







目录
一 栈的基本概念
1.栈的定义:
栈(Stack)是只允许在一端进行插入或删除操作的线性表。首先栈是一种线性表,但限定这种线性表只能在某一端进行插入和删除操作。
栈顶(Top) 线性表允许进行插入删除的那一端
栈底(Bottom) 固定的,不允许进行插入和删除的另一端。
空栈 不含任何元素。
二 栈的顺序存储结构

1.栈的存储结构:
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;
int capacity;
}ST;2.栈的所有接口:
//栈的初始化、销毁
void STInit(ST* ps);
void STDestroy(ST* ps);
//栈的入栈、出栈
void STPush(ST* ps, STDataType x);
void STPop(ST* ps);
//获取栈顶元素、有效数据个数
STDataType STTop(ST* ps);
int STSize(ST* ps);
//判断栈是否为空
bool STEmpty(ST* ps);3.栈的初始化:
void STInit(ST* ps)
{
ps->a = NULL;
ps->capacity = 0;
ps->top = -1;//ps->top = 0;
}输出:

4.栈顶指针初值为-1或者0的区别:
当栈顶指针初始值为-1时:
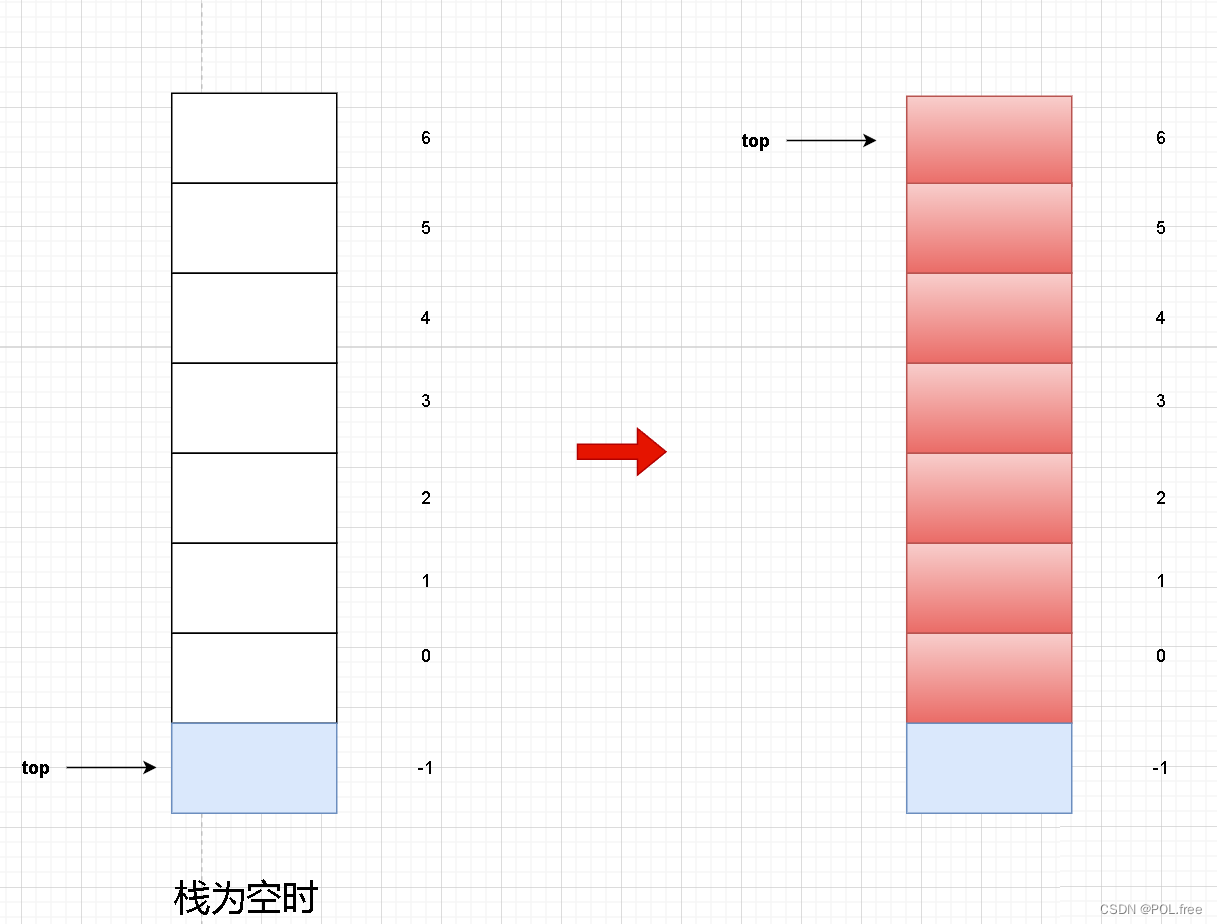
进栈时:
因为此时栈为空且栈顶指针指向-1所以我们先让栈顶指针先自增然后把值赋给栈顶元素。
ps->a[++ps->top] = x;
出栈时:
先取栈顶元素然后再自减。
x = ps->arr[ps->top--];
当栈顶指针初始值为0时:
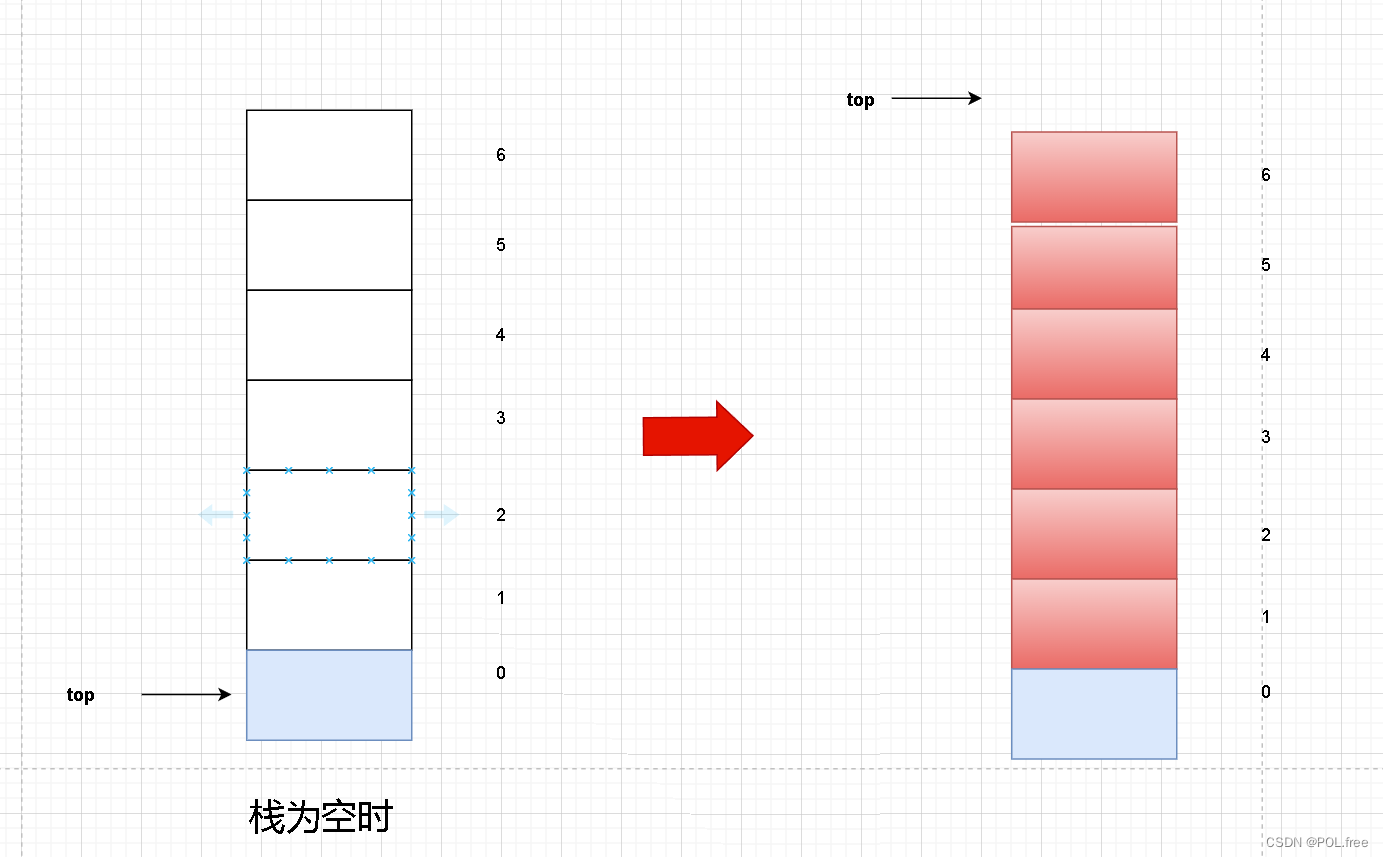
进栈时:
因为此时栈为空且栈顶指针指向0所以我们先值赋给栈顶元素然后再让栈顶指针先自增。
ps->a[ps->top++] = x;出栈时:
先自减然后再取栈顶元素。
x = ps->arr[--ps->top];其实谁便用哪个都行看自己喜好,它们无非就是先自增和后自增,自减也和自增一样。
5.栈的销毁:
void STDestroy(ST* ps)
{
assert(ps);//判断ps指针是否为空
free(ps->a);
ps->a = NULL;
ps->capacity = 0;
ps->top = -1;
}输出:

6.入栈:
void STPush(ST* ps, STDataType x)
{
assert(ps);
//栈扩容
if (ps->capacity == ps->top + 1)//因为ps->capacity为0而ps->top为-1,为了能让栈扩容
//那就必须要相等
{
STDataType NewCapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;
ST* tmp = (ST*)realloc(ps->a, NewCapacity * sizeof(STDataType));
if (tmp == NULL)
{
perror("malloc error");
exit(-1);
}
ps->a = tmp;
ps->capacity = NewCapacity;
}
ps->a[++ps->top] = x;//ps->top == 0 : ps->a[ps->top++] = x;
}输出:

7.出栈:
void STPop(ST* ps)
{
assert(ps);
if (ps->top == -1)//判断栈是否为空
{
exit(-1);
}
ps->top--;
}输出:

8.获取栈顶元素:
STDataType STTop(ST* ps)
{
assert(ps);
if (ps->top == -1)
{
exit(-1);
}
return ps->a[ps->top];
}
输出:

9.获取有效数据个数:
int STSize(ST* ps)
{
assert(ps);
ps->top++;
return ps->top;
}输出:

10:判断栈是否为空:
bool STEmpty(ST* ps)
{
assert(ps);
return ps->top == -1;//当栈为空那么返回的就是真反之则为假
}输出:

11.打印栈:

三 栈的链式存储结构

1.栈的存储结构:
//链表存储结构
typedef int STTDataType;
typedef struct STist
{
struct STist* next;//指针域
STTDataType data;//数据域
}ST;
//栈存储结构
typedef struct LinkedStack
{
ST* top;//栈顶指针
int size;//有效数据
} LS;
3.栈的所有接口:
//初始化、销毁
//初始化、销毁
void Init_Stack(LS* Stack);
void Destroy_Stack(ST* Stack);
//入栈、出栈
void push_Stack(ST* Stack, STTDataType x);
void pop_Stack(ST* Stack);
//检查栈是否为空
STTDataType STEmpty(ST* Stack);
//获取栈顶元素、有效数据个数
STTDataType STTop(ST* Stack);
STTDataType STSize(ST* Stack);
4.栈的初始化:
void Init_Stack(LS* Stack)
{
assert(Stack);
Stack->top = NULL;
Stack->size = 0;
}输出:

5.栈的销毁:
void Destroy_Stack(LS* Stack)
{
assert(Stack);
Stack->size = 0;
ST* tmp = Stack->top;
while (tmp != NULL)
{
ST* next = tmp->next;
free(tmp);
tmp = next;
}
}6.入栈:
void push_Stack(LS* Stack, STTDataType x)
{
assert(Stack);
ST* Newnode = (ST*)malloc(sizeof(ST));
if (Newnode == NULL)
{
perror("malloc error");
exit(-1);
}
Newnode->data = x;
//首先就是让第一个节点指向为空(把它当成尾)然后再让新节点指向之前的节点以此类推
Newnode->next = Stack->top;
Stack->top = Newnode;//让Stack->top永远为第一个节点
Stack->size++;//有效数据自增
}输出:
7.出栈:
void pop_Stack(LS* Stack)
{
assert(Stack);
if (Stack->top == NULL)//判断栈顶指针是否为空
{
exit(-1);
}
ST* Ptmp = (Stack->top)->next;
free(Stack->top);
Stack->top = Ptmp;
Ptmp = Ptmp->next;
}输出:

8.获取栈顶元素:
STTDataType STTop(LS* Stack)
{
return Stack->top->data;
}输出:

9.获取有效数据个数:
STTDataType STSize(LS* Stack)
{
return Stack->size;
}
输出:

10.判断栈是否为空:
STTDataType IsEmpty(LS* Stack)
{
if (Stack->top == NULL)//判断栈顶指针是否为空
{
return 0;
}
return 1;
}输出:

四 顺序存储和链式存储实现栈的优缺点比较
顺序存储和链式存储都可用于实现栈,各有优缺点。具体选择哪种方式取决于应用的特定需求和优先级。
1.顺序存储(基于数组的栈):
优点:
-
2.高效的访问和随机检索: 顺序存储允许使用索引直接访问堆栈中的任何元素,从而实现高效的随机检索元素。
-
可预测的内存使用: 基于数组的栈具有预定义的大小,使得估计和管理内存使用更加容易。
-
缓存友好型访问: 数组中的连续内存位置往往可以更好地利用 CPU 缓存。
缺点:
-
有限的动态调整大小: 基于数组的栈具有固定大小,在运行过程中调整大小可能效率低下,并且需要复制元素。
-
潜在的内存浪费: 如果栈大小估计过高,则可能由于未使用的分配空间而浪费内存。如果估计过低,则栈可能溢出,导致错误。
-
中间插入/删除代价高昂: 在基于数组的栈中插入或删除中间元素可能代价高昂,因为它需要移动元素以保持顺序。
2.链式存储(基于链表的栈):
优点:
-
动态调整大小: 链表可以根据需要动态增长或缩小,因此适用于堆栈大小不可预测的情况。
-
中间插入/删除高效: 在链表栈中插入或删除中间元素相对便宜,因为它只需要修改指针引用。
-
灵活的内存分配: 链表不需要连续的内存分配,因此适用于内存受限的环境。
缺点:
-
较慢的访问和检索: 访问链表堆栈中的特定元素需要从头开始遍历链表,与顺序存储相比,随机检索速度较慢。
-
指针开销: 链表会引入额外的内存开销来存储节点之间的指针,这在内存关键型应用程序中可能是一个因素。
-
缓存效率低: 链表的非连续内存布局可能导致缓存利用率低于顺序存储。
五 总结
-
建议使用顺序存储(基于数组的栈):
- 随机访问和检索速度至关重要。
- 可预测和可控的内存使用很重要。
- 堆栈大小相对稳定,可以事先估计。
-
建议使用链式存储(基于链表的栈):
- 需要动态的堆栈大小来处理不可预测的数据量。
- 预计频繁地在堆栈中间插入/删除元素。
- 内存限制是一个问题,需要灵活的内存分配。
对于实现栈的顺序存储和链式存储之间的选择,取决于应用的特定需求和优先级。仔细权衡访问速度、内存使用和动态功能之间的利弊,以做出最佳决策。
















 6926
6926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











