






1.关于anaconda和pycharm的安装这里就不在赘述了,站内有很多大佬都做了如何安装这一步,直接到官网下载即可。
2.到GitHub上下载yolov7的压缩包和权重文件,链接如下。(如果实在打不开github的官网,可以找一下有个台湾的官网,我之前试了一次,可以进去,只是有点慢。)
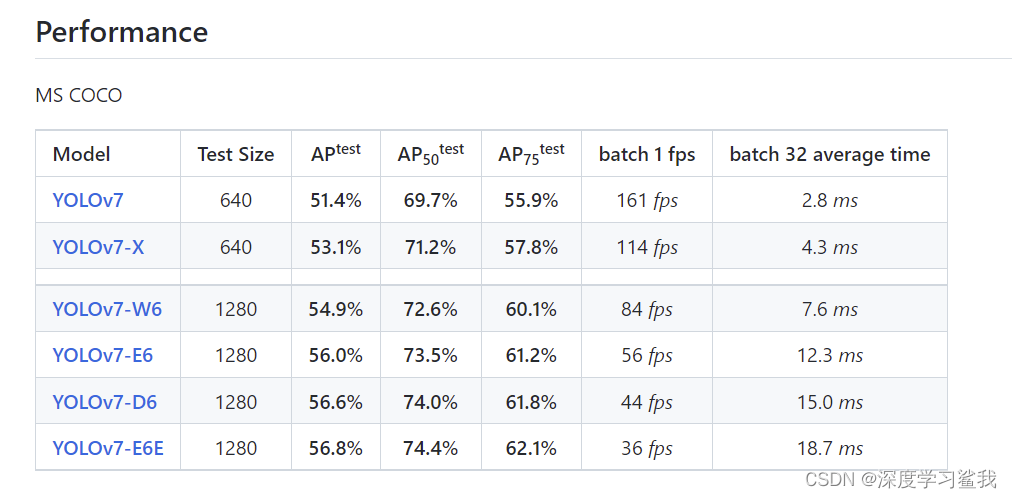
在这里下载预训练权重,建议下载yolov7那一个,当然,如果你的电脑是3090ti或者有好几张显卡,那当我没说,大佬请随意。 下载完yolov7的压缩包以后,建议解压到d盘里,yolov7随便一个模型跑出来存的权重文件都5个多g,放在c盘怕是分分钟爆炸。
3.yolov7的包解压以后,就用pycharm打开,第一次搞深度学习的同学,不建议用cmd打开,因为要根据自己的电脑配置修改很多的参数等等,本来就是要用pycharm打开的,就不要来回切换了。(之前跑yolov5的时候出现过用cmd打开就能跑,用pycharm打开就不能跑的情况,不知道咋回事,可能是环境配置冲突了吧。)总之,打开以后如下图。
4.环境配置
仔细阅读这个readme(估计你也不太乐意读,不然也不会来看教程了),打开以后,首先就是要配环境,这里需要注意的是,使用cpu跑的同学和使用gpu跑的同学环境配置是不一样的,这里首先说使用cpu的环境配置,我的环境是python3.9.12和pytorch 1.12.0。
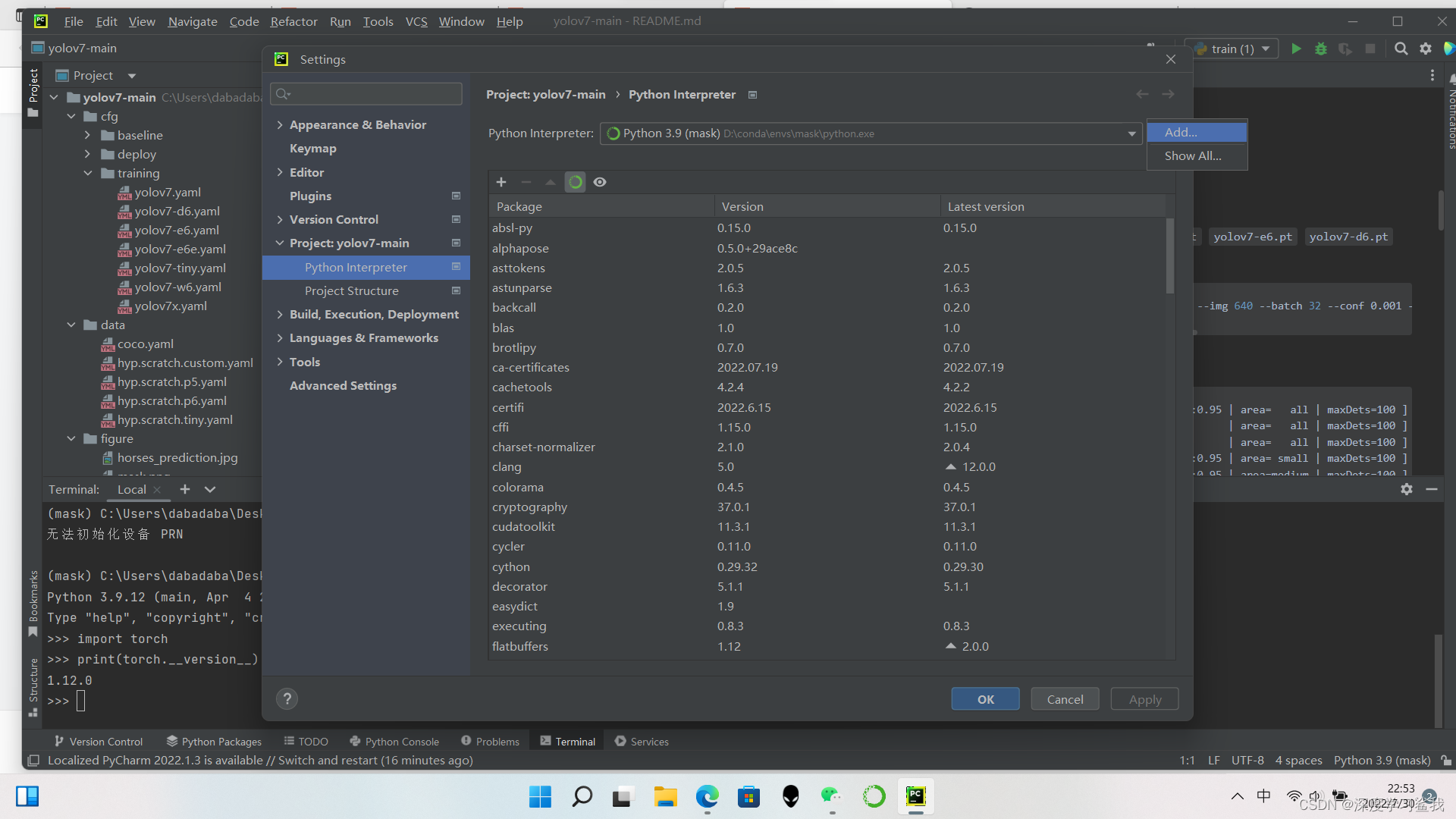
点击右下角那个python interpreter,然后点击interpreter setting,就会进入到这个上图这个界面,然后点击旁边那个齿轮,就会出现add,在这里添加环境。
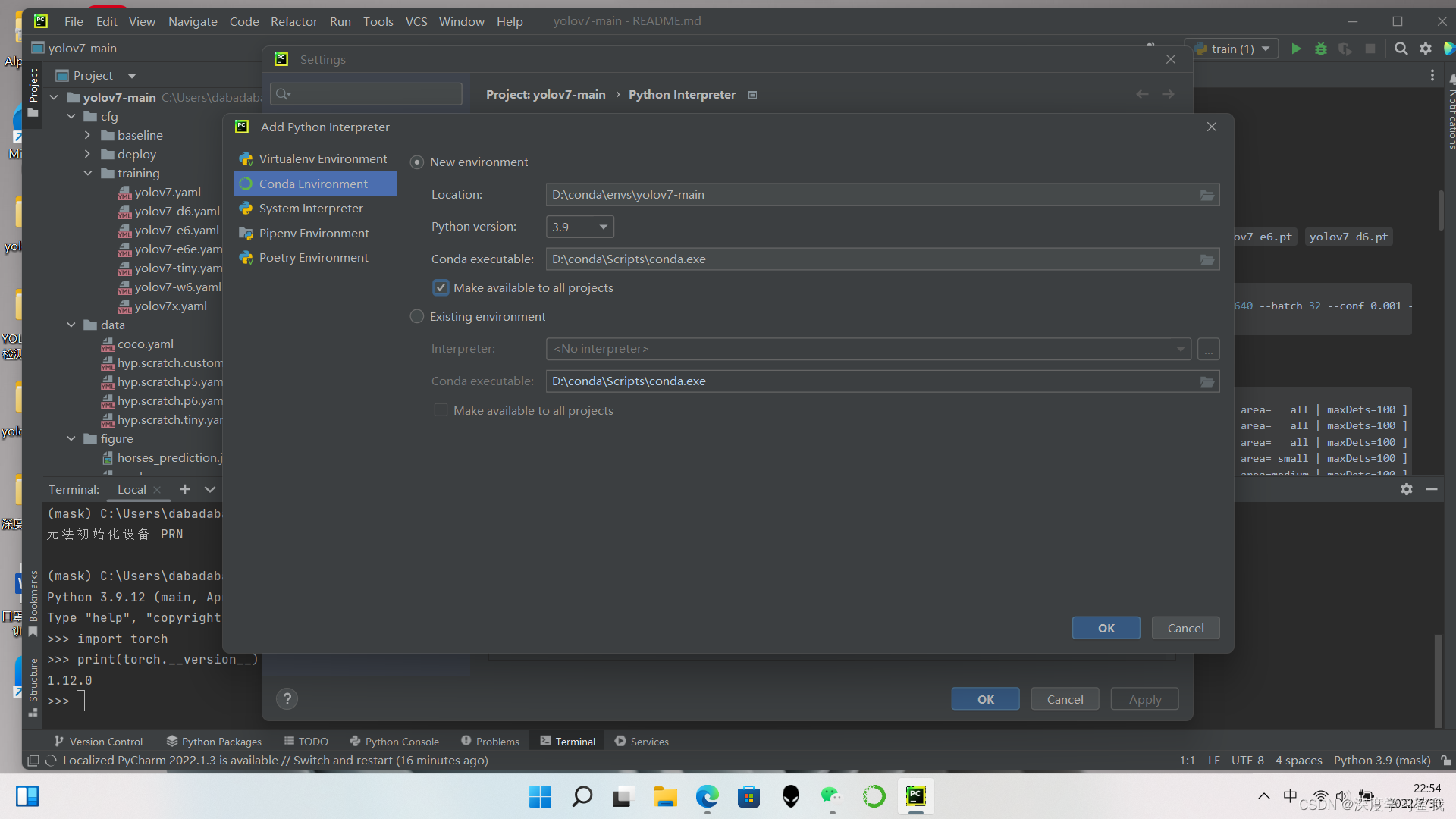
在这里选择conda environment 然后选择python的版本,这个make available to all projects建议勾上,就是让这个环境能在所有项目上用,大部分的目标检测的环境都大差不差的,我都是用的一个环境,直接大杂烩。
环境配置完成以后,就要安装pytorch了,链接如下。
一个问题是,大部分的博主在做教程的时候会教你们如何把下载源切换成清华源或者是中科大源,但是我之前在配环境的时候,根本就不知道这俩源啥时候会出问题,导致在下载依赖包的时候会莫名其妙的报错,所以,如果网速够快,且有耐心的同学,建议直接在官网下,别换源,当然,你要换的话,代码如下。
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
# 设置搜索时显示通道地址
conda config --set show_channel_urls yes
————————————————
这是清华源。
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/msys2/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/bioconda/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/menpo/
# 设置搜索时显示通道地址
conda config --set show_channel_urls yes
这是中科大的源,如果不想用了,可以用下面的代码切换为官方源。
conda config --remove-key channels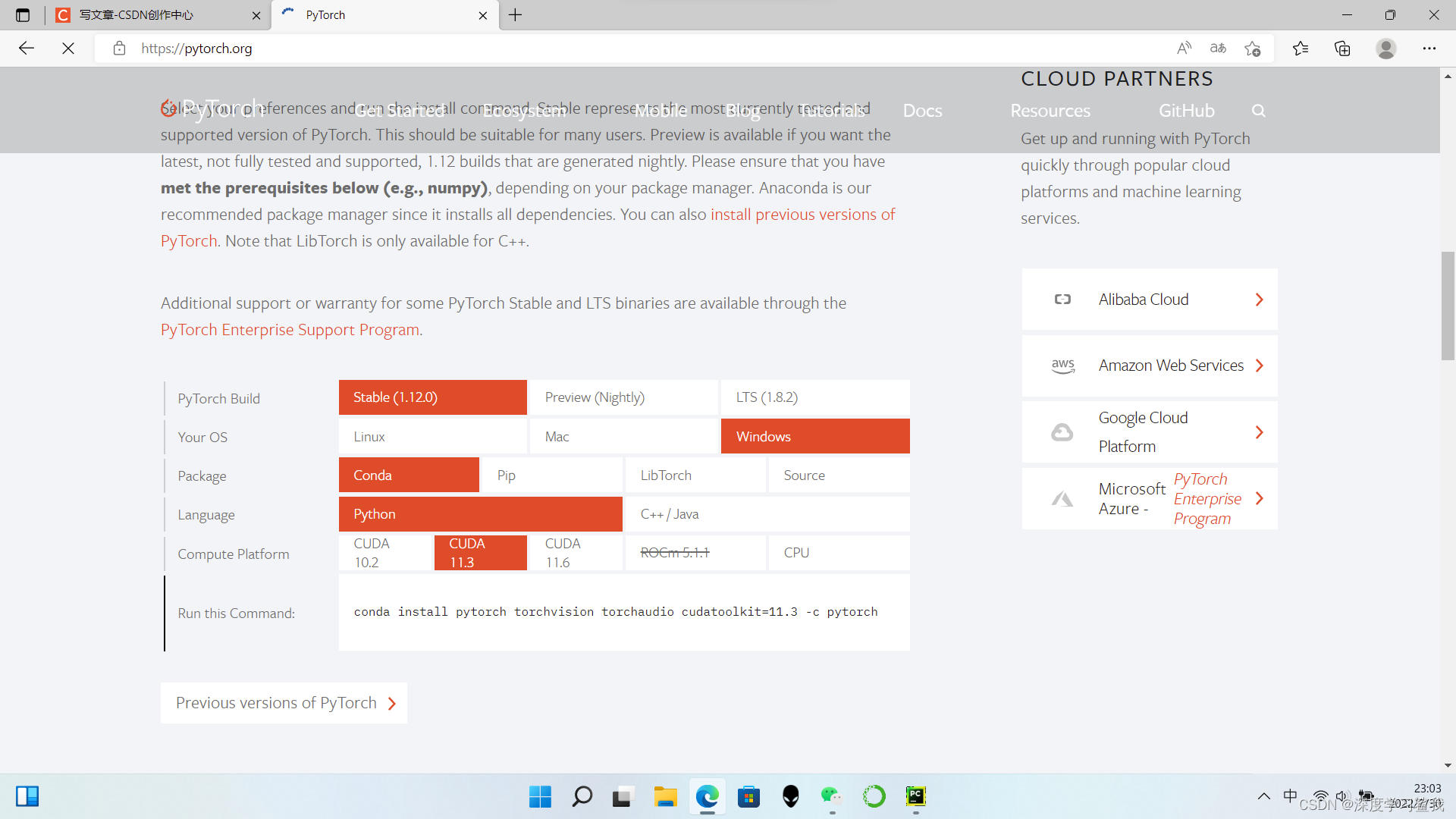
在这里选好你要下载的版本以后,直接复制run this command中的代码即可,如果要使用国内的源下载的话,后面的那个-c pytorch就不要复制,就复制前面的就可以了。这里需要注意的是,我使用的平台是conda,所以我选择了conda的package,如果你用的是其他的,请选择你对应的包,最后,有个compute platform,如果你是30系的显卡,建议选择cuda11.3,因为版本太高了cudnn怕是配不上,20系及其一下的,建议选择cuda10.2,如果没有显卡,就选择cpu。
环境配置完毕以后,输入以下代码,如果有输出,就会告诉你,你的python版本和pytorch版本什么,如果没有输出,则说明安装不成功,建议换成官方的源再下一遍。
python
import torch
print(torch.__version__)使用cpu的同学,环境的搭建就结束了,但是使用gpu的同学,才刚刚开始。
首先,你需要查看自己的显卡的版本,型号等,在桌面直接打开英伟达控制面板,就可以看到。
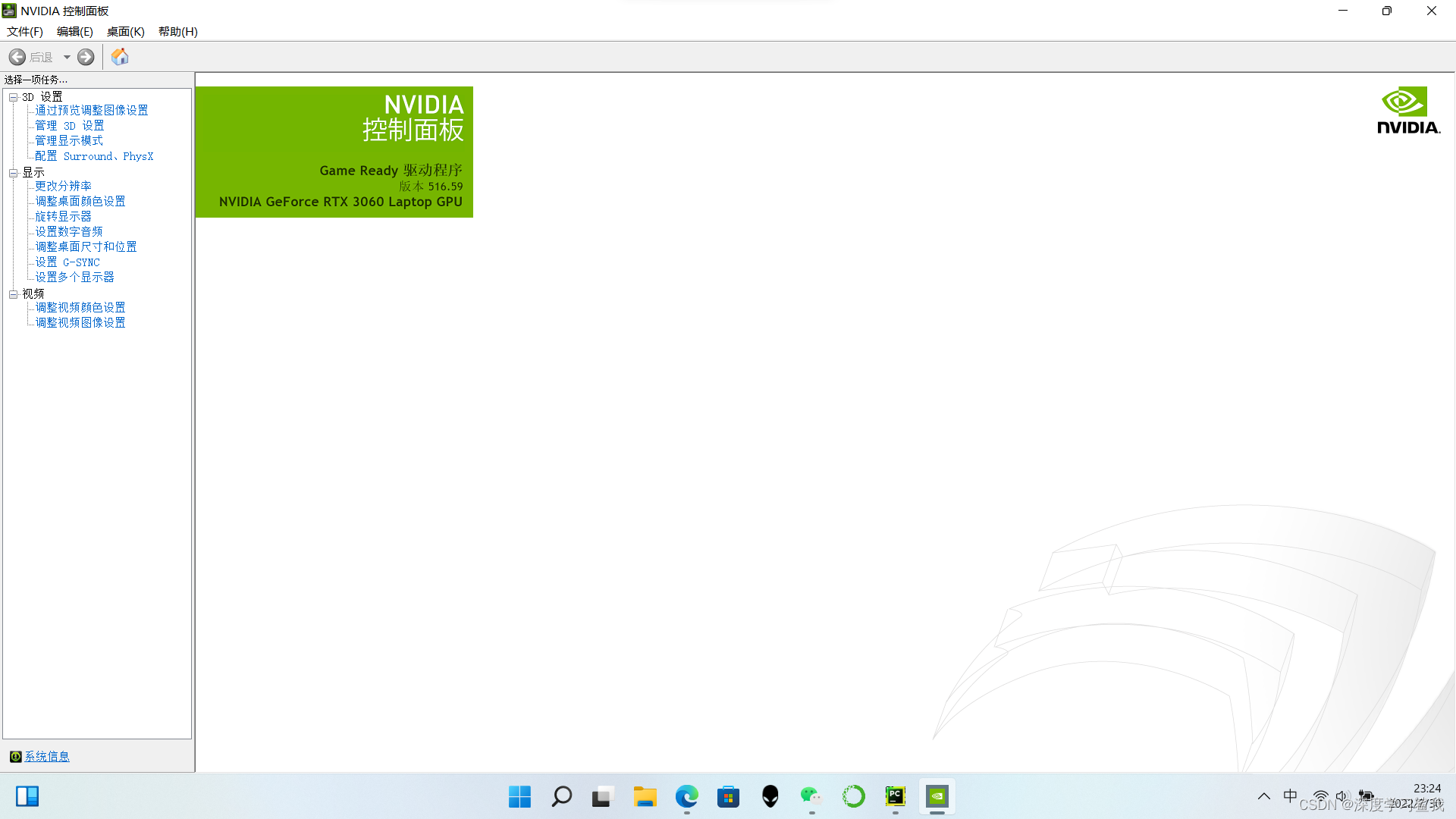
比如我的是rtx3060,版本号是516.69,暂时不清楚其他的显卡驱动有没有更新,但是3060的在6月28号更新了一波,还是建议大家到英伟达的官网更新一下自己的驱动,英伟达官网链接如下。
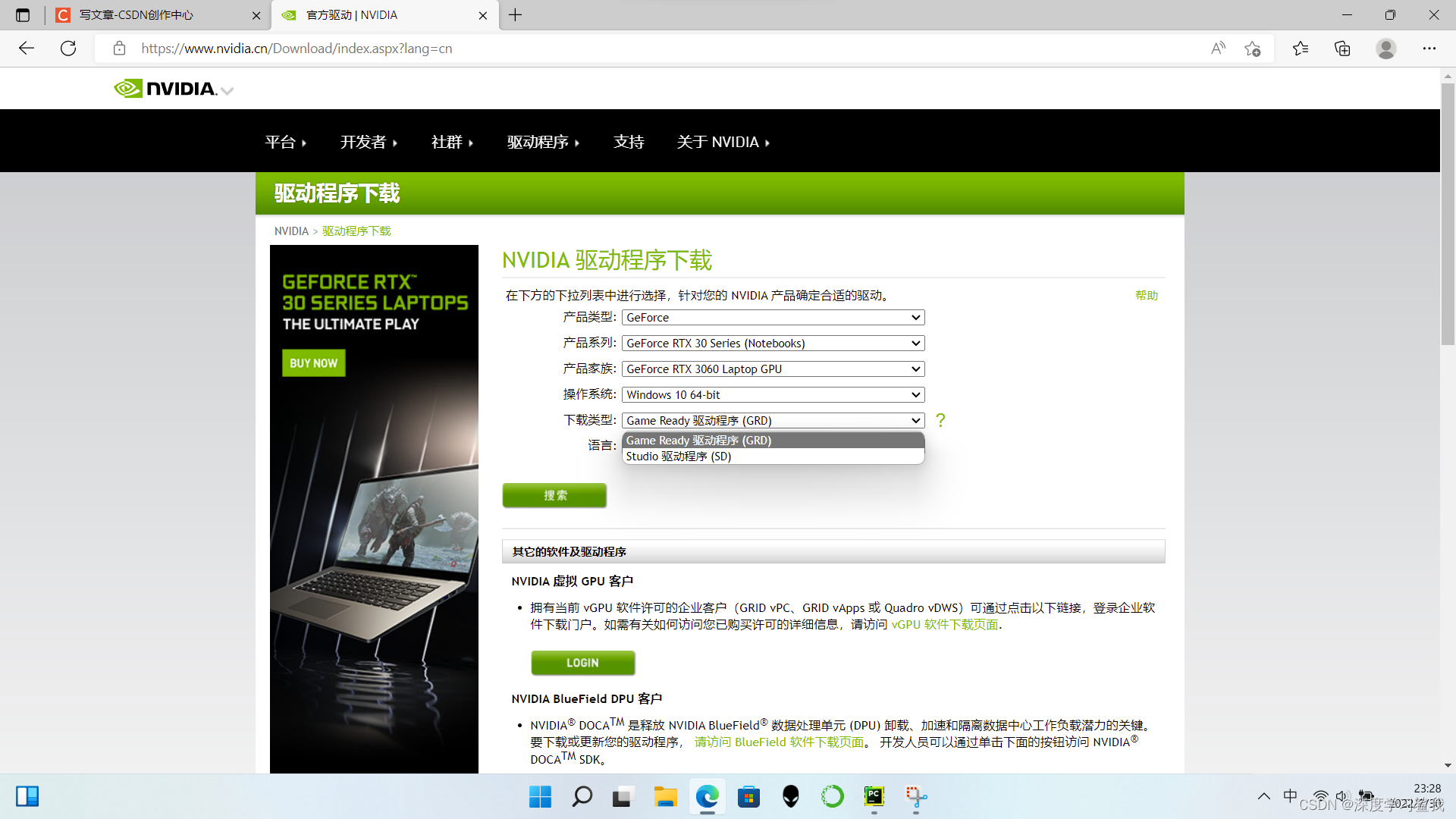
这里大家选择自己的显卡型号即可,这个下载类型有两个,就下那个game ready即可,学习之余还可以打一打csgo放松一下自己。下载下来以后,直接安装,然后他会提示你要重启电脑,重启就完事儿了,重启电脑以后,会像第一次开机一样,重新设置这那的,别怕,不是系统崩了,只是显卡驱动重装了而已。
驱动更新了以后,就需要下载cuda和cudnn了,这个是比较麻烦的一步,因为cuda和cudnn还有tensorflow的版本要一一对应起来才跑得动,这个版本对应比较麻烦,我的配置是cuda11.5.0+cudnn8.3.2+tensorflow2.6.1,如果你的配置跟我一样,win11+i712700h+gtx3060,可以参考我的cuda配置,如果不是,你也可以在cudnn的下载页面上找到与cudnn搭配的cuda版本(当然,小白是指定看不懂的),所以建议你直接在站内搜,大佬早就给你配好了。下面是cuda和cudnn的下载链接。
CUDA Toolkit Archive | NVIDIA Developer
cuDNN Archive | NVIDIA Developer
cuda下载完毕以后,先不要着急安装,因为cuda的开发平台会涉及到c++等,所以,你还需要下一个visual studio,下面是下载链接。
Visual Studio: 面向软件开发人员和 Teams 的 IDE 和代码编辑器 (microsoft.com)
下载完毕以后,会有如下界面。
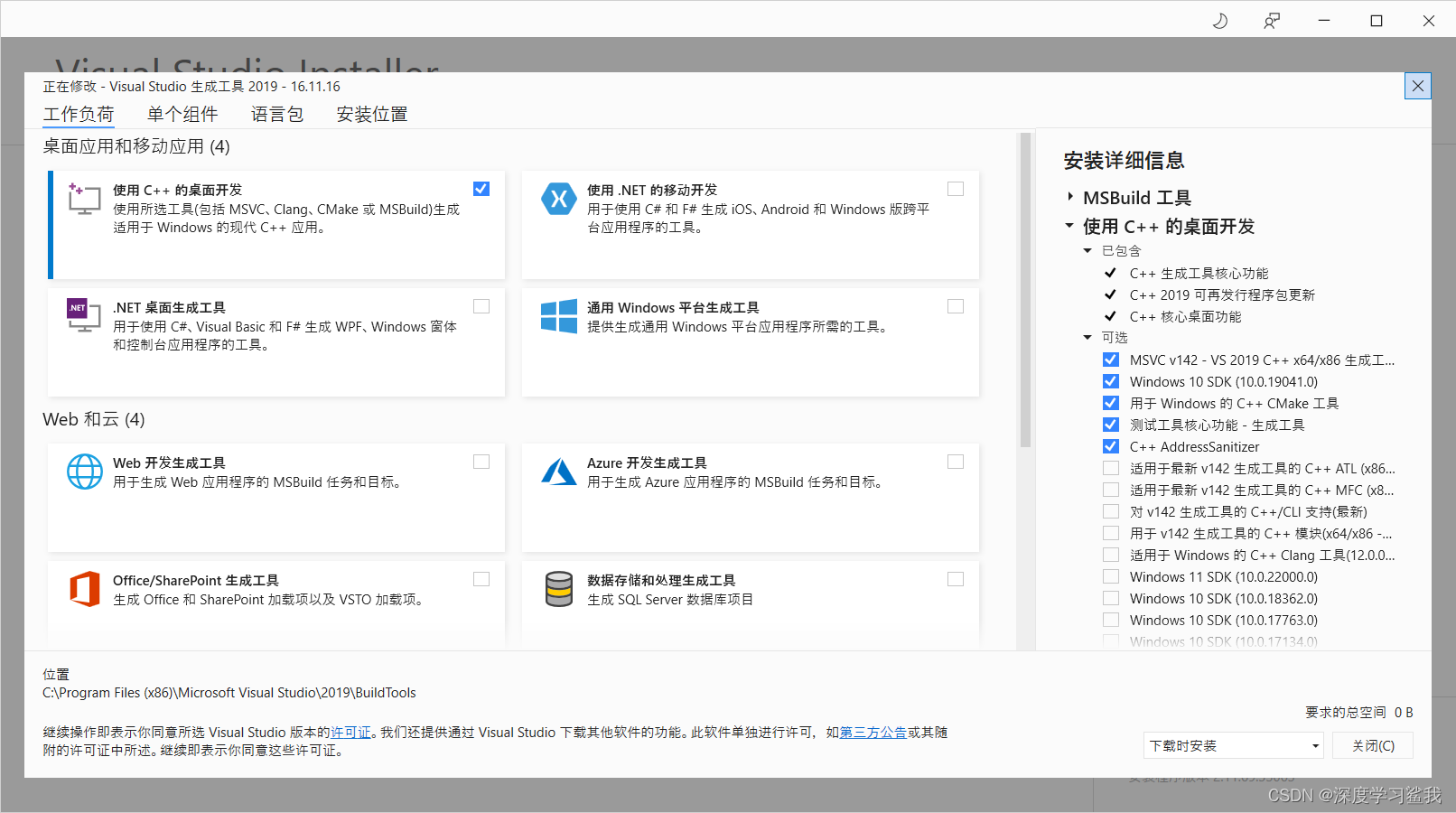
这个c++的桌面开发如果全部下完还是挺大的,但是我们用不着,所以把前五个勾上即可,其他的都不用管 。
然后再开始安装cuda,直接点击安装,然后一路next就可以了,第一次安装会下载一些依赖包啥的,让他下就完事儿了。
cudnn的下载稍微有点麻烦,要注册个账号,还要加入啥开发者计划这那的,跟着点就行了,cudnn下载完以后,是一个文件夹,如下图。
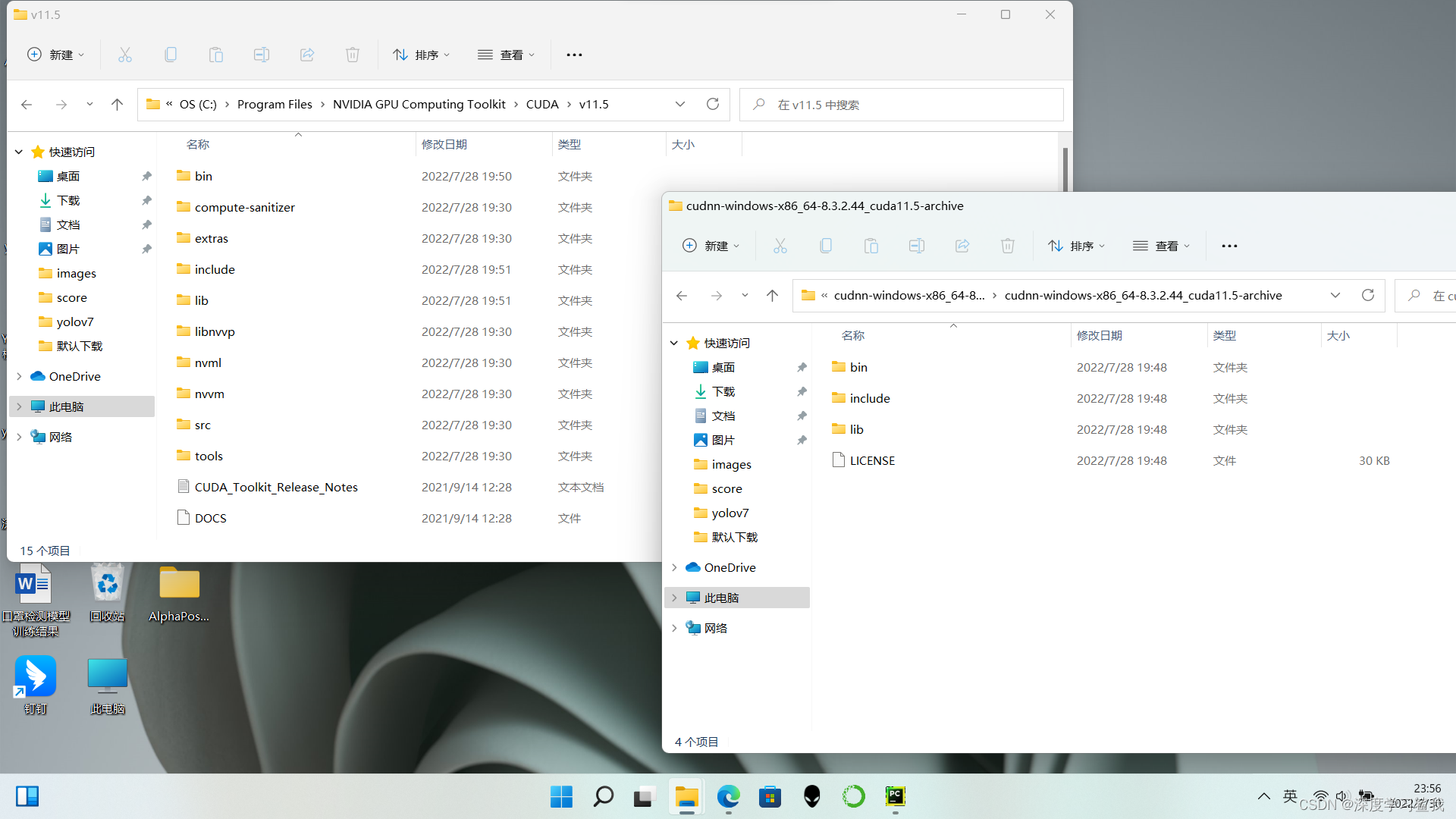
在cudnn里面,有3个文件夹,分别是bin,include和lib,打开c盘,在 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5这个路径下能找到跟他相同的三个文件夹,然后,把cudnn里的这三个文件夹里面的东西分别复制到对应的cuda的文件夹里面,然后重启电脑。
到这里,cuda和cudnn就算是安装完成了。
下一步,安装tensorflow。你在安装cudnn的时候,就能看到你要下载的cudnn所支持的tensorflow是什么版本的,比如我的配置对应的版本是tensorflow2.6.2,所以直接在terminal下输入以下代码
pip install tensorflow-gpu==2.6.2到这里,使用gpu的同学环境也算是搭建完成了。最后,输入以下代码来测试自己的cuda,cudnn和tensorflow是否安装完成。
python
import tensorflow as tf
tf.reduce_sum(tf.random.normal([1000, 1000]))
version = tf.version
gpu_ok = tf.test.is_gpu_available()
print(“tf version:”,version,"\nuse GPU",gpu_ok)如果有输出,就是安装完成,如果报错,那就是安装有问题。然后把那个报错复制到百度里,看看大佬都是怎么解决的,俺也不会。
5.安装依赖包
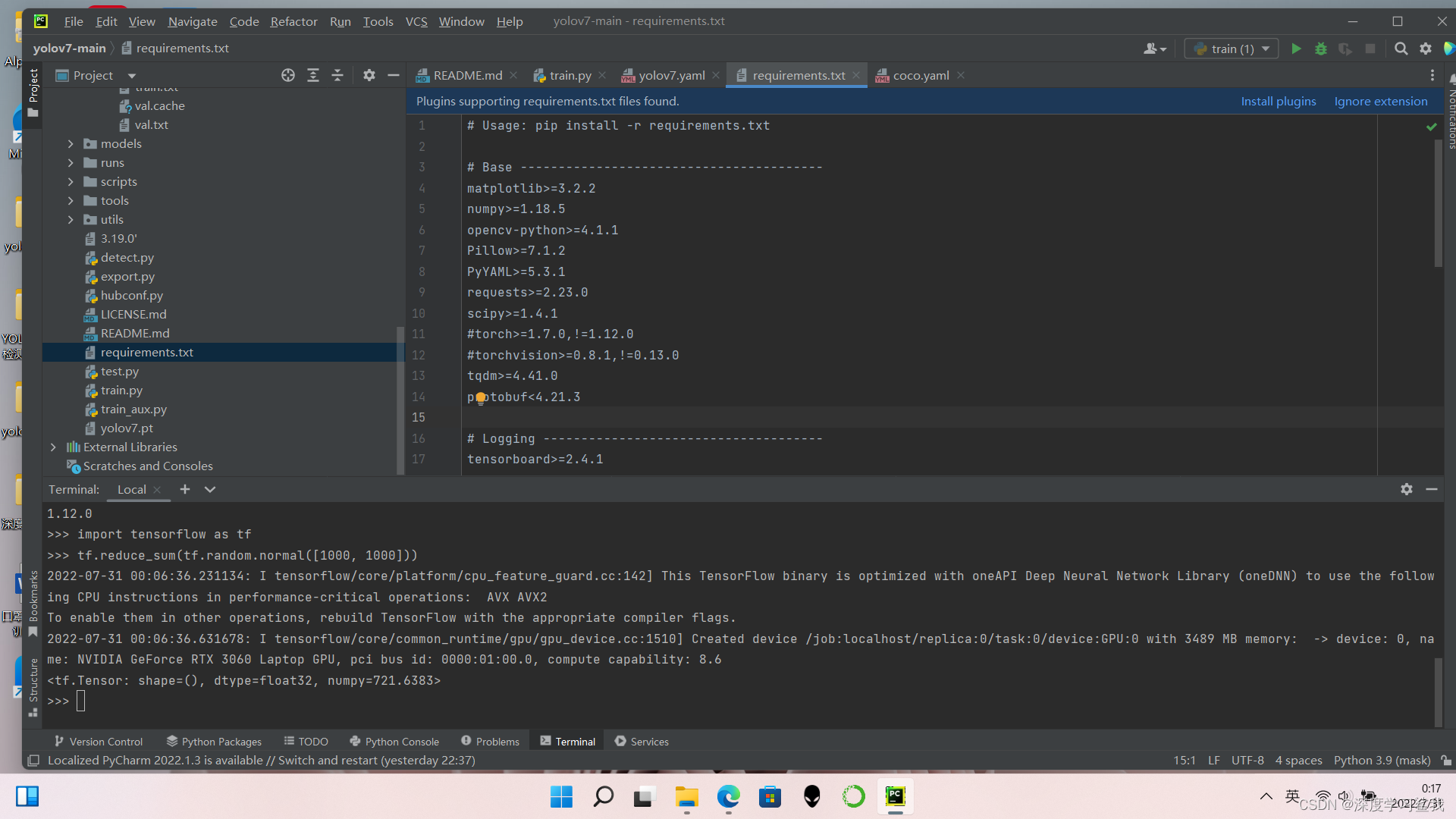
在文件列表里找到requirements.txt这个文本文件,里面都是要下载的依赖包,打开这个文件以后,大家会发现里面有一个
torch>=1.7.0,!=1.12.0 torchvision>=0.8.1,!=0.13.0
这两条指令,但是如果大家都是按照我的方法,提前将环境配置好的话,那么大概率你的环境就会和官方给的环境不一样,所以如果大家的环境已经配置完了,就把这两条删掉,然后执行以下代码即可。
pip install -r requirements.txt
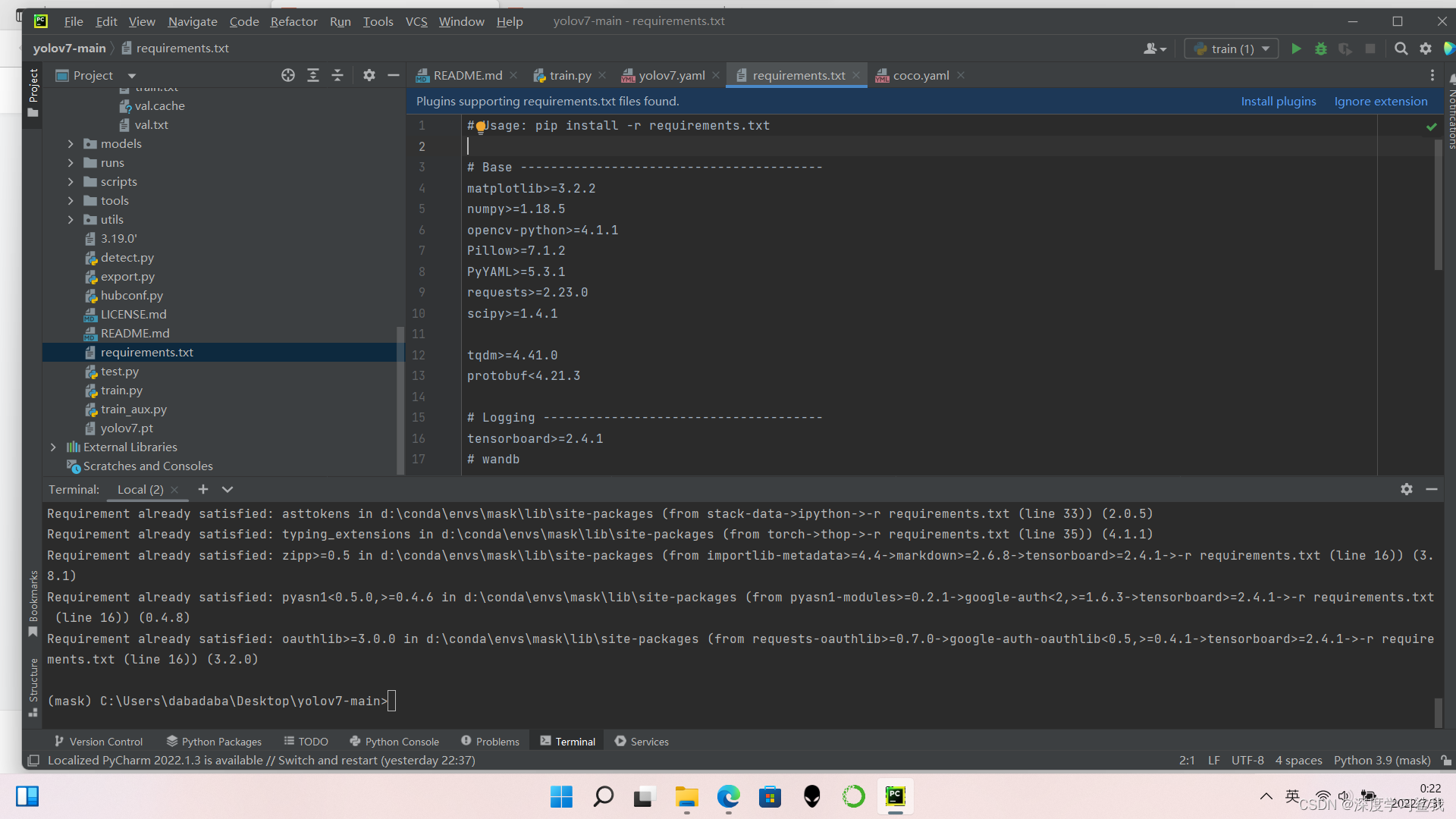
下载完毕以后,如下图所示,如果没有任何报错,则说明依赖包安装成功。
6.代码测试
将你一开始下载好的权重文件,yolov7.pt拖到yolov7-main这个文件夹中,然后执行输入下面的代码,即可测试。
python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source inference/images/horses.jpg
这段代码的意思是在python中运行detect.py脚本文件,然后修改其中的一些参数,训练权重使用yolov7.py这个文件,置信度为0.25(就是如果系统判断他有25%以上的概率是匹马,它就会输出,这是匹马,如果25%以下,系统就认为它不是马)图片大小为640,然后检测的要文件路径为inference/images/horses.jpg,输出结果如下。
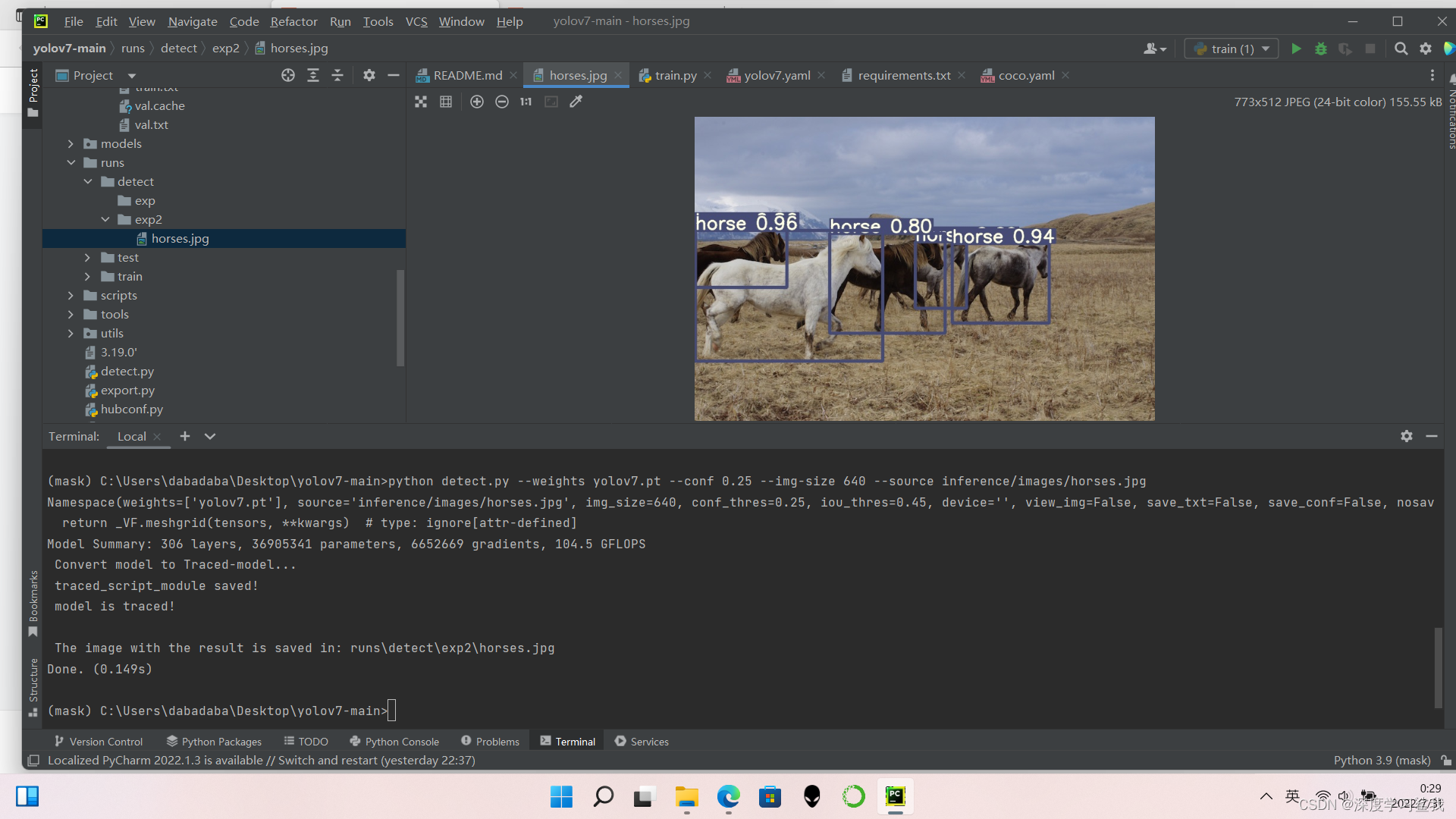
The image with the result is saved in: runs\detect\exp2\horses.jpg
Done. (0.149s)
意思是系统把跑完的图片保存在runs\detect\exp2\horses.jpg这个路径下,然后跑这一张图一共用了0.149s。
7.数据集的制作和训练
这里统一使用coco的数据集,然后用labelimg打标签,yolo系列大部分都是coco的数据集,也方便大家做各个版本的训练的效果对比,不过这个数据集起步一千张才有效果,不然根本不收敛。用cmd打开yolov7-main,然后输入以下代码
pip install labelimg下载完毕以后,直接输入labelimg即可启动,界面如下图。
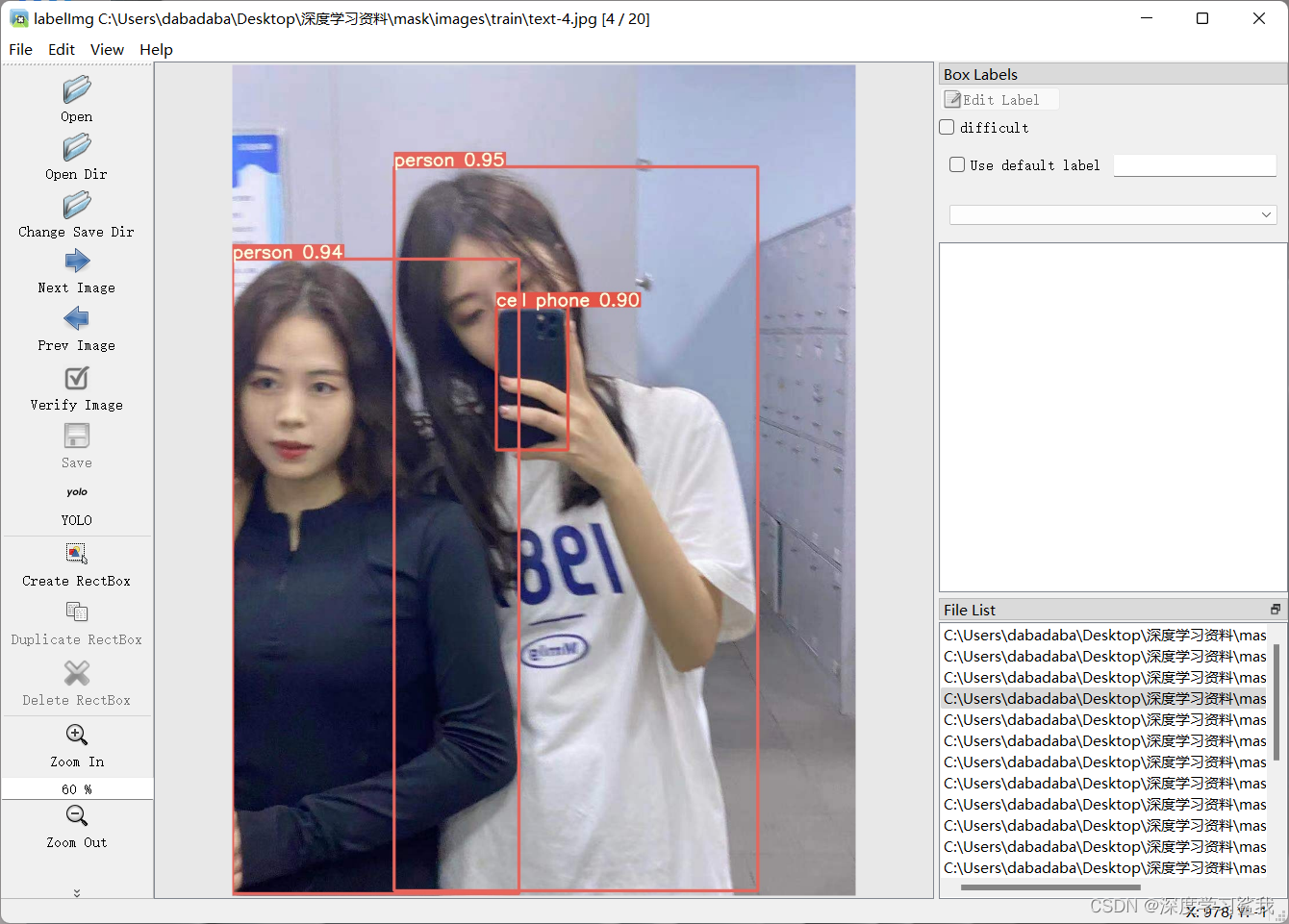
labelimg打开以后界面如下图,简单的介绍一下左边都是什么作用,open dir就是打开你要打标签的文件夹,change save dir就是修改存放标签文件的地址。那个yolo有的可能不是这个,建议改成coco的数据集,create rectbox就是创建画框标注,我用的这张图是我之前检测过的,原图让我删了,没找到,具体自己要做什么数据集,就看个人情况了,我这里做的是口罩检测的数据集,所以我会打人脸和口罩的标签。关于labelimg的使用方法大家可以自行百度,非常的简单,这里就不过多赘述了。
数据集做完以后,你的文件夹目录应该是
dataset
-images
--train
--val
--test
-labels
--train
--val
--test
-train.txt
-val.txt
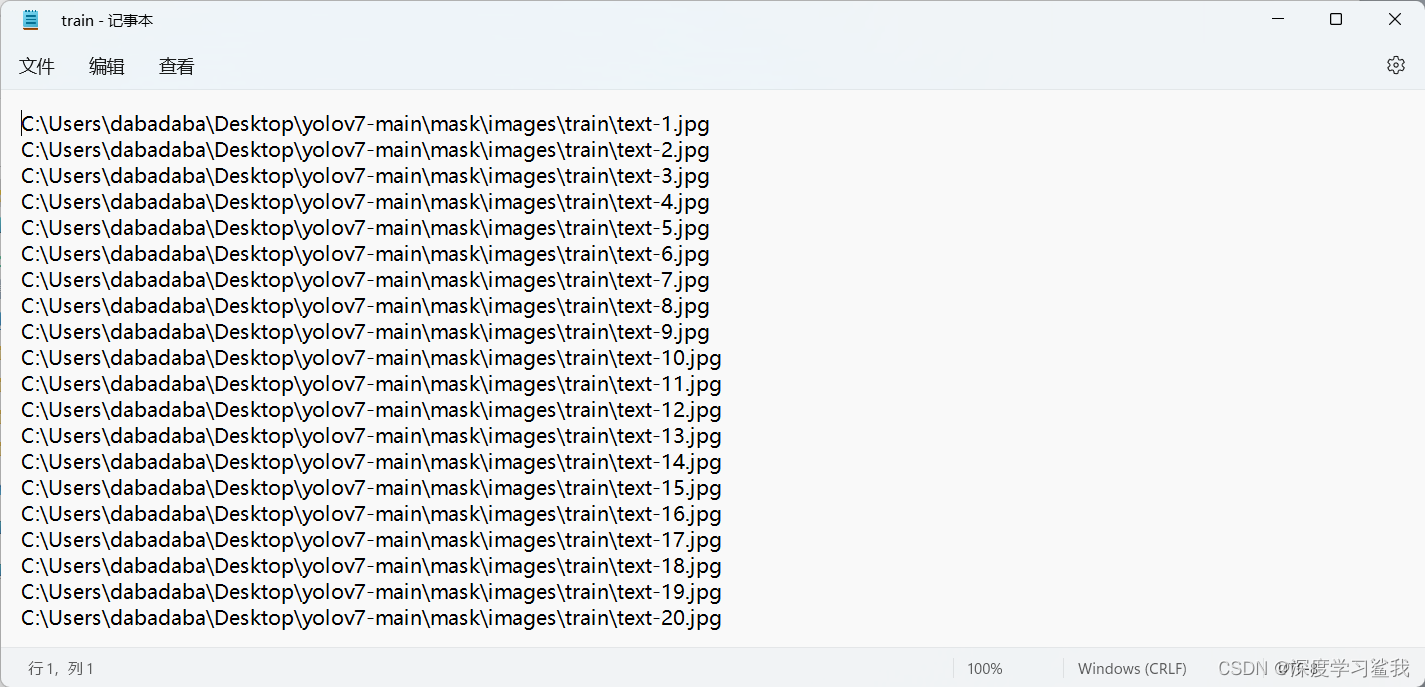
-test.txt其中images中的三个文件夹存放的是照片,labels中的三个文件夹存放的是标签文件,是文本文件,在你打标签的时候,change save dir那里就把文件地址设置为分别对应的文件地址。最后,在一级目录下面还有三个文本文件,这三个文本文件存放的是该文件里所有照片的绝对寻址地址,说起来很复杂,其实只要选中所有的照片,然后右键,点击复制文件地址,然后直接粘贴到这个文本文件里面就可以了。粘过来的时候会有引号,直接全部替换为空格就可以了,如下图。
到此,所有的数据集也制作完成了,然后就是修改配置文件里的参数,开始跑模型。
大家只需要修改两个配置文件即可,具体修改内容如下图。
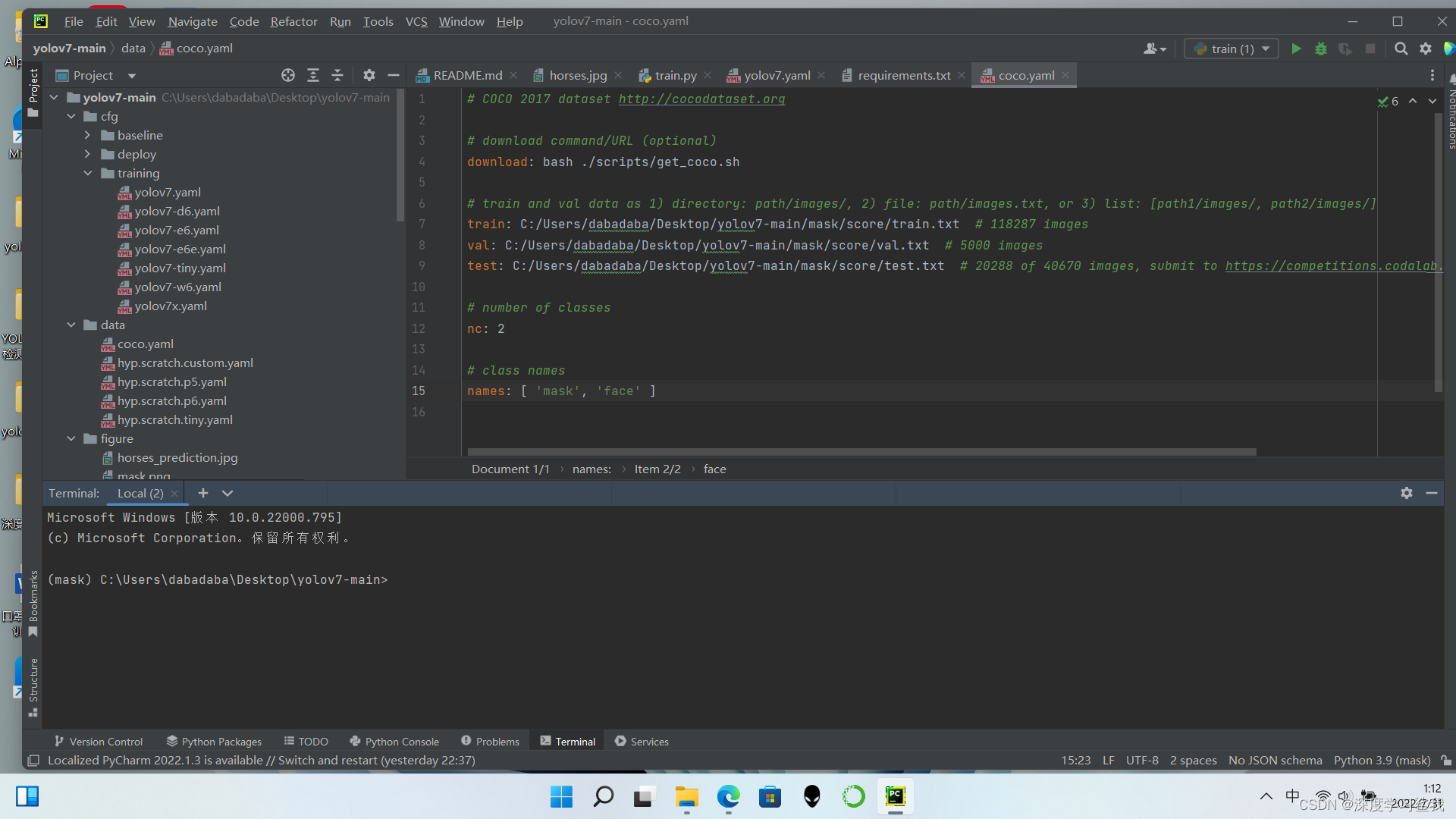
修改coco.ymal文件中,text,val,train的文件地址,改为自己的文件地址,需要注意的是,这里的文件地址是图片的绝对寻址地址的文本文件,跟yolov5还是有所区别的,还有就是/的问题,大家复制过来以后,会发现那个\是反的,python是不认识这个\的,要全部都改成/。下面的class names 改成你要检测的名称,比如我做口罩检测,所以我的名称是“mask” “face”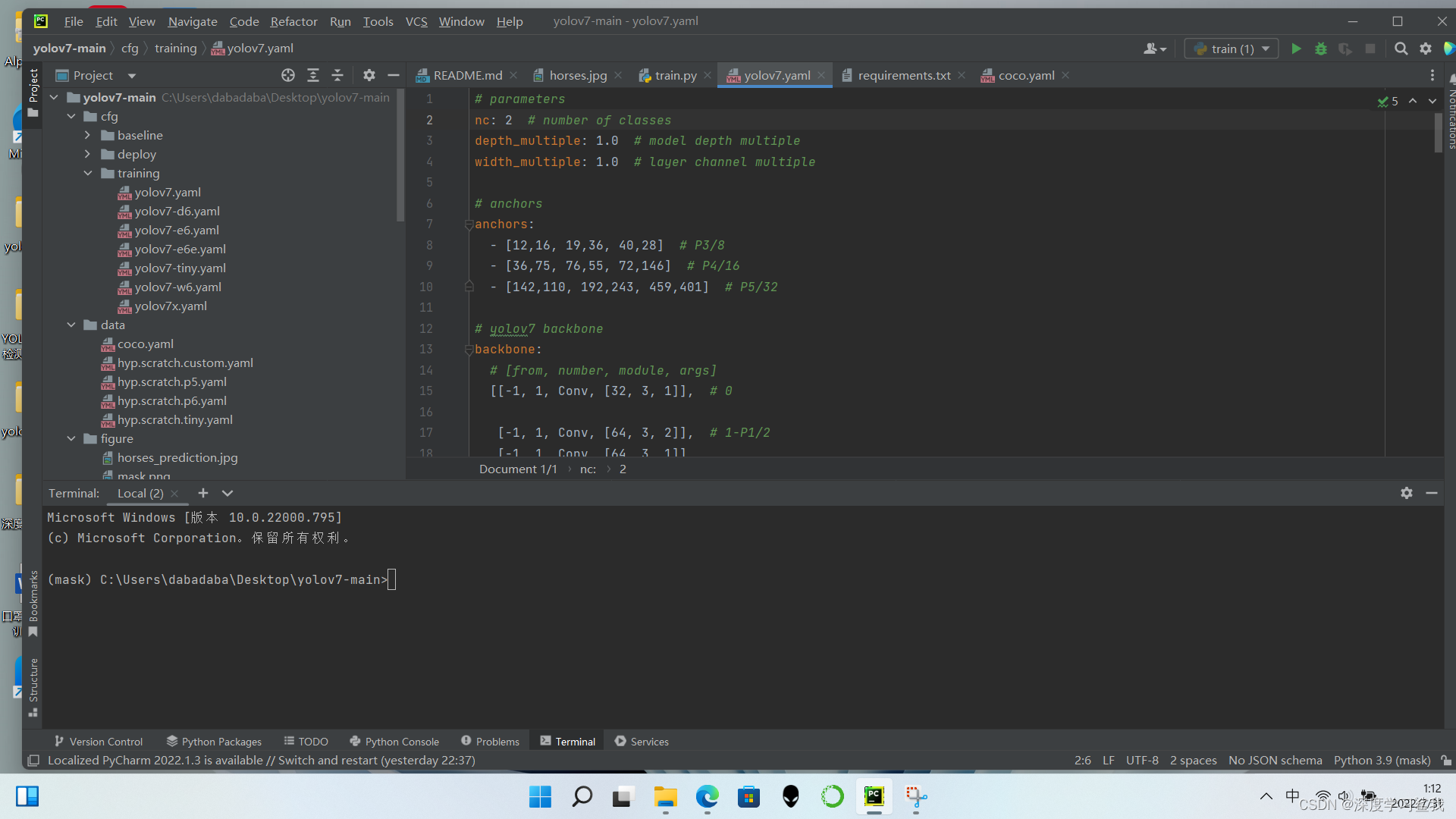
在yolov7.yaml中,只需要把number of classes改成你要检测的数据种类个数即可,我只做人脸和口罩的检测,所数据种类是2,我改成了2。
到这里就基本结束了,最后就是输入指令开始跑模型了,代码如下。
python train.py --workers 0 --device 0 --batch-size 8 --data data/coco.yaml --img 640 640 --cfg cfg/training/yolov7.yaml --weights '' --name yolov7 --hyp data/hyp.scratch.p5.yaml
python train.py --workers 4 --device cpu --batch-size 4 --data data/coco.yaml --img 640 640 --cfg cfg/training/yolov7.yaml --weights '' --name yolov7 --hyp data/hyp.scratch.p5.yaml
我这里给了两个代码,第一个是用gpu跑的,第二个是cpu跑的,workers指的是使用的cpu的个数,device 是选择配置的,0就是用gpu跑,cpu就是用cpu跑,batch size是每轮的抓取检测数量,不建议太大,一是太大了,跑的轮数又不够,容易梯度消失,结果不收敛,二是大家显卡估计都一般,我的3060已经是显存最大的了,bs也只能跑到8,大家要是跑出来报错了,就把bs调小一点试试。后面是使用的数据集,超参数文件,预训练权重等,就不一一赘述了,大家能把这个跑通,应该对yolov7也有了一定的了解,后面的就自己探索吧,跑通以后结果如下图。
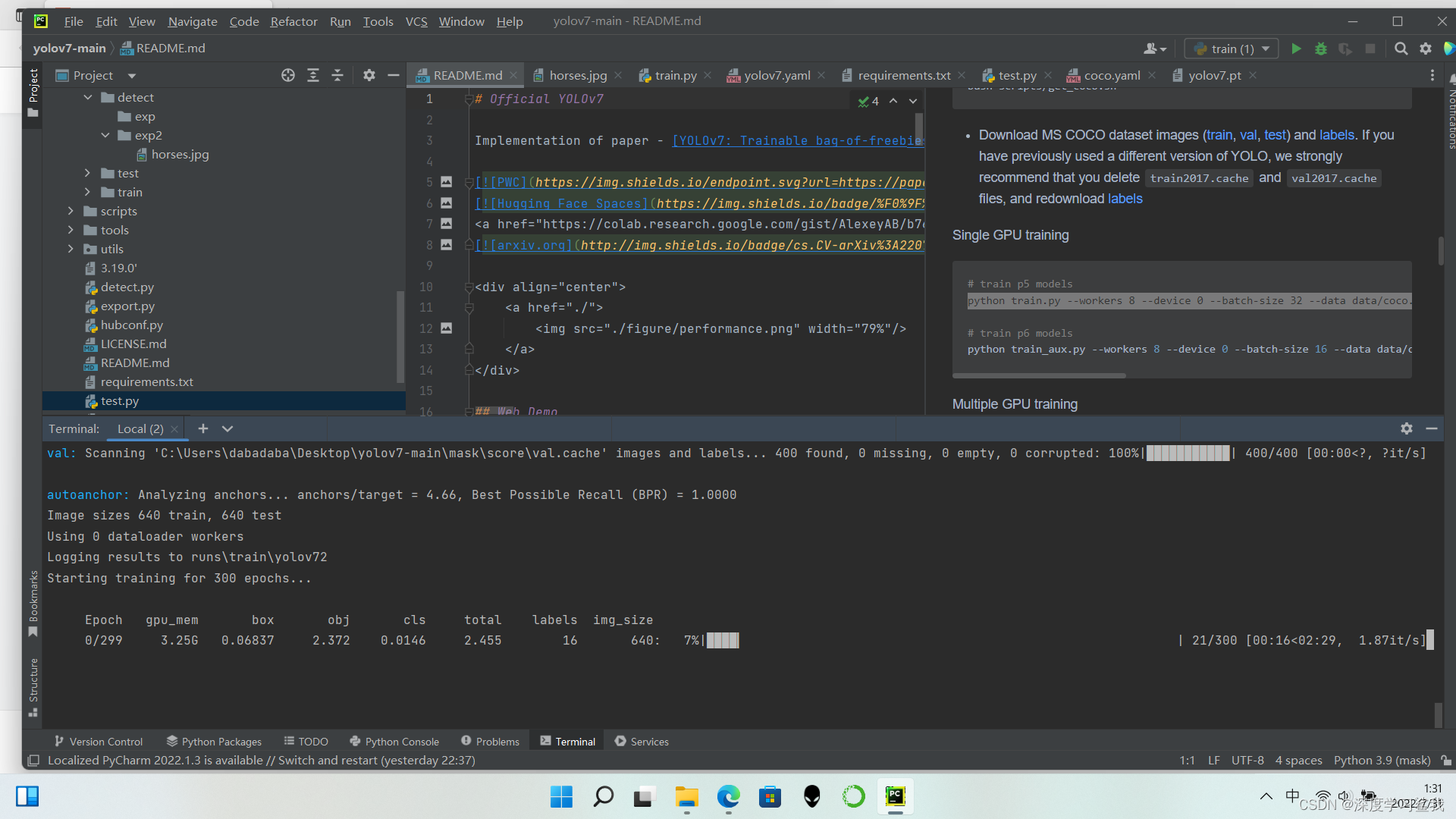
这个如果没有gpu或者设置的轮数太多,数据集又大大话,估计要跑个一周十来天都有可能,所以如果实在没有gpu就去网上租别人的服务器跑吧。

跑完以后会把结果存在C:\Users\dabadaba\Desktop\yolov7-main\runs\train\yolov7这个路径下面,里面有什么权重,结果的文本文件,混沌矩阵啥的,那个混沌矩阵可以看你的模型最后的精确度咋样,f1 曲线,p曲线啥的是看你的模型收不收敛的,还有散点图啥的,具体的就要自己去学习了。














 5206
5206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









