









文章目录
string
string是字符串,因为文字的特殊性,所以字符串被封装成了一个类。并且为了适应全球多种不同语言,string的开发路程很复杂。
1.开发路程
起初,计算机的研发美国领先,为了提供给非研发人员使用,所以需要将文字,转换成二进制数字供人机交互,ASCII码诞生

用1个字节,所能表示的范围是128个,每个都对应一个字符。
但是因为,有不同的语言,不可能所有语言都使用ASCII码,所以出现了
Unicode,万国码

而Unicode其中有一个兼容ASCII的编码—— UTF-8


UTF-8是用2个字节存储字符,本来1个字节足以存储英文字符,但是欧洲,亚洲,非洲的语言种类更多,1个字节无法记录,所以另加一个字节来存储。
而汉语的转换,我国编写了,一个GBK来适配汉语的转化

小现象
string s2("你好");
你好在计算机的存储是这样的

因为需要兼容ASCII码,所以汉语的存储不能用ASCII码的那些正数,使用了负数
其中[0]和[1]代表 “你”,[2]和[3]代表 “好”。2个字节存储一个汉字。
PS:常见的汉字都是2个字节表示,但因为汉字之多,所以一些偏僻字使用3个字节存储
2.string模板

最开始的string是basic_string,是一个类模板,为了应对传入的不同类型。basic_string有几个实例化版本

第一个是最常用的char版本,u16string是将字符统一用16个byte,也就是2个字节存储,而u32string则是用4个字节存储,但是4个字节对于绝大多数语言,空间其实是很浪费的,就像英文原本只需要1个字节,大多数中文也只要2个字节,统一用4个字节存储就会造成很多的浪费。
wstring和string的区别,详情见大佬博文
千百元的wstring是什么?跟string有什么区别
3.string的使用
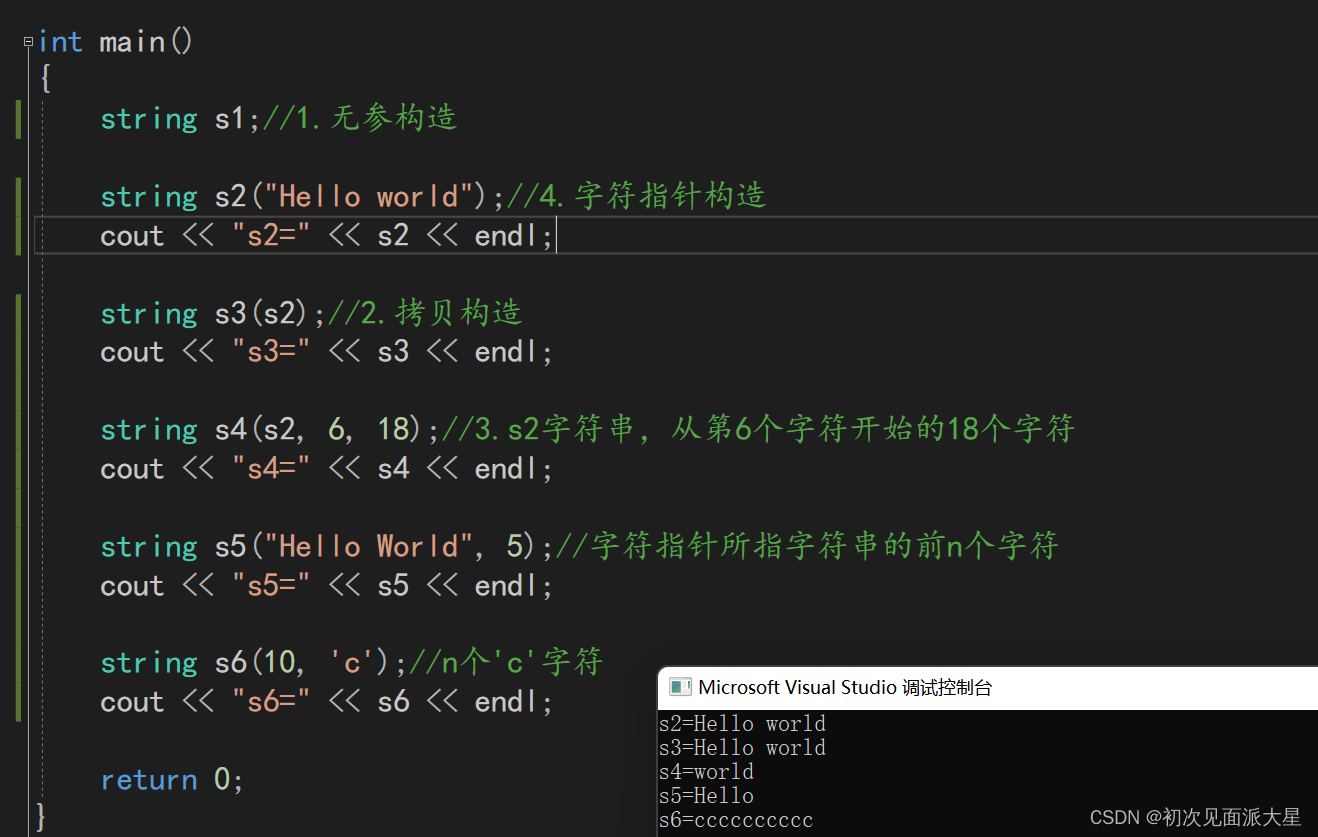
一. 构造函数

string的构造函数由7个,较为常用的是第一个无参构造和第四个,第二个为拷贝构造
第一个:无参构造
第二个:拷贝构造
第三个:拷贝构造(拷贝str字符串,从pos位置开始的len个字符)npos是缺省参数。无符号的-1,实际值为42亿9千万多。如果pos超出str长度,会拷贝到最后)
第四个:构造函数,传参是字符指针所指的字符串
第五个:构造函数,传参是字符指针所指的字符串的前n个字符
第六个:n个字符 ‘c’
第七个:内含迭代器,以后补充
二. 操作
目前先学习其中的几个

size&length
size和length都是返回字符串的长度的,功能相同。
为什么会有两个相同的功能函数?因为string原先不是STL的,最先定义的是length,但是后来被归入STL,为了和其他的容器相统一,又编写了size。

因为VS不算最后的\0,所以显示11,其实长度是12。max_size
max_size返回string的最大长度,没什么价值

capacity
capacity返回当前string的容量(因为容量是动态开辟的,类似C语言实现的栈)
PS:不同平台的扩容规则不同,存储也不同
VS的string扩容
string其实有两个存储数据的东西,_Buf和_Ptr


_Buf是一个16字节的数组,_Ptr是字符指针。
当初始化的字符个数大于16时,才用_Ptr动态开辟,不然存储在_Buf中。
VS的string整体扩容是1.5倍扩容
reserve扩容(提前扩容,减少后续系统扩容,增加效率)

resize扩容+初始化
 如果指定的大小比原先的容量大,则扩容,初始化是用缺省值。(可自定义初始化的字符)
如果指定的大小比原先的容量大,则扩容,初始化是用缺省值。(可自定义初始化的字符)


若容量比原先小,那么只改变size,因为缩减容量代价很高。相当于删除数据(因为访问不到)

三. 修改

-
push_back和append
push_back是一个字符一个字符的插入
append是插入字符串

-
+=运算符重载

+=运算符重载,相同于是push_back和append的封装,可以使用二者的功能

四. 遍历
- string有三种遍历的方法
方法一:
[]运算符重载
string s1("hello world");
for (int i = 0; i < s1.size(); i++)
{
cout << s1[i] << " ";
}
cout << endl;
方法二:
迭代器iterator
我们可以暂时将其理解成指针,具体认识会在之后的模拟实现学习
string s1("hello world");
string::iterator it = s1.begin();
while (it != s1.end())
{
cout << *it << " ";
it++;
}
方法三:
范围for
范围for的底层其实也是使用迭代器
string s1("hello world");
for (auto ch : s1)
{
cout << ch << " ";
}
cout<<endl;
五. 认识string的迭代器
iterator正向迭代器
string s1("hello world");
string::iterator it = s1.begin();
while (it != s1.end())
{
cout << *it <<" ";
++it;
}
cout << endl;
iterator是string封装的一个类。此处我们可以把他理解为一个指针
查阅文献:


begin和end的返回值是iterator,我们此处理解为指针,begin指向string的首元素,end指向string的最后一个元素的下一个。这样最后的元素才可以被访问到

iterator是正向迭代器,那么就有反向迭代器
reverse_iterator反向迭代器
string::reverse_iterator rit = s1.rbegin();
while (rit != s1.rend())
{
cout << *rit << " ";
rit++;
}
cout << endl;
此时,反向迭代意味着反向遍历


rbegin和rend的返回值是reverse_iterator,对应反向遍历
rbegin指向的位置是string的最后一个元素,rend指向的是string的首元素的前一个元素
注意:反向迭代器的移动依然是++

const迭代器
const_iterator和const_reverse_iterator
仔细看begin和end等的返回值,其实还有一个const的迭代器
这是因为,前两个迭代器既可以读,也可以写,但是总会有不让改动的string,所以产生了const迭代器,适配const的string
void Fun(const string &s)
{
string::const_iterator it = s.begin();
while (it != s.end())
{
cout << *it << " ";
++it;
}
cout << endl;
string::const_reverse_iterator rit = s.rbegin();
while (rit != s.rend())
{
cout << *rit << " ";
rit++;
}
cout << endl;
}
PS:因为类型名过长,我们可以使用auto去自动识别类型
六. inert&erase
随机插入和随机删除


insert提供了很多函数重载的版本
(1)在pos位置,插入另一个string
(2)在pos位置,插入另一个从subpos位置开始,长度为sublen的string的子串,若sublen访问超出string长度,只会访问到最后一个
(3)在pos位置,插入常量字符串
(4)在pos位置,插入常量字符串的前n个字符串
(5)在pos位置,插入n个c
6和7位迭代器,暂时不作了解
例子:
int main()
{
string s1("hello");
cout << s1 << endl;
string s2("world");
//(1)在pos位置,插入另一个string
s1.insert(5,s2);
cout << s1 << endl;
//(2)在pos位置,插入另一个从subpos位置开始,长度为sublen的string的子串
//若sublen访问超出string长度,只会访问到最后一个
string s3("i love you");
s1.insert(10, s3, 2, 4);
cout << s1 << endl;
//(3)在pos位置,插入常量字符串
s1.insert(5, " ");
cout << s1 << endl;
//(4)在pos位置,插入常量字符串的前n个字符串
s1.insert(11, " love", 1);
cout << s1 << endl;
//(5)在pos位置,插入n个c
s1.insert(11, 6, 'i');
cout << s1 << endl;
}

erase
(1)从pos位置开始(缺省值为0),删除len个(缺省值是npos,无符号-1)
PS:npos是静态成员变量,可以直接通过类名访问。string::npos


七. replace

replace
(1)把从pos位置开始的len个字符,替换成str
(2)把从pos位置开始的len个字符,替换成str的从subpos位置开始,sublen个字符
(3)把从pos位置开始的len个字符,替换成常量字符串
(4)把从pos位置开始的len个字符,替换成常量字符串的前n个字符
(5)把从pos位置开始的len个字符,替换成n个c

八. find&substr&rfind
find
-find相当于查找子串,但是默认他只是返回第一个子串的位置。不过可以指定从pos位置开始查找,也可以指定从pos位置往后查找几个。
实际用例:截取后缀
substr

获取字符串的子串,返回从pos位置开始(缺省值为0),len个字符的字符串(缺省值是npos)
rfind

从后往前查找
截取真实后缀

九. c_str

返回C语言形式的指针
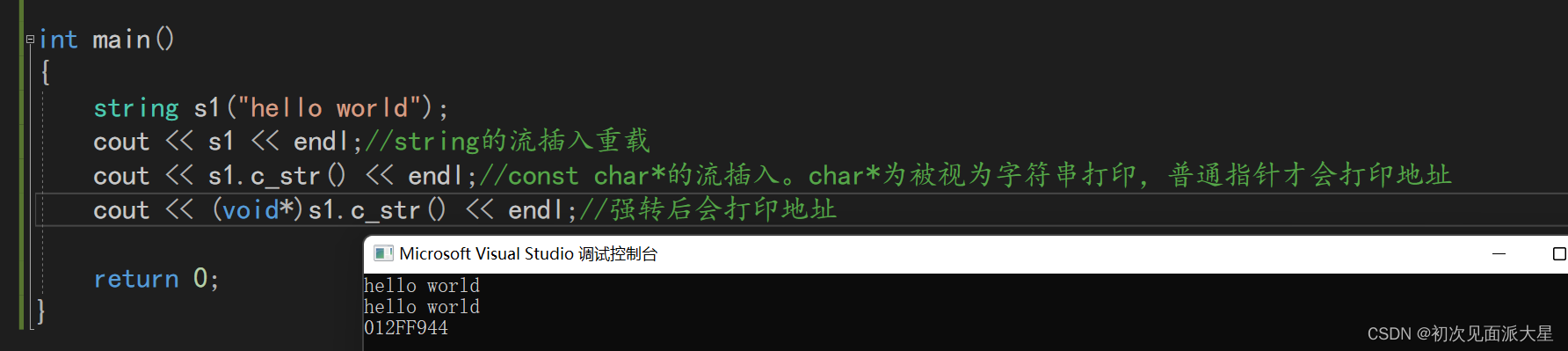
在输入时,string实例化的对象时char*,会被识别为字符串输出,无法输出地址
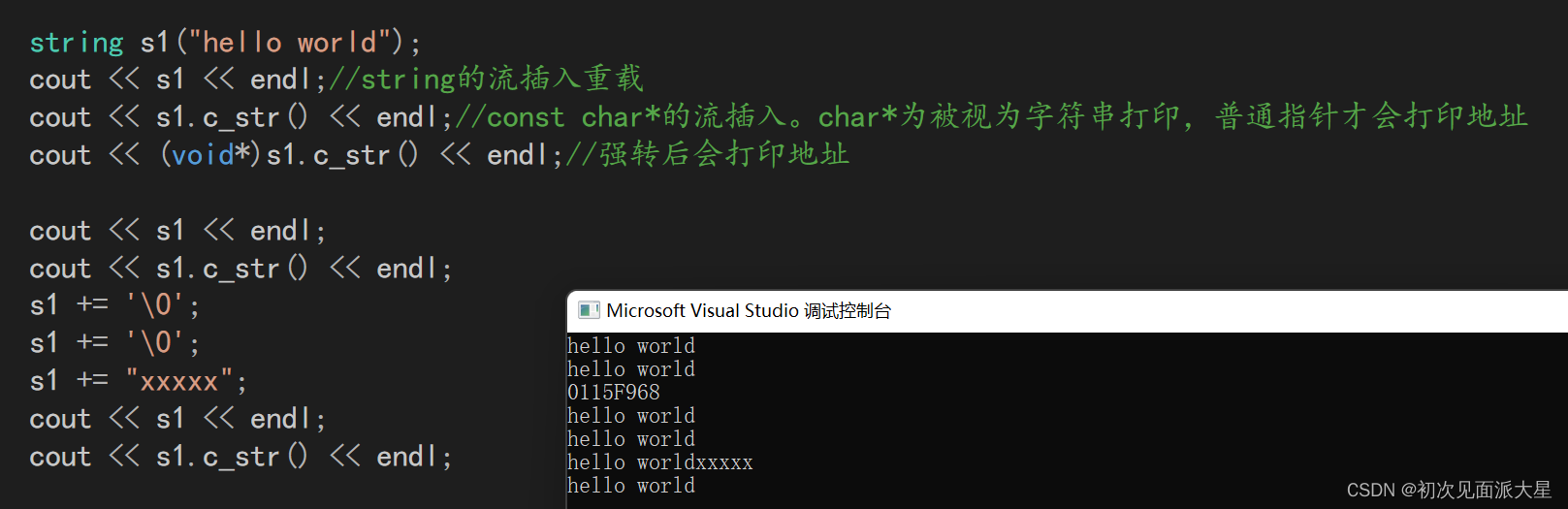
另外在识别上也有区别,打印s1,是按照size的大小去打印的。
但是打印s1.c_str是按照 ’ \0 '打印的
十. find_first_of&find_last_of
find_first_of

(1)从pos位置开始,找寻string中第一个str里的字符(任意一个都可以)
(2)从pos位置开始,找寻string中第一个s里的字符(任意一个都可以)
(3)从pos位置开始,找寻string中第一个s里的字符(s的前n个)
(4)从pos位置开始,找寻string中第一个c字符
例子

将str中的所有abcdv都替换成*
find_last_of
和find_first_of类似,不过是从尾开始查找,然后返回第一个。
十一. getline
- getline是解决字符串输入结束标志判断的std函数
 cin和scanf判断字符串是否结束是通过\0和换行判断的
cin和scanf判断字符串是否结束是通过\0和换行判断的

但我们实际想要的是hello world,所以此时scanf和cin显然完成不了。getline就是解决这一问题

string的使用暂时学到这,后续会再补充。本章用于记笔记,如果有不对或者不足的地方,欢迎大佬们指正,补充。感谢大家的阅读,如果感觉博主写的还可以,麻烦点个赞支持一下,阿里嘎多。
















 1270
1270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









