







引言
在我们的项目中,我们需要实现一个图像转文本的功能,即根据输入的图片自动生成描述性文字。
BLIP模型初尝试
最初,我尝试使用了Hugging Face提供的两个BLIP模型:
blip-image-captioning-baseblip-image-captioning-large
这两个模型都是基于BLIP架构的经典图像描述生成模型。
在实际测试中,我发现这两个模型存在以下问题:
- 生成的描述过于简短,缺乏细节
- 对于复杂场景的理解能力有限
- 对特定领域图片(如医学图像、技术图表)的适应性差
- 无法根据提示词(prompt)进行条件生成
尽管调整了生成参数(如max_length、num_beams等),效果提升仍然有限,无法满足我们的项目需求。
class BLIPService:
def __init__(self):
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.processor = BlipProcessor.from_pretrained(MODEL_PATH)
self.model = BlipForConditionalGeneration.from_pretrained(MODEL_PATH).to(self.device)
if self.device == "cuda":
self.model = self.model.half()
def blip_analyze_image(self, image_url):
"""分析图片并生成描述
Args:
image_path: 图片路径(URL)
Returns:
str: 生成的描述文本
"""
prompt = "a photo of"
try:
# 支持图片URL
response = requests.get(image_url, stream=True, timeout=10)
response.raise_for_status()
image = Image.open(response.raw).convert('RGB')
# 条件生成或无条件生成
inputs = self.processor(image, text=prompt, return_tensors="pt").to(self.device)
if self.device == "cuda":
inputs = inputs.to(torch.float16)
with torch.no_grad():
outputs = self.model.generate(
**inputs,
max_length=150,
num_beams=5,
temperature=0.7
)
return self.processor.decode(outputs[0], skip_special_tokens=True)
except Exception as e:
raise RuntimeError(f"BLIP analysis failed: {str(e)}")
# 单例模式(全局共享实例)
blip_service = BLIPService()
@blip_bp.route('/blip-analyze-image', methods=['POST'])
def blip_analyze_image():
"""处理图片上传和分析请求
支持传递图片URL(application/json)
"""
try:
data = request.get_json()
image_url = data.get('image_url')
if not image_url:
return jsonify({"error": "Missing 'image_url'"}), 400
description = blip_service.blip_analyze_image(image_url)
return jsonify({"description": description})
except Exception as e:
return jsonify({"error": str(e)}), 500
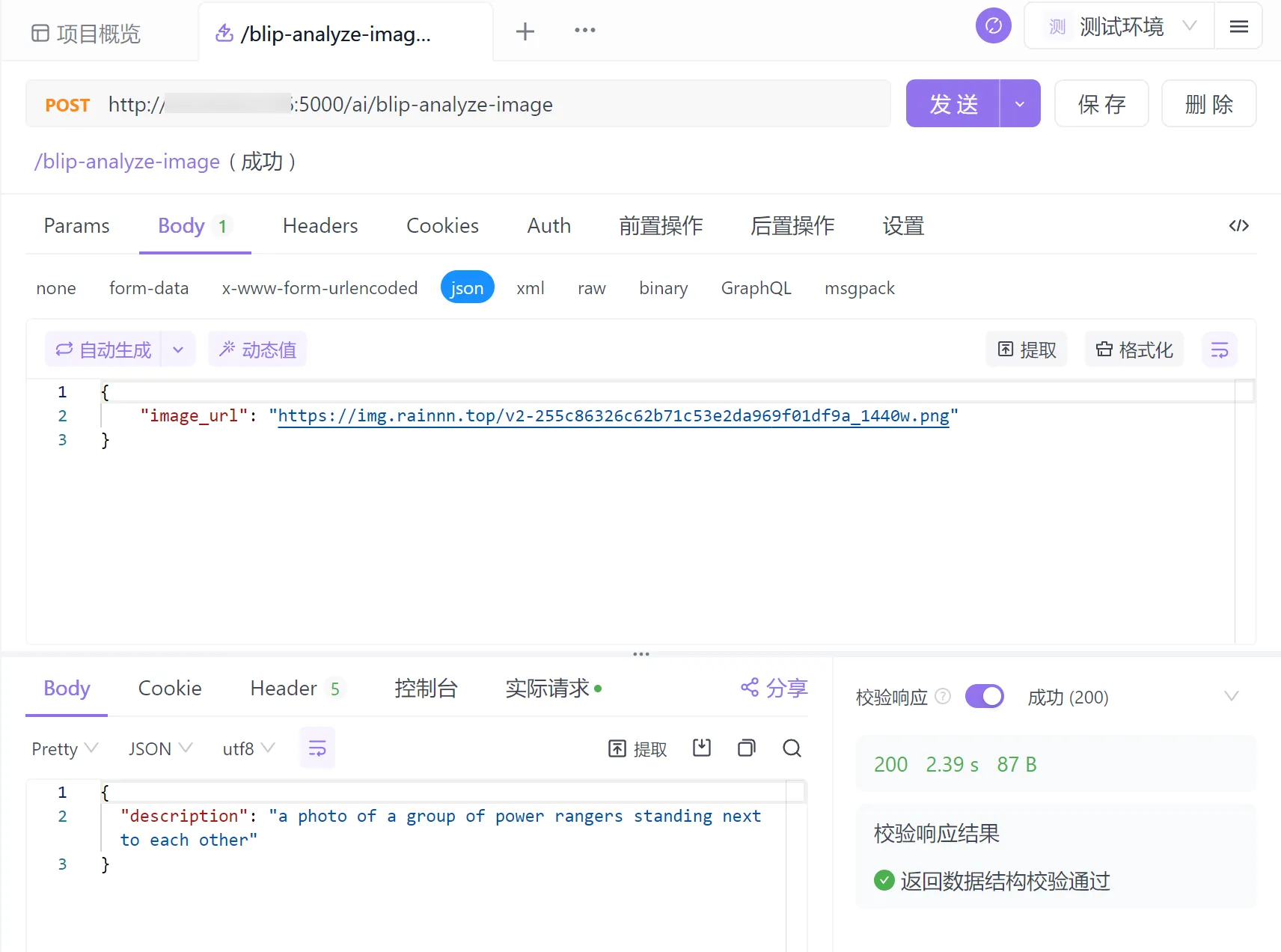
比如在上面的测试中,该模型并无法识别ultraman,且描述的很简短
转向BLIP2模型
经过调研,我决定尝试BLIP2模型,BLIP2采用了创新的架构设计,将预训练的视觉模型和语言模型通过轻量级的Q-Former连接起来,实现了更强大的图像理解能力。
BLIP2的优势:
- 更大的模型规模:我们选择了
blip2-opt-2.7b版本,相比之前的BLIP模型参数规模更大 - 多模态理解能力:能够更好地理解图像和文本之间的关系
- 条件生成:可以根据提示词(prompt)生成特定风格的描述
- 生成质量:描述更加详细、准确,符合人类语言习惯
实现代码
在我们的Flask后端服务中,我实现了BLIP2的服务类:
python
class BLIP2Service:
def __init__(self):
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.processor = Blip2Processor.from_pretrained(MODEL_PATH)
self.model = Blip2ForConditionalGeneration.from_pretrained(
MODEL_PATH,
device_map={"": self.device},
torch_dtype=torch.float16
)
def blip2_analyze_image(self, image_url, prompt):
print(f"✅ 正在使用设备: {self.device.upper()}")
try:
# 支持图片URL
response = requests.get(image_url, stream=True, timeout=10)
response.raise_for_status()
image = Image.open(response.raw).convert('RGB')
# 条件生成或无条件生成
inputs = self.processor(image, text=prompt, return_tensors="pt").to(self.device, torch.float16)
# 生成描述
with torch.no_grad():
outputs = self.model.generate(
**inputs,
max_length=150,
num_beams=5,
min_new_tokens=20,
repetition_penalty=1.5,
length_penalty=1.0,
)
return self.processor.decode(outputs[0], skip_special_tokens=True)
except Exception as e:
raise RuntimeError(f"BLIP2 analysis failed: {str(e)}")
@blip_bp.route('/blip-analyze-image', methods=['POST'])
def blip_analyze_image():
"""处理图片上传和分析请求
支持传递图片URL(application/json)
"""
try:
data = request.get_json()
image_url = data.get('image_url')
if not image_url:
return jsonify({"error": "Missing 'image_url'"}), 400
description = blip_service.blip_analyze_image(image_url)
return jsonify({"description": description})
except Exception as e:
return jsonify({"error": str(e)}), 500
在具体实践中,为了使Flask 服务在 Docker Compose 中使用 GPU,需要修改docker-compose.yml 文件,添加 GPU 支持相关的配置如下:
services:
moodVine_ai:
...... # 此处省略,在上文中提到过
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu] # 启用 GPU 计算能力
command: flask run --host=0.0.0.0 --reload
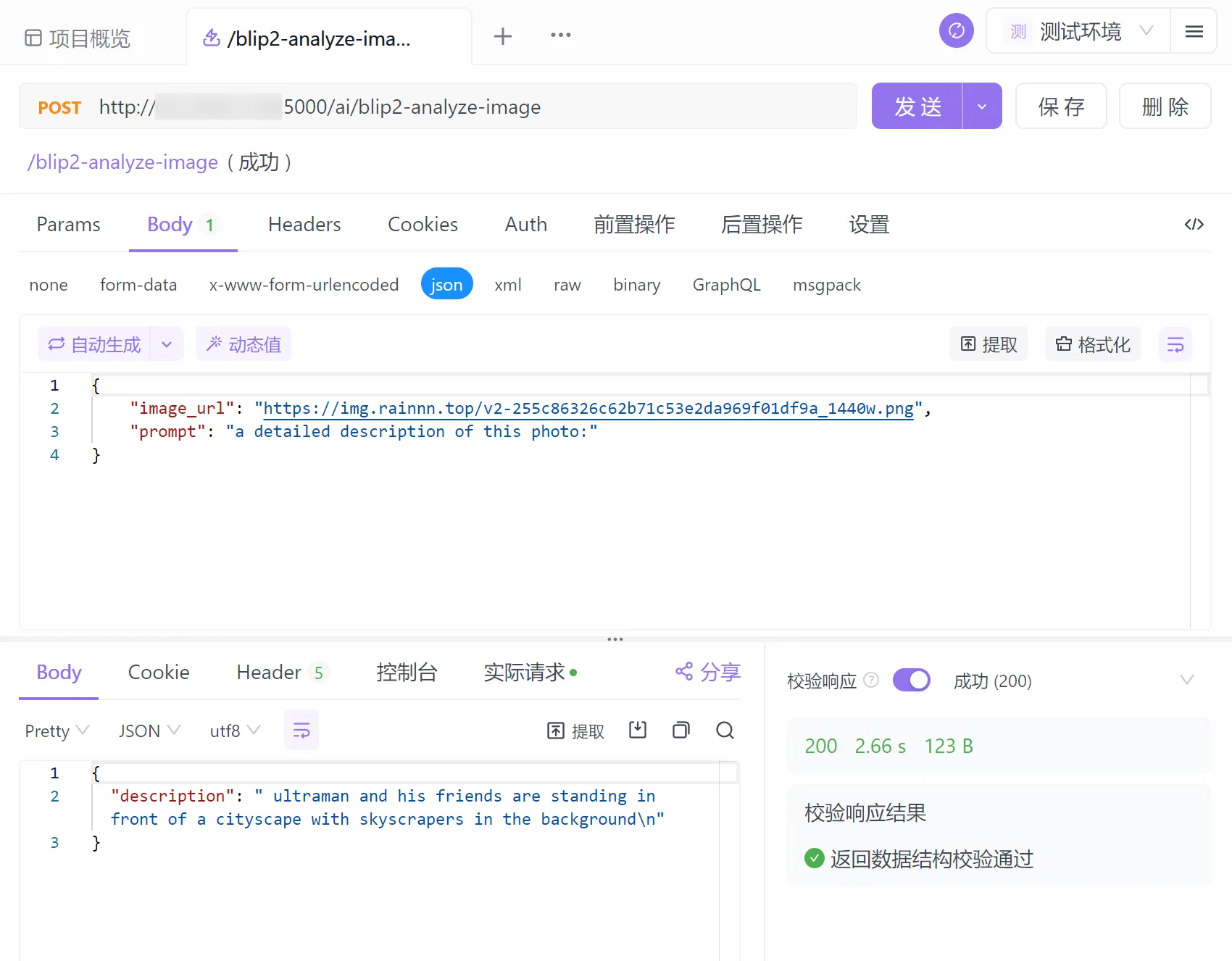
可以看到,该模型在基本差不多的生成速度下,生成的描述更为详细且能够正确识别ultraman


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









