






使用Flask-SQLAlchemy管理数据库:
扩展Flask-SQLAlchemy集成了SQLAlchemy,它简化了连接数据库服务器、管理数据库操作会话等各类工作,让Flask中的数据处理体验变得更加轻松。首先使用Pipenv安装Flask-SQLAlchemy及其依赖(主要是SQLAlchemy)
$ pipenv install flask-sqlalchemy然后实例化Flask-SQLAlchemy提供的SQLAlchemy类,传入程序实例app,以完成扩展的初始化:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
db = SQLAlchemy(app)我们把实例化扩展类的对象命名为db。这个db对象代表我们的数据库,它可以使用Flask-SQLAlchemy提供的所有功能。
连接数据库服务器
DBMS通常会提供数据库服务器运行在操作系统中。要连接数据库服务器,首先要为我们的程序指定数据库URI,数据库URI是一串包含各种属性的字符串,其中包含了各种用于连接数据库的信息。
常用的DBMS及其数据库URI格式示例

连接Mysql:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:root@127.0.0.1:3306/flask_test'
db = SQLAlchemy(app)定义数据库模型:
用来映射到数据库表的Python类通常被称为数据库模型(model),一个数据库模型类对应数据库中的一个表。定义模型即使用Python类定义表模式,并声明映射关系。所有的模型类都需要继承Flask-SQLAlchemy提供的db.Model基类。
class Users(db.Model):
__tablename__='tb_users'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.Text)常用数据类型:
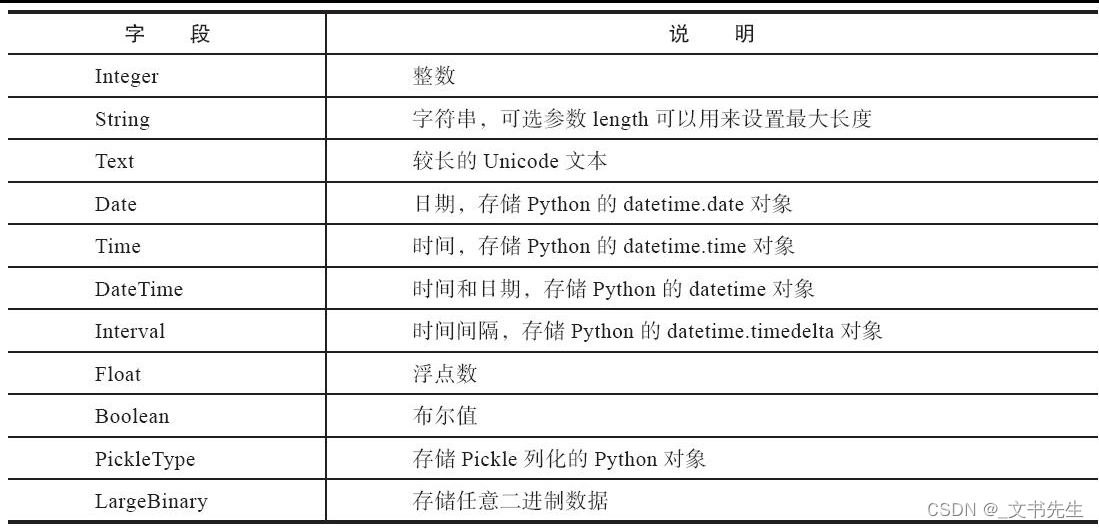
flask-sqlalchemy 会自动根据类名创建表明, 如果想要创建自定义的表名, 可以通过 __tablename__ 属性来实现.
常用的SQLAlchemy字段参数:
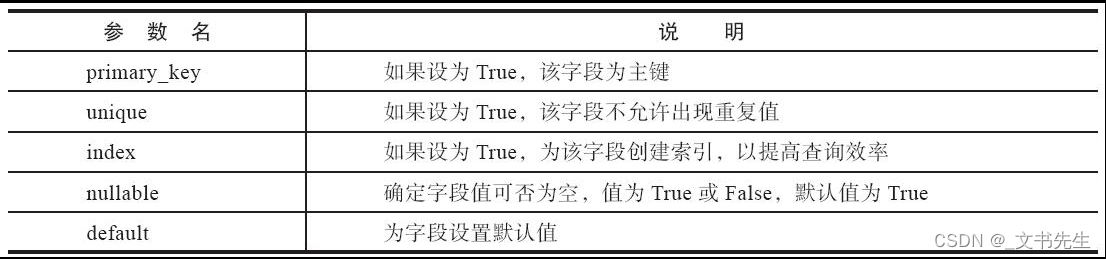
数据库迁移:
xxx
数据库操作:
Create:
添加一条新记录到数据库主要分为三步:
1)创建Python对象(实例化模型类)作为一条记录。
2)添加新创建的记录到数据库会话。
3)提交数据库会话。
>>> from app import db, Note
>>> note1 = Note(body='remember Sammy Jankis')
>>> note2 = Note(body='SHAVE')
>>> note3 = Note(body='DON\'T BELIEVE HIS LIES, HE IS THE ONE, KILL HIM')
>>> db.session.add(note1)
>>> db.session.add(note2)
>>> db.session.add(note3)
>>> db.session.commit()我们首先从app模块导入db对象和Note类,然后分别创建三个Note实例表示三条记录,使用关键字参数传入字段数据。我们的Note类继承自db.Model基类,db.Model基类会为Note类提供一个构造函数,接收匹配类属性名称的参数值,并赋值给对应的类属性,所以我们不需要自己在Note类中定义构造方法。接着我们调用add()方法把这三个Note对象添加到会话对象db.session中,最后调用commit()方法提交会话.
除了依次调用 add() 方法添加多个记录,也可以使用 add_all() 一次添加包含所有记录对象的列表。
SQLAlchemy提供了一个SQLALCHEMY_COMMIT_ON_TEARDOWN配置变量,将其设为True可以设置自动调用commit()方法提交数据库会话.
Read:
使用模型类提供的query属性附加调用各种过滤方法及查询方法可以完成查询操作
<模型类>.query.<过滤方法>.<查询方法>使用某个模型类, 通过query属性对应的Query对象上附加的过滤方法和查询函数对模型类对应的表中的记录进行各种筛选和调整,最终返回包含对应数据库记录数据的模型类实例,对返回的实例调用属性即可获取对应的字段数据。

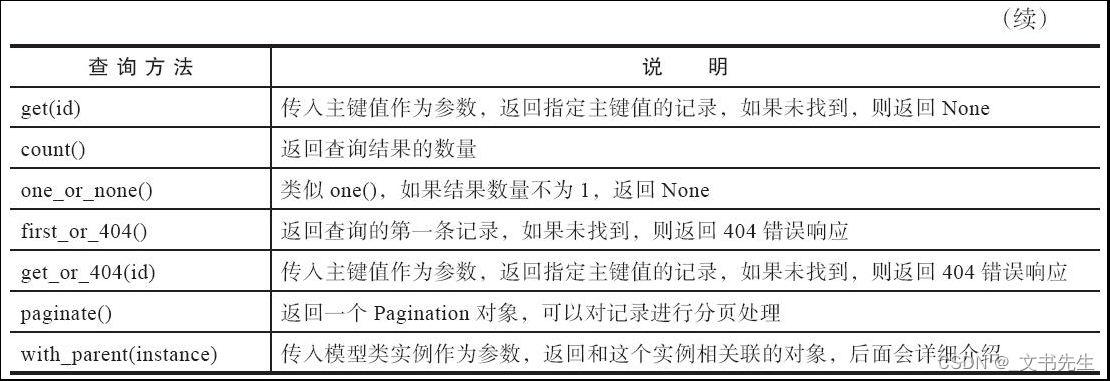
all():
查询所有

first():
查询返回第一条记录

get():
返回指定主键值(id字段)的结果

count():
返回记录的数据数量

条件过滤:
SQLAlchemy还提供了许多过滤方法,使用这些过滤方法可以获取更精确的查询,比如获取指定字段值的记录。对模型类的query属性存储的Query对象调用过滤方法将返回一个更精确的Query对象(后面我们简称为查询对象)。因为每个过滤方法都会返回新的查询对象,所以过滤器可以叠加使用。在查询对象上调用前面介绍的查询方法,即可获得一个包含过滤后的记录的列表。
完整的查询方法和过滤方法列表在http://docs.sqlalchemy.org/en/latest/orm/query.html

filter()方法是最基础的查询方法。它使用指定的规则来过滤记录,下面的示例在数据库里找出了body字段值为“I love python”的记录:

直接打印查询对象或将其转换为字符串可以查看对应的SQL语句

在filter()方法中传入表达式时,除了“==”以及表示不等于的“!=”,其他常用的查询操作符以及使用示例如下所示:
LIKE:
IN:

NOT IN:

AND:
# 使用and_()
from sqlalchemy import and_
filter(and_(Note.body == 'foo', Note.title == 'FooBar'))
# 或在filter()中加入多个表达式,使用逗号分隔
filter(Note.body == 'foo', Note.title == 'FooBar')
# 或叠加调用多个filter()/filter_by()方法
filter(Note.body == 'foo').filter(Note.title == 'FooBar')OR:
from sqlalchemy import or_
filter(or_(Note.body == 'foo', Note.body == 'bar'))完整的可用操作符列表可以访问
http://docs.sqlalchemy.org/en/latest/core/sqlelement.html#sqlalchemy.sql.operators.ColumnOperators
和filter()方法相比,filter_by()方法更易于使用。在filter_by()方法中,你可以使用关键字表达式来指定过滤规则。更方便的是,你可以在这个过滤器中直接使用字段名称。

Update:
更新一条记录非常简单,直接赋值给模型类的字段属性就可以改变字段值,然后调用commit()方法提交会话即可。
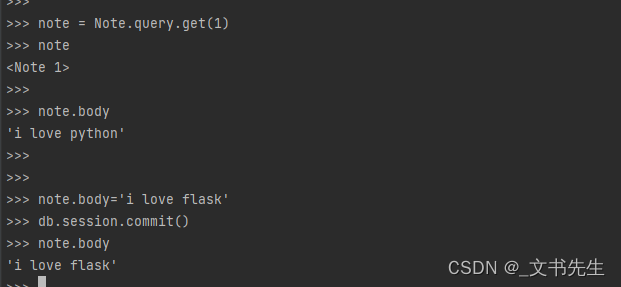
只有要插入新的记录或要将现有的记录添加到会话中时才需要使用add()方法,单纯要更新现有的记录时只需要直接为属性赋新值,然后提交会话。
Delete:
删除记录和添加记录很相似,不过要把add()方法换成delete()方法,最后都需要调用commit()方法提交修改。

创建关系:
一对多:
定义外键:
将以作者和文章来演示一对多关系:一个作者可以写作多篇文章。
定义关系的第一步是创建外键。外键是(foreign key)用来在A表存储B表的主键值以便和B表建立联系的关系字段。因为外键只能存储单一数据(标量),所以外键总是在“多”这一侧定义,多篇文章属于同一个作者,所以我们需要为每篇文章添加外键存储作者的主键值以指向对应的作者。在Article模型中,我们定义一个author_id字段作为外键:
class Author(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(70), unique=True)
phone = db.Column(db.String(20))
class Article(db.Model):
id = db.Column(db.Integer, primary_key=True)
title = db.Column(db.String(50), index=True)
body = db.Column(db.Text)
author_id = db.Column(db.Integer, db.ForeignKey('author.id'))定义关系属性:
可以在 一 的一方通过relationship() 函数来定义一个关系属性, 其目的就是通过这个属性来查看拥有多少文章
class Author(db.Model):
...
articles = db.relationship('Article', backref='author', lazy=True)
















 1351
1351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











