









问题:
在visual studio 2019编译器中,我们创建了三个文件,分别是 test.cpp 、 a.cpp 和 a.h 。 三个文件内容如下:
a.h文件:
#pragma once
#include <iostream>
using namespace std;
void Func1();
template<class T>
void Func2(const T&x = T());
a.cpp文件:
#include "a.h"
void Func1()
{
cout << "Func1()" << endl;
}
template<class T>
void Func2(const T&x)
{
cout << "void Func2(const T&x)<<endl";
}
test.cpp文件:
#define _CRT_SECURE_NO_WARNINGS 1
#include "a.h"
int main()
{
Func1();
Func2(10);
return 0;
}
以下是框图:

当我们运行编译器时,编译器会报错,编译不通过。这是为什么呢?
具体原因是:链接错误。
为了了解并且解决这个问题,让我们从编译器编译时的四个阶段着手:
预处理(Preprocessing)
预处理阶段是编译过程的第一个阶段,其主要目的是在实际编译之前对源代码进行一些文本替换和处理。预处理器通常执行以下一些主要任务:
(
注意:
在预处理阶段,预处理器不会对普通变量进行求值。因此在下面的条件编译中条件表达式中,切勿出现变量或变量相关的表达式,要使用常量表达式或者宏定义,即一开始编译器便能确认的信息。
)
1、宏替代(Marco Replacement):
处理源代码中的宏定义。宏是一种预定义的代码片段,可以通过在代码中使用宏名称进行替换。预处理器会找到代码中的宏调用,并将其替换为相应的宏定义。如:下面代码
#define N 100
#include <iostream>
using namespace std;
int count = N;
// ...
int main()
{
int arr[N];
}
经过宏替代后:
#define N 100
#include <iostream>
using namespace std;
int count = 100;
// ...
int main()
{
int arr[100];
return 0;
}
预处理器会将程序中所有的N都替换成100。
(
需要留意,要留意宏定义后的效果是什么,比如这里上述例子中,常量值100被宏定义为N,即N是一个常量。那么就得注意常量的使用。其他的情况也一样,得要有个认知
)
2、文件包含(File Inclusion):
处理 #include 指令,将指定的头文件的内容插入到源代码中。这样,便可以将代码模块化并重用。也就是头文件的包含。如:
#include <iostream>
#include <string>
#include <vector>
int main()
{
return 0;
}
当在工程中,包含了指定的头文件时,目标头文件中的所有内容都将被展开。
注意:
当使用 #include 预处理指令 包含头文件时,预处理器会将指定头文件的内容插入到包含该指令的源文件中。这包括头文件中的所有文本。
3、条件编译(Conditional Compilation):
条件编译是一种在源代码中 选择性地 包含 或 排除 某些代码块的技术。这由预处理器通过处理 条件预处理指令 来实现。以下是条件编译的主要指令和它们的作用:
(
重点:
条件编译要求条件表达式必须是在编译时就能够确定结果的常量表达式
)
① #ifdef(If Defined)和 #ifndef(If Not Defined):
#ifdef :用于检查是否定义了指定的宏
#ifndef :用于检查是否没有定义指定的宏
#endif :标志条件编译块的结束。
如:
#ifdef HEAD // 开始
// 仅当HEAD宏定义时,才会包含这段代码(截止到#endif)
#endif // 截止
#ifndef HEAD // 开始
// 仅当HEAD没被宏定义时,才会包含这段代码(截止到#endif)
#endif // 截止
② #if,#elif,#else和#endif:
#if :允许根据一些表达式的值进行条件编译。
#elif(else if):用于添加额外的条件分支。
#else :用于在前面的条件不满足时执行的代码块。
#endif :标志条件编译块的结束。
如以下:
#if defined(ARCH_64)
// 64位架构的代码
#elif defined(ARCH_32)
// 32位架构的代码
#else
// 默认情况下的代码
#endif
#if
当编译器识别到环境是多少位时,便会去执行预处理满足条件的代码,而跳过不满足条件的代码。
③ #define和条件编译:
可以使用 #define 来定义宏,然后使用条件编译来根据宏的定义与否进行代码选择。
如程序中经常使用的:
#ifndef HEAD // 第一遍时没有定义宏,编译将包含以下代码
#define HEAD // 宏定义HEAD
// 头文件内容
#endif // 结束
这样,第一遍时,因为条件编译#ifndef,还没有宏定义HEAD,编译器便会包含截止到#endif之间的代码,而在这段代码中,我们又使用#define宏定义了HEAD,那么第二遍时,便不会再次包含从#ifndef 到 #endif 中的代码。当用户将头文件中的声明、定义等放到这中间时,便能有效的避免了头文件多次包含的问题。
④ #pragma指令:
#pragma指令可以用于向编译器发出特定的指令,有时也用于条件编译。
#pragma once
// 确保头文件只包含一次
#pragma GCC optimize("O2")
// GCC编译器优化级别设置
条件编译总结:
条件编译使得可以根据不同的编译选项、平台或宏定义选择性地包含或排除代码,这在程序编译时,大大减小了内存空间上的消耗,同时也提高了程序的效率。同时在处理跨平台开发、调试、测试等方面非常有用。
4、去注释(Comments Removal):
移除(删除)源代码中的注释。
如:
// 下面是一个主函数
int main()
{
// 今天吃什么?
return 0;
}
经过预处理器的去注释后:
int main()
{
return 0;
}
预处理器会移除这些注释,因为注释对编译器来说是无关紧要的。
一般着重了解以上四步即可,下面两个做了解
5、条件包含(Conditional Inclusion):
根据一些条件决定是否包含某些代码。
#define ARCH 64
#if (ARCH == 64)
// 64-bit specific code
#else
// 32-bit specific code
#endif
注意条件包含和条件编译两者的区别:
条件编译,是通过预处理器指令来决定是否编译特定部分的代码。
条件包含,是在源代码中根据条件选择性地包含不同的头文件或代码文件。
两者常常结合使用,以便根据不同的条件来选择性地包含特定的头文件或代码块。例如,使用条件编译来根据不同平台选择不同的宏定义,并在代码中使用这些宏来决定条件包含的头文件。这样可以确保在不同的情况下编译不同的代码模块。
6、其他预处理指令:
预处理器还支持其他一些指令,如#pragma,用于向编译器发出特定的指令。初级阶段可以不必过于纠结,着重了解预处理期间前面四个任务即可。
预处理阶段,总结:
通过以上的预处理步骤,编译器最终会生成一个经过处理的代码,该代码将被送入编译器进行实际的编译。这个经过预处理的代码通常被保存为一个中间文件,也就是后缀名为 .i 的文件。可以通过查看这个文件来了解预处理之后的代码。
(字母 i,是 Intermediate 英文的缩写,中文意思为:中间)
编译(Compilation)
编译阶段是编译过程的第二个阶段。该阶段的任务可笼统的概括为:①检查语法; ② 生成汇编代码。然而实际上,该阶段做的任务、细分的更多,总共划分为8个任务:
① 词法分析(Lexical Analysis):
词法分析器首先对源代码进行词法分析,将源代码分解为词法单元(tokens)。词法单元是程序中的基本语法单元,如关键字、标识符、常量、运算符等。
其中,
关键字 :C语言有32个、C++有64个;
标识符 :用来标识变量、函数、数组等程序实体的名称;
常量 :固定不变的值,在程序中不能被修改。主要分为三种类型:字面常量、符号常量、枚举常量。
运算符 :算术运算符、关系运算符、逻辑运算符、位运算符、赋值操作符、杂项运算符共六大类,使用时需要注意运算符之间的优先级问题。
② 语法分析(Syntax Analysis):
语法分析器将词法单元组织成语法结构,并构建抽象语法树(Abstract Syntax Tree,AST)。语法分析的任务是确保源代码符合编程语言的语法规则。
③ 语义分析(Semantic Analysis):
语义分析器对源代码进行分析,以确定程序的语义结构和语义( 语句和表达式 )的合法性、正确性。主要关注的是代码的含义和逻辑,而不仅仅是语法的正确性。具体的分析有:
<1> 类型检查(Type Checking)
<2> 标识符解析(Identifier Resolution)
<3> 语义规则验证(Semantic rules validation)
<4> 控制流分析(Control Flow Analysis)
<5> 控制流分析(Control Flow Analysis)
<6> 语义错误检测与报告(Semantic Error Detection And Reporting)
在这个过程中,编译器会获取源代码的语义信息,并将其转化为一种叫做中间表示形式的抽象表。完成语义分析后,编译器将得到完整的中间表示形式(Intermediate Representation)。
常见的中间表示形式有:
<1> 三地址码(Three-Address Code)
<2> 虚拟机代码(Virtual Machine Code)
<3> 抽象语法树(Abstract Syntax Tree)
<4> 控制流图(Control Flow Graph):
<5> SSA 形式(Static Single Assignment)等等。多种的形式意味着编译器在生成中间表示形式时,有一定的灵活性。通常由编译器的设计和实现决定,可以是选择其中的一种形式,也可以是将多种形式混合使用。根据不同的 优化 和 转换需求 选择最适合的中间表示形式,即不同的表示形式可能对于不同类型的优化更加有利。同时,混合使用不同形式的中间表示形式可以提供更灵活和强大的编译器功能,使编译器更有效地进行代码分析、优化和转换。
④ 中间代码生成(Intermediate Code Generation):
在这一阶段,编译器将源代码经过语义分析后的中间表示形式转化为具体的中间代码。
具体的中间代码是一种抽象的、介于源代码和目标代码之间的表示形式,它在语义上接近源代码,但更易于进行优化和转换。在中间代码生成阶段,编译器会执行以下任务:
<1> 表达式转换
<2> 控制流转换
<3> 变量和内存操作
<4> 函数调用和参数传递
<5> 中间代码优化
中间代码通常会去除源代码中一些高级语言特定的细节,但仍然保留了足够的信息,为接下来的优化阶段和目标代码生成阶段提供了基础。使得优化阶段更加容易,因为编译器不必处理高级语言的各种语法结构和语义,而是处理一种更底层、更容易优化的表示形式。总的来说,中间代码相对于高级源代码来说更接近底层语言,但相对于最终生成的机器代码来说,仍然有一些抽象。
注意:中间代码涵盖了中间表示形式中的代码内容。也就是说即便时生成的中间代码,里面依旧时中间表示形式中的代码。
中间代码和汇编代码的区别:
中间代码:
通常是一种更高级、与具体机器无关的代码表示形式,但并不直接对应于汇编代码。中间代码的目的是为了在不同目标平台上进行优化和生成机器代码。
中间代码是在中间表示形式基础上生成的,是一种抽象的、中间的表示形式。比源代码更底层,但比机器代码更高层。它提供了一种统一的表示形式,使得编译器可以进行各种优化和转换。
汇编代码:
是直接对应于特定机器的低级指令集的表示形式。它是中间代码经过进一步转换和生成的结果,是可以在具体的目标平台上执行的代码形式。汇编代码与具体的处理器架构和指令集相关联,它是一种较为底层的、直接与硬件交互的表示形式。
因此,中间代码与汇编代码并不是等价的。中间代码是在中间表示形式基础上生成的一种更高级的抽象表示。而汇编代码是针对具体目标平台的低级指令集的表示形式。是在中间代码生成阶段之后,经过优化阶段,最终在目标代码生成阶段翻译生成与目标平台相关的汇编代码。
⑤ 优化(Optimization):
在这个阶段,编译器通常有许多不同类型的优化技术被应用于对中间代码进行优化,以改进程序的性能、执行速度、资源利用等方面。常见的编辑优化技术有:
<1> 常量折叠(Constant Folding)
<2> 公共子表达式消除(Common Subexpression Elimination)
<3> 循环优化(Loop Optimization)
<4> 数据流分析与优化(Data Flow Analysis and Optimization)
<5> 指令调度(Instruction Scheduling)
<6> 内联展开(Inline Expansion)
<7> 寄存器分配与优化(Register Allocation and Optimization)
<8> 代码块重排(Code Motion)
<9> 减少内存访问次数(Memory Access Optimization)
<10> 向量化(Vectorization)
以上是一部分常见的编译优化技术,实际上,编译器的优化功能是非常复杂和多样化的。编译器根据程序的特性和目标架构来选择适合的优化技术,并在保证程序正确性的前提下,尽可能地提升程序的性能,旨在生成更有效率的目标代码。
⑥ 目标代码生成(Code Generation):
编译器将中间代码翻译、转换为目标汇编代码。在这个阶段,编译器将中间表示形式(如抽象语法树或三地址码)翻译成汇编代码,这是一种人类可读的低级表示形式。生成的汇编代码包含了与目标体系结构相关的汇编语言指令以及对应的符号(如变量名、函数名等)。这个阶段的输出通常是汇编代码的文本文件,例如使用类似于 x86 汇编、ARM 汇编等语法的文本。最终,这个汇编代码可以通过汇编器进行处理,将其转换为机器码或可执行文件,以供计算机硬件直接执行。
具体的目标代码生成阶段可能涉及的主要任务和步骤为:
<1> 指令选择(Instruction Selection)
<2> 寄存器分配(Register Allocation)
<3> 代码布局(Code Placement)
<4> 栈帧布局(Stack Frame Layout)
<5> 数据与指令的修饰(Data and Instruction Transformation)
总之,目标代码生成阶段主要是将中间代码翻译为目标平台的机器代码或汇编代码。它包括指令选择、寄存器分配、代码布局、栈帧布局和数据与指令的修饰等步骤,以便生成适用于目标平台的可执行代码。具体生成的内容取决于目标平台的架构和指令集。
⑦ 目标代码优化(Code Optimization):
在这个阶段,编译器对生成的汇编代码进行优化,旨在改善程序的性能、执行速度或者减少其占用的资源。这些优化可能包括减少代码长度、提高代码执行速度、消除冗余计算等。目标代码优化旨在使生成的机器码更为高效,以更好地利用底层硬件资源。这个阶段并非必需,但通常会被包括在编译器的流程中,以提高最终程序的质量。
常见的目标代码优化技术:
<1> 代码重排(Code Reordering)
<2> 寄存器分配优化(Register Allocation Optimization)
<3> 常量传播与折叠(Constant Propagation and Folding)
<4> 循环优化(Loop Optimization)
<5> 数据流分析与优化(Data Flow Analysis and Optimization)
<6> 函数内联(Function Inlining)
<7> 分支预测优化(Branch Prediction Optimization)
<8> 存储器访问优化(Memory Access Optimization)
注意:前面第⑤对生成的中间代码的优化也涉及了一个优化步骤,内联展开。跟此处目标代码优化涉及的一个步骤,函数内联,是什么关系、有什么区别?
答:内联展开和函数内联在中间代码和目标代码生成优化中的目标和原理是相似的。它们都是通过将函数调用处替换为函数体的内容,以减少函数调用开销和提高代码效率。两者的关系是函数内联是目标代码优化的一部分,而内联展开是中间代码优化的一部分。它们在不同的阶段针对不同层次的代码进行优化,但优化的目标和原理是相似的。
⑧ 符号解析(Symbol Resolution):
在这个阶段,编译器将处理程序中出现的符号,这些符号可以是变量、函数、类等标识符。这个阶段的目标是将这些符号解析为具体的内存地址或者其他可执行目标,以便在后续阶段正确地生成最终的可执行文件。具体解析为:
<1> 变量解析
<2> 函数解析
<3> 类和对象解析
<4> 模板和库解析
<5> 命名空间解析
编译器通过解析程序中的符号引用,确保它们都被正确地解析为内存地址或其他合适的信息。
符号解析是链接过程的一部分,用于解决符号与实际内存地址或目标代码之间的关联。这确保了最终生成的可执行文件中的所有符号都能够正确地被识别和访问。
编译阶段,总结:
以上8个任务一起构成了编译器的编译阶段。最终生成 .s 的汇编文件。总体来说,编译阶段的目标是将高级语言代码翻译成底层语言的形式,并进行各种优化,以便生成高效的可执行文件。也就是生成常说的汇编代码文件。
(字母 s,是 单词Assembling 的缩写,中文意思为 :汇编)
汇编(Assembly)
汇编阶段是编译过程的第三个阶段。该阶段的任务可笼统的概括为:将汇编代码转成二进制的机械码。然而实际上,该阶段由汇编器(Assembler Work) 执行汇编任务、具体细分以下几个主要步骤:
① 词法分析(Lexical Analysis)
在这一步骤中,汇编器会扫描汇编代码,并将其分解为一系列词法单元,例如指令、操作数、寄存器名、标签等。通过词法分析,汇编器能够创建一个有序的词法单元流,为后续的语法分析做准备。
② 语法分析(Syntax Analysis)
在语法分析阶段,汇编器会根据汇编语言的语法规则对词法单元流进行解析。它会验证语法是否正确,并构建语法树(Syntax Tree)或其他内部数据结构来表示汇编代码的结构和层次关系。
③ 符号解析和地址解析(Symbol Resolution and Addressing)
汇编器解析指令中使用的符号(如标签、变量名等),并将其映射到正确的内存地址或值。这涉及到符号表的维护和查询,在符号解析和地址解析过程中,汇编器会解决标签的跳转和调用等问题。
④ 机器指令生成(Code Generation)
在机器指令生成阶段,汇编器根据语法分析得到的语法树或其他数据结构,将每个汇编指令转换为适当的二进制表示形式,即二进制机械码。它会根据所使用的目标机器和指令集架构,生成与之对应的机器码指令序列。
注意:
伪操作处理是在这一步骤中进行的。
伪操作(Pseudoinstructions)是一种在汇编语言中使用的特殊指令或语法结构,它们并不是真正的机器指令,而是在汇编阶段被转换为一系列真正的机器指令。
伪操作的作用在于提供方便的语法结构或简化汇编代码的方式,使程序员能够更容易地定义数据和符号、进行内存操作等。它们可以在汇编源代码中使用,但在生成的最终机器码中,伪操作会被转换为真正的机器指令。
⑤ 错误检查和报告(Error Checking and Reporting)
汇编器会进行错误检查,识别可能存在的语法错误、语义错误、不支持的指令等。如果发现错误,汇编器会生成错误消息,并指示错误发生的位置,以便开发人员可以进行修正。
错误检查和报告阶段通常会关注:
<1> 语法错误
<2> 符号错误
<3> 类型错误
<4> 跳转和分支错误
<5> 使用未支持的指令
<6> 冲突和重复错误
<7> 格式错误
总结:
通过这些步骤,汇编器将高级语言表示的汇编代码转化为底层的二进制机器码,以供计算机硬件执行。最终生成 .o 的目标文件。
(字母 o ,是单词 Object 的缩写,中文意思是: 目标)
链接(Linking)
将多个目标文件(Object Files)和库文件(Library Files)合并成一个可执行文件(Executable File)或共享库文件(Shared Library)。链接器(Linker)负责执行这个过程,它将目标文件之间的引用关系解决并创建最终的可执行文件。
主要任务和步骤:
① 符号解析(Symbol Resolution)
链接器会解析所有目标文件中的符号(变量、函数或类)引用,找到它们的定义。这包括解决目标文件中的内部符号(只在同一目标文件内可见)和外部符号(在多个目标文件间共享的符号)。
② 符号重定位(Symbol Relocation)
由于目标文件中的代码和数据可能是在不同内存位置上定义的,链接器需要对引用的符号进行重定位。它会根据目标文件的内存映像将引用的符号的地址调整到正确的位置。
③ 段合并(Segment Merging)
目标文件中通常被分割成不同的段(如代码段、数据段、BSS段等)。链接器将这些段合并为一个连续的内存布局,并为它们分配正确的内存地址。
④ 符号表生成(Symbol Table Generation)
链接器会生成一个符号表,其中包含所有符号的地址信息。这个符号表对于调试和动态链接等操作是非常重要的。
⑤ 库文件链接(Library Linking)
如果目标文件引用了外部库文件中的符号,链接器会查找库文件,并将其与目标文件进行链接。这可以是静态库链接(将库文件的代码和数据拷贝到可执行文件中)或动态库链接(在运行时链接到共享库)。
⑥ 强弱符号解析(Strong and Weak Symbol Resolution)
在链接阶段,如果多个目标文件中有相同名称的符号,链接器需要解决它们之间的冲突。根据符号的属性(强符号或弱符号),链接器将选择具有最高优先级的符号作为最终定义。
⑦ 调整入口点(Adjusting Entry Points)
对于可执行文件,链接器将调整程序的入口点,使其指向正确的起始地址,以便正确执行程序。
最终,链接器生成一个完整的可执行文件,通常称为可执行程序(Executable Program)或可执行文件(Executable File)。这样的文件包含了已经经过编译、链接和标准格式化处理的二进制机器代码,它可以在操作系统上直接运行。
不同的操作系统和文件系统下,具有不同的文件后缀名:
Windows系统:.exe(例如:myprogram.exe)
macOS系统 :无后缀名或者 .app(例如:myprogram,或者 MyProgram.app)
Linux系统 :无后缀名(例如:myprogram)
除了可执行文件,还需要了解一个文件,共享库文件的含义:
共享库文件,通常被称为动态链接库(Dynamic Link Library,DLL)或共享对象文件(Shared Object File,SO)。共享库文件包含编译后的可重用代码和数据,多个可执行程序可以共享这些库文件,以减少内存占用和代码冗余。
共享库文件的文件后缀名也会因操作系统和文件系统的不同而有所变化。一些常见的共享库文件后缀名包括:
Windows系统:.dll(例如:mylib.dll)
macOS系统 :.dylib(例如:mylib.dylib)
Linux系统 :.so(例如:libmylib.so)
需要注意的是,这些文件后缀名仅是约定和惯例,并非强制性要求。实际上,文件后缀并不影响文件的内容和使用,操作系统会通过其他方式确定文件是否是可执行文件或共享库文件。
至此,对于编译的四个阶段的学习到此结束,回到文章中起初的问题之前,有必要先了解一下符号表这一组成部分。
符号表(Symbol Table)通常包含了程序中定义的所有符号(如变量、函数、类等)及其对应的地址或其他相关信息。这些符号在程序的编译过程(这里的过程包括预处理之后的三个阶段,而不仅仅是第二个阶段的编译,要注意)中产生,但并不是所有的符号都会在最终的可执行文件中保留。符号表的目的之一是链接阶段进行符号解析,将符号引用与符号定义关联起来。
在编译过程中,生成汇编代码和机械码的同时,编译器还会维护符号表。符号表中的条目包括函数、变量等标识符的名称以及相应的地址或其他信息。只有被实际使用的符号才会在最终的可执行文件中保留。
总体而言,符号表的生命周期贯穿整个编译过程,从源代码的词法分析开始,一直到生成最终的可执行文件。符号表记录了程序中定义的符号及其相关信息,但只有实际被使用的符号才会在最终的可执行文件中留存。这有助于减小程序的大小和提高执行效率。符号表的设计和管理是编译器中一个关键的组成部分,对于正确解析和生成目标代码至关重要。
注意1:
在预处理阶段,编译器并不会构建符号表,因为预处理阶段主要关注代码的文本处理,不涉及符号的语义和类型信息。
在第二阶段的编译阶段,编译器开始对词法分析时,才构建、创建了相应的符号表。即符号表的生命周期是从编译开始后的编译阶段开始,到生成最终的可执行文件终止的。
注意2:
在最终生成可执行文件时,符号表通常由多张符号表组成,其中包括每个源文件各自的局部符号表以及一个全局符号表。
每个源文件在编译阶段会构建一个局部符号表,用于记录该源文件中定义的局部符号,如变量、函数等。局部符号表通常只包含该源文件内部的符号及其相关信息。
同时,编译器还会维护一个全局符号表,用于记录全局范围内的符号和其相关信息,如全局变量、全局函数等。全局符号表中的符号可以在整个程序中被访问和使用。
当编译器生成目标文件时,每个源文件的局部符号表会被编译器合并到目标文件中的符号表部分。这样,在链接阶段时,链接器会使用目标文件中的符号表以及其他被链接的目标文件的符号表,最终生成一个包含所有符号的全局符号表。
这样的设计使得在链接阶段能够进行符号解析、符号重定位和符号的访问控制等操作,并确保编译后的可执行文件能够正确地引用和使用所有的符号。
总结起来,在最终生成可执行文件时,通常会存在多张符号表,包括每个源文件的局部符号表和一个全局符号表。局部符号表用于记录每个源文件内部的符号,全局符号表用于记录全局范围内的符号。这些符号表在链接阶段会进行合并,最终生成包含所有符号的全局符号表。
答案
了解了前面的知识后,让我们接着来探寻文章起初的问题的答案。
我们在VS编译器中,从创建了3个文件,分别是test.cpp 、 a.cpp 、a.h ,其中有两个为.cpp源文件。编译的时候,编译器报错不通过了。这个错误其实属于链接错误,即在编译的四个阶段之一的链接阶段出了错误。我们根据前面的知识,追朔其报错的根源。
首先,我们要认识到,在默认情况下,Visual Studio(VS)会使用并行编译来加快整体编译速度,这意味着它会尝试同时编译多个不相互依赖的源文件。这可以通过使用多个编译线程来实现,并行编译可以更充分地利用多核处理器的能力,从而加快编译速度。
即,test.cpp 文件和 a.cpp文件是同时被编译的,是独立自主的!既如此,我们先对test.cpp源文件进行粗略大概的分析:
(
重点 :符号表会在第二阶段开始记录符号信息。
)
test.cpp 源文件编译分析
在test.cpp文件中,
#define _CRT_SECURE_NO_WARNINGS 1
#include "a.h"
int main()
{
F1();
F2(10);
return 0;
}
第一阶段
第一阶段,预处理后结果为:
( 头文件就不展开了)
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream> // 该头文件也应该要展开,但是为了方便就不展开了
using namespace std; // 同理,就不展开了
void Func1();
template<class T>
void Func2(const T&x = T());
int main()
{
Func1();
Func2(10);
return 0;
}
即头文件的内容会在头文件所在的位置被包含到test.cpp源文件。
第二阶段
第二阶段,编译:
编译器会检查是否有语法上的错误。在上面代码上,声明了两个函数,一个普通函数Func1(),另一个是模板函数Func2()。在main函数中,分别调用了声明的两个函数。在语法上,并没有任何问题!
检查语法上没有问题后,生成汇编代码,进入下一阶段。
(在编译检查语法时:声明表示有这么个东西的存在,但是这个东西具体有没有实现、定义,在这一阶段并不关心)
第三阶段
第三阶段,汇编:
由汇编器将汇编代码转换为CPU/机械能读懂的二进制机械码。然后接着进入下一阶段。
第四阶段
第四阶段,链接:
在这一阶段中,编译器会在全局的符号表中,寻找对应的、需要的信息,如地址等。
在前面调用的两个函数中,我们只有函数的声明,但是并没有具体函数的实现、定义。即没有函数实现所在的地址,那么编译器便会通过对应的函数名符号,在全局的符号表中查找,找到的话就将首地址匹配、配置到自己的地址栏中。
我们发现,普通函数Func1()找到了定义的地址,但是模板函数Func2()并没有找到,这是怎么回事呢?让我们先对a.app源文件进行编译分析。
a.cpp 源文件编译分析
在a.cpp文件中,
#include "a.h"
// 普通函数Func1函数定义
void Func1()
{
cout<<"Func1()"<<endl;
}
// 模板函数Func2 ”定义“
template<class T>
void Func2(const T& x)
{
cout<<"void Func2(const T&x)"<<endl;
}
第一阶段
第一阶段,预处理后结果为:
( 头文件就不展开了)
#include <iostream> // 该头文件也应该要展开,但是为了方便就不展开了
using namespace std; // 同理,就不展开了
void Func1();
template<class T>
void Func2(const T& x = T());
void Func1()
{
cout<<"Func1()"<<endl;
}
// 模板函数Func2 ”定义“
template<class T>
void Func2(const T& x)
{
cout<<"void Func2(const T&x)"<<endl;
}
即头文件的内容会在头文件所在的位置被包含到a.cpp源文件。
( <iostream>被包含了两次怎么不会发生头文件多次包含的错误?那是因为头文件一般都做了处理,只会被编译一次,当第二次编译时头文件会被忽略,具体看预处理中的条件编译)
第二阶段
第二阶段,编译:
编译器会检查是否有语法上的错误。在上面代码上,声明了两个函数,一个普通函数Func1(),另一个是模板函数Func2()。
然后接着定义了普通函数Func1()的代码,即普通函数Func1实现了,并且有了分配的一块连续地址。
而模板函数Func2(),因为不知道模板参数T的类型( 没有实例化 ),因此并没有像Func1()函数实现一说,可以理解为:
template<class T>
void Func2(const T& x)
{
cout<<"void Func2(const T&x)"<<endl;
}
这一段代码依旧只是声明,编译器并没有分配地址给它。但是!
在语法上,并没有任何问题!
检查语法上没有问题后,生成汇编代码,进入下一阶段。
第三阶段
第三阶段,汇编:
由汇编器将汇编代码转换为CPU/机械能读懂的二进制机械码。然后接着进入下一阶段。
第四阶段
第四阶段,链接:
在这一阶段中,编译器会在全局的符号表中,寻找对应的、需要的信息,如地址等。
问题来了!
在test.cpp源文件中,
Func1()函数,通过全局的符号表,知道了Func1()函数在a.cpp源文件中定义,因此便到a.cpp源文件的符号表中中,找到Func1函数定义申请的到连续空间中的第一个地址,然后返回,将地址存起来和符号匹对。如下图:
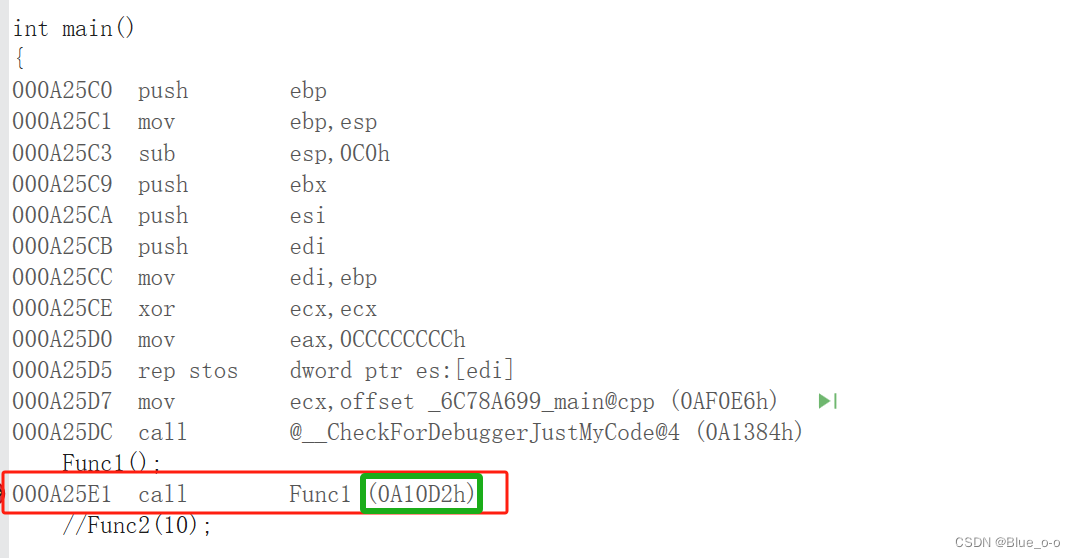
地址0x0A10D2h便是a.cpp源文件中,函数Func1()连续地址的第一个地址。
所以,main函数中对于第一个函数Func1()的链接是没有问题的,那么问题就是出现在第二个函数FUnc2()的链接问题上,为什么会链接错误呢?
在a.cpp源文件中,
前面分析过,在a.cpp源文件中,因为函数模板Func2()中的模板参数T没有接收到任何类型,因此编译器不会对该函数模板分配任何地址,只是声明,但是没有定义。因此在a.cpp源文件的符号表中,并没有Func2()函数的地址。
肯定有小伙伴跟我一样,在这里有一个疑问?在test.cpp源文件main函数中,Func2(10),调用时不是传入了整形10了吗?怎么会没有参数啊?
这就要注意前面重点提醒过的,编译器对于不同的源文件是并行编译的,各个源文件中是同时进行编译、互不干扰、具有独立性的。
因此,在test.cpp源文件中,main函数中调用模板函数Func2(10),传入的整形10。其实是被test.cpp源文件中的函数模板声明接收到了。也就是说,在test.cpp源文件的模板函数声明中模板参数T是接收到了整形int的数据。但是它只是一个声明,并不是定义。
而在a.cpp源文件中,函数模板Func2() “定义” 的地方,却没有接收到外界传进来的模板参数(独立性、独立性、独立性),也就是没有实例化,因此也就没有定义,分配地址。
所以main函数中Func2函数在符号表中,没有找到Func2函数所需要的地址。所以在最终将目标文件整合在一起,要生成可执行文件前,便发生了 链接错误,编译器报错不通过。
至此,便解决了一链接报错的问题,(模板类也是同样的道理)
既然我们发现了问题,那么要如何针对这一问题,解决了呢?
两个方法:
解决方法1:在a.cpp源文件中对模板函数进行显示实例化定义:
template<class T>
void Func2(const T&x)
{
cout << "void Func2(const T&x)<<endl";
}
// 模板显式实例化
template<>
void Func2<int>(const int& x)
{
cout << "void Func2(const T&x)<<endl";
}
但是这个方法不常用,因为调用不同的参数时,得分别显式实例化对应的参数类型,代码过于冗余,与使用模板的初衷相违背。
解决方法2:暴力解决,就是不要分离编译,模板放到.h文件中
a.h文件:
#pragma once
#include <iostream>
using namespace std;
// 函数声明
void Func1();
// 模板声明
template<class T>
void Func2(const T&x = T());
// 函数定义
void Func2<int>(const T&x)
{
cout << "void Func2(const T&x)<<endl";
}
// 函数“定义”
template<class T>
void Func2(const T&x)
{
cout << "void Func2(const T&x)<<endl";
}
补充一点:
函数模板的符号表问题:
对于函数模板而言,如果它被实例化并在程序中被使用,那么相关的符号信息会被记录在符号表中。否则,如果函数模板没有被使用,编译器会根据优化策略将未被使用的代码删除,并在符号表中移出相应的条目。所以如果一个函数模板没被实例化,那么符号表从始至终都不会有该函数模板的信息。
完结。















 2239
2239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









