







原文链接:https://blog.fengqingmo.top/articles/150
文件结构

-
.HINT: 提示文件 用于加速构建索引
-
.MERGERFIN: 存储merge后产生的文件,只会有一个文件
-
.SEG:数据文件
-
FLOCK:文件锁
内存索引结构-基数树
roseDB在内存中保存索引的结构是基数树**(RadixTree)**
基数树是 **Trie(字典树)**的压缩版本,一条边可以存储多个字符。
因为索引都是用字符串表示,字符串有很多相同前缀,用基数树保存性能高
基数树的特点包括:
- 高效查询:对于给定的查询字符串,基数树能够在O(m)时间内确定该字符串是否存在于树中,或者是否存在以该字符串为前缀的节点。
- 空间效率:基数树可以有效利用空间,因为只有当路径上的字符存在时,才会创建对应的节点。
- 前缀搜索:基数树支持高效的前缀搜索,可以快速找到所有以特定前缀开头的字符串。
数据编码格式
rosedb中的每次put操作都视为一次批处理操作,每个chunk(LogRecord)有以下字段
+-------------+-------------+-------------+--------------+-------------+--------------+
| type | batch id | key size | value size | key | value |
+-------------+-------------+-------------+--------------+-------------+--------------+
1 byte varint(max 10) varint(max 5) varint(max 5) varint varint
- type: 分为
- LogRecordNormal: 这种类型的chunk包含实际数据
- LogRecordDelete: 这种类型的chunk 表示删除
- LogRecordDelete:这种类型的chunk 表示相应的batch id对应的批处理事务的完成,可以在批处理过程中出现错误时回滚
- batch id 对应一次批处理
Varint类型
varint 是用来压缩整数编码的,小的数字用 1字节,大的数字用5字节,64位整型数据占用 10字节,实际场景中小整数使用率更多,所以可以起到很好的压缩效果
编码方法
func encodeLogRecord(logRecord *LogRecord) []byte {
header := make([]byte, maxLogRecordHeaderSize)
header[0] = logRecord.Type
var index = 1
// batch id
index += binary.PutUvarint(header[index:], logRecord.BatchId)
// key size
index += binary.PutVarint(header[index:], int64(len(logRecord.Key)))
// value size
index += binary.PutVarint(header[index:], int64(len(logRecord.Value)))
var size = index + len(logRecord.Key) + len(logRecord.Value)
encBytes := make([]byte, size)
// copy header
copy(encBytes[:index], header[:index])
// copy key
copy(encBytes[index:], logRecord.Key)
// copy value
copy(encBytes[index+len(logRecord.Key):], logRecord.Value)
return encBytes
}
关键方法
Merge操作实现
// 遍历所有数据文件,并将有效数据写入新的数据文件。
reader := db.dataFiles.NewReaderWithMax(prevActiveSegId)
for {
chunk, position, err := reader.Next()
if err != nil {
if err == io.EOF {
break
}
return err
}
record := decodeLogRecord(chunk)
// 只处理 normal 类型数据
//LogRecordDeleted and LogRecordBatchFinished will be ignored, because they are not valid data.
if record.Type == LogRecordNormal {
indexPos := db.index.Get(record.Key)
if indexPos != nil && positionEquals(indexPos, position) {
// clear the batch id of the record,
// all data after merge will be valid data, so the batch id should be 0.
record.BatchId = mergeFinishedBatchID
// Since the mergeDB will never be used for any read or write operations,
// it is not necessary to update the index.
newPosition, err := mergeDB.dataFiles.Write(encodeLogRecord(record))
if err != nil {
return err
}
// And now we should write the new posistion to the write-ahead log,
// which is so-called HINT FILE in bitcask paper.
// The HINT FILE will be used to rebuild the index fastly when the database is restarted.
_, err = mergeDB.hintFile.Write(encodeHintRecord(record.Key, newPosition))
if err != nil {
return err
}
}
}
}
初始化数据库,加载索引
- 加载 merge文件,将merge后的文件转存到data目录下,并将merge过的旧文件删除
- 从 hint 文件加载索引
- 从所有的数据文件加载索引
func Open(options Options) (*DB, error) {
// check options
if err := checkOptions(options); err != nil {
return nil, err
}
// create data directory if not exist
if _, err := os.Stat(options.DirPath); err != nil {
if err := os.MkdirAll(options.DirPath, os.ModePerm); err != nil {
return nil, err
}
}
// create file lock, prevent multiple processes from using the same database directory
fileLock := flock.New(filepath.Join(options.DirPath, fileLockName))
hold, err := fileLock.TryLock()
if err != nil {
return nil, err
}
if !hold {
return nil, ErrDatabaseIsUsing
}
// load merge files if exists
if err = loadMergeFiles(options.DirPath); err != nil {
return nil, err
}
// open data files from WAL
walFiles, err := wal.Open(wal.Options{
DirPath: options.DirPath,
SegmentSize: options.SegmentSize,
SementFileExt: dataFileNameSuffix,
BlockCache: options.BlockCache,
Sync: options.Sync,
BytesPerSync: options.BytesPerSync,
})
if err != nil {
return nil, err
}
// init DB instance
db := &DB{
dataFiles: walFiles,
index: index.NewIndexer(),
options: options,
fileLock: fileLock,
}
// load index frm hint file
if err = db.loadIndexFromHintFile(); err != nil {
return nil, err
}
// load index from data files
if err = db.loadIndexFromWAL(); err != nil {
return nil, err
}
return db, nil
}
Put/delete操作
每个写请求都被视为一次批处理, 先写入缓冲池,再提交写入到文件
// Put 将一个键值对写入数据库。
// 实际上,它将打开一个新的批处理并提交它。
// 你可以将批处理视为只包含一个Put操作。
func (db *DB) Put(key []byte, value []byte) error {
// 创建一个批处理选项,默认为DefaultBatchOptions
options := DefaultBatchOptions
// 由于这是一个单一的写操作,我们可以将Sync设置为false
// 因为数据将被写入WAL(Write-Ahead Logging),
// WAL文件将根据数据库选项同步到磁盘。
options.Sync = false
// 创建一个新的批处理实例
batch := db.NewBatch(options)
// 在批处理中执行Put操作,将键值对写入batch缓冲池
if err := batch.Put(key, value); err != nil {
// 如果Put操作失败,返回错误
return err
}
// 提交批处理,将写入的数据永久保存到数据库
return batch.Commit()
}
DefaultBatchOptions
var DefaultBatchOptions = BatchOptions{
//表示批处理操作是否需要同步到磁盘
Sync: true,
// 表示批处理是否只用于读取操作
ReadOnly: false,
}
Get操作
先从待写入的batch缓冲池读,没读到再从内存索引拿到 position,交给 WAL 读
func (b *Batch) Get(key []byte) ([]byte, error) {
if len(key) == 0 {
return nil, ErrKeyIsEmpty
}
if b.db.closed {
return nil, ErrDBClosed
}
// get from pendingWrites
if b.pendingWrites != nil {
b.mu.RLock()
if record := b.pendingWrites[string(key)]; record != nil {
if record.Type == LogRecordDeleted {
b.mu.RUnlock()
return nil, ErrKeyNotFound
}
b.mu.RUnlock()
return record.Value, nil
}
}
// get from data file
chunkPosition := b.db.index.Get(key)
if chunkPosition == nil {
return nil, ErrKeyNotFound
}
chunk, err := b.db.dataFiles.Read(chunkPosition)
if err != nil {
return nil, err
}
record := decodeLogRecord(chunk)
if record.Type == LogRecordDeleted {
return nil, ErrKeyNotFound
}
return record.Value, nil
}
理清架构
主要分成 内存区的设计 和 磁盘文件区的设计
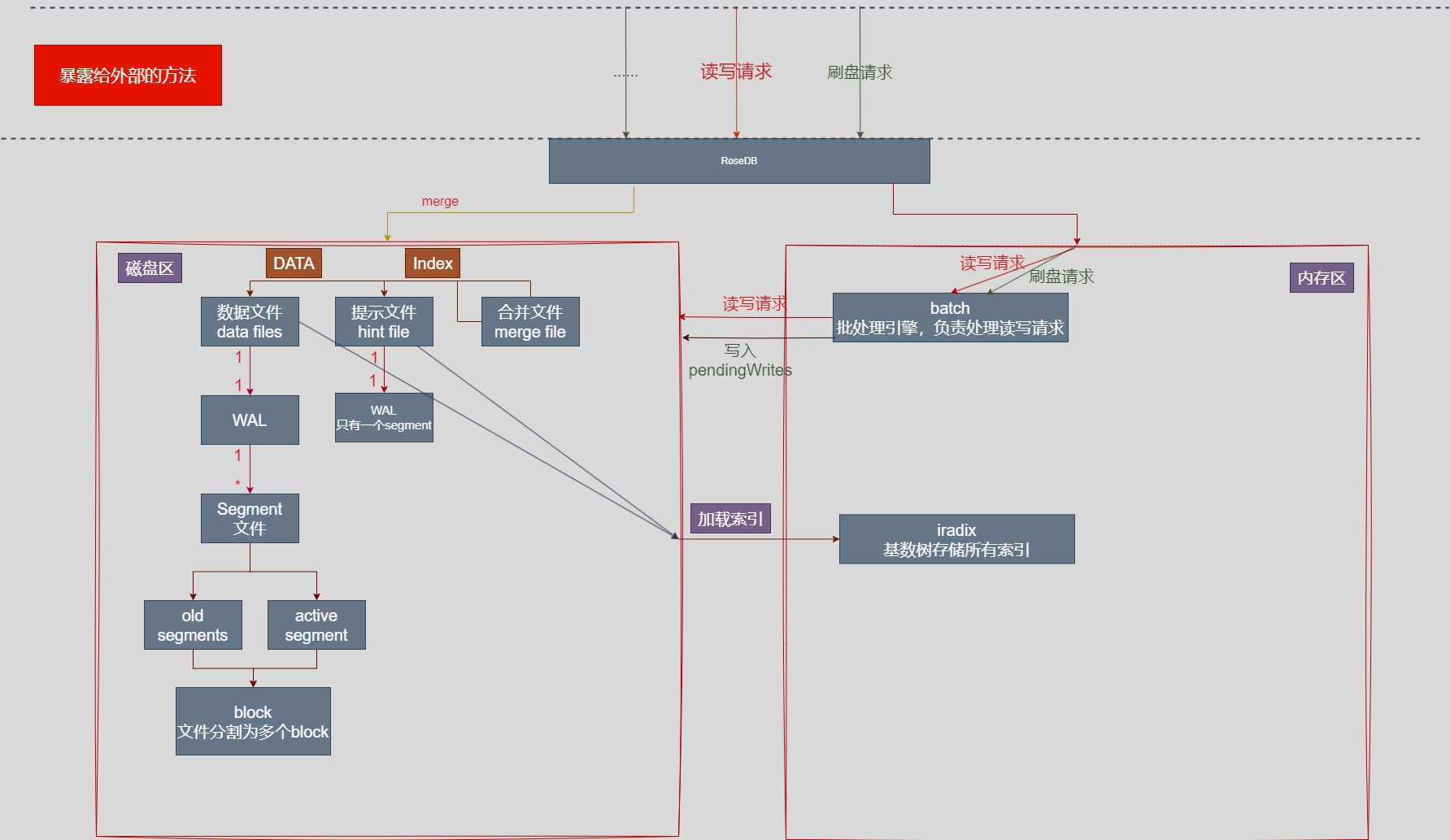
完结
感觉设计一个 简单的数据库的 重难点在于以下几方面
- 设计数据在文件内的编码方式
- 数据结构设计:确定每个记录所需包含的字段,并设计它们的数据类型和大小。
- 数据完整性:实现校验和或 checksum 来确保数据的完整性。
- 错误处理:设计错误检测和恢复机制保证事务的原子性
- 索引设计:
- 索引结构:选择合适的索引结构,如哈希表、B树、跳表、基数树等,以提高查询效率。
- 索引维护:设计索引的维护机制,如在插入、删除和更新操作时如何更新索引。
- 临界情况处理:
- 数据分布:当数据过大无法连续存储时,设计数据分布策略,如分片或分段。
- 锁机制设计:
- 并发控制:设计合理的锁机制,如乐观锁、悲观锁、读写锁等,以避免数据冲突。
- 锁优化:优化锁的获取和释放,减少锁冲突和锁等待
其他:
编码能力也很重要,对于之前是写java简单业务的来说,这些相对底层的代码无疑是有难度的。
最重要的还是心态,从刚开始clone下这个项目打开时看代码一脸懵,到现在理清脉络,中间一度看不下去。坚持啃下去才能有收获!!
















 1044
1044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









