






一、html文件准备
首先,我们要明确我们需要的数据,并在html中找到它们的位置。
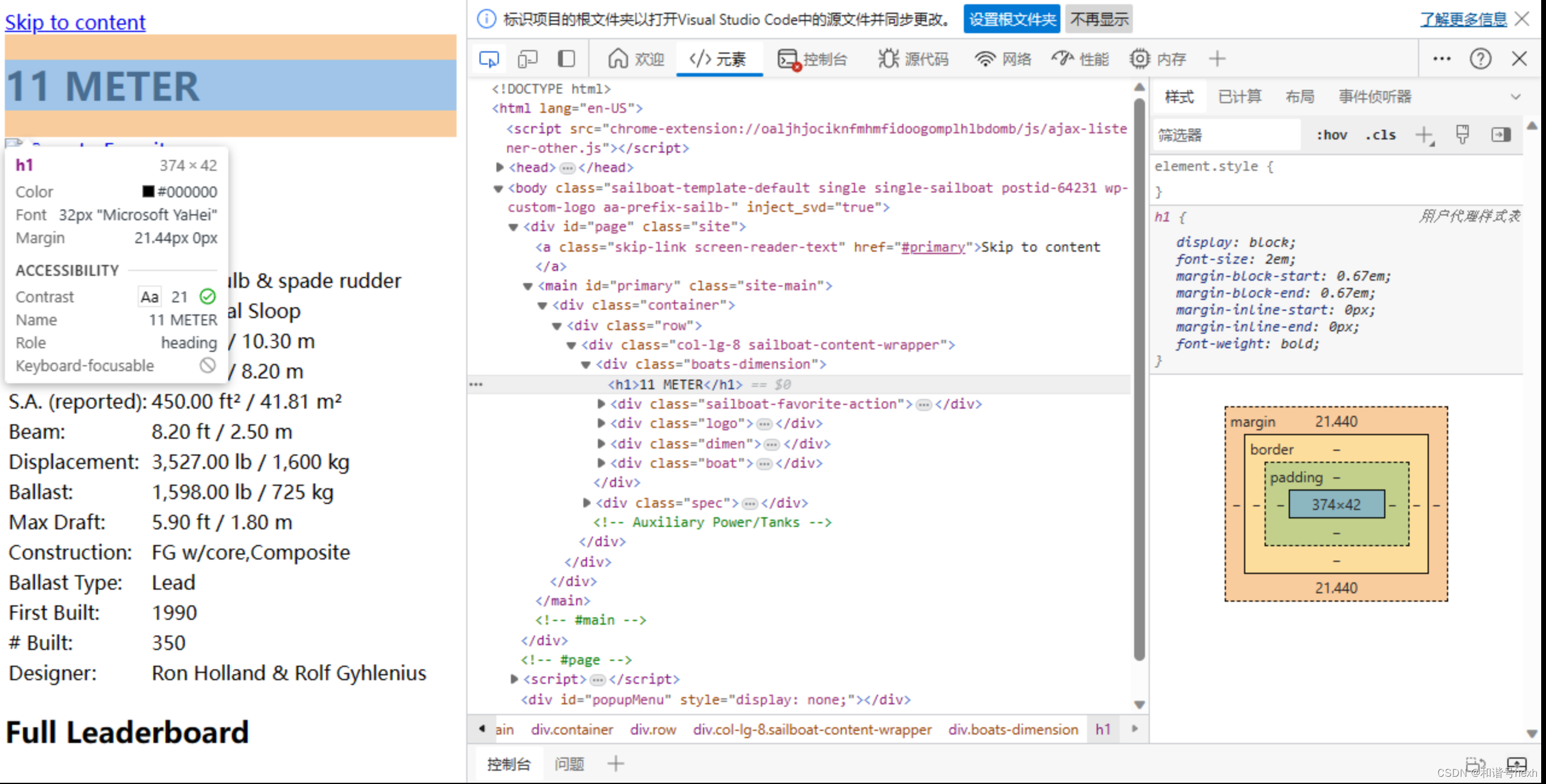
1.帆船名称:11 METER
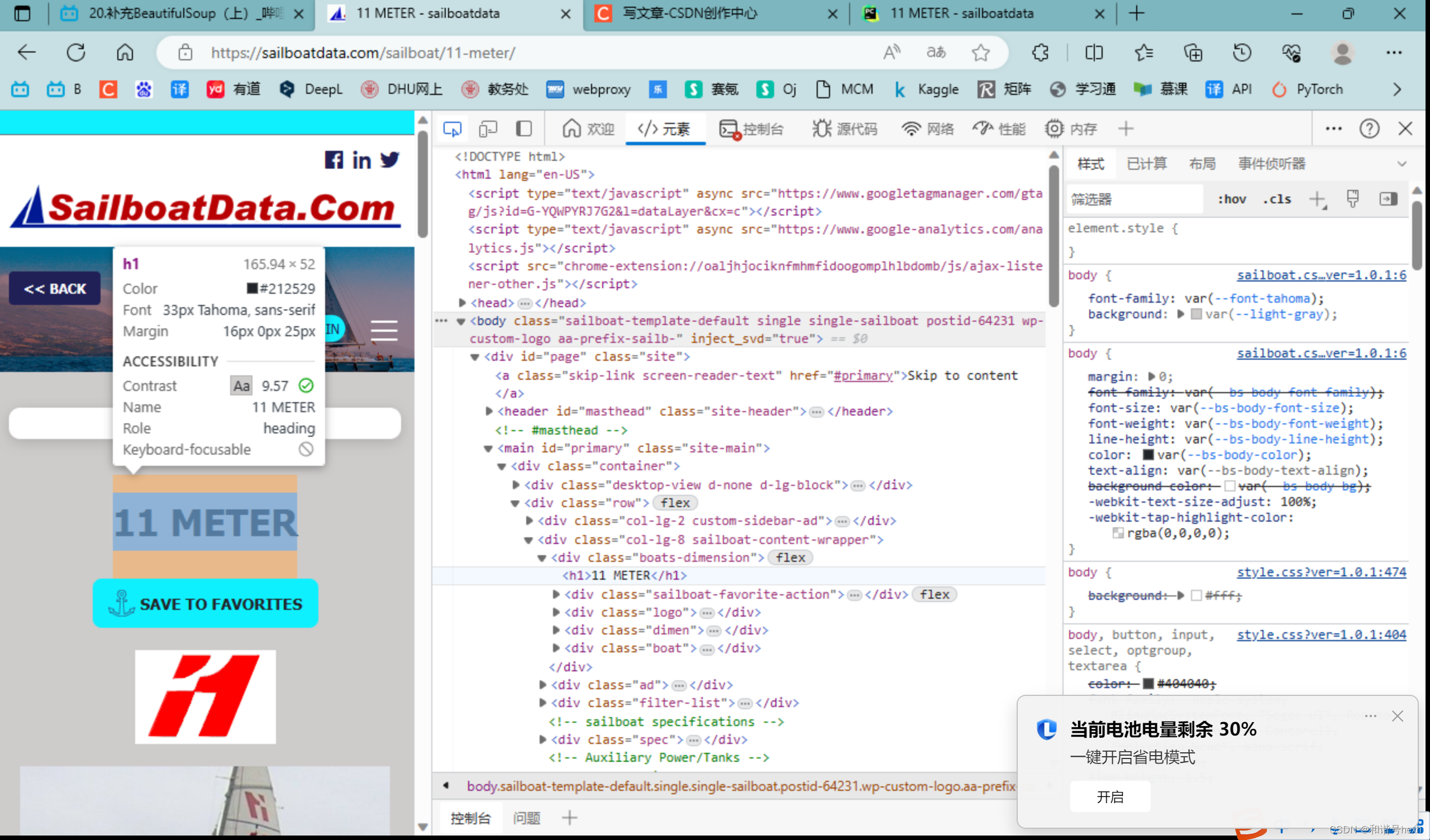
2.Sailboat Specifications
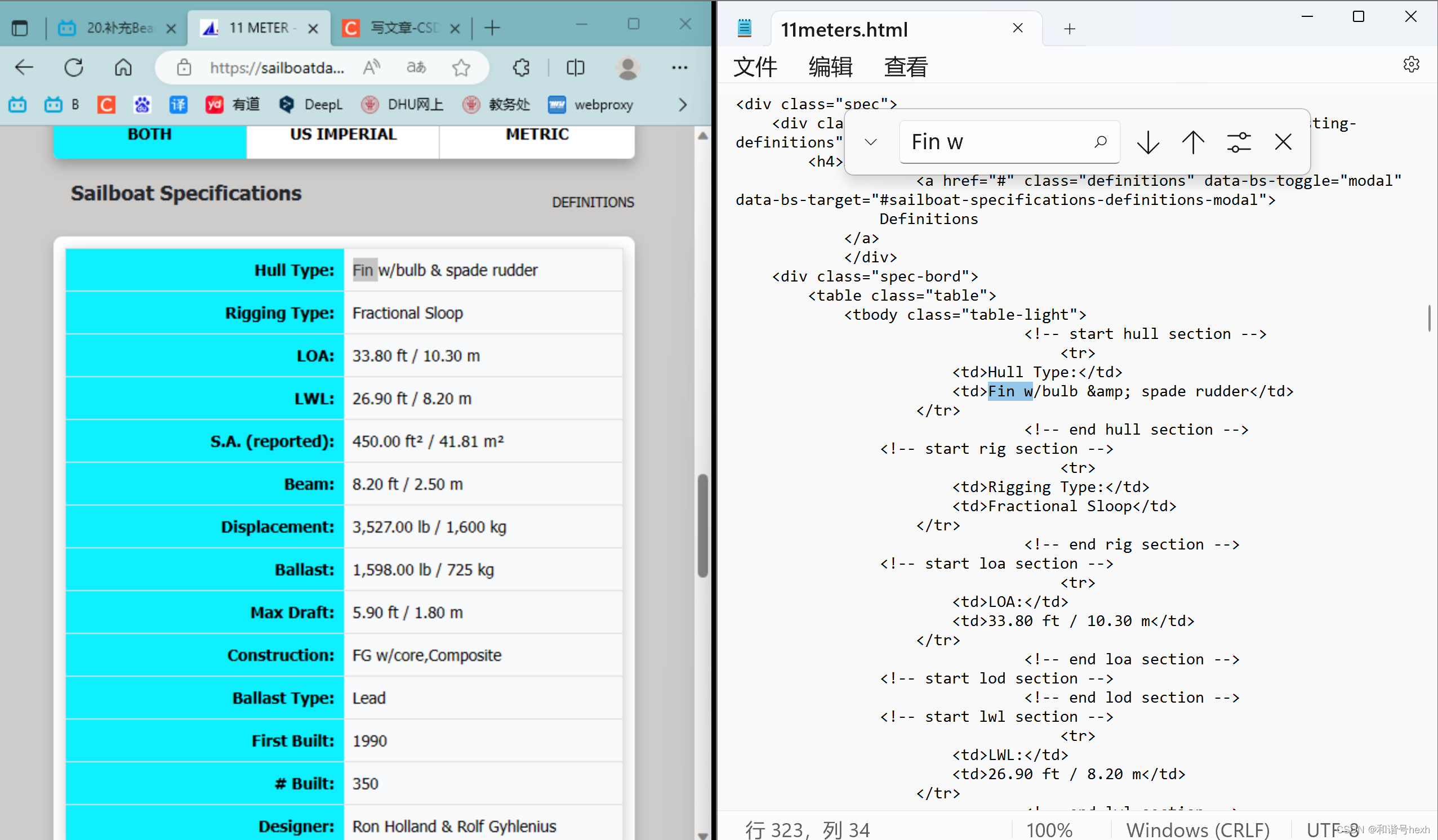
事实上,还可以获取更多帆船数据,但因为与Sailboat Specifications的过程基本相同,这里省略。
为了方便演示,我把相关部分摘下来:
<!doctype html>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta name="apple-itunes-app" content="app-id=1545197438">
<link rel="profile" href="https://gmpg.org/xfn/11">
<meta name='robots' content='index, follow, max-image-preview:large, max-snippet:-1, max-video-preview:-1'/>
<!-- This site is optimized with the Yoast SEO plugin v20.6 - https://yoast.com/wordpress/plugins/seo/ -->
<title>11 METER - sailboatdata</title>
<link rel="canonical" href="https://sailboatdata.com/sailboat/11-meter/"/>
<meta property="og:locale" content="en_US"/>
<meta property="og:type" content="article"/>
<meta property="og:title" content="11 METER - sailboatdata"/>
<meta property="og:url" content="https://sailboatdata.com/sailboat/11-meter/"/>
<meta property="og:site_name" content="sailboatdata"/>
<meta property="article:publisher" content="https://www.facebook.com/sailboatdata"/>
<meta property="article:modified_time" content="2023-05-12T18:11:13+00:00"/>
<meta property="og:image" content="https://sailboatdata.com/wp-content/uploads/2023/03/11_meter_photo.jpg"/>
<meta property="og:image:width" content="483"/>
<meta property="og:image:height" content="640"/>
<meta property="og:image:type" content="image/jpeg"/>
</head>
<body class="sailboat-template-default single single-sailboat postid-64231 wp-custom-logo aa-prefix-sailb-">
<div id="page" class="site">
<a class="skip-link screen-reader-text" href="#primary">Skip to content</a>
<main id="primary" class="site-main">
<div class="container">
<div class="row">
<div class="col-lg-8 sailboat-content-wrapper">
<div class="boats-dimension">
<h1>11 METER</h1>
</div>
<div class="spec">
<div class="spec-bord">
<table class="table">
<tbody class="table-light">
<!-- start hull section -->
<tr>
<td>Hull Type:</td>
<td>Fin w/bulb & spade rudder</td>
</tr>
<!-- end hull section -->
<!-- start rig section -->
<tr>
<td>Rigging Type:</td>
<td>Fractional Sloop</td>
</tr>
<!-- end rig section -->
<!-- start loa section -->
<tr>
<td>LOA:</td>
<td>33.80 ft / 10.30 m</td>
</tr>
<!-- end loa section -->
<!-- start lod section -->
<!-- end lod section -->
<!-- start lwl section -->
<tr>
<td>LWL:</td>
<td>26.90 ft / 8.20 m</td>
</tr>
<!-- end lwl section -->
<!-- start sa section -->
<tr>
<td>S.A. (reported):</td>
<td>450.00 ft² / 41.81 m²</td>
</tr>
<!-- end sa section -->
<!-- start beam section -->
<tr>
<td>Beam:</td>
<td>8.20 ft / 2.50 m</td>
</tr>
<!-- end beam section -->
<!-- start beam wl section -->
<!-- end beam wl section -->
<!-- start disp section -->
<tr>
<td>Displacement:</td>
<td>3,527.00 lb / 1,600 kg</td>
</tr>
<!-- end disp section -->
<!-- start ballast section -->
<tr>
<td>Ballast:</td>
<td>1,598.00 lb / 725 kg</td>
</tr>
<!-- end ballast section -->
<!-- start max draft section -->
<tr>
<td>Max Draft:</td>
<td>5.90 ft / 1.80 m</td>
</tr>
<!-- end max draft section -->
<!-- start min draft section -->
<!-- end min draft section -->
<!-- start hull construction section -->
<tr>
<td>Construction:</td>
<td>FG w/core,Composite</td>
</tr>
<!-- end hull construction section -->
<!-- start ballast type section -->
<tr>
<td>Ballast Type:</td>
<td>Lead</td>
</tr>
<!-- end ballast type section -->
<!-- start Bridgedeck Clearance section -->
<!-- end Bridgedeck Clearance section -->
<!-- start first built section -->
<tr>
<td>First Built:</td>
<td>1990</td>
</tr>
<!-- end first built section -->
<!-- start last built section -->
<!-- end last built section -->
<!-- start number built section -->
<tr>
<td># Built:</td>
<td>350</td>
</tr>
<!-- end number built section -->
<!-- start builder name section -->
<!-- end builder name section -->
<!-- start designer name section -->
<tr>
<td>Designer:</td>
<td>Ron Holland & Rolf Gyhlenius</td>
</tr>
<!-- end designer name section -->
</tbody>
</table>
</div>
</div>
<!-- Auxiliary Power/Tanks -->
</div>
</div>
</div>
</main><!-- #main -->
</div><!-- #page -->
</body>
</html> 
观察结构,它是由一个head和body组成,head中有一些meta、link
二、beautifulsoup基本类型与用法
beautifulsuop,漂亮的汤,它的作用是将一个html文件进行解析,转换成一个树状结构,每个节点是一个Python对象,有四种类型:Tag,NavigableString,BeautifulSoup,comment
首先我们新建文件testBs4.py
0.导包、读取文件、创建bs对象
from bs4 import BeautifulSoup
f = open(r"./11meters.html", "rb") # 以二进制读取,以模拟我们爬取页面response的结果
html = f.read().decode("utf-8") # 解码
#创建beautifulsoup对象
bs= BeautifulSoup(html,"html.paeser") # (待解析的文档,解析器类型)1.bs4.element.Tag(获取第一次出现的标签及层级下的所有内容)
print(type(bs.title),bs.title)
print("-"*50)
print(type(bs.meta),bs.meta)
print("-"*50)
print(type(bs.link),bs.link)
print("-"*50)
print(type(bs.head),bs.head)
print("-"*50)
print(type(bs.a),bs.a)
print("-"*50)
# print(type(bs.div),bs.div)
# print("-"*50)D:\Anaconda3\python.exe C:\Users\和谐号\PycharmProjects\pythonProject\2023-08-22-sailboatData\testBs4.py
<class 'bs4.element.Tag'> <title>11 METER - sailboatdata</title>
--------------------------------------------------
<class 'bs4.element.Tag'> <meta charset="utf-8"/>
--------------------------------------------------
<class 'bs4.element.Tag'> <link href="https://gmpg.org/xfn/11" rel="profile"/>
--------------------------------------------------
<class 'bs4.element.Tag'> <head>
<meta charset="utf-8"/>
<meta content="width=device-width, initial-scale=1" name="viewport"/>
<meta content="app-id=1545197438" name="apple-itunes-app"/>
<link href="https://gmpg.org/xfn/11" rel="profile"/>
<meta content="index, follow, max-image-preview:large, max-snippet:-1, max-video-preview:-1" name="robots">
<!-- This site is optimized with the Yoast SEO plugin v20.6 - https://yoast.com/wordpress/plugins/seo/ -->
<title>11 METER - sailboatdata</title>
<link href="https://sailboatdata.com/sailboat/11-meter/" rel="canonical">
<meta content="en_US" property="og:locale">
<meta content="article" property="og:type">
<meta content="11 METER - sailboatdata" property="og:title"/>
<meta content="https://sailboatdata.com/sailboat/11-meter/" property="og:url"/>
<meta content="sailboatdata" property="og:site_name"/>
<meta content="https://www.facebook.com/sailboatdata" property="article:publisher"/>
<meta content="2023-05-12T18:11:13+00:00" property="article:modified_time"/>
<meta content="https://sailboatdata.com/wp-content/uploads/2023/03/11_meter_photo.jpg" property="og:image"/>
<meta content="483" property="og:image:width"/>
<meta content="640" property="og:image:height"/>
<meta content="image/jpeg" property="og:image:type"/>
</meta></meta></link></meta></head>
--------------------------------------------------
<class 'bs4.element.Tag'> <a class="skip-link screen-reader-text" href="#primary">Skip to content</a>
--------------------------------------------------
进程已结束,退出代码为 0
可以str()到字符串
2.bs4.element.NavigableString (获取第一次出现的标签里的内容)
print(type(bs.title.string),bs.title.string)
print("-"*50)
print(type(bs.meta.string),bs.meta.string)
print("-"*50)
print(type(bs.link.string),bs.link.string)
print("-"*50)
print(type(bs.head.string),bs.head.string)
print("-"*50)
print(type(bs.a.string),bs.a.string)
print("-"*50)
# print(type(bs.div),bs.div)
# print("-"*50)
<class 'bs4.element.NavigableString'> 11 METER - sailboatdata
--------------------------------------------------
<class 'NoneType'> None
--------------------------------------------------
<class 'NoneType'> None
--------------------------------------------------
<class 'NoneType'> None
--------------------------------------------------
<class 'bs4.element.NavigableString'> Skip to content
--------------------------------------------------
当不存在内容时,就是None,类型也不是bs4.element.NavigableString了,
可以str()到字符串
3.bs4.BeautifulSoup (整个bs对象)
print(type(bs.name),bs.name)
print("-"*50)
print(type(bs.attrs),bs.attrs)
print("-"*50)
print(type(bs),bs)<class 'str'> [document]
--------------------------------------------------
<class 'dict'> {}
--------------------------------------------------
<class 'bs4.BeautifulSoup'> <!DOCTYPE doctype html><html lang="en-US">
<head>
<meta charset="utf-8"/>
<meta content="width=device-width, initial-scale=1" name="viewport"/>
<meta content="app-id=1545197438" name="apple-itunes-app"/>
<link href="https://gmpg.org/xfn/11" rel="profile"/>
<meta content="index, follow, max-image-preview:large, max-snippet:-1, max-video-preview:-1" name="robots">
<!-- This site is optimized with the Yoast SEO plugin v20.6 - https://yoast.com/wordpress/plugins/seo/ -->
<title>11 METER - sailboatdata</title>
<link href="https://sailboatdata.com/sailboat/11-meter/" rel="canonical">......
4.bs4.element.Comment(一种特殊的NavigableString)
当标签里的内容时注释时,再用.string命令,得到的不在是NavigableString,而是comment,同时也不会原封不动地输出注释,而是展示去掉注释符号以后的结果。
(1)对html做如下修改:

print(type(bs.a),bs.a)
print(type(bs.a.string),bs.a.string)
print(type(bs.a.attrs),bs.a.attrs)<class 'bs4.element.Tag'> <a class="skip-link screen-reader-text" href="#primary">Skip to content</a>
<class 'bs4.element.NavigableString'> Skip to content
<class 'dict'> {'class': ['skip-link', 'screen-reader-text'], 'href': '#primary'}
(2)在修改:

print(type(bs.a),bs.a)
print(type(bs.a.string),bs.a.string)
print(type(bs.a.attrs),bs.a.attrs)<class 'bs4.element.Tag'> <a class="skip-link screen-reader-text" href="#primary"><!--Skip to content--></a>
<class 'bs4.element.Comment'> Skip to content
<class 'dict'> {'class': ['skip-link', 'screen-reader-text'], 'href': '#primary'}
5..attrs获取标签里的属性值(字典类型,键值对存储)
print(type(str(bs.title.attrs)),str(bs.title.attrs))
print("-"*50)
print(type(bs.meta.attrs),bs.meta.attrs)
print("-"*50)
print(type(bs.link.attrs),bs.link.attrs)
print("-"*50)
print(type(bs.head.attrs),bs.head.attrs)
print("-"*50)
print(type(bs.a.attrs),bs.a.attrs)
print("-"*50)<class 'str'> {}
--------------------------------------------------
<class 'dict'> {'charset': 'UTF-8'}
--------------------------------------------------
<class 'dict'> {'rel': ['profile'], 'href': 'https://gmpg.org/xfn/11'}
--------------------------------------------------
<class 'dict'> {}
--------------------------------------------------
<class 'dict'> {'class': ['skip-link', 'screen-reader-text'], 'href': '#primary'}
--------------------------------------------------
当不存在内容时,返回空字典
上述内容只是让我们了解beautifulsoup中有的对象类型,以及它们的特点,真正在使用的时候,还用不上,因为它只能返回它找到的第一项,对我们提取数据用处不大。
三、beautifulsoup遍历(对tag操作)
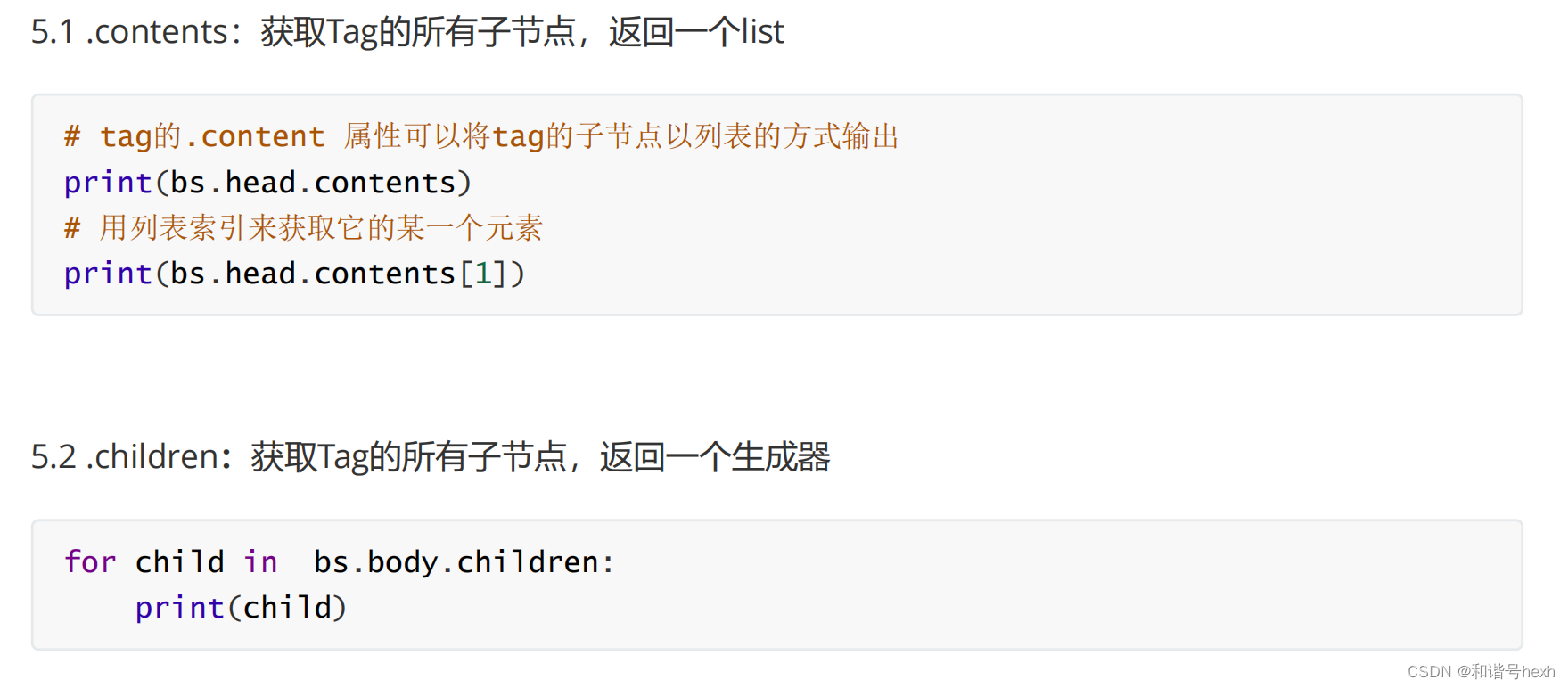
1..contents属性
print(bs.body)
print("-"*500)
print(type(bs.body.contents))
for item in bs.body.contents:
print(item)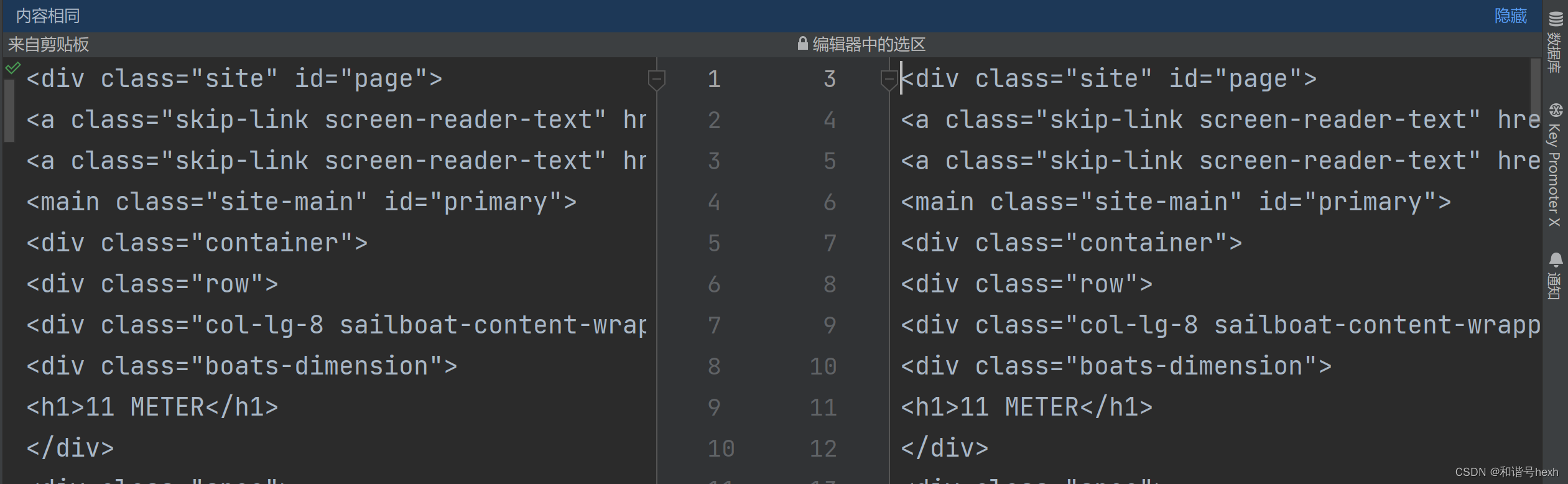
bs.body是tag对象,我们可以把它转为str,然后按行放到一个列表中,有点像readlins()方法
以上代码,主题部分是完全相同的,区别就是contents只有head里面的内容,head标签以及起止符不会出现:
.body:
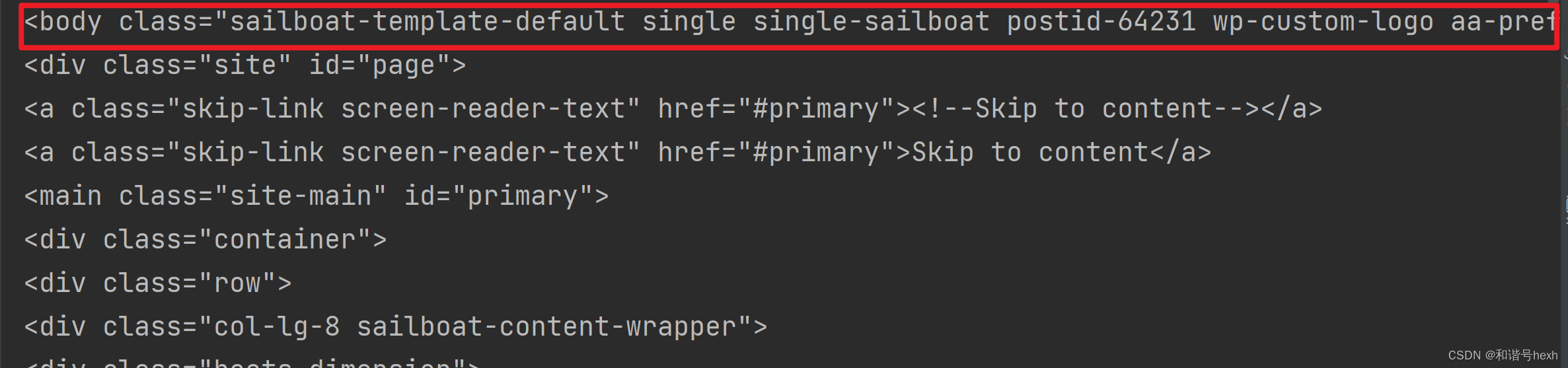

.body.contents:
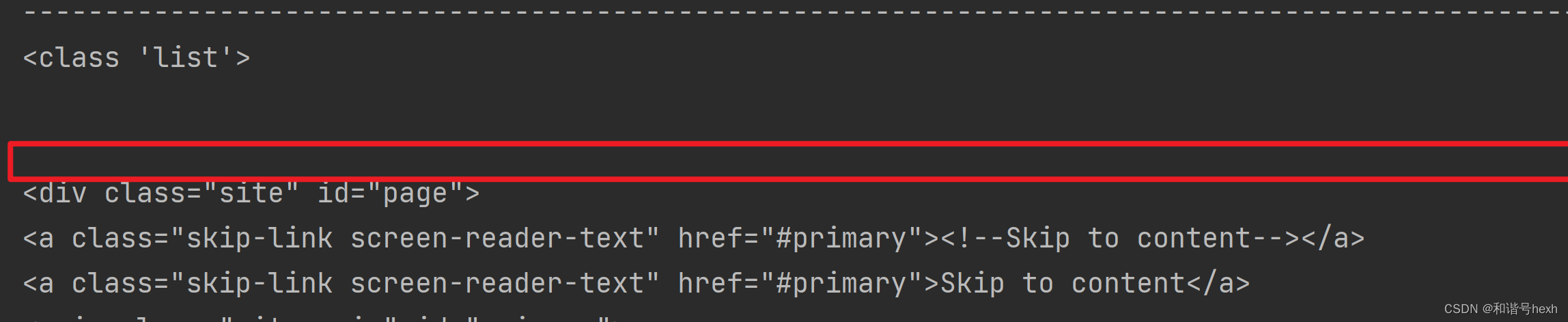

2.children
print(bs.body)
print("-"*500)
print(type(bs.body.children))
for item in bs.body.children:
print(item) 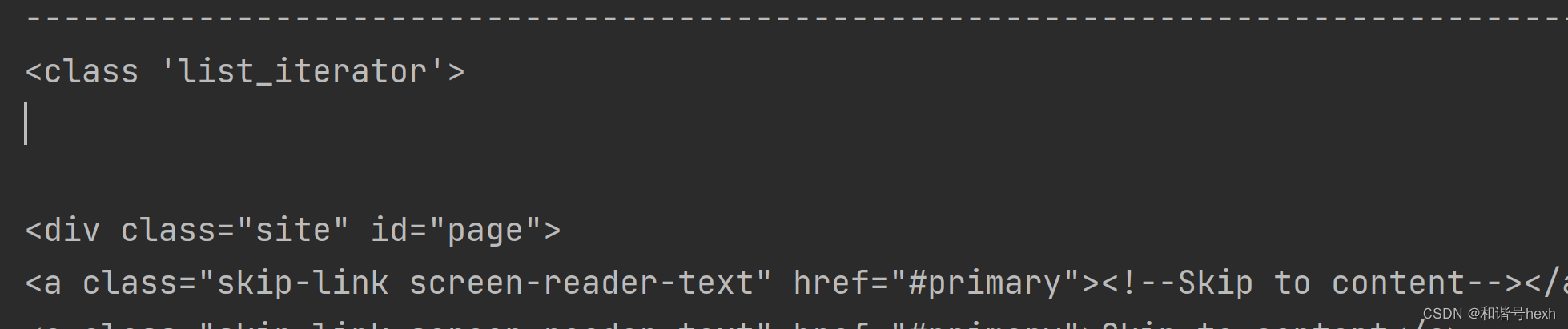
与contents相比,似乎只是数据类型的不同,contents得到是list,children得到的是list_iterator
3.其它
5.3 、 .descendants :获取 Tag 的所有子孙节点5.4 、 .strings :如果 Tag 包含多个字符串,即在子孙节点中有内容,可以用此获取,而后进行遍历5.5 、 .stripped_strings :与 strings 用法一致,只不过可以去除掉那些多余的空白内容5.6 、 .parent :获取 Tag 的父节点5.7 、 .parents :递归得到父辈元素的所有节点,返回一个生成器5.8 、 .previous_sibling :获取当前 Tag 的上一个节点,属性通常是字符串或空白,真实结果是当前标签与上一个标签之间的顿号和换行符5.9 、 .next_sibling :获取当前 Tag 的下一个节点,属性通常是字符串或空白,真是结果是当前标签与下一个标签之间的顿号与换行符5.10 、 .previous_siblings :获取当前 Tag 的上面所有的兄弟节点,返回一个生成器5.11 、 .next_siblings :获取当前 Tag 的下面所有的兄弟节点,返回一个生成器5.12 、 .previous_element :获取解析过程中上一个被解析的对象 ( 字符串或 tag) ,可能与previous_sibling 相同,但通常是不一样的5.13 、 .next_element :获取解析过程中下一个被解析的对象 ( 字符串或 tag) ,可能与 next_sibling 相同,但通常是不一样的5.14 、 .previous_elements :返回一个生成器,可以向前访问文档的解析内容5.15 、 .next_elements :返回一个生成器,可以向后访问文档的解析内容5.16 、 .has_attr :判断 Tag 是否包含属性















 1864
1864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









