







【问题】在二叉树中有两个节点m和n,若m是n的祖先,则使用( )可以找到从m到n的路径
A:先序遍历 B:中序遍历 C:后序遍历 D:层序遍历
本文主要参考自遇见哥:https://www.zhihu.com/people/xi-wo-wang-yi-15-46/posts
首先明确一点,什么是路径,访问一个结点 x 时,栈中结点恰好是 x 结点的所有祖先,从栈底到栈顶结点再加上 x 结点,这样就构成了从根结点到 x 结点的一条路径。
对题目换一种表达:
我们对二叉树进行遍历,我们总是把探测到的节点放入栈中,而在访问的时候才将它出栈,请问,哪一种遍历可以保证,访问到某节点时,栈中存储的永远是它的全部祖先节点,为什么?
遍历的访问顺序描述了一种左子树,根,右子树三者之间的关系. 这里提到了子树,我们在讨论树的问题的时候,最好的方式就是,永远不要把树上的节点割裂出来孤立的分析,而是把它们放在子树中,考察子树共同的性质。
我们都知道,某个节点想要访问,必先入栈,若想入栈,那么它的每一个祖先节点都必须已经入栈过。所以我们这个问题其实就是分析两个点
-
栈中除了祖先节点,是否还混杂了其他的节点。
-
祖先节点是不是完整的都保留下来了。
先序遍历:
void preorderTraversal(TreeNode* root) {
if (root == NULL) return;
stack<TreeNode*> stack;
stack.push(root);
while (!stack.empty()) {
TreeNode* node = stack.top();
stack.pop();
// 访问当前节点
cout << node->val << " ";
// 先右后左入栈保证左子树先被访问
if (node->right) {
stack.push(node->right);
}
if (node->left) {
stack.push(node->left);
}
}
}
在先序遍历中,访问的顺序是根节点-左子树-右子树。当我们访问一个节点时,我们首先将该节点放入栈中,然后立即访问它,之后才去访问它的左子树和右子树。这意味着祖先节点在其子节点被访问前就已经不在栈中了。
中序非递归遍历
// 中序遍历非递归实现
void inorderTraversal(TreeNode* root) {
stack<TreeNode*> stack;
TreeNode* current = root;
while (current != NULL || !stack.empty()) {
// 尽可能的向左走,将所有左子节点入栈
while (current != NULL) {
stack.push(current);
current = current->left;
}
// 当左子节点走到头,开始处理栈顶节点
current = stack.top();
stack.pop();
// 访问当前节点
cout << current->val << " ";
// 转向右子树
current = current->right;
}
}
【遍历思想】:
- 栈的使用:利用一个栈来模拟递归调用的行为,首先尽可能地将所有左子节点推入栈中。
- 节点处理:当左侧没有更多节点时,从栈中取出节点访问,然后转向该节点的右子节点。
- 遍历右子树:对于每个从栈中取出的节点,都尝试访问其右子树。如果右子树存在,重复前面的过程,即先将右子树的所有左子节点入栈。
在中序遍历中,当我们访问一个节点(比如节点n)时,它的左子树已经被完全访问并从栈中移除。如果n在其祖先节点的右子树中,那么在访问n之前,这个祖先节点已经被访问并从栈中移除了。因此,栈中也不会保留完整的祖先路径。只有当n位于所有祖先节点的直接左侧时(即在最左边的路径上),栈中才会包含其全部祖先。
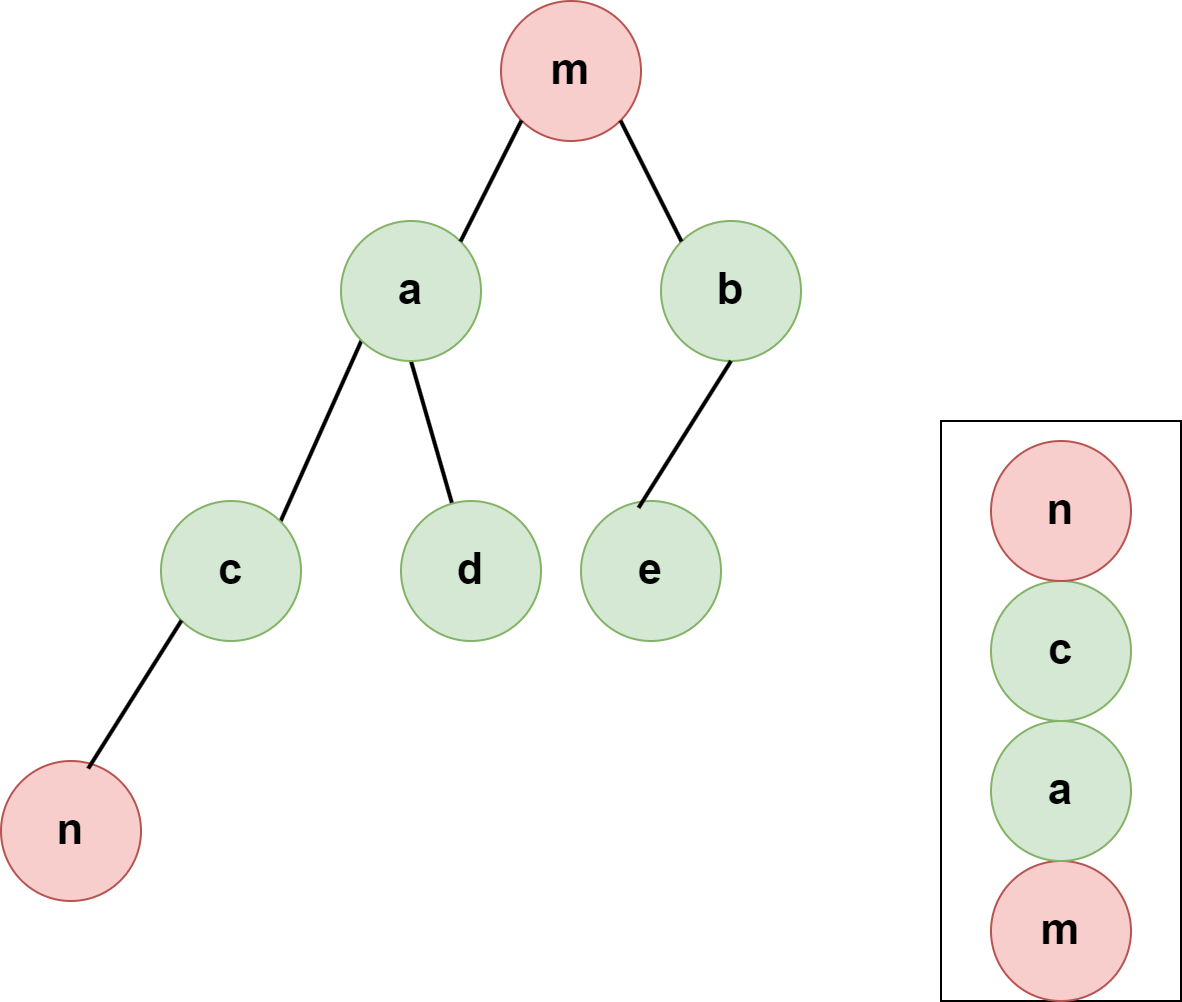
- 如下左图,结点c是结点n的一个祖先节点,但是结点n位于结点c的右子树,当访问到结点n时,结点c已经出栈了,因此此时栈里面未保留完整的祖先路径;
- 而右图中,n位于其所有祖先节点的直接左侧,因此访问到n时,栈中的结点恰好是其完整的祖先节点。
- 图3的普通情况下,中序非递归的栈中,n的祖先节点缺的就更多了,因此中序非递归遍历不能保证找到m到n的完整路径。



后序非递归遍历
vector<int> postorderTraversal(TreeNode* root) {
vector<int> res;
stack<TreeNode*> stk;
TreeNode* cur = root, *pre = NULL;
//主要思想:
//由于在某颗子树访问完成以后,接着就要回溯到其父节点去
//因此可以用prev来记录访问历史,在回溯到父节点时,可以由此来判断,上一个访问的节点是否为右子树;
while(cur != NULL || !stk.empty()){
while(cur!=NULL) { //步骤1:沿着根的左孩子依次入栈,直到左孩子为空;
stk.push(cur);
cur = cur ->left;
}
cur = stk.top();
stk.pop(); //步骤2:此时从栈中弹出的元素,左子树一定是访问完了的;
//现在需要确定的是是否有右子树,或者右子树是否访问过
//如果没有右子树,或者右子树访问完了,也就是上一个访问的节点是右子节点时
//说明可以访问当前节点
if(cur->right == NULL || pre == cur->right) {
res.push_back(cur->val);
pre = cur;//更新历史访问记录,这样回溯的时候父节点可以由此判断右子树是否访问完成;
cur = NULL; //结点访问完,重置cur指针,以免跳到步骤1;
}else{
stk.push(cur);//如果右子树没有被访问,那么将当前节点压栈,访问右子树
cur = cur -> right; //将其右子树转去执行步骤2.
}
}
return res;
}
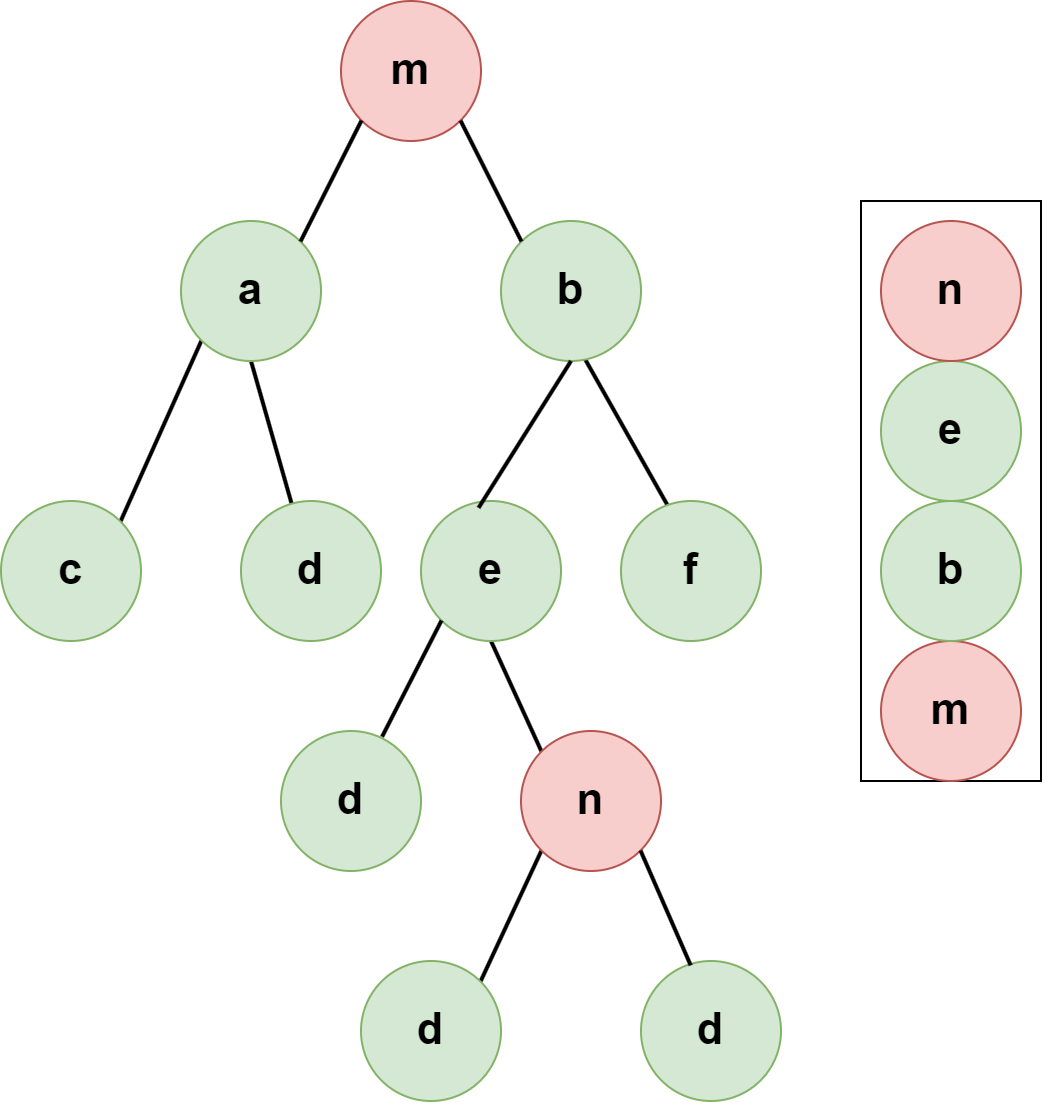
- 左子树中的节点n:当访问n时,因为后序遍历的顺序是先左后右再根,n的右侧兄弟(即右子树)尚未开始遍历,所以n的所有祖先节点都还在栈中。
-
右子树中的节点n:当访问的节点 n n n 在右子树,由于是后序遍历,可以肯定左子树已经全部访问完并且出栈了,而且祖先还在栈中,右子树访问到 n n n,此时 n n n的后代节点也已经全部出栈,所以到 n n n 的时候,栈中还是全部都是祖先节点。
-
递归到整个树结构,后序遍历可以保证,访问到某节点时,栈中存储的永远是它的全部祖先节点。
因此后序遍历在处理祖先节点的保留上表现最佳。无论节点n位于左子树还是右子树,遍历过程保证了在访问 n n n之前,其所有祖先节点都未被访问并因此仍存储在栈中。















 662
662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









