






一、元素定位
元素定位的定义
元素定位是指查找元素HTML代码的过程
元素HTML代码指的是从开始标签到结束标签之间的所有代码
selenium通过find_element定位一个元素
find_elements定位多个元素
元素定位方法
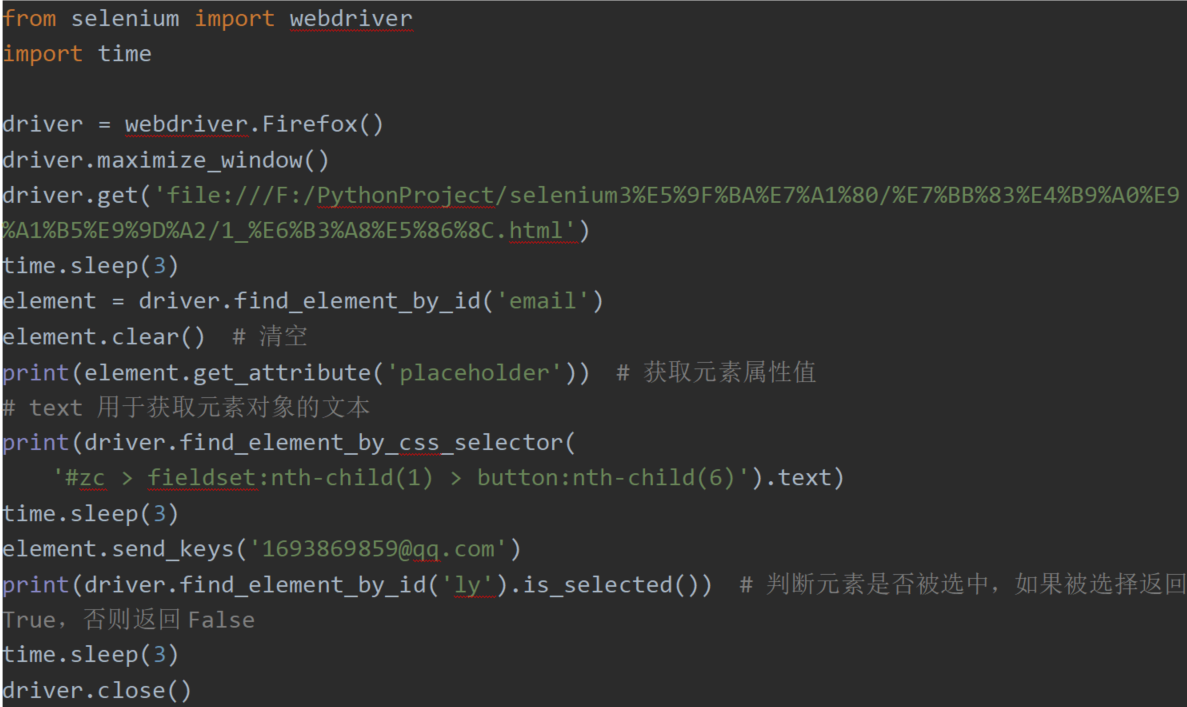
by_id 当元素具有id属性时,可以通过by_id定位元素。
方法:driver.find_element_by_id('id属性值')
说明:HTML规定整个HTML文档中元素的id属性值必须是唯一的不允许重复。
by_name 当元素具有name时,可以通过by_name定位元素。
方法:driver.find_element_by_name('name属性值')
说明:HTML规定name属性指定元素名称,name属性值允许重复,可以不唯一。
by_class_name 当元素具有class属性时,可以通过by_class_name定位元素。
方法:driver.find_element_by_class_name('class属性值')
说明:HTML规定class属性指定元素类名,class属性允许有多个值,多个值之间使用空格分隔。元素定位时任选其一即可。class属性值允许重复。
by_tag_name 通过元素标签名定位元素,由于查找到的标签名通常不止一个,所以一般结合find_elements使用。
单数定位
方法:driver.find_element_by_tag_name(‘标签名’)
说明:返回符合条件的第一个元素,结果为元素对象。
复数定位
方法:driver.find_elements_by_tag_name(‘标签名’)
说明:返回符合条件的所有元素,结果为列表,列表中为符合条件的所有元素对象。
by_link_text 通过超链接元素的全部文字定位元素
方法:driver.find_element_by_link_text(‘超链接全部文字’)
by_partial_link_text 通过超链接元素的部分文字定位元素
方法:driver.find_element_by_partial_link_text(‘超链接部分文字’)
by_xpath
xpath(XML path)用来确定XML文档中某部分位置的语言
方法:driver.find_element_by_xpath(‘xpath表达式’)
xpath表达式:
1)绝对路径 从根元素到指定元素之间经过的所有元素的层级路径,以/开头
2)相对路径 从符合条件的元素开始,以//开头
①标签+属性
//标签名[@属性名=”属性值”]
②层级定位
//父元素标签名[@父元素属性名=”父元素属性值”]/子元素标签名
索引定位
//父元素标签名[@父元素属性名=”父元素属性值”]/子元素标签名[索引] xpath表达式索引从1开始
by_css_selector
css(层叠样式表)是用来表现xml或html等文档样式的语言
方法:driver.find_element_by_css_selector(‘css表达式’)
css表达式:
①id属性定位 # id属性值
② class属性定位 .class属性值
③ 标签+属性 标签名[属性名=”属性值”]
④ 层级定位 父元素的标签名[父元素属性名=”父元素属性值”] >子元素标签名
⑤ 索引定位
a.匹配父元素中的第n个子元素
父元素的标签名[父元素属性名=”父元素属性值”] >子元素标签名:nth- child(n)
b.匹配父元素同种标签第n个子元素
父元素的标签名[父元素属性名=”父元素属性值”] >子元素标签名:nth-of-type(n)
元素定位策略
当页面元素具有id属性时,可以通过by_id定位元素;
当页面元素有超链接需要定位时,通过link_text或partial_link_text定位元素;
当常用方法都无法定位元素时,可以考虑使用xpath或css定位。
xpath定位功能很强大,但采用从上到下遍历搜索模式,定位速度慢,尽量少用。
css语法简单,采用样式定位,定位速度较快,同时对浏览器的兼容性较好。
二、元素操作
常用操作
输入 元素对象.send.keys(‘输入内容’)
点击 元素对象.click()
其他操作
清空 元素对象.clear()
获取元素文字 元素对象.text
获取元素属性值 元素对象.get_attribute(‘属性值’)
判断元素是否被选中,如果被选择返回True,否则返回False
元素对象.is_selected()
三、下拉菜单
普通方法定位
直接定位下拉菜单中的选项,并点击
Select类方法定位
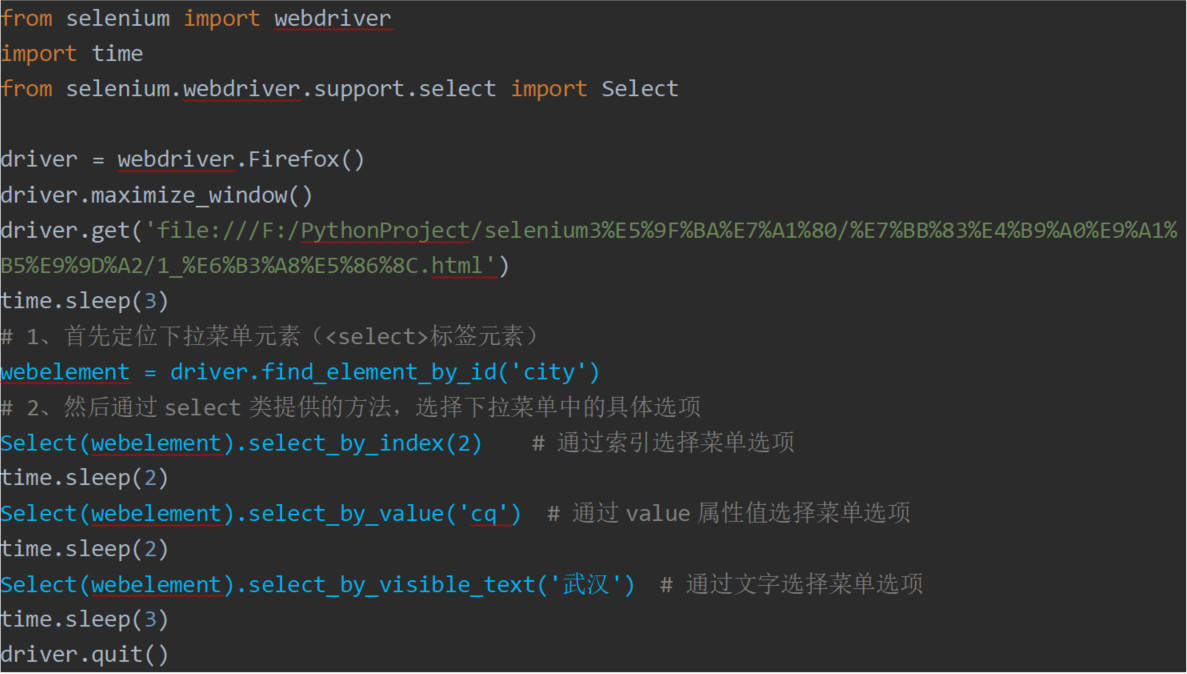
定位<select>标签实现的下拉菜单元素
webelement = driver.find_element_by_XXX(' ') 提供的八种方法随便选择
使用Select类中提供的方法选择菜单选项
①通过select类提供的方法,选择下拉菜单中的具体选项。
Select(webelement).select_by_index(索引)
②通过value属性值选择菜单选项。
Select(webelement).select_by_value('value属性值')
③通过文字选择菜单选项。
Select(webelement).select_by_visible_text(文字)
说明:Select类只针对于<select>标签实现的下拉菜单有效
四、单选框和复选框
单选框
定位并点击
复选框
复选框的单选 定位并点击
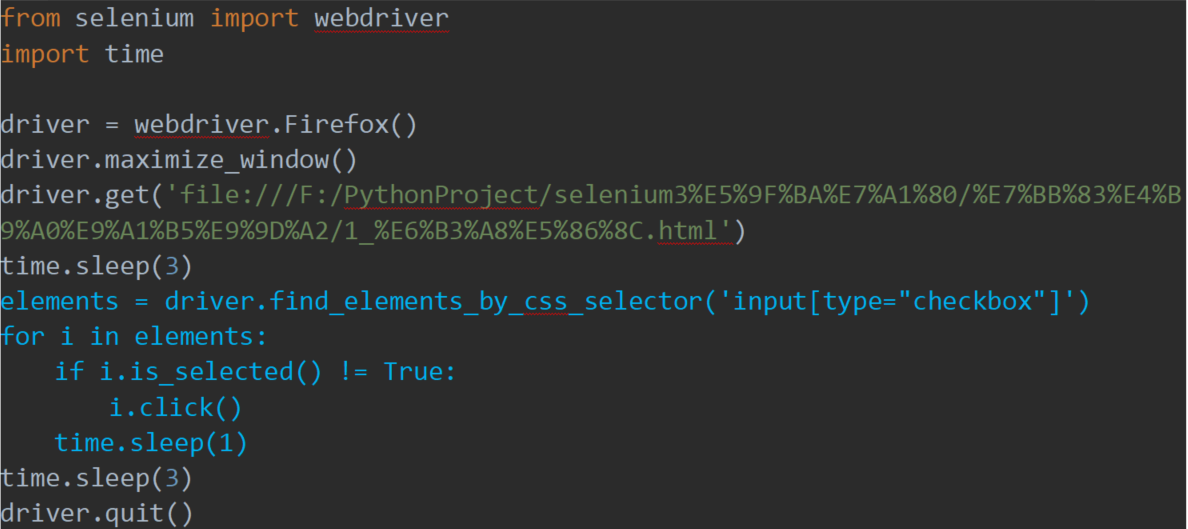
复选框的全选
使用find_elements复数定位,对结果进行遍历点击,但需要注意的是,再次点击已选择的复选框相当于取消,所以点击之前先要判断复选框是否已被选择
五、多窗口
在页面操作过程中,点击超链接有时会打开一个新窗口,如果要定位新窗口中的元素需要使用switch_to.window()切换窗口。
获取所有窗口句柄(窗口id) driver.window_handles
获取当前窗口句柄 driver.current_window_handle
切换窗口 driver.switch_to.window(driver.window_handles[索引])
六、鼠标事件
ActionChains类鼠标操作方法
鼠标拖拽
ActionChains(drive).drag_and_drop(起始元素,目标元素).perform()
鼠标悬停
ActionChains(drive).move_to_element(目标元素).perform()
说明:调用ActionChains类中的鼠标操作方法时,事件不会立即执行,而是会将事件保存到一个队列中,需要调用perform()方法,队列中的事件才会执行
七、滚动条
当页面元素超过一屏时,有时候可能无法定位屏幕下方的元素,这时就需要拖动滚动条,使被定位的元素出现在当前屏幕上,而selenium无法定位和操作滚动条,需要借助js脚本。
js脚本实现浏览器中打开新窗口 ’window.open(“网址”)’
js脚本实现拖动滚动条 'window.scrollBy(水平距离,垂直距离)'
selenium执行js脚本
driver.execute_script(‘js脚本’)
八、表单嵌套页面
在web应用程序中会经常遇见iframe/frame表单嵌套页面,selenium无法定位嵌套页面中的元素,需要使用switch_to.frame()切换到表单的内嵌页面
进入表单内嵌页面
driver.switch_to.frame('id属性值') # iframe/frame标签元素的id属性值
# driver.switch_to.frame('name属性值') # iframe/frame标签元素的name属性值
# driver.switch_to.frame(索引) # iframe/frame标签元素的索引
element = driver.find_element_by_css_selector('#if2') # 先定位元素
driver.switch_to.frame(element) # iframe/frame标签元素对象
返回最外层页面
driver.switch_to.default_content()
返回上一层页面
driver.switch_to.parent_frame()
九、js弹窗
JavaScript中有警告框、确认框、提示框三种弹窗。
selenium使用 switch_to.alert 定位js弹窗,然后调用相应的方法对js弹窗进行操作。
点击js弹窗上的确定按钮 driver.switch_to.alert.accept()
点击js弹窗上的取消按钮 driver.switch_to.alert.dismiss()
获取js弹窗上的文字 driver.switch_to.alert.text
向js弹窗输入内容 driver.switch_to.alert.send_keys( )
十、上传文件
对于标签名为input并且type属性值为file的上传功能,selenium通过send_keys(文件路径)来实现文件的上传。
十一、验证码处理
web自动化登录验证码处理方法:
找开发改测试环境,将验证码的代码注释掉;
找开发设置万能码,只适用于输入型的验证;
使用cookie跳过登录;
验证码识别技术OCR
十二、元素等待
在页面中定位元素时如果元素未出现,则在指定时间内一直等待的过程。
在web自动化中引入等待的机制,可以保证代码的稳定性,使代码不会受到网络、电脑等因素的影响。
Selenium中有三种等待方式:强制等待、隐式等待、显式等待。
强制等待:强行让浏览器等待指定时间,然后再进行下一步操作。
方法:time.sleep(秒)
隐式等待:在指定时间内,如果页面中的元素全部加载完成,则进行下一步操作,否则直到时间结束,然后抛出异常
方法:driver.implicitly_wait(秒)
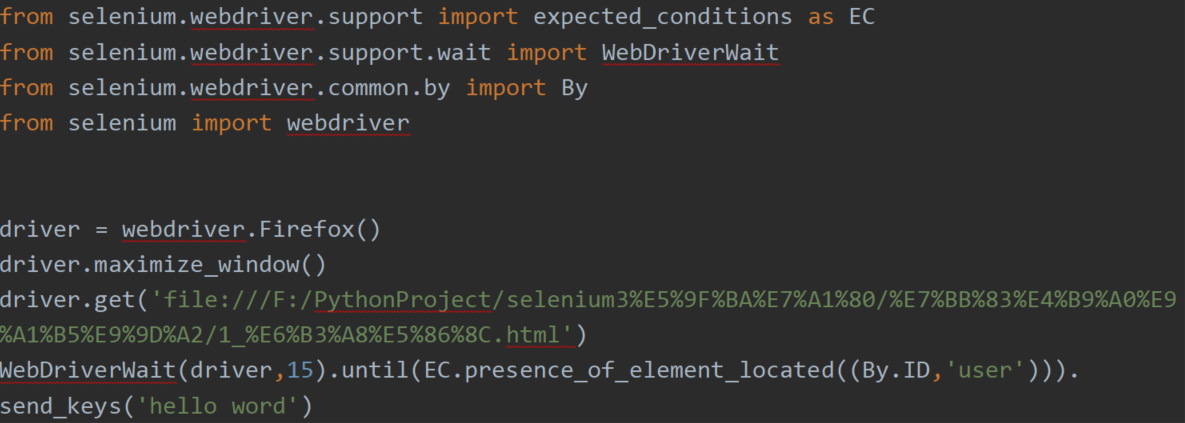
显式等待:程序每隔一段时间就检查一次元素是否出现等条件,如果元素出现,则进行下一步操作,否则继续等待,直到超过最长等待时间,然后抛出超时异常。
方法:
WebDriverWait(driver,等待时间).until(EC.presence_of_element_located((By.ID, '属性值'))).send_keys('输入的东西')
四、POM设计模式
POM模式介绍
POM(page object model)页面对象模型,将每个待测页面都封装成一个page类。然后将那些繁琐的元素定位和元素操作都封装到这个类里,是一种封装思想。在自动化测试中引入POM设计模式,可以实现页面元素和测试用例的分离,能使测试代码的可读性、维护性和复用性变得更好。
POM设计思路
POM设计模式一般分为三层(分层设计模式)
第一层:对selenium进行二次封装,定义一个所有页面类都继承的BasePage类,封装selenium的常用方法,如元素的定位、输入、点击等,用那些封装那些。
第二层:将每个待测页面封装成一个page类,这个类中包含三个小层:
表现层,页面的可见元素。
操作层,对页面元素进行的操作,如输入、点击等。
业务层,对页面元素操作后实现的功能,如登录、注册、支付等。
第三层:使用单元测试框架对业务逻辑进行测试,并实现数据驱动(参数化)。















 2101
2101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









