






 本文详细介绍了Stata中的sort和gsort命令,用于数据排序,包括语法、示例以及推荐的学习路径。针对计量经济学初学者,强调了实践操作和结合阅读专业文献的重要性。
本文详细介绍了Stata中的sort和gsort命令,用于数据排序,包括语法、示例以及推荐的学习路径。针对计量经济学初学者,强调了实践操作和结合阅读专业文献的重要性。
在很多应用场景,用户需要对数据进行排序处理。Stata排序命令主要为sort命令和gsort命令。
sort命令的语法格式为:
sort varlist [in] [, stable]
varlist代表将要进行排序的变量,[in]代表排序的范围,[, stable]的含义是如果两个观测值相同,其顺序保持与原数据相同。
gsort命令的语法格式为:
gsort [+|-] varname [[+|-] varname ...] [, generate(newvar) mfirst]
其中[+]表示按升序排列,[-]表示按降序排列,Stata默认升序排列。generate(newvar)表示排序之后生成新的变量,mfirst表示将缺失值排在最前面。
此处以本书附带的“数据1E”数据文件为例进行说明,在命令窗口中输入:
use "C:\Users\Administrator\Desktop\数据1E.dta" (本命令的含义是打开“数据1E”数据文件)
sort y5 (本命令的含义是将“数据1E”数据文件中的样本观测值按变量y5从小到大排列)
上述命令的执行结果如图1.63和图1.64所示,其中图1.63为排序前的数据,图1.64为排序后的数据。
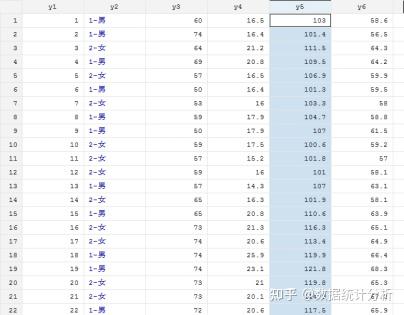
图1.63 排序前的y5数据
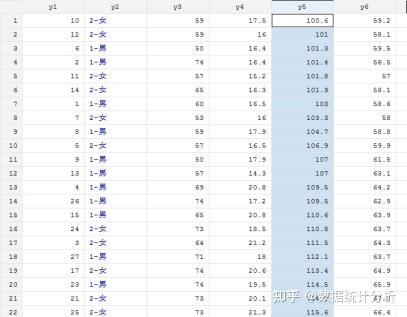
图1.64 排序后的y5数据
该操作也可以使用gsort命令完成,命令为:
gsort + y5
读者可以自行执行一遍,查看执行结果是否与上述结果相同。
本案例节选自《Stata统计分析从入门到精通》 杨维忠、张甜 清华大学出版社。关于学习Stata与计量经济学的问题,如果大家只是为了写论文,而不是专门的计量经济学专业、研究计量理论方法的,推荐学习路径如下:如果是新手可以先学习这本书《Stata统计分析从入门到精通》 杨维忠、张甜 清华大学出版社。

2022年新书,山东大学陈强教授作序推荐。


本书专为计量经济学基础薄弱或学不进去,但又有写论文的读者入门所设计,注重应用,较少数学推导。边看书边操作,学的差不多了以后,再多看你目标研究领域的高质量的研究文献,看看人家用的什么方法,比如政策效应检验、结构方程模型等等,再针对性的学习那些相对较难、比较专业的方法就可以(到了那个阶段和层次,基本就可以通过看文献自学了;而针对一些前沿的方法或者要更加系统的学习,参加陈强老师的培训班也是一个很好的选择)。
创作不易,恳请多多点赞,欢迎大家多多关注我,一起学习Stata/SPSS/Python,感谢大家的厚爱支持!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











