






Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
Neo4j因其嵌入式、高性能、轻量级等优势,越来越受到关注.
Neo是一个网络——面向网络的数据库——也就是说,它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络上而不是表中。网络(从数学角度叫做图)是一个灵活的数据结构,可以应用更加敏捷和快速的开发模式。
Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下,而不是严格、静态的表中。但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。Neo4j因其嵌入式、高性能、轻量级等优势,越来越受到关注。
现实中很多数据都是用图来表达的,比如社交网络中人与人的关系、地图数据、或是基因信息等等。RDBMS并不适合表达这类数据,而且由于海量数据的存在,让其显得捉襟见肘。NoSQL数据库的兴起,很好地解决了海量数据的存放问题,图数据库也是NoSQL的一个分支,相比于NoSQL中的其他分支,它很适合用来原生表达图结构的数据。
通常来说,一个图数据库存储的结构就如同数据结构中的图,由顶点和边组成。
Neo4j是图数据库中一个主要代表,其开源,且用Java实现(需安装JDK)。经过几年的发展,已经可以用于生产环境。其有两种运行方式,一种是服务的方式,对外提供REST接口;另外一种是嵌入式模式,数据以文件的形式存放在本地,可以直接对本地文件进行操作。
Neo4j分三个版本:社区版(community)、高级版(advanced)和企业版(enterprise)。社区版是基础,本文主要对其作出介绍,它使用的是GPLv3协议,这意味着修改和使用其代码都需要开源,但是这是建立在软件分发的基础上,如果使用Neo4j作为服务提供,而不分发软件,则不需要开源。这实际上是GPL协议本身的缺陷。高级版和企业版建立在社区版的基础上,但多出一些高级特性。高级版包括一些高级监控特性,而企业版则包括在线备份、高可用集群以及高级监控特性。要注意它们使用了AGPLv3协议,也就是说,除非获得商业授权,否则无论以何种方式修改或者使用Neo4j,都需要开源。
设计理念
Neo4j的设计动机是为了更好地同时也更高效地描述实体之间的关系。在现实生活中,每一个实体都于周围的其他实体有着千丝万缕的关系,这些关系里面所存储的信息甚至要大于身体本身的属性。然后传统的关系型数据库更注重刻画实体内部的属性,实体与实体之间的关系通常都是利用外键来实现。所以在求解关系的时候通常需要join操作,而join操作通常又是耗时的。互联网尤其是移动互联网的爆发式增长本来就使得传统关系型数据库不堪重负,再加上诸如社交网络等应用对于关系的高需求,可以说关系型数据库已经是毫无优势。而图数据库作为重点描述数据之间关系的数据库应运而生,成为了NoSQL中非常重要的一部分。而Neo4j正是图数据库中最为优秀的之一。
Neo4j特点
所用语言: Java
特点:基于关系的图形数据库 使用许可: GPL,其中一些特性使用 AGPL/商业许可 协议: HTTP/REST(或嵌入在 Java中) 可独立使用或嵌入到 Java应用程序 图形的节点和边都可以带有元数据 很好的自带web管理功能 使用多种算法支持路径搜索 使用键值和关系进行索引为读操作进行优化 支持事务(用 Java api) 使用 Gremlin图形遍历语言支持 Groovy脚本 支持在线备份,高级监控及高可靠性支持使用 AGPL/商业许可。
Neo4j相关特性
数据模型
Neo4j被称为property graph,除了顶点(Node)和边(Relationship,其包含一个类型),还有一种重要的部分——属性。无论是顶点还是边,都可以有任意多的属性。属性的存放类似于一个hashmap,key为一个字符串,而value必须是Java基本类型、或者是基本类型数组,比如说String、int或者int[]都是合法的。
索引
Neo4j支持索引,其内部实际上通过Lucene实现。
事务
Neo4j完整支持事务,即满足ACID性质。
ACID是以下四个事务特性的缩写:
- 原子性
一个事务的所有工作要么都(成功)执行,要么都不执行。不会发生只执行一部分的情况。
比如说,一个事务开始更新100行记录,但是在更新了20行之后(因为某种原因)失败了,那么此时数据库会回滚(撤销)对那20条记录的修改。
- 一致性
事务将数据库从一个一致性状态带入另一个一致性状态。
比如说,在一个银行事务(在描述关系数据库事务的特性时,基本上都是用银行事务来作为描述对象的)中,需要从存储账户扣除款项,然后在支付账户中增加款项。
如果在这个中转的过程发生了失败,那么绝对不能让数据库只执行其中一个账户的操作,因为这样会导致数据处于不一致的状态(这样的话,银行的账目上,借贷就不平衡了)。
- 隔离性
这个特性是说,直到事务结束时(commit/rollback),其他事务(或者会话)对此事务所操作的数据都不可见(但并不是说其他会话的读取会被阻塞)。
比如说,一个用户正在修改hr.employees表,但是没有提交,那么其他用户在这个修改没有提交之前是看不到这个修改的。
- 永久性
被提交的更改会永久地保存到数据库中(并不是说以后就不可以修改)。
事务提交之后,数据库必须通过“恢复机制”来确保事务更改的数据不会丢失。
遍历和查询
遍历是图数据库中的主要查询方式,所以遍历是图数据中相当关键的一个概念。可以用两种方式来进行遍历查询:第一种是直接编写Java代码,使用Neo4j提供的traversal框架;第二种方式是使用Neo4j提供的描述型查询语言,Cypher。
图算法
Neo4j实现的三种图算法:最短路径(最少数目的关系)、Dijkstra算法(解决有向图中任意两个顶点之间的最短路径问题)以及A*算法(是解决静态路网中求解最短路最有效的方法)。
嵌入式可扩展
Neo4j是一个嵌入式,基于磁盘的,支持完整事务的Java持久化引擎,它在图像中而不是表中存储数据。Neo4j提供了大规模可扩展性,在一台机器上可以处理数十亿节点、关系、属性的图像,可以扩展到多台机器并行运行。相对于关系数据库来说,图形数据库善于处理大量复杂、互连接、低结构化的数据,这些数据变化迅速,需要频繁的查询——在关系数据库中,这些查询会导致大量的表连接,因此会产生性能上的问题。Neo4j重点解决了拥有大量连接的传统RDBMS在查询时出现的性能衰退问题。通过围绕图形进行数据建模,Neo4j会以相同的速度遍历节点与边,其遍历速度与构成图形的数据量没有任何关系。
Neo4j与传统数据库的区别
| Neo4j | RDBMS |
|---|---|
| 允许对数据的简单且多样的管理 | 高度结构化的数据 |
| 数据添加和定义灵活,不受数据类型和数量的限制,无需提前定义 | 表格schema需预定义,修改和添加数据结构和类型复杂,对数据有严格的限制 |
| 常数时间的关系查询操作 | 关系查询操作耗时 |
| 提出全新的查询语言cypher,查询语句更加简单 | 查询语句更为复杂,尤其涉及到join或union操作时 |
最后再以下面两张图来展示一下两者在查询关系时的区别:
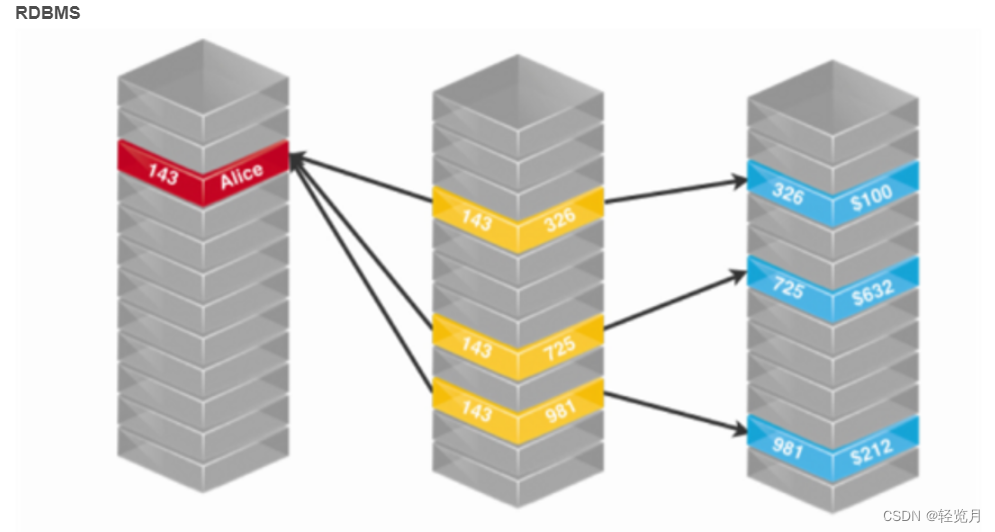
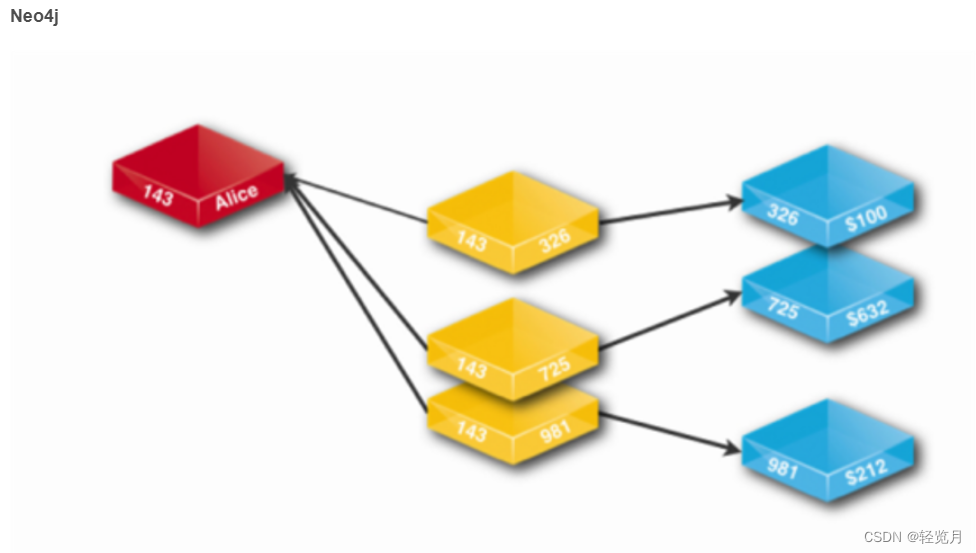
Neo4j集群模式运行原理
一个Neo4J HA集群的协作运行,协调行为是通过zookeeper完成的。2.0以后基于Paxos协议开发了自己的集群协调机制。
当一个Neo4j HA实体开启时将去连接协调器服务(zookeeper)注册其本身并询问“谁是主机(master)?”。如果某个机器是主机,新的实体将以从机(slaver)开启并连接到主机(master)。如果机器开启时为第一个注册或者通过主机选择算法应该成为主机,将会作为主机开启。
当从一个从机上执行一个写入的事务时,每个写入操作将与主机同步(主机与从机将被锁定)。当事务提交时首先存在于主机上。当主机事务提交成功,从机上的事务也会被提交。为确保一致性,在执行写入操作前从机与主机同步必须是最新的。这是建立主机与从机之间的通讯协议,所以如果需要,更新将会自动发生。
可以通过在包含ha.slave_coordinator_update_mode=none配置参数的配置文件中将数据库实体设置成只做为从机。此实体虽然在系统故障恢复选择时将不可能再成为主机,然而此从机的行为与其他所有从机都一样,含有永久写入到主机的能力。
当从主机上执行写入操作,它将与在普通的嵌入模式中执行一样。此时主机将不会推送更新消息到从机。相反,从机可以配置一个拉取消息的时间间隔。没有选举,更新操作仅仅只会发生在从机上,任何时候都将同步一个写入到主机。
将所有写入操作通过从机执行的好处是数据将被复制到两台机器上。这是建议的,避免当新选主机时可能造成回滚失败。
当某台neo4j数据库服务不可用时,协调器(coordinator)将探测到并从集群中删除掉。当主机当机时,新的主机将自动被选择出来。一般地,一个新的主机被选定并在几秒钟内启动,在这段时间将不会执行任何写入操作(写入将抛出异常)。当某台机器从故障中恢复了,将会被自动重新连接到集群中。当没有得到其他任何机器的备份的旧的主机改变时, 是唯一不确定的。如果新的主机被选择并在旧的主机恢复前执行改变,将会有两个不同版本的数据。旧主机将移除分支数据库并从新主机下载一个全版本的数据。
Ø 所有这些可以归纳如下:
Ø 从机可以处理写入事务。
Ø 更新相对从机最终将会一致。
Ø Neo4j HA 是一个容错并能继续执行从x台机器到单独一台机器(基于zookeeper设置)。
Ø 在写入操作上从机将自动同步到主机。
Ø 当主机故障时新的主机将自动选出。
Ø 当任何导致运行中断的错误(网络、维护)解决时当台机器将会自动被重新连接到集群中。
Ø 事务的原子性、持久性和一致性并最终会广播到其他从机上。
Ø 主机故障了,所有正在运行写入事务将会被回滚,主机选举时任何写入操作都不能执行。
Ø 读取操作高度可用。
Neo4j优缺点
优点:
-
数据的插入,查询操作很直观,不用再像之前要考虑各个表之间的关系。
-
提供的图搜索和图遍历方法很方便,速度也是比较快的。
-
更快的数据库操作。当然,有一个前提条件,那就是数据量较大,在MySql中存储的话需要许多表,并且表之间联系较多(即有不少的操作需要join表)。
缺点:
-
当数据过大时插入速度可能会越来越慢。.
-
超大节点。当有一个节点的边非常多时(常见于大V),有关这个节点的操作的速度将大大下降。这个问题很早就有了,官方也说过会处理,然而现在仍然不能让人满意。
-
提高数据库速度的常用方法就是多分配内存,然而看了官方操作手册,貌似无法直接设置数据库内存占用量,而是需要计算后为其”预留“内存…
注:鉴于其明显的优缺点,Neo4j适合存储”修改较少,查询较多,没有超大节点“的图数据。
应用场景
适用于图形一类数据。这是 Neo4j与其他nosql数据库的最显著区别
例如:社会关系,公共交通网络,地图及网络拓谱。
Neo4j不适用于:
记录大量基于事件的数据(例如日志条目或传感器数据)
对大规模分布式数据进行处理,类似于Hadoop
二进制数据存储
适合于保存在关系型数据库中的结构化数据
Neo4j安装部署
Neo4j有两种访问模式:服务器模式和嵌入模式。在这里咱们只单纯介绍一下服务器安装模式。注:仅有企业付费版支持HA模式,免费试用30天。
Windows服务安装
-
到官网下载对应版本的Neo4j安装包
-
将安装包放到指定的目录下
-
NEO4J_HOME配置
-
运行:bin\Neo4j.bat install
-
查询服务状态:bin\Neo4j.bat status
-
开启服务:bin\Neo4j.bat start
-
停止服务:bin\Neo4j.bat stop
-
卸载命令:bin\Neo4j.bat remove
注:如果webadmin不工作请尝试禁用防火墙。
运行Neo4j后,在浏览器中打开网页:http://localhost:7474(https的端口是7473), 即可进入Neo4j的图形操作界面,在里面可以直接操作数据库,也可以查看数据库的状态。
页面顶端可以直接写Cypher语句并运行。右侧则显示一些数据库的状态以及提供一部分操作,包括:
-
Database Information。数据库信息。节点类别,边的类别,属性(包括节点的属性和边的属性)。
-
Favorites。写好的基本数据库语句,包括创建节点,查询节点个数,边个数等。创建示例图。查看数据库的状态。
-
Documentation。各种官方文档。
-
Neo4j Browser Sync。清空本地数据库。与云端数据库同步。
-
Browser Settings。图形操作界面的设置。
Neo4j集群模式介绍
在了解了如何使用Neo4J之后,下一步要考虑的就是如何通过搭建一个Neo4J集群来提供一个具有高可用性,高吞吐量的解决方案了。首先您要知道的是,和其它NoSQL数据库所提供的近乎无限的横向扩展能力相比,Neo4J集群实际上是有一定限制的。为了能更好地理解这些限制,就让我们首先看一看Neo4J集群的架构以及它到底是如何工作的:
通常情况下,每个Neo4J集群都包含一个Master和多个Slave。该集群中的每个Neo4J实例都包含了图中的所有数据。这样任何一个Neo4J实例的失效都不会导致数据的丢失。集群中的Master主要负责数据的写入,接下来Slave则会将Master中的数据更改同步到自身。如果一个写入请求到达了Slave,那么该Slave也将会就该请求与Master通信。此时该写入请求将首先被Master执行,再异步地将数据更新到各个Slave中。所以在上图中,您可以看到表示数据写入方式的红线有从Master到Slave,也有从Slave到Master,但是并没有从Slave到Slave。而所有这一切都是通过Transaction Propagation组成来协调完成的。
有些读者可能已经注意到了:Neo4J集群中数据的写入是通过Master来完成的,那是不是Master会变成系统的写入瓶颈呢?答案是几乎不会。首先是图数据修改的复杂性导致其并不会像栈,数组等数据类型那样容易被修改。在修改一个图的时候,我们不但需要修改图结点本身,还要维护各个关系,本身就是一个比较复杂的过程,对用户而言也是较难理解的。因此对图所进行的操作也常常是读比写多很多。同时Neo4J内部还有一个写队列,可以用来暂时缓存向Neo4J实例的写入操作,从而使得Neo4J能够处理突然到来的大量写入操作。而在最坏的情况就是Neo4J集群需要面对持续的大量的写入操作。在这种情况下,我们就需要考虑Neo4J集群的纵向扩展了,因为此时横向扩展无益于解决这个问题。
反过来,由于数据的读取可以通过集群中的任意一个Neo4J实例来完成,因此Neo4J集群的读吞吐量可以在理论上做到随集群中Neo4J实例的个数线性增长。例如如果一个拥有5个结点的Neo4J集群可以每秒响应500个读请求,那么再添加一个结点就可以将其扩容为每秒响应600个读请求。
但在请求量非常巨大而且访问的数据分布非常随机的情况下,另一个问题就可能发生了,那就是Cache-Miss。Neo4J内部使用一个缓存记录最近所访问的数据。这些缓存数据会保存在内存中以便快速地响应数据读取请求。但是在请求量非常巨大而且所访问数据分布随机的情况下,Cache-Miss将会持续地发生,使得每次对数据的读取都要经过磁盘查找来完成,从而大大地降低了Neo4J实例的运行效率。而Neo4J所提供的解决方案被称为Cache-based Sharding。简单地说,就是使用同一个Neo4J实例来响应一个用户所发送的所有需求。其背后的原理也非常简单,那就是同一个用户在一段时间内所访问的数据常常是类似的。因此将这个用户的一系列数据请求发送到同一个Neo4J服务器实例上可以很大程度上降低发生Cache-Miss的概率。
Neo4J数据服务器中的另一个组成Cluster Management则用来负责同步集群中各个实例的状态,并监控其它Neo4J结点的加入和离开。同时其还负责维护领导选举结果的一致性。如果Neo4J集群中失效的结点个数超过了集群中结点个数的一半,那么该集群将只接受读取操作,直到有效结点重新超过集群结点数量的一半。
在启动时,一个Neo4J数据库实例将首先尝试着加入由配置文件所标明的集群。如果该集群存在,那么它将作为一个Slave加入。否则该集群将被创建,并且其将被作为该集群的Master。
如果Neo4J集群中的一个Neo4J实例失效了,那么其它Neo4J实例会在短时间内探测到该情况并将其标示为失效,直到其重新恢复到正常状态并将数据同步到最新。这其中有一个特殊情况,那就是Master失效的情况。在该情况下,Neo4J集群将会通过内置的Leader选举功能选举出新的Master。
在Cluster Management组成的帮助下,我们还可以创建一个Global Cluster。其拥有一个Master Cluster以及多个Slave Cluster。该集群组建方式允许Master Cluster和Slave Cluster处于不同区域的服务集群中。这样就可以允许服务的用户访问距离自己最近的服务。和Neo4J集群中的Master及Slave实例的关系类似,数据的写入通常都是在Master Cluster中进行,而Slave Cluster将只负责提供数据读取服务。
系统要求
内存限制了图数据库的大小,磁盘I/O限制了读写的性能。
中央处理器
性能通常是消耗在创建大图数据库的内存或者I/O上,以及计算适合内存的图数据库。
最小要求
Intel 486
推荐配置
Intel Core i7
内存
最小要求
1GB
推荐配置
4-8GB
磁盘
最小要求
SCSI, EIDE
推荐配置
SSD w/ SATA
文件系统
最小要求
ext3 (或者更简单的)
推荐配置
ext4, ZFS
软件
Neo4j是基于Java开发的。
Java
1.6+
操作系统
Linux, Windows XP, Mac OS X
Linux服务安装
下载对应版本的tar包到相应的目录
配置NEO4J_HOME然后进入目录中
执行:sudo ./bin/neo4j install
执行查看状态命令:service neo4j-service status
执行启动命令:service neo4j-service start
执行结束命令:service neo4j-service stop
注:在安装过程中你将会被要求设定用户名和密码并指定数据源文件的存储路径。
Neo4j服务器配置
服务器首要的配置文件是:conf/neo4j-server.properties
默认日志服务配置:conf/log4j.properties
低性能配置参数文件:conf/neo4j.properties
守护进程配置文件:conf/neo4j-wrapper.properties,怕翻译不准确故下附原文。
(Configuraion of the deamonizing wrapper are found in conf/neo4j-wrapper.properties)
重要的配置参数
主配置文件的服务器可以发现在 conf/neo4j-server.properties。
此文件包含几个重要的设置,并且虽然默认设置是明智管理员可能会选择进行更改
(特别是对端口设置)。
设置硬盘数据库存储目录:
org.neo4j.server.database.location=data/graph.db
注:Windows环境中应配置绝对路径:“c:/data/db”
指明支持数据、管理、UI接入的http(HTTPS的为7473)服务端口:org.neo4j.server.webserver.port=7474
指明web服务的客户端接受模式(默认的是127.0.0.1和localhost)
#allow any client to connect
org.neo4j.server.webserver.address=0.0.0.0
设置REST数据API访问数据库时的相对路径:
org.neo4j.server.webadmin.data.uri=/db/data/
设置在使用webadmin 工具时administration API的管理URI的相对路径org.neo4j.server.webadmin.management.uri=/db/manage
Force the server to use IPv4 network addresses, in conf/neo4j-wrapper.conf under the section Java Additional Parameters add a new paramter: wrapper.java.additional.3=-Djava.net.preferIPv4Stack=true 强制服务器使用IPv4地址
低性能调节参数应当被如下的设置明确指定:org.neo4j.server.db.tuning.properties=neo4j.properties
注:如果没有设置服务器会在相同的路径下寻找neo4j.properties充当neo4j-server.properties如果既没有设置这个参数,相同的路径下也不存在这个文件,服务会在日志中作出警报,随后在运行时服务器会安装默认设置调节自身。
关掉显示器的日志输出:java.util.logging.ConsoleHandler.level=OFF
编辑conf/neo4j-server.properties启用http loging: org.neo4j.server.http.log.enabled=true
org.neo4j.server.http.log.config=conf/neo4j-http-logging.xml
如果你需要能从外部主机访问,请在 conf/neo4j-server.properties 中设置 org.neo4j.server.webserver.address=0.0.0.0 来启用。
取消密码登录
配置自动索引,配置完成后重启服务(貌似新版本中已经没有这个功能,使用过程中一般手动指定)。














 1236
1236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









