









目录
内存对齐
概念
内存对齐是指数据在内存中存储时相对于起始地址的偏移量是数据大小的整数倍。
(该篇文章主要针对结构体的大小的计算,也就是结构体内的内存对齐)
重点:
① 内存中存储的数据都要求内存对齐,不单单只针对结构体而言。
② 对齐的参考点是,起始地址(就是每次对齐计算时的起点)。
对齐规则
- 第一个成员在与结构体变量偏移量为0的地址处。
- 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
对齐数 = 编译器默认的一个对齐数 与 该成员大小的较小值。
Visaul Studio编译器默认的值为8 - 结构体总大小为最大对齐数(每个成员变量都有一个对齐数,其中最大的对齐数)的整数倍。
- 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
接下来,针对这四条对齐规则一 一理解:
1. 第一个成员在与结构体变量偏移量为0的地址处。
结合以下结构体:
#include <stdio.h>
struct A
{
int a1; // int类型 - 4个字节
char a2; // char类型 - 1个字节
double a3; // double类型 - 8个字节
};
int main()
{
A a; // 创建结构体变量a
return 0;
}
在程序中,我们定义了一个结构体A,并且在main函数中用创建了变量a,变量a的类型是结构体A。对于其中的内存管理以及对于该规则的解释,我们借助下面的图形讲解
(主要为理解服务,真实情况不会这么的捡漏)

我们假设,在整个程序中,编译器提供了黑色方框的内存,main函数所占用的内存空间是红色方框,而在main函数中创建的结构体变量a申请到的内存空间就是红色方框内的绿色方框。
思考一下?结构体内的成员变量是如何在绿色方框的空间里存储的呢?
答:结构体成员变量的存储顺序便是结构体内成员变量定义的顺序。第一个存储的就是结构体内第一个声明定义的变量,并且是存储在 结构体变量偏移量为0 的地址,也就是图中的标识“结构体变量a的起始地址”所指向的地方。
这个地方便是,结构体变量a一块空间中的起始地址,也就是该规则所说的 “第一个成员在与结构体变量偏移量为0的地址处”。
(绿色方框中一个个的小长方形。将一个小长方形理解定义为一个字节的空间大小)
注意:起始地址是后续所有变量对齐内存时的参照地址,可以理解为地平线、x轴中的原点…,比如在x轴中,正是因为有原点0的存在,我们才能知道我们走了1、2、3这些衡量数值。
下面介绍第二个规则。
2. 其他成员变量要对齐到,对齐数的整数倍的地址处。
问题一:什么是对齐数?
答:对齐数是指,要求数据在内存中的存储地址是某个值的整数倍。“ 某个值 ” 指的便是对齐数。
问题二:对齐数怎么获取,怎么知道一个类型的对齐数是多少?
答:对齐数 = 编译器默认的一个对齐数 与 该成员大小,两者中的较小值。
重点:
① 编译器默认的对齐数,不同的编译器默认的对齐数可能有所不同,这里使用的编译器Visaul Studio 2019 默认的对齐数是8;
② “ 该成员 ”的含义,指的是结构体中的成员变量。当结构体A中嵌套着结构体B,也就是结构体A中的成员变量存在着结构体B,则先算出结构体B的大小,再做比较(别问我结构体B怎么算,邦邦就是两拳头)。
经过前面两个问题,我们便可以得出该规则的含义了:
结构体中的第一个成员变量存储的地址是,结构体的起始地址,也就是偏移量为0的地址。
那其他的成员变量(依次),存储的规则便是,轮到哪个成员变量存储,则用该成员变量的大小 与 编译器默认的对齐数大小,两者做比较,取小的那个大小作为对齐数。
获取到了对齐数,则该变量存储的位置是以起始地址(地址偏移量为0)作为参考点,整数倍的对齐数的位置。如:
#include <stdio.h>
struct A
{
char a1; // char类型 - 1个字节
int a2; // int类型 - 4个字节
float a3; // float类型 - 4个字节
};
int main()
{
A a; // 创建结构体变量a
return 0;
}
我们在main函数中创建了结构体变量a,我们单独对于结构体内的空间进行分析,如下:

结构体成员变量a1是存储在偏移量为0的地址,接下来存储成员变量a2,a2的数据类型是int,大小为4个字节,比编译器默认的对齐数8要小。所以对于成员变量a2来说对齐数为4,因此成员变量a2内存存储要对齐的是4的整数倍, 0、4、8、12、… 、4n ,并且是以偏移量0作为参考值。
如图,0地址处已经被成员变量a1所占用,因此不能存储在地址0处。那下一处的存储地址是4,我们发现偏移量为4的地方是空地址,因此变量a2在偏移量为4的地方存储下来,连续占用四个字节的空间大小。
( 疑问:
在该例子中,发现1、2、3处的空间岂不是浪费了吗?没错!就是浪费了。为什么呢?
文章末尾进行解答。
)
重点:区分一个点,就是偏移量为0的起始地址,是作为变量存储的参考点。变量存储的时候还要注意,当利用对齐数的整数倍选定了存储的地址时,切勿后面已经存储了变量,也就是说不可以重新利用因为内存对齐所浪费掉的那些空间。 规则3的例子将会对这一注意事项有直观的阐述。
下面介绍第三个规则。
3. 结构体总大小为最大对齐数的整数倍。
问题:学习了前面的1、2规则,是不是就可以计算结构体的大小了呢?实践出真理,我们利用已知的1、2规则看看能不能正确的计算处结构体的大小。见如下程序:
#include <stdio.h>
struct A
{
char a1;
int a2;
char a3;
};
int main()
{
printf("%d\r\n", sizeof(A)); // 打印输出结构体A的大小
return 0;
}
现在,按照我们对前面1、2规则的认知,进行如下图的推断:

通过已知的规则,我们可以推断上图便是结构体A中成员变量存储的情况,结合图形来看,结构体A的大小应该是9个字节。那么结果是不是输出9呢?让我们运行程序
运行结果:
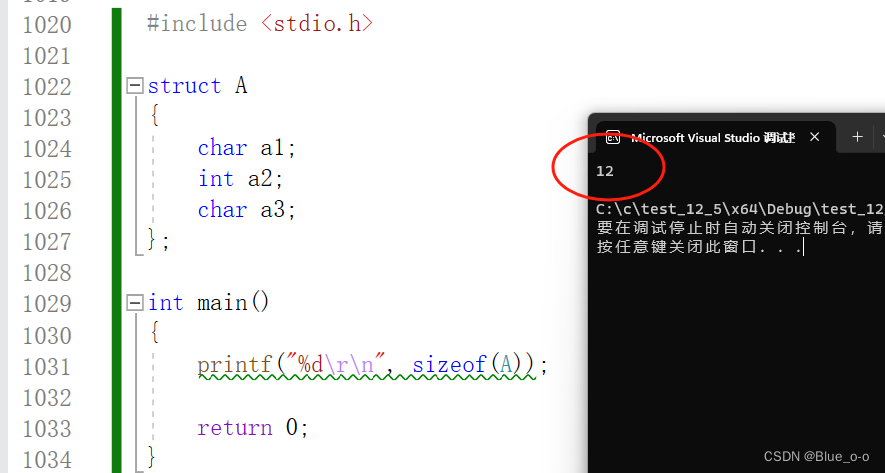
咦~我们神奇的发现,结构体A的大小输出结果是12个字节,而不是9个字节,这是怎么回事呢?
答案是:规则3的作用。
规则3:结构体总大小为(结构体中的)最大对齐数的整数倍。
其中,最大对齐数,指的是每个成员变量确定了自己的对齐数后,在所有的成员变量的对齐数中,最大的那一个对齐数。
如上面的例子,
成员变量a1的对齐数是1;
成员变量a2的对齐数是4;
成员变量a3的对齐数是1;
因此结构体当中最大的对齐数是,成员变量a2的对齐数4。
所以,虽然实际中,当存储好变量a3时,只占用了9个字节,但是9不是4的倍数,在9之后又是4的倍数是12。所以编译器会将变量a3后面的3个字节空间也纳入结构体的空间(也可以认为是浪费了三个字节的空间大小)。
最终答案是,结构体A的大小是12个字节。相信通过这个例子,能够很好的解释规则3的作用。
( 规则2后面的注意事项,指的是变量a3要注意的事项。我们已知a3对齐数为1,那岂不是随意存嘛!以偏移量0做参考点,那我存到1处的地址岂不是很好!××× 这不许这么个勤俭持家哦家人们,要明白当存储完变量a2时,1、2、3处的地址便‘ 浪费 ’了,不可以再使用了,在a2后还有变量要存储时,是以偏移量0为参考点,但是是要接在变量a2后面的地址进行存储,前面浪费的地址就不能再用了。
)
4. 如果结构体内嵌套了结构体的情况
通过前面规则1、2、3的学习,我们已经能够计算出成员变量都是内置类型的结构体的大小了。如果结构体内的成员变量中出现自定义类型,如另外的结构体呢?对齐数该如何取,空间大小这时又该如何计算?
见以下程序:
#include <stdio.h>
// 最大对齐数 4
// 结构体大小 12
struct A
{
char a1;
int a2;
char a3;
};
struct B
{
int b1;
A b2;
char b3;
};
int main()
{
B b;
printf("%d\r\n",sizeof(b)); // 输出打印结构提b的大小
return 0;
}
运行结果:
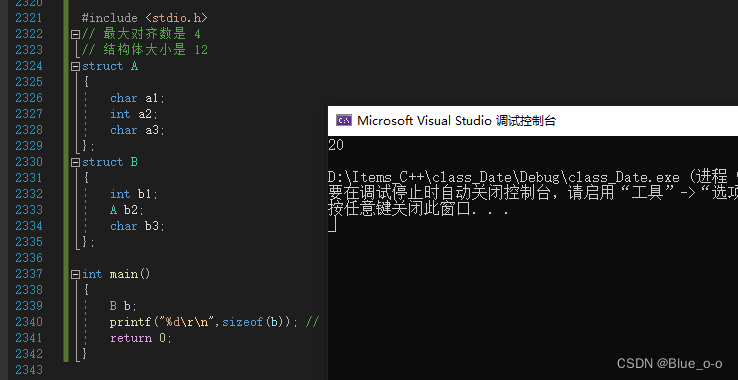
根据前面的学习,我们可以得知。在结构体B中,
成员变量b1的对齐数是4,并且从起始位置开始存储。
成员变量b2,是一个结构体A类型的变量。我们知道如果变量类型是内置型,那么该变量与对齐数作比较的大小便是内置型类型的大小。那么像b2这种是自定义类型的变量,与对齐数做比较的“ 大小 ”是多少,该如何选取呢?
规则4做出了规定:
如果嵌套了结构体的情况,嵌套的结构体对齐到 自己的最大对齐数 的整数倍处。
也就是说对于结构体b2选取的是自身的最大对齐数 作为与编译器默认对齐数比较的大小。通过前面的学习,我们能够清楚的知道结构体A的最大对齐数是 4个字节,比编译器默认对齐数8要小,所以对于变量b2而言,对齐数是4,存储的情况则遵循前面的规则。
如此,我们可以画出结构体B的内存分布:

成员变量b1存储在红色区域;
成员变量b2存储在绿色区域(注意地址偏移量);
成员变量b3存储在蓝色区域。
我们发现,实际上当变量b3存储完时,只用了17个字节的空间。
又根据规则3:
结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
在该例子中,结构体B内最大对齐数是4,是4的倍数又在17之后的,便是20了。
所以程序的输出结果是20个字节的空间大小。
至此,对于如何计算结构体的大小,其实就是内存对齐的本质的学习,完结!
练习题
下面是一些练习题,读者们可以根据以上所学的知识,试一试能不能算出来
练习一:计算结构体A的大小:
#include <stdio.h>
struct A
{
char a1;
char a2;
int a3;
};
int main()
{
A a;
printf("%d\r\n",sizeof(a)); // 输出打印结构提a的大小
return 0;
}
练习二:计算结构体B的大小
struct B
{
double b1;
char b2;
int b3;
};
int main()
{
B b;
printf("%d\r\n",sizeof(b)); // 输出打印结构提b的大小
return 0;
}
练习三:计算结构体C的大小
struct B
{
double b1;
char b2;
int b3;
};
struct C
{
char c1;
B c2;
double c3;
};
int main()
{
C c;
printf("%d\r\n",sizeof(c)); // 输出打印结构提c的大小
return 0;
}
结尾彩蛋:
为什么内存空间中的数据,一定要内存对齐,在有些情况下,不是白白浪费了很多地址空间吗?
答:
1、平台原因(移植原因):
对于有一些硬件的平台,是不能够访问任意地址上的任意数据的。比如有些硬件平台要求便是4个字节、4个字节的读取数据。这时如果内存存储中不按照4字节为对齐标准时,会导致数据读取混乱的问题。
2、性能原因
数据结构应该尽可能的在自然边界上对齐。原因在于,如果要读取未对齐的内存时,处理器需要作两次内存的访问(比如未对齐的内存,前部分存在内存块1,后部分存在内存块2,而处理器一次只能访问一个内存块)。而如果使用了内存对齐,处理器只需要访问一次就可以顺利读取到数据了。
总的来说:
数据的内存对齐就是拿空间来换取时间的做法,通过牺牲、浪费一些空间,来提高内存访问的性能,提高时间上的高效。切勿因为要省空间,而导致时间上的下降,因为随着技术的发展,硬件上的空间已经是很充足、很富裕的了。因此不要为了杜绝空间上的浪费,不遵从内存对齐的原则,导致数据读取混乱,违背了使程序执行的效率更高的初衷。















 394
394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









