







一. 包装类
1.1 包装类的引入
在 这篇博文 http://t.csdn.cn/jg7L6中提到过,八种基本数据类型都有自己对应的包装类
| 基本数据类型 | 包装类 |
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| char | Character |
| float | Float |
| double | Double |
| boolean | Boolean |
肯定有同学要问:这些包装类存在的意义是什么?
Java中一切皆对象,包装类让基本数据类型也面向了对象
先别开喷,我知道你内心的想法:

让我用个例子来解释一下
写一个方法,实现字符串转成整型
public static void main(String[] args) {
Scanner sc=new Scanner(System.in);
String s=sc.nextLine(); int a=Integer.parseInt(s);
}
写好啦!不仅如此,我还能直接用String.valueOf()再把整型转成String类呢!
当然在面试的时候这样写要被踹出去的,本博主想表达的意思是,如果只是一个朴实无华的int 类,能在类体内部提供各种方法吗?这时候包装类就十分有必要了
1.2 装包和拆包
顾名思义,装包,又称装箱,是指将基本数据类型转换成包装类
拆包,又称拆箱,是指将包装类转换成基本数据类型
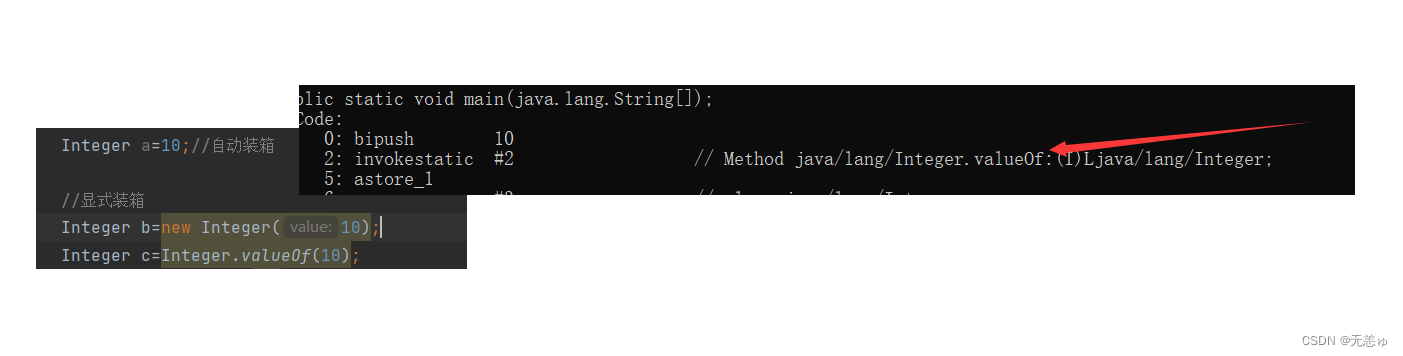
下面演示装包的方法
Integer a=10;//自动装箱
//显式装箱
Integer b=new Integer(10);
Integer c=Integer.valueOf(10);
实际上自动装箱底层也是valueOf方法
拆包同样也有显式和自动
int e=a;//自动拆包
int d=b.intValue();//显式拆包
不论显式还是隐式,都是调用的intValue方法

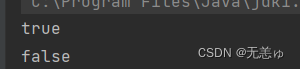
下面有一个so easy的问题,请你们来猜一下结果 
public static void main ( String [] args ) {Integer a = 127 ;Integer b = 127 ;Integer c = 128 ;Integer d = 128 ;System . out . println ( a == b );System . out . println ( c == d );}
是不是以为都是false?a,b,c,d都是对象嘛,都有自己的空间咯
但是编译器的运行结果并不是这样的
我们刚才提到过,自动转换的底层还是valueOf方法,现在来看看它的实现机制吧
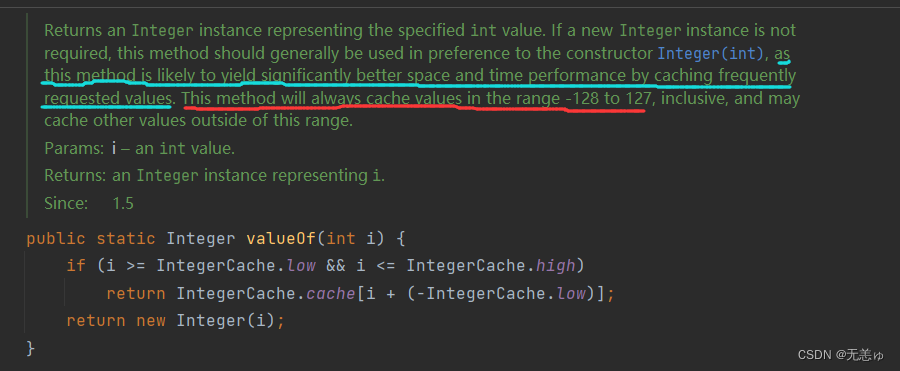
蓝线大意是说,为了更好地支配空间,会用缓存记载出现频率高的数字,红线的大意就是这些被Cache抓住的倒霉鬼就是[128,127]之间的数字
结合上文,我们就可以推断出IntegerCache.low==-128,IntegerCache.high==127,如果用自动装箱或用valueOf方法创造出来的对象在这个范围之内,会返回一个数组的元素(引用类型),所以a和b的地址是相同的
二. 泛型
2.1 什么是泛型
泛型是在 JDK1.5 引入的新的语法,通俗讲,泛型: 就是适用于许多许多类型 。从代码上讲,就是对类型实现了参数化。
我知道你又在OS:
所以我又要拿一个例子来解释
2.2 引出泛型
现在想实现一个数组,可以装下任意类型的数据
class MyArray {
public Object[] myArray=new Object[10];
//设置下标为pos的元素
public void setEle(int pos,Object val) {
myArray[pos]=val;
}
//获取下标为pos的元素
public Object getEle(int pos) {
return myArray[pos];
}
}于是就可以往里面存任意类型的数据了
public class Test {
public static void main(String[] args) {
MyArray array=new MyArray();
array.setEle(0,"abcdef");
array.setEle(1,36);
}
}但是正所谓一时存一时爽,想要取出来就麻烦了
因为存在向下转型,编译器认为这是不安全的,所以必须强转
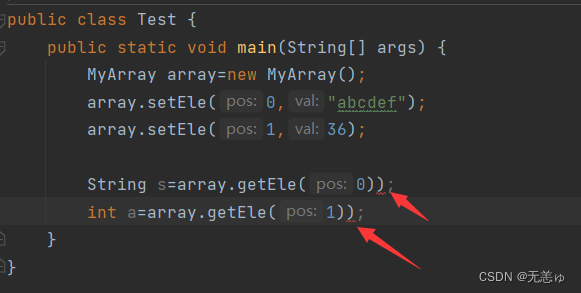
但是又有一个问题了,如果有100个,1000个..我怎么能把所有元素的类型都记住呢?
所以我的问题又变了,请实现一个数组,可以存储任意类型但类型唯一的数据
这时候我们就可以把类型当做参数一样传进去,让当前数组只存储这一个类型的对象
2.3 泛型的语法
格式1:class 泛型类名称 < 类型形参列表 > {// 这里可以使用类型参数}//举例class ClassName < T1 , T2 , ..., Tn > {//T是一个占位符,表示当前参数是一个类型}
格式2:class 泛型类名称 < 类型形参列表 > extends 继承类 /* 这里可以使用类型参数 */ {// 这里可以使用类型参数}//举例class ClassName < T1 , T2 , ..., Tn > extends ParentClass < T1 > {// 可以只使用部分类型参数}
现在我们来实现一下刚才的数组
class MyArray<T>{
public Object[] myArray=new Object[10];//此处不能T[] myArray=new T[10]
下文会解释
//设置下标为pos的元素
public void setEle(int pos,T val) {
myArray[pos]=val;
}
//获取下标为pos的元素
public T getEle(int pos) {
return (T)myArray[pos];
}
}接着就可以创造多个数组存储多种数据类型的元素了
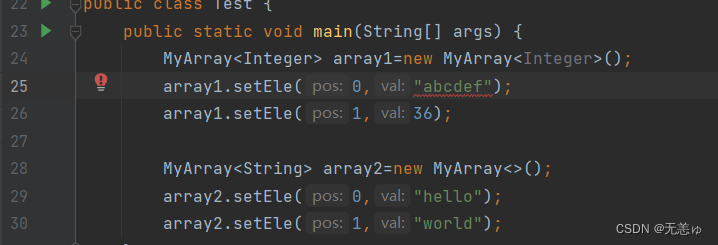
注意看,如果使用Integer定义的数组来存储String类型,编译器就会报错,这也是使用泛型的好处
接下来强调几个注意点:
- 第24行的第一个MyArray<Integer>中的Integer不可以省略,但new之后的Integer可以省略(因为编译器会自动推导)
- 泛型类传入的类型参数不能是基本数据类型,只能是包装类或自定义类型
2.4 裸类型(Raw type)
裸类型是一个泛型类但没有带着类型实参
再把刚才的例子拿过来
public class Test {
public static void main(String[] args) {
MyArray array3=new MyArray();
array.setEle(0,"abcdef");
array.setEle(1,36);
}
}在定义泛型类MyArray之后,这个array3对象也是可以创建的,它是为了兼容老版本保留的机制
2.5 泛型是如何编译的
泛型的转换和检查(对象是否合法)会在编译的时候进行,所以JVM运行的时候不会出现泛型的概念
2.5.1 擦除机制
那么泛型类的定义在编译的时候会转换成什么呢?
我们借助反汇编来看一下
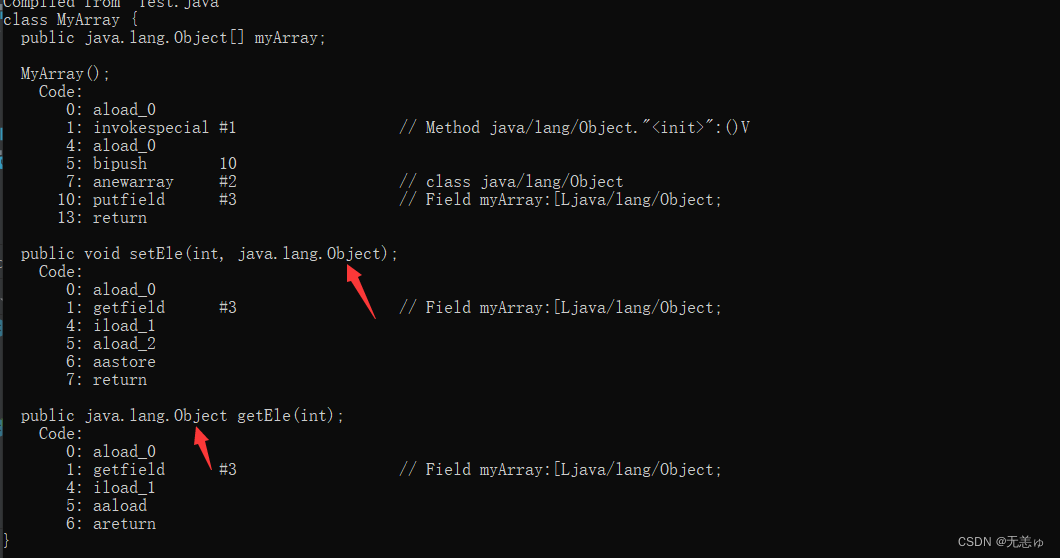
可以看到,在setEle方法里,传入的参数是T类型,编译的时候转换成了Object类,在getEle方法里,返回的是T类型,编译的时候也转换成了Object类
在编译的过程当中,将所有的T替换为Object这种机制,我们称为:擦除机制。
现在来解决刚才产生的一个问题:既然在编译的时候所有的T都会转换成Object,为什么new T[10]不能转换成new Object[10]然后通过编译呢?
因为数组有自己的规定,在实例化时必须指定类型
2.5.2 泛型数组埋的坑
现在想实现一个方法,可以获得MyArray类中的数组
class MyArray<T>{
public Object[] myArray=new Object[10];
//设置下标为pos的元素
public void setEle(int pos,T val) {
myArray[pos]=val;
}
//获取下标为pos的元素
public T getEle(int pos) {
return (T)myArray[pos];
}
//获取数组
public T[] getArray() {
return (T[])myArray;
}
}
public class Test {
public static void main(String[] args) {
MyArray<Integer> array1=new MyArray<Integer>();
Integer[] array2= array1.getArray();//获取array1的数组
}
}
上面的代码编译的时候可以通过,把myArray通过向下转型赋给了array2,但是在运行的时候会抛异常
![]()
这是因为数组的检查是比较严格的,如果myArray数组存储了String,Double等其他类型,向下转型是十分不安全的。总之,数组对象不能向下转型
针对这个问题,可以使用反射解决,下面提供解决方式(以后再讲原理)
class MyArray<T>{
public T[] myArray;
public MyArray(Class<T> type,int capacity) {//第一个参数type传入类型,第二个参数传入容量
myArray=(T[]) Array.newInstance(type,capacity);
}
//设置下标为pos的元素
public void setEle(int pos,T val) {
myArray[pos]=val;
}
//获取下标为pos的元素
public T getEle(int pos) {
return (T)myArray[pos];
}
public T[] getArray() {
return myArray;//此处不需要强转,因为数组类型本来就是T[]
}
}
public class Test {
public static void main(String[] args) {
MyArray<Integer> array1=new MyArray<>(Integer.class,20);
Integer[] array2=array1.getArray();//获取array1的数组
for(int i=0;i<array2.length;i++) {
array2[i]=i;//给每个数组元素赋值
}
System.out.println(array1.getEle(2));//获取下标为2的元素
}
}
//输出结果为2但是在实际开发过程中,我们的解决方式往往不是上面这种,而是借鉴了源码
下面是ArrayList类的源码

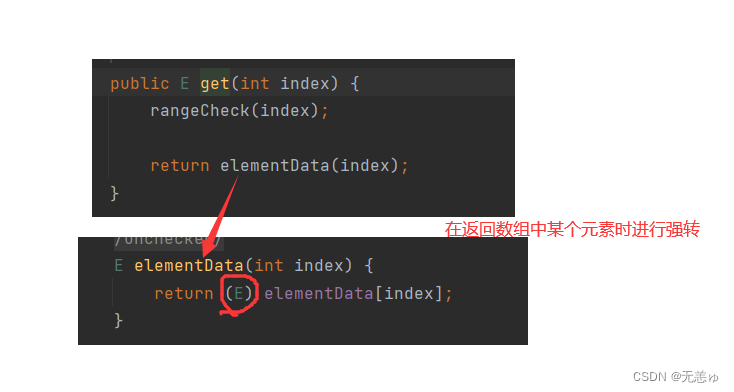

所以根据源码修改后的MyArray如下
class MyArray<T>{
public Object[] myArray=new Object[10];
//设置下标为pos的元素
public void setEle(int pos,T val) {
myArray[pos]=val;
}
//获取下标为pos的元素
public T getEle(int pos) {
return (T)myArray[pos];
}
public Object[] getArray() {
return myArray;
}
}
public class Test {
public static void main(String[] args) {
MyArray<Integer> array1=new MyArray<>();
Object[] array2=array1.getArray();//只能用Object类型数组接收
for(int i=0;i<array2.length;i++) {
array2[i]=i;
}
System.out.println(array1.getEle(2));
}
}
2.6 泛型的上界
2.6.1 为什么需要泛型上界
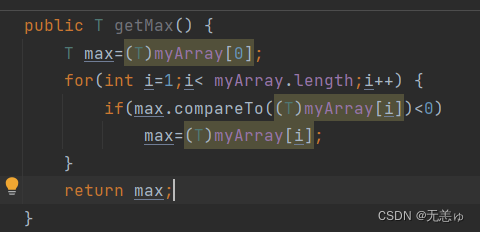
在刚才的MyArray类中定义一个方法,可以找出myArray的最大值

可以看到有多处爆红,因为可能传入String,Boolean等不能直接用比较运算符进行比较的类型,于是我们想到了使用Comparable接口中提供的compareTo方法
但是使用compareTo方法就意味着这个类必须实现Comparable接口,于是我们在类型参数列表加个限制
![]()
2.6.2 泛型上界的语法
class 泛型类名称 < 类型形参 extends 类型边界 > {...}
类型边界可以是某个类,表示传入的类型参数必须是这个类或者这个类的子类
类型边界也可以是某个接口,表示传入的类型参数必须实现了这个接口
究其原理,泛型上界让编译器在编译的时候把T替换成上界允许的类型,而不是单纯的Object类
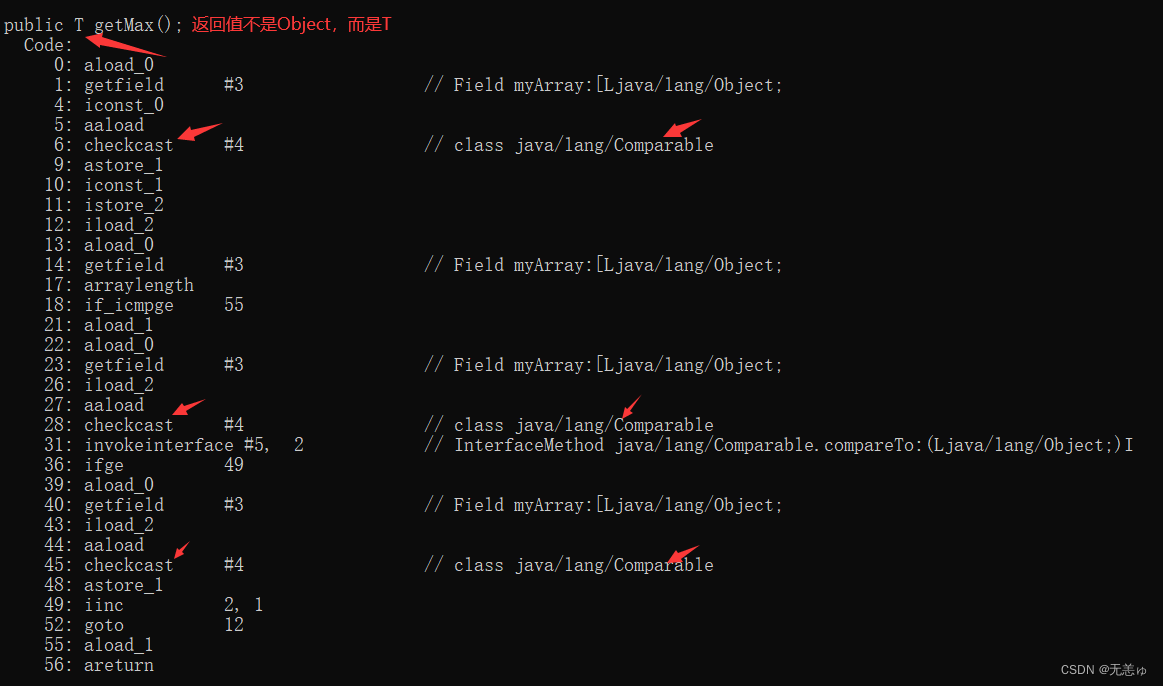
2.7 泛型方法
泛型方法是指能处理指定类型的方法
定义在泛型类中的方法都是泛型方法,都可以根据泛型类传入的类型参数处理该类型的数据
但是如果这个类是个普通类,怎么在它内部定义泛型方法呢?
定义语法
方法限定符 <类型形参列表> 返回值类型 方法名称(形参列表) { ... }
示例:
class GetMax {//定义一个普通类,用来提供geMax方法
public static<T extends Comparable<T>> T getMax(T a,T b) {//可以对传入的参数类型添加上界
if(a.compareTo(b)>0) return a;
return b;
}
}
public class Test {
public static void main(String[] args) {
int max1=GetMax.getMax(10, 20);//调用GetMax类中的静态方法,它会根据参数类型自动推导
int max2=GetMax.<Integer>getMax(20,60);
}
}
//max1=20,max2=60















 2379
2379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











