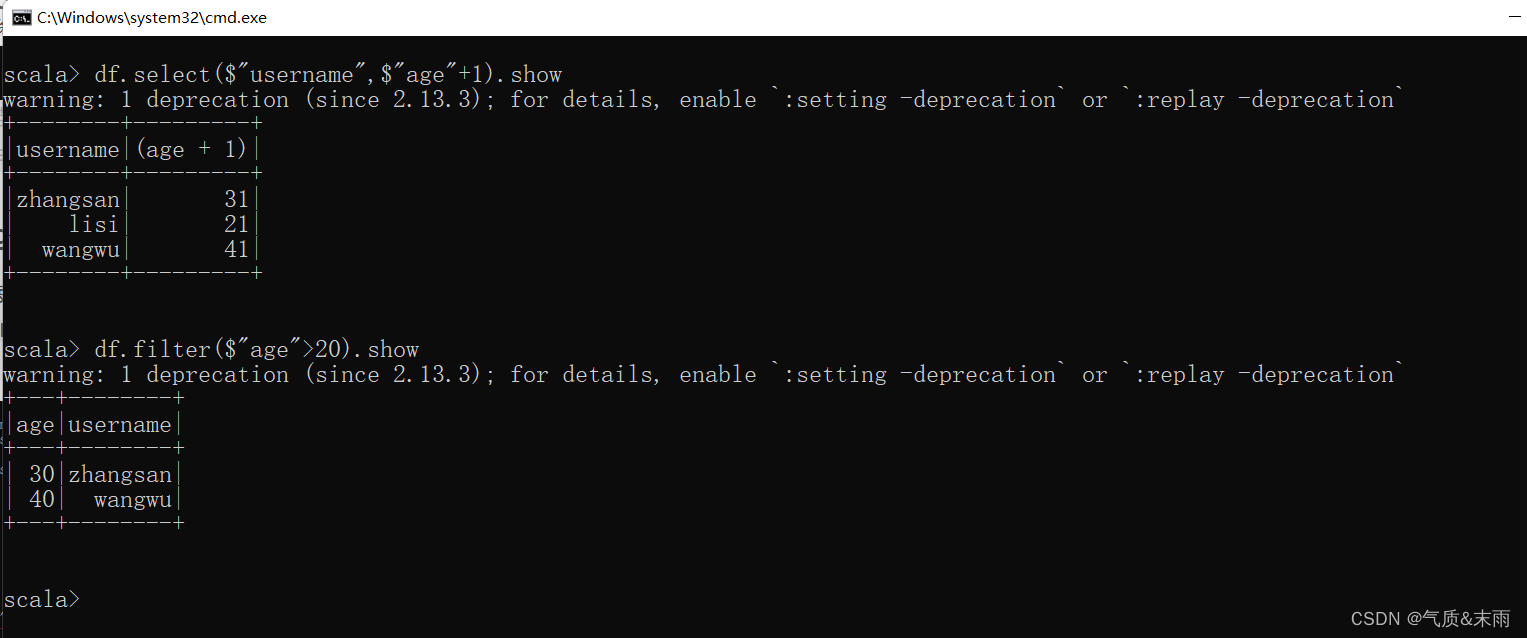
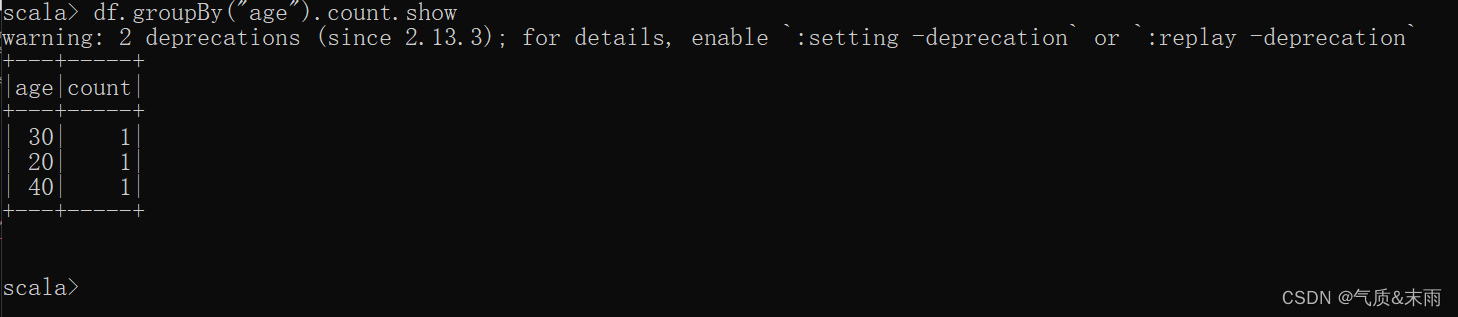
6) 按照"age"分组,查看数据条数
使用groupBy,分组完还必要要用count统计
df.groupBy("age").count.show
4、RDD 转换为 DataFrame
在 IDEA 开发程序时,如果需要 RDD 与 DF 或者 DS 之间互相操作,那么需要引入import spark.implicits._
这里的 spark 不是 Scala 中的包名,而是创建的sparkSession 对象的变量名称,所以必须先创建 SparkSession 对象再导入。这里的 spark 对象那个不能那个使用 var 声明,因为Scala 只支持 val 修饰的对象的引入。
spark-shell 中无需导入,自动完成此操作。
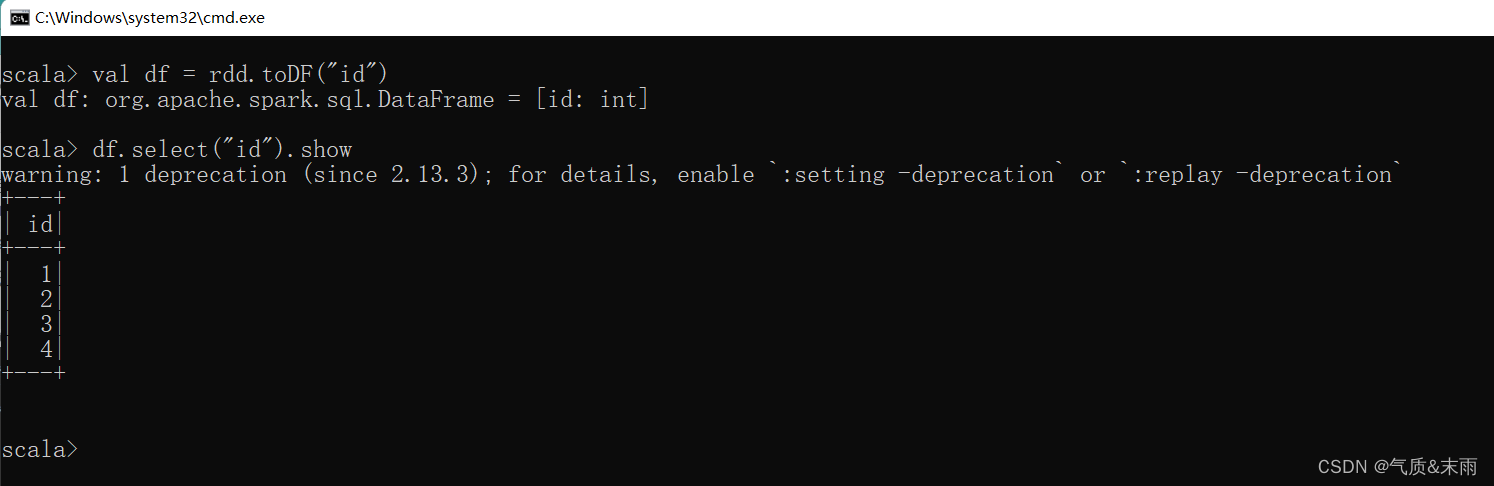
首先创建一个rdd
val rdd = sc.makeRDD(List(1,2,3,4)) 然后可以看到下面有很多的方法,其中有一个toDF方法,就是 RDD 转换为 DataFrame的。
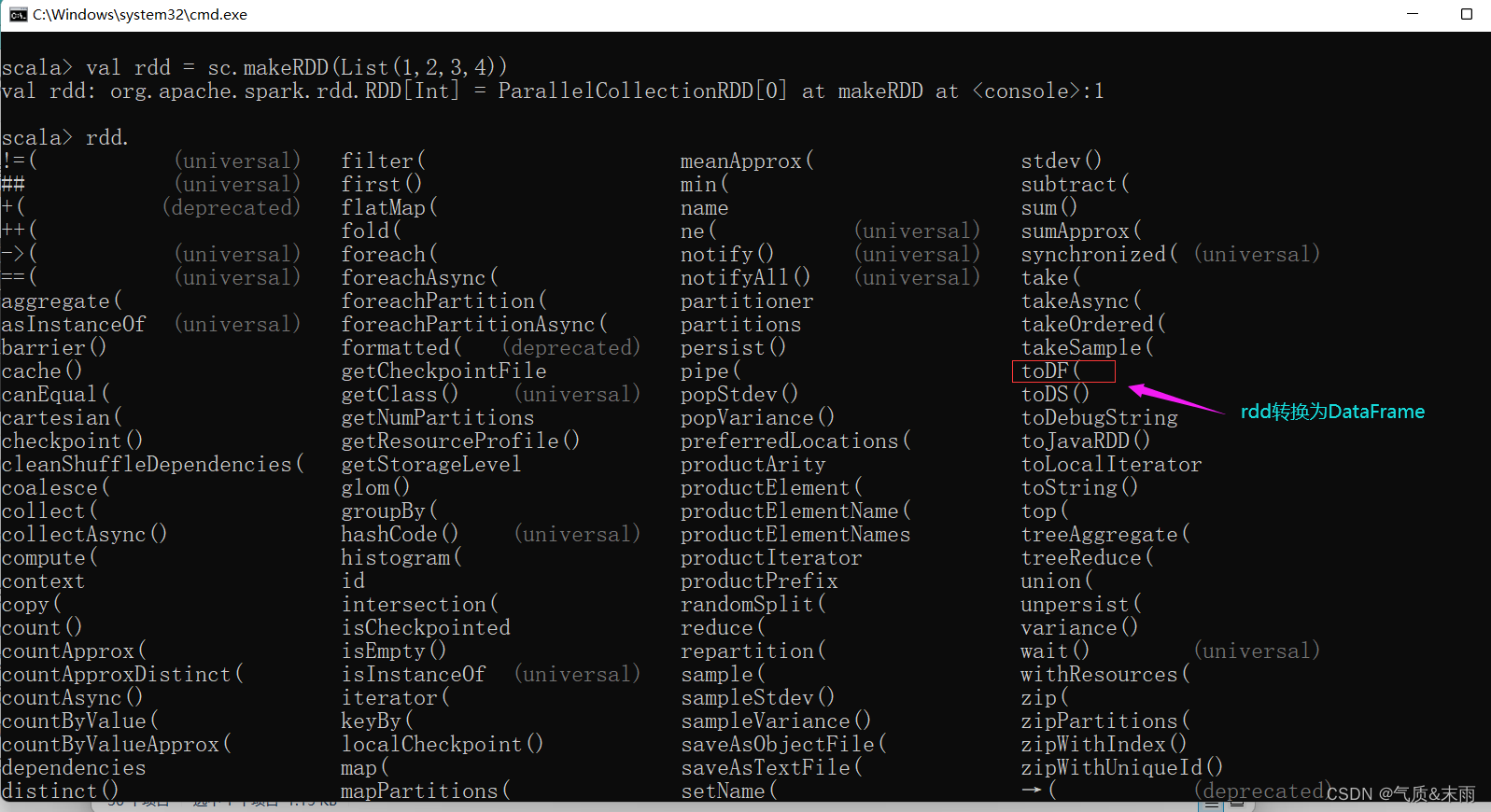
val df = rdd.toDF("id") 我们将数据转换为DataFrame 那我们得让他知道我们的数据是什么意思,所以给他一个列字段名,“id”。
要是想从DataFrame转换回RDD的话,那么直接 df.rdd 就转换回去了。
5、DataSet
DataSet 是具有强类型的数据集合,需要提供对应的类型信息。
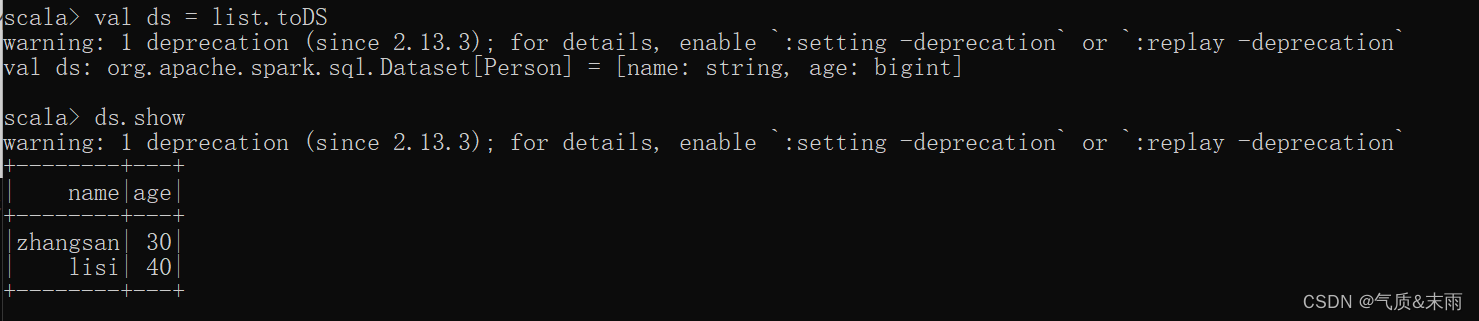
1) 创建 DataSet
使用样例类序列创建DataSet

上面创建了一个样例类的列表的数据 ,然后直接使用toDS 方法之间转换为DataSet

转换好之后,数据就可以直接看了。
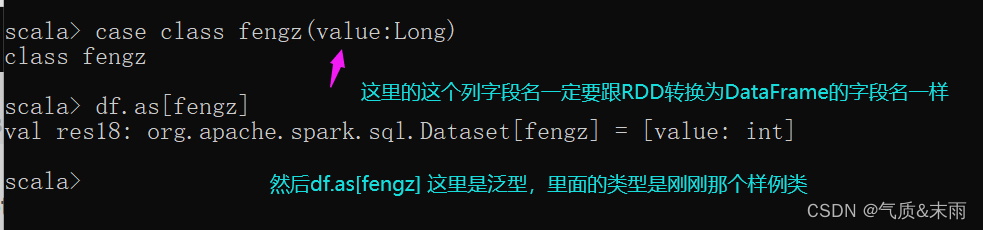
2) DataFrame 转换为 DataSet
首先从RDD转换为DataFrame使用rdd.toDF,然后我们要创建一个样例类,注意样例类里面这个列字段名要和那个DataFrame里面的那个字段名是一样的,比如这里这个是value,然后用df.as[fengz] 有了类型他就变成DataSet了。

3)RDD 直接转换为 DataSet
直接先创建一个样例类,把他的类型先确定好,然后创建一个RDD,RDD里面的数据直接使用这个样例类创建,然后直接使用rdd.toDS直接就从RDD转换为DataSet了。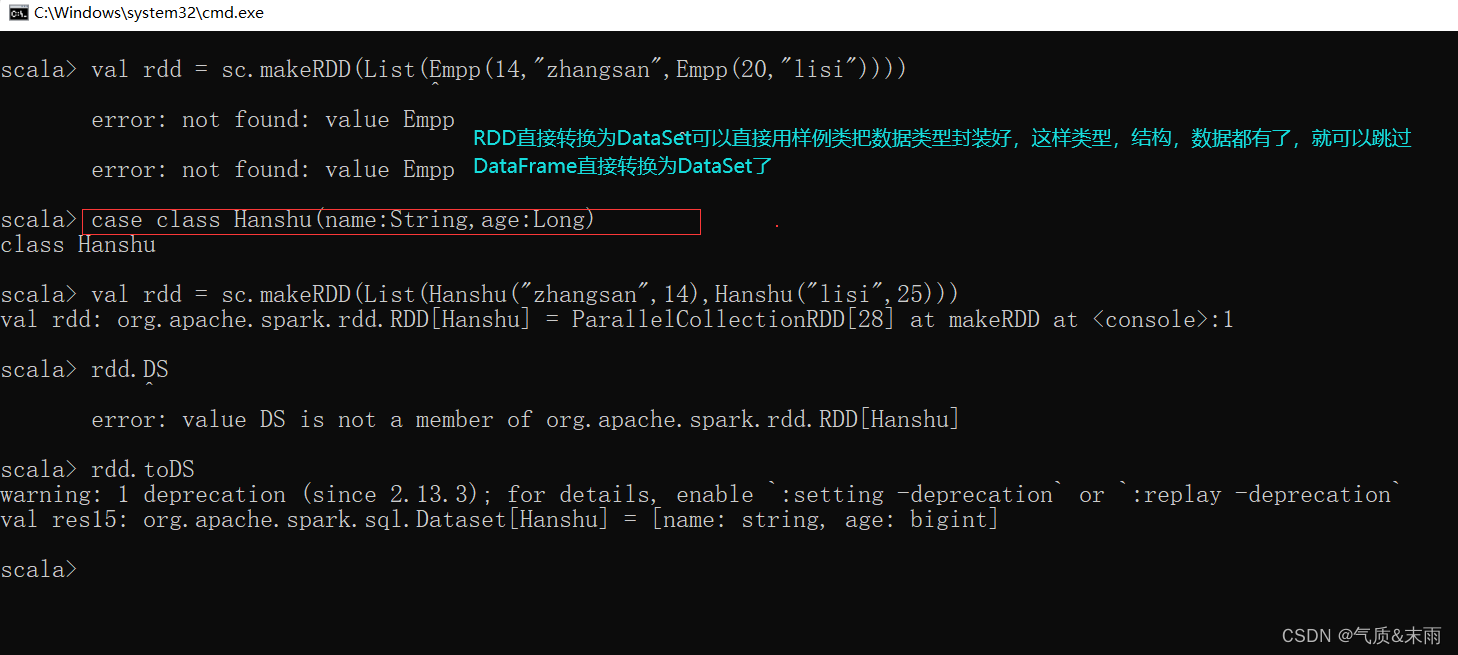
6、IDEA 开发SparkSQL
1) 添加依赖
注意这里的scala的版本和spark的版本一定要对。
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.3.1</version>
</dependency>
</dependencies>
注意:在使用DataFrame时,涉及到转换操作需要引入转换规则。import spark.implicits._这个spark不是包的名字,而是上下文配置对象的名字,这个名字可以随便取的。
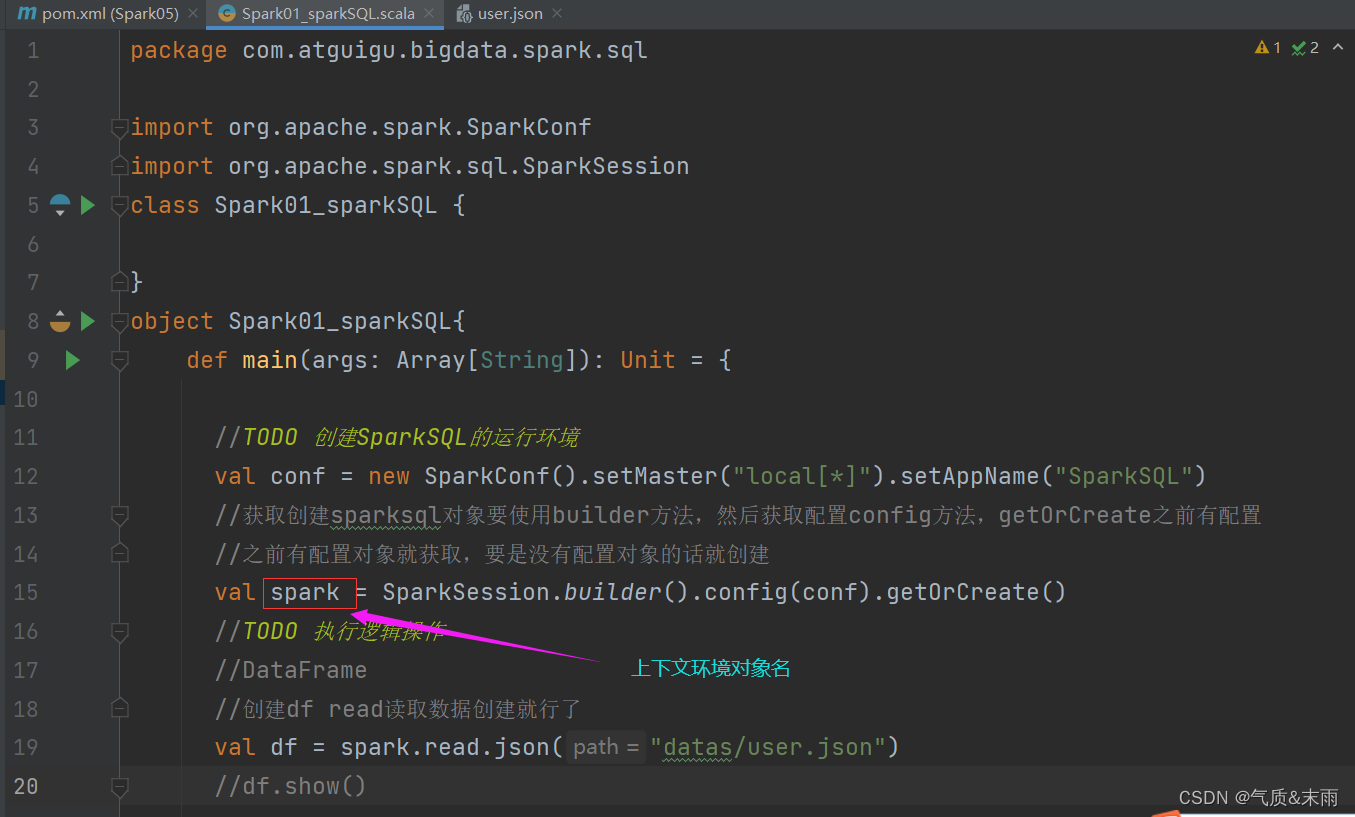
2) RDD & DataFrame & DataSet 互相转换
RDD 是只有数据,然后使用toDF()方法转换为DataFrame的时候可以加上字段这样就有字段了也就是DataFrame了,然后要是想转换为DataSet的话,那么还需要有类型,封装一个样例类case class User(id:Int,name:String,age:Int)有DataFrame的时候直接使用df.as[User] 然后返回这样就变成一个DataSet了,或者直接使用toDS方法也可以。
package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
class Spark01_sparkSQL {
}
object Spark01_sparkSQL{
def main(args: Array[String]): Unit = {
//TODO 创建SparkSQL的运行环境
val conf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL")
//获取创建sparksql对象要使用builder方法,然后获取配置config方法,getOrCreate之前有配置
//之前有配置对象就获取,要是没有配置对象的话就创建
val spark = SparkSession.builder().config(conf).getOrCreate()
//TODO 执行逻辑操作
//TODO DataFrame
//创建df read读取数据创建就行了
val df:DataFrame = spark.read.json("datas/user.json")
//df.show()
//DataFrame SQL 语法
df.createOrReplaceTempView("user") //临时视图
spark.sql("select avg(age) from user").show()
//在使用DataFrame时,如果涉及到转换操作
//需要引入转换规则
import spark.implicits._
//df.select($"age" + 1,"name").show()
//DataFrame => DSL 语法
df.select("name") //DSL不用创建一个临时的表对象,可以直接查询
//TODO DataSet
//DataFrame 其实是特定泛型的DataSet 所以前面DataFrame的方法,DataSet都可以用
val seq = Seq(1,2,3,4)
val ds: Dataset[Int] = seq.toDS() //直接toDS转换就是DataSet了
ds.show()
//RDD <=> DataFrame
val rdd = spark.sparkContext.makeRDD(List((1,"zhangsan",30),(2,"lisi",40)))
val df2 = rdd.toDF("id", "name", "age") //最这个是RDD转换为DataFrame
//这个是DataFrame转换为RDD直接rdd方法转换,但是类型不对
//上面是一个元组,这里的泛型是Row所以我们要写一个样例类
val rdd1: RDD[Row] = df2.rdd
//DataFrame <=> DataSet
//然使用as后面[]里面是泛型就是我们封装的样例类,这样类型也对了,
//但是这样有数据有结构有类型这样就变成DataSet了
//我们想把DataSet变成DataFrame直接把类型去掉就行了,直接toDF
val ds2 = df2.as[User] //然使用as后面[]里面是泛型就是我们封装的样例类,这样类型也对了,
val df3: DataFrame = ds2.toDF //这样类型也对了
//用样例类进行封装
case class User(id:Int,name:String,age:Int)
//RDD <=> DataSet
val ds3:Dataset[User] = rdd.map { //这里有类型有结构可以直接转换为ds
case (id, name, age) => {
User(id, name, age)
}
}.toDS()
//TODO 关闭环境
spark.close()
}
}
7 用户自定义函数
用户可以通过spark.udf功能添加自定义函数,实现自定义功能
1) UDF
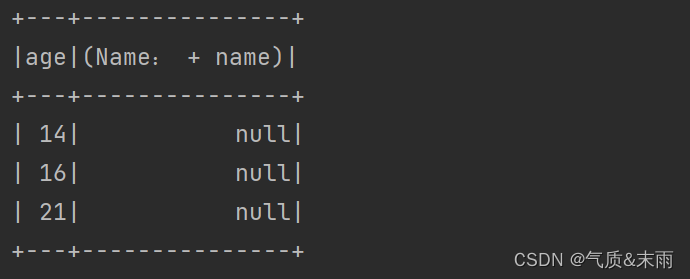
比如一个DataFrame 里面有两个字段,一个age,一个name,我们要做的是在表格中在name 字段下面的数据前面加上Name: 我们直接在SQL语句的查询字段前面直接加上这个的话,spark.sql("select age,'Name:' + name from user")这个样子是不行的。它查询出来是这个样子的,所以我们可以使用自定义函数来实现。
SparkSql 自定义函数,使用udf函数下面的register函数,这个样子就可以实现了,里面两个参数,第一个参数是自定义函数的名字,第二个参数就是函数,首先他有一个参数列表,把字段名写进去,然后把字段的类型的写好,然后下面就是这个字段的具体操作,比如这里是在name字段的数据前面加上Name: 所以直接这样操作就行了。
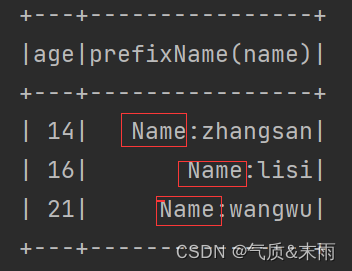
spark.udf.register("hanshu",(name:String) => { "Name:" + name })
然后下面再次进行查询spark.sql("select age,hanshu(name) from user").show() 这个name字段用我们的自定义函数包裹住。就可以出现我们想要的结果了。

package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
//SpatkSQL自定义函数
class Spark02_sparkSQL_UDF {
}
object Spark02_sparkSQL_UDF{
def main(args: Array[String]): Unit = {
//TODO 创建SparkSQL的运行环境
val conf = new SparkConf().setMaster("local[*]").setAppName("Spark_SQL_UDF")
val spark = SparkSession.builder().config(conf).getOrCreate()
val df = spark.read.json("datas/user.json")
df.createOrReplaceTempView("user") // 创建一个临时视图
//这个样子直接把Name放在里面是不行的,我们可以自定义一个函数来实现
//spark.sql("select age,'Name:'+ name from user").show()
spark.udf.register("prefixName",(name:String)=>{
"Name:" + name
}) //udf.register 方法可以自定义函数
spark.sql("select age,prefixName(name) from user").show()
//TODO 关闭环境
spark.close()
}
}
2) UDF 弱类型函数
弱类型的UDF自定义函数已经不推荐使用了,推荐使用强类型的UDF函数。
package com.atguigu.bigdata.spark.sql
import org.apache.hadoop.shaded.com.fasterxml.jackson.databind.deser.std.FromStringDeserializer.types
import org.apache.spark.sql.Row.empty.getLong
import org.apache.spark.sql.{Row, SparkSession, types}
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, LongType, StructField, StructType}
import org.apache.spark.{SparkConf, SparkContext}
class test {
}
object test{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("DataFrame")
val spark = SparkSession.builder().config(conf).getOrCreate()
val df = spark.read.json("datas/user.json")
df.createOrReplaceTempView("user")
spark.udf.register("MyAvgUDAF",new MyAvgUDAF())
spark.sql("select name,MyAvgUDAF(age) from user").show()
spark.close()
}
/*
* 自定义聚合函数类:计算年龄的平均值
* 1、继承 UserDefinedAggregateFunction
* 2、重写方法(8个)
* */
class MyAvgUDAF extends UserDefinedAggregateFunction{
override def inputSchema: StructType = {
//输入数据的结构
StructType( //这个类是单例对象,可以直接拿来用,他里面是个数组
Array(
StructField("age",LongType) //StructField方法是底层的
)
)
} //Schema(结构)输入结构
//缓冲区数据的结构 Buffer
//他这里面的结构就不是一个了,还有一个计算好的结果,count
override def bufferSchema: StructType = {
StructType( //这个类是单例对象,可以直接拿来用,他里面是个数组
Array(
StructField("total",LongType), //St(ructField方法是底层的 total总和
StructField("count",LongType)
)
)
}
//函数计算结果的数据类型:Out
override def dataType: DataType = LongType
//函数的稳定性
override def deterministic: Boolean = true
//Buffer缓冲区初始化
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L
buffer(1) = 0L
buffer.update(0,0L)
buffer.update(1,0L)
}
//根据输入的值更新缓冲区数据
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer.update(0,buffer.getLong(0)+input.getLong(0))
buffer.update(1,buffer.getLong(1)+1)
}
//缓冲区数据合并
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1.update(0,buffer1.getLong(0)+buffer2.getLong(1))
buffer1.update(1,buffer1.getLong(1)+buffer2.getLong(1))
}
//计算平均值
override def evaluate(buffer: Row): Any = {
buffer.getLong(0)/buffer.getLong(1)
}
}
}
3) UDF 强类型函数
实现思路:
首先我们在main方法下面自己定一个计算年龄平均值的类,然后继承org.apache.spark.sql.expressions.Aggregator 这个类,里面有三个泛型,第一个是输入的in,第二个是缓冲区转换的buff,第三个是输出的out,要定义他们的类型,首先输入的是年龄所以定义为Long,buff缓冲区,里面两个参数一个是计算年龄总数的total,然后还有一个是统计次数的,也就是有几个人。所以我们定义一个样例类case class Buff(var total:Long,var count:Long),然后输出的是计算好的年龄平均值,当然也是Long。
然后泛型定义好之后,Aggregator是一个抽象类,我们要重写它里面的方法了,里面有六个方法:
第一个方法是zero在scala里面看到这个方法一般都是初始值,我们要定义缓冲区初始值,缓冲区buff的初始值,他们都是都是Long类型的,所以初始值定义为Buff(0L,0L),所以总数和次数的初始值都是0。
然后第二个方法是reduce,这个是输入的数据来更新缓冲区的数据,这个方法里面两个参数第一个是Buff,第二个是in,buff.total = butal.total + in,这样子来进行总数的更新,然后这里加了一次,次数也要进行更新,buff.count = buff.count + 1,最后第三行直接返回一个buff,就更新完成了。
第三个方法是merege合并,因为spark是会分为多个区进行计算的,所以我们这里要进行分区间的合并了,merge方法里面两个参数,buff1和buff2,buff1.total = buff1.total + buff2.total 这样总数就合并完成了,还有统计次数也是一样的,buff1.count = buff1.count + buff2.count,最后返回 buff1。这就是最终返回的结果,
第四个方法是finish,这是计算结果,上面我们年龄总和和统计次数都已经拿到了,我们可以直接用年龄总和除以次数就行了。buff.total / buff.count。这样计算就完成了。
最后还有两个方法缓冲区和输出的编码操作。是涉及到数据在网络中传输,序列化还有编码和解码的操作。这个是系统固定的Encoders编码,如果是我们自定义的类型,比如说buff,那么统一都是Encoders.prodouct,如果是scala自己就有的类型,比如我们这里输出的Long是有的那么就是,Encoders.scalaLong。
我们将这个类里面的方法重写完了,上面我们main方法里面要进行调用了。创建自定义函数spark.udf.register("avgAge",functions.udaf(new MyAvgUDF)),然后接下来正常的使用sql语句调用spark.sql("select ageAvg(age) from user").show(),重点是我们这是强类型的,类型都是定义好了的,但是sql不能直接解析,所以我们使用fuctions.udaf()来进行转换,转换为弱类型的自定义函数就可以使用了。
package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.{Encoder, Encoders, Row, SparkSession, functions}
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, LongType, StructField, StructType}
//强类型的自定义函数
class Spark04_sparkUDF_qiang {
}
object Spark04_sparkUDF_qiang{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("UDF_qiang")
val spark = SparkSession.builder().config(conf).getOrCreate()
val df = spark.read.json("datas/user.json")
//创建临时视图
df.createOrReplaceTempView("user")
//创建自定义函数
spark.udf.register("avgAge",functions.udaf(new MyAvgUDF))
//使用sql语句查询
spark.sql("select ageAvg(age) from user").show()
spark.close()
}
/*
* 自定义聚合函数类:计算年龄的平均值
* 1、继承 org.apache.spark.sql.expressions.Aggregator 定义里面的泛型
* IN: 输入的数据类型 Long 年龄的值那肯定就是数值的所以是Long
* BUF: 里面有两个参数一个是统计总数的,一个是统计次数的,没有现成的我们定义一个样例类
* OUT: 输出的也是年玲的平均值也是 Long
* 2、重写方法(8个)
* */
case class Buff(var total:Long,var count:Long)
class MyAvgUDF extends Aggregator[Long,Buff,Long]{
//一般在scala中,重写方法有z & zreo的,一般都是初始值或者零值
//缓冲区的初始化
override def zero: Buff = {
Buff(0L,0L) //因为我们定义的样例类,BUFF里面有两个变量,一个total就是0,count初始值也定义为0
}
//根据输入的数据来更新缓冲区的数据
override def reduce(buff: Buff, in: Long): Buff = { //前面buff是缓冲区的数据,in是输入的
buff.total = buff.total + in //buff.total初始值是0,现在等于total+in相当于输入的值加进来更新
buff.count = buff.count + 1 //这个是统计次数的,total是统计总数的,上面更新了数据这下面次数要+1
buff //最后返回buff
}
//合并缓冲区
//merge都是合并的
override def merge(buff1: Buff, buff2: Buff): Buff = {
buff1.total = buff1.total + buff2.total //这个就是缓冲区的总和
buff1.count = buff1.count + buff2.count //这是两个区统计次数的总和
buff1
}
//计算结果
override def finish(buff: Buff): Long = {
buff.total / buff.count //上面的总数和统计的次数都有了,就非常简单,直接除就完了
}
//缓冲区的编码操作
//因为将数据在网络中传输涉及到一个序列化的问题还有编码和解码的操作,Encoder就是编码
override def bufferEncoder: Encoder[Buff] = {
Encoders.product //这两个是固定的写法,如果自定义的类那么就是prodoct
}
//输出的编码操作
override def outputEncoder: Encoder[Long] = {
Encoders.scalaLong //如果是scala有的类那么就是scalaLong 如果是String那么就是scalaString
}
}
}
4) UDAF
强类型的 DataSet 和弱类型的DataFrame 都提供了相关的聚合函数,如count(),countDistinct(),avg(),max(),min()。除此之外,用户可以设定自己的自定义聚合函数。通过继承 UserDefinedAggregateFunction 来实现用户自定义弱类型聚合函数。从Spark3.0版本后,UserDefindAggregateFunction 已经不推荐使用了,可以统一采用强类型聚合函数 Aggregator。
8、Spark SQL 数据的加载和保存
1) 通用的加载和保存方式
SparkSQL 提供了通用的保存数据和数据加载的方式,这里的通用指的是使用相同的API,根据不同的参数读取和保存不同格式的数据,Spark SQL 默认读取和保存的文件格式为 parquet(这是一种列式存储的方式)。
(1) 加载数据通用方式
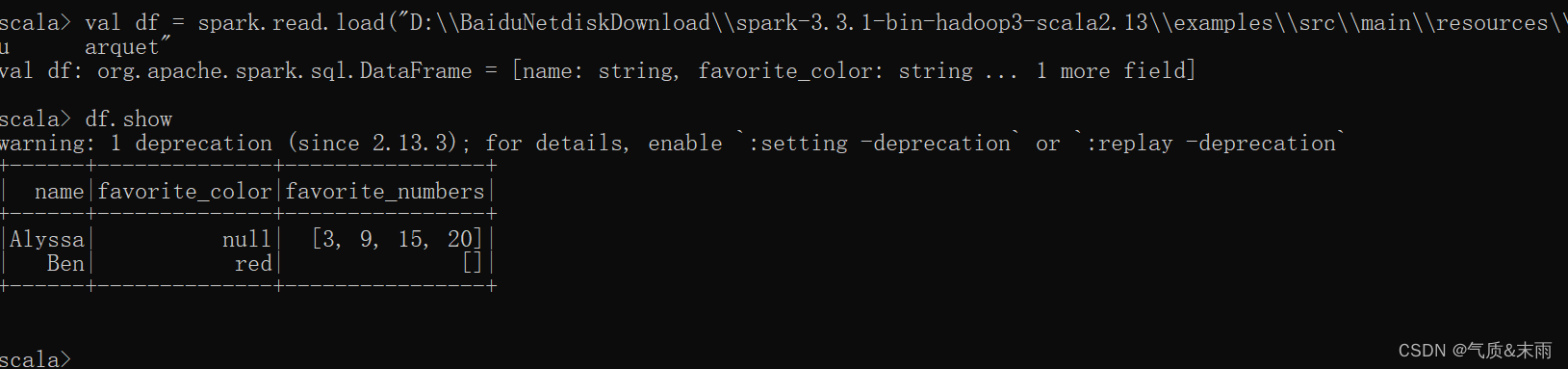
val df = spark.read.load 是加载数据的通用方法,里面的参数是读取的路径

spark.read.load() 默认读取的是parquet格式的数据,要是读取的是其他格式的数据会报错,比如json。
df.writer.save("output") 这个是保存数据的方法,里面的参数是保存的路径,保存数据的格式默认也是parquet
spark.read.load() 默认读取的都是parquet格式的数据,要是想读取其他格式的数据可以使用 format()方法,比如spark.read.format("json").load("data/user.json") 这样皆可以用load读取json格式的文件了,保存文件的也是一样的,比如我们读取的是parquet格式数据,我们想保存成其他格式的,spark.write.format("json").sava("oupput") 这样就保存为json格式的数据了。
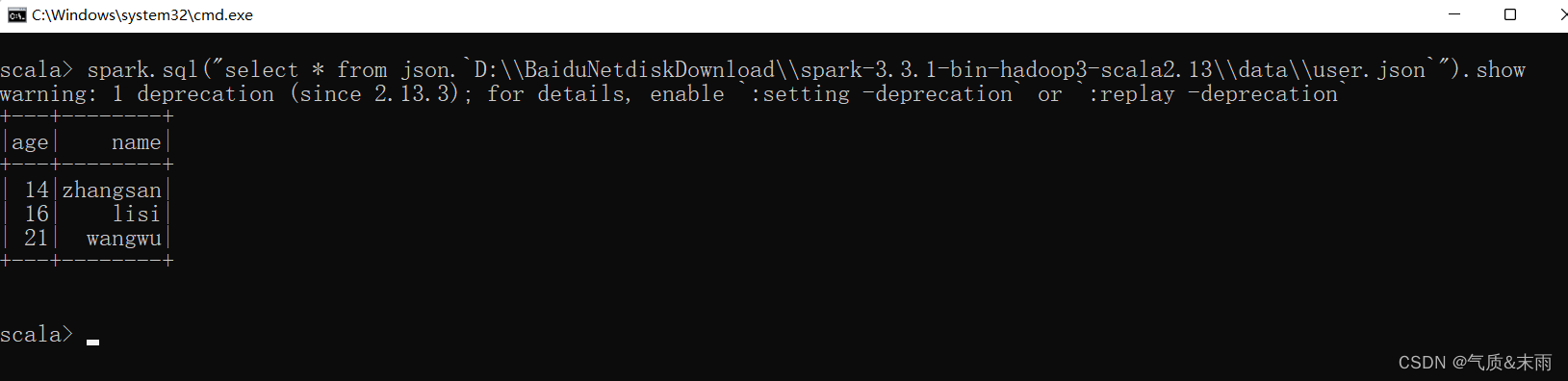
我们前面都是使用read API 先把文件加载到DataFrame 然后再查询,其实,我们也可以直接在文件上进行查询:文件格式 + 文件路径 这个文件路径要用``这个包起来,比如:
spark.sql("select * from json.·D:\\ user.json·") 因为用 那两个 ··会自动变红所以这里我用这个代替,大概就是这个样子,就可以不用创建临时表然后再使用sql语句。
(2) 通用保存
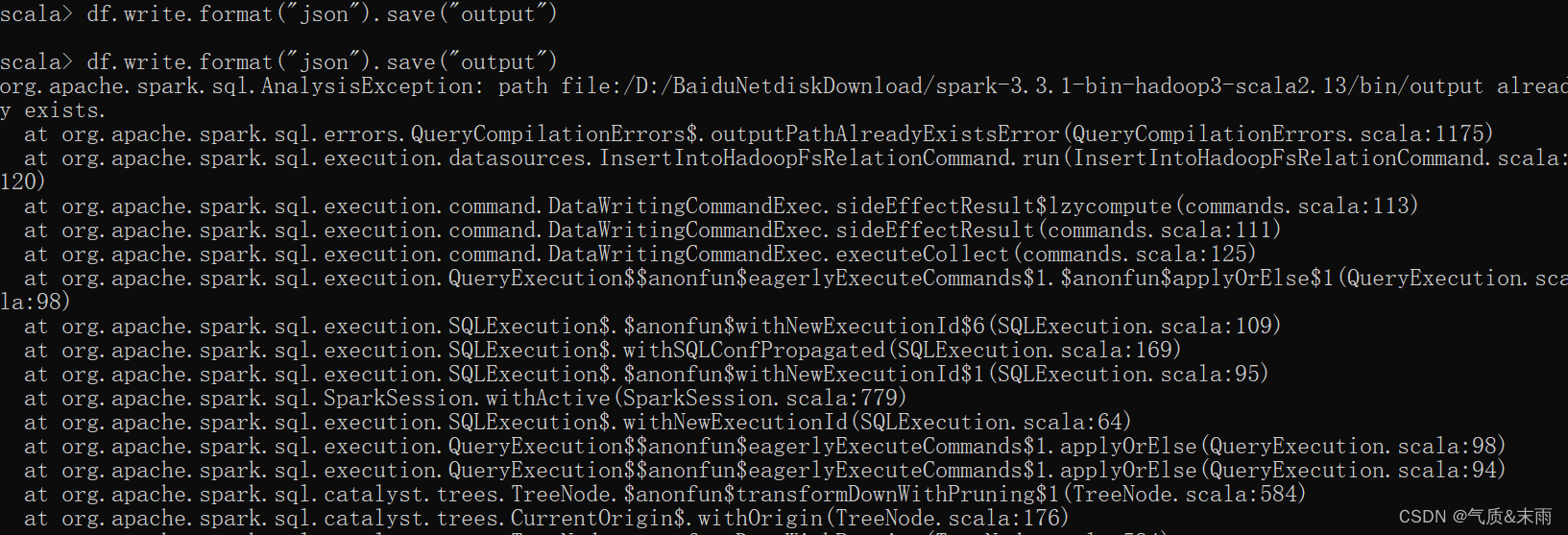
df.write.sava() 通用保存的方法
spark.read.load() 默认读取的都是parquet格式的数据,要是想读取其他格式的数据可以使用 format()方法,比如spark.read.format("json").load("data/user.json") 这样皆可以用load读取json格式的文件了,保存文件的也是一样的,比如我们读取的是parquet格式数据,我们想保存成其他格式的,spark.write.format("json").sava("oupput") 这样就保存为json格式的数据了。
当我们保存了之后重复进行保存就会报错
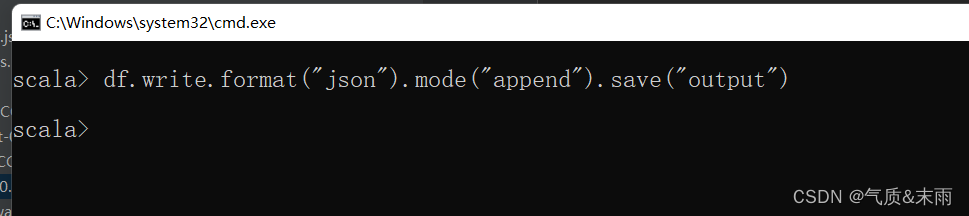
保存操作可以使用 SavaMode,用来指明如何处理数据,使用 mode() 方法来设置,有一点很重要:这些 SavaMode 都是没有加锁的,也不是原子操作。
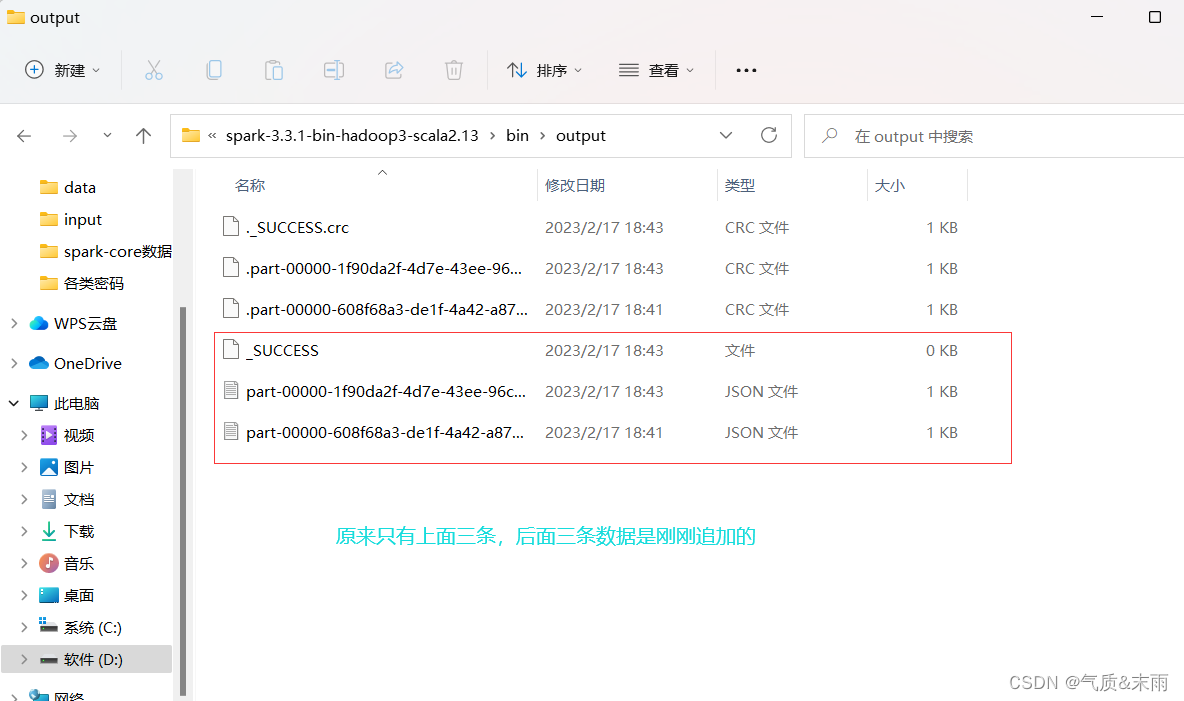
df.write.mode("append").json("/opt/module/data/output") append是追加,我们可以在原来保存的数据后面再追加一个,这样就不会报错了
SavaMode 是一个枚举类,其中的常量包括:
也就是包括error(警告),append(追加),overwrite(覆盖,ignore(忽略)这四种
| Scala/Java | Any Language | Meaning |
|---|---|---|
| SaveMode | “error”(default) | 如果文件已经存在则抛出异常 |
| SaveMode.Append | “append” | 如果文件已经存在则追加 |
| SaveMode.Overwrite | “overwrite” | 如果文件已存在则表示覆盖 |
| SaveMode.Ignore | “ignore” | 如果文件已经存在则忽略 |
(3) parquet
Spark SQL 的默认数据源为Parquet格式。Parquet 是一种能够有效存储嵌套数据的列式存储格式。
数据源为Parquet文件时,Spark SQL 可以方便的执行所有操作,不需要使用format修改配置项 spark.sql.sources.default,可修改默认数据源格式。
(4) json
Spark SQL 能够自动推测 json 数据集的格式,并将它加载为一个 DataSet[Row] 可以通过 SparkSession.read.json() 去加载 json 文件。
注意:Saprk 读取的json 文件不是传统的 json 文件,每一行都应该是一个 json 串。格式如下:
它是按照一行一行读取的,只要每一行符合json格式的标准就行,绝对不能后面有啥逗号啥的。
{"name": "zhangsan"}
{"name": "lisi","age": 16}
[{"name": "wangwu","age": 21},{"name": "lisi","age": 16}]
(5) csv
Spark SQL 可以配置 CSV 文件的列表信息,读取CSV文件,CSV文件的第一行设置为数据列。
val df = spark.read.format("csv").option("sep",";").option("infeSchema").option("header","true").load("D:\\output\\peple.csv")
其中,.option("sep",";")是进行分隔,然后option("header","true")是以第一行为表头,也就是是列的字段名

9、MySQL 操作
Spark SQL 可以通过JDBC从关系型数据库中读取数据的方式创建DataFrame,通过对DataFrame 一系列计算后,还可以将数据再写回关系型数据库中。如果使用spark-shell操作,可在启动 shell 时指定相关的数据库驱动路径或者将相关的数据库驱动放到 spark 的类路径下。
下面是IDEA中通过JDBC对MySQL进行操作
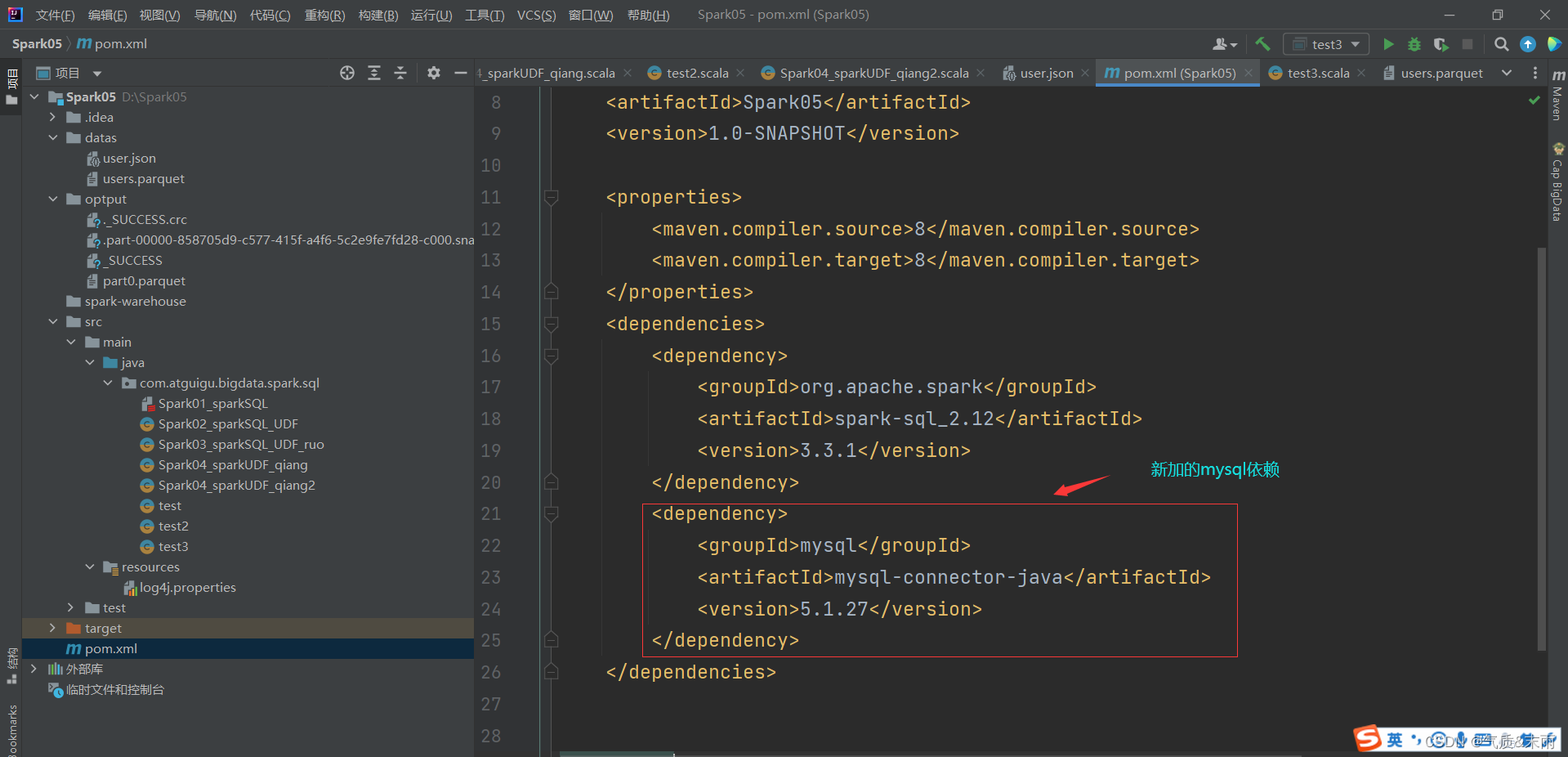
1) 导入依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
2) 读取数据
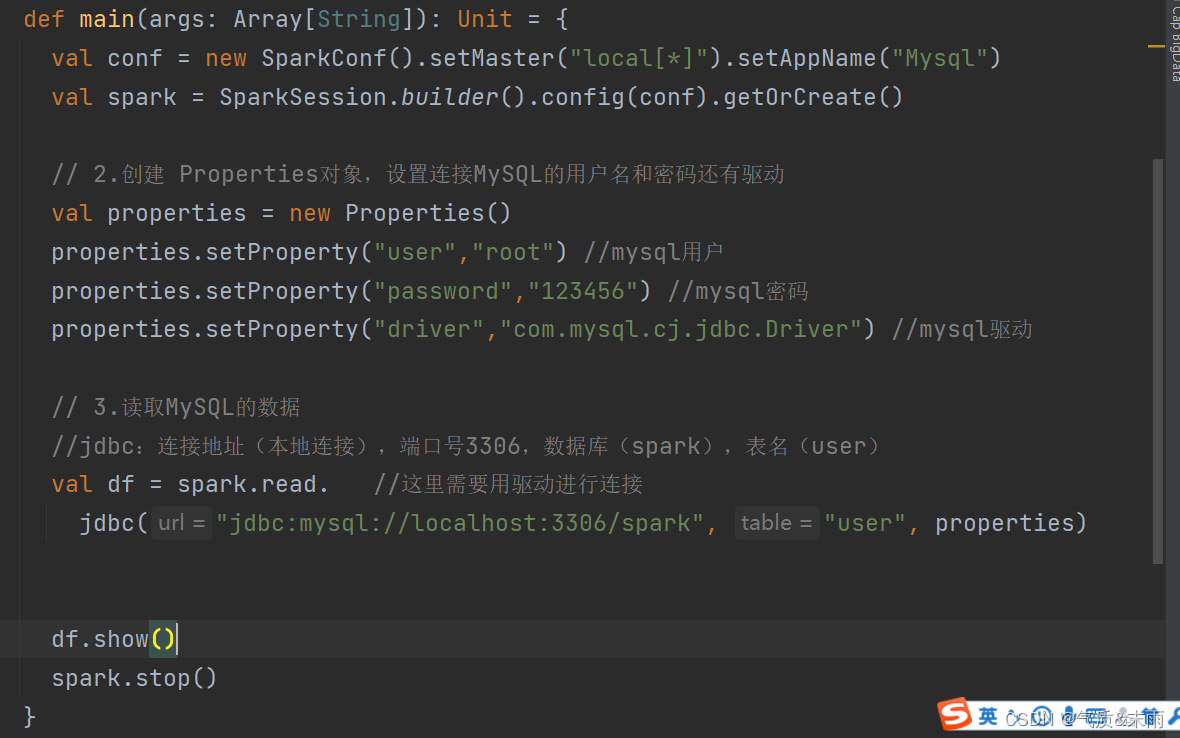
首先要进行数据库连接,需要创建new一个 Properties 对象,Properties 对象有一个setProperty()方法,需要设置连接MySQL数据库的用户名和密码还有驱动。下面是创建DataFrame,val df = spark.read.jdbc("jdbc:mysql://localhost:3306/spark","user",properties),里面三个参数,第一个参数是连接的方式,端口号和数据库,第二个参数是表,第三个参数是上面设置的的 properties 对象。
这样就把Mysql数据库中uesr表的数据给读取出来了。
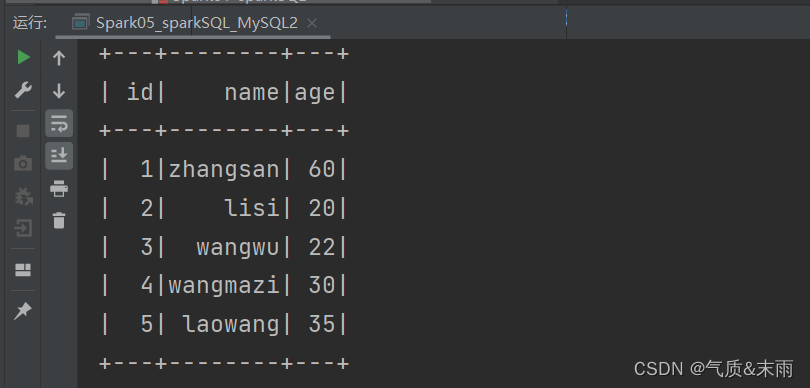
package com.atguigu.bigdata.spark.sql
import org.apache.hadoop.shaded.com.google.j2objc.annotations.Property
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.zookeeper.server.SessionTracker.Session
import java.util.Properties
class Spark05_sparkSQL_MySQL2 {
}
object Spark05_sparkSQL_MySQL2{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("Mysql")
val spark = SparkSession.builder().config(conf).getOrCreate()
// 2.创建 Properties对象,设置连接MySQL的用户名和密码还有驱动
val properties = new Properties()
properties.setProperty("user","root") //mysql用户
properties.setProperty("password","123456") //mysql密码
properties.setProperty("driver","com.mysql.cj.jdbc.Driver") //mysql驱动
// 3.读取MySQL的数据
//jdbc:连接地址(本地连接),端口号3306,数据库(spark),表名(user)
val df = spark.read. //这里需要用驱动进行连接
jdbc("jdbc:mysql://localhost:3306/spark", "user", properties)
df.show()
//关闭环境
spark.stop()
}
}
3) 保存数据
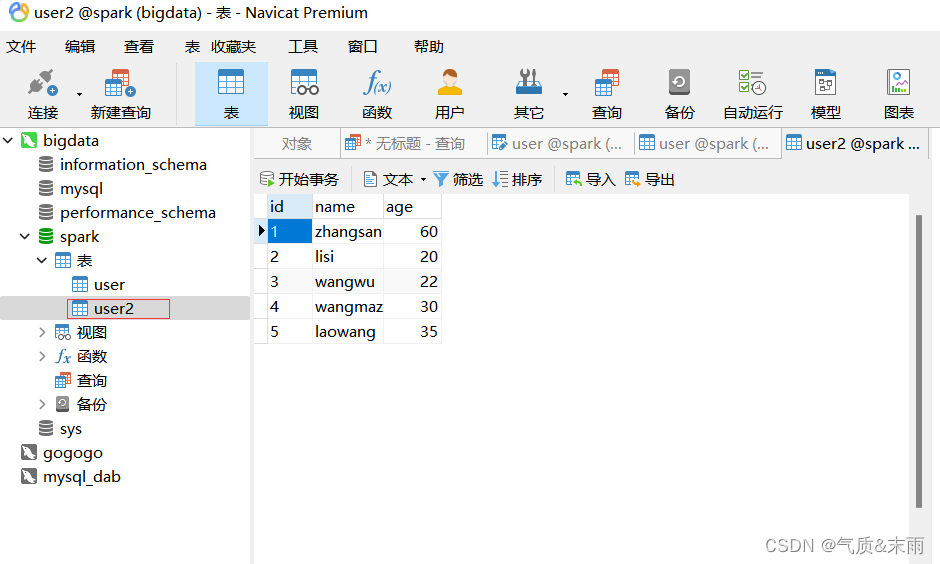
df.write.mode("append").jdbc("jdbc:mysql://localhost:3306/spark", "user2", properties)保存数据直接 使用df.write.mode 然后里面是追加,然后.jdbc 跟上面一样的直接表名改一下就行了,我们创建一个新的表进行保存。
这样我们数据库中就多了一个叫 user2的新表
10、Hive 内置操作
Apache Hive 是 Hadoop 上的SQl引擎,Spark SQL编译时可以包含 Hive 支持,也可以不包含。包含 Hive 支持的Spark SQL 可以支持Hive表访问,UDF(用户自定义函数)。
首先创建一张表,输入命令:spark.sql("create table atguigu(id int)")
因为这里面就一个字段,id,所以我们准备一个存放数据的文件


接下来输入命令:spark.sql("load data local inpath 'D:\\id.txt' into table atguigu")
将数据给导入atguigu表中

现在可以看到有atguigu这个表了

这样相当于是在本地建立了一些数仓的东西,但是我们一般是使用的外置连接,内置的hive一般都是用来做练习的。
11、HIve 外置操作
1) linux Hive 外置操作
这是在 linux 中,使用shell
如果想要连接外部已经部署好的Hive,需要通过以下几个步骤:
(1) Spark 要接管 Hive 需要把hive-site.xml 拷贝到 conf/目录下
(2) 把Mysql的驱动copy到jars/目录下
(3) 如果访问不到hdfs,则需要把core-site.xml 和 hdfs-site.xml 拷贝到 conf/目录下
(4) 重启 spark-shell
2) IDEA 代码操作Hive
工作当中,一般想从Hive中取一些数据,一般都是在程序中操作。
(1) 导入依赖
需要导入这些依赖,这些是所有的依赖,注意这里的mysql的版本是8.0.32,spark的版本是3.3.2,scala的版本是2.13,不要导入错了,然后还会引发日志冲突,所以这些全部都要导入进去。
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.2</version>
<exclusions>
<exclusion>
<groupId>org.apache.log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.9</version>
</dependency>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.32</version> <!--8.0.32-->
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.13</artifactId>
<version>3.3.1</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.codehaus.janino</groupId>
<artifactId>janino</artifactId>
<version>3.0.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.13</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.13</artifactId>
<version>3.3.1</version>
</dependency>
</dependencies>
(2)linux spark-sql
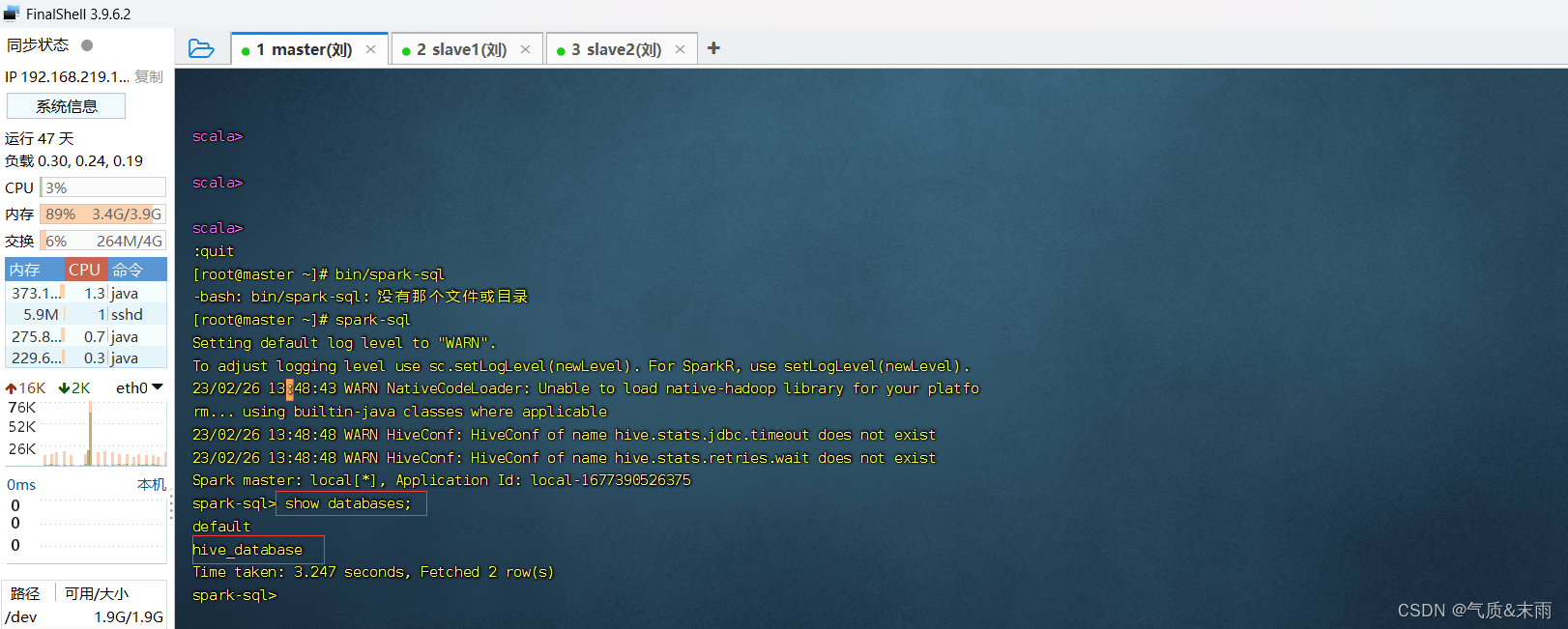
那样子连太麻烦了,可以直接spark-sql进入,然后就可以直接sql语句了,show databases;记得要加分号,然后就可以看到hive中的数据库了。















 5233
5233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









