






如何对抗反爬虫
用Python爬虫非常的容易,但是爬虫是个运算很快的程序。如果速度太快那就是对服务器的爬虫攻击了。加个while ture不断爬虫就会对小服务器会产生压力。所以也就会有了反爬虫机制。咋么防御的呢,如下图所示:
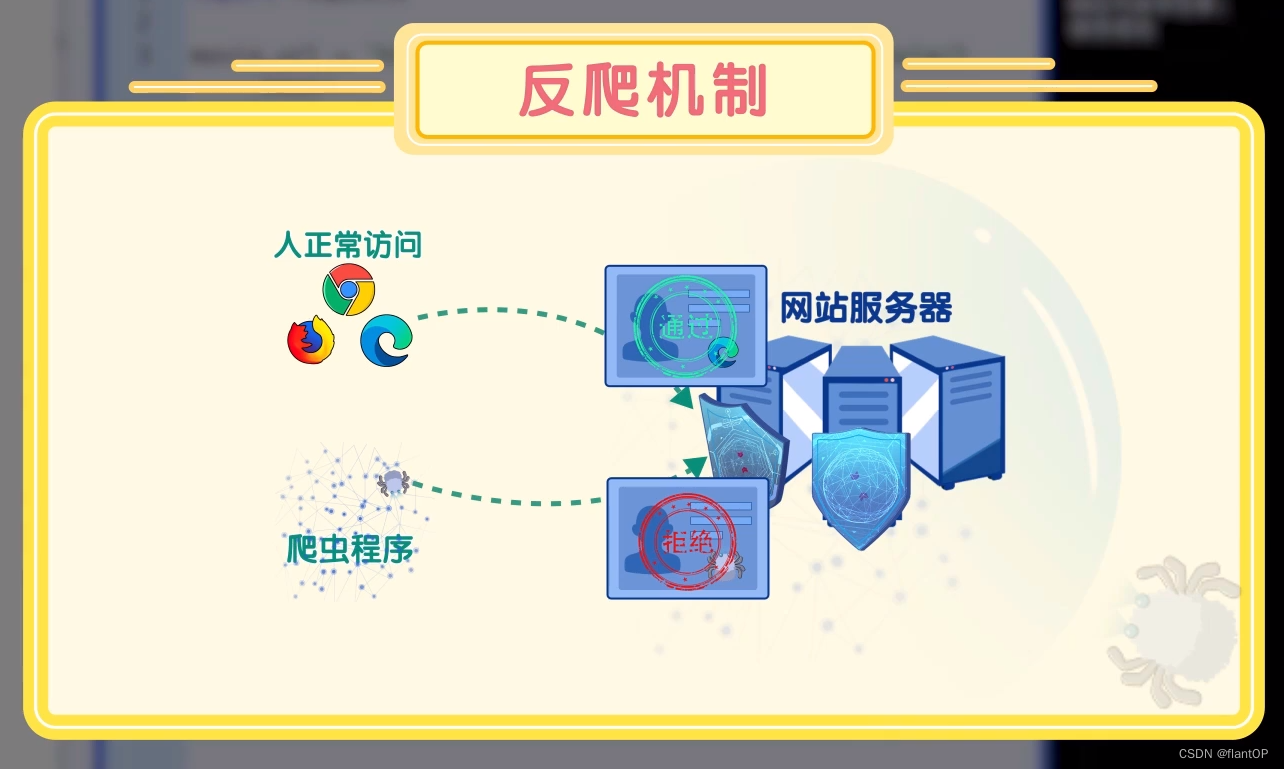
来自朋友在上课时的截屏
所以有的服务器上只用变自己的身份就可以了。
以下就是示范:
import requests
url = #'网站'
m = {
身份
}
r = requests.get(url=url,headers=m)身份是啥可以填一个例子:
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'
可爬虫内容和robots文件
那么如何知道爬虫可以爬那些呢呢?
要爬的网页加上/robots.txt
我在此用我们熟悉的blibli。
回正题:
User-agent: *
Disallow: /medialist/detail/
Disallow: /index.html
User-agent: Yisouspider
Allow: /
User-agent: Applebot
Allow: /
User-agent: bingbot
Allow: /
User-agent: Sogou inst spider
Allow: /
User-agent: Sogou web spider
Allow: /
User-agent: 360Spider
Allow: /
User-agent: Googlebot
Allow: /
User-agent: Baiduspider
Allow: /
User-agent: Bytespider
Allow: /
User-agent: PetalBot
Allow: /
User-agent: *
Disallow: /这些东西就是了,那么咋看呢?
User-agent: 爬虫的名称
Disallow: 不允许爬虫访问的地址
Allow: 允许爬虫访问的地址
爬虫第一步:查看robots.txt - 知乎 (zhihu.com)
我在网上学的。
速度的控制
速度不能太快咋,太快封了就完了。这是我在网上摸索出来的。再次声明转载了代码,并感谢。
Acheng1011-CSDN博客 :怎样反爬虫和控制爬虫的速度_beautifulcoup 限制爬取速度-CSDN博客版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
他的代码如下:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 1
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3
#默认False;为True表示启用AUTOTHROTTLE扩展
AUTOTHROTTLE_ENABLED = True
#默认5秒;初始下载延迟时间
AUTOTHROTTLE_START_DELAY = 1
#默认60秒;在高延迟情况下最大的下载延迟
AUTOTHROTTLE_MAX_DELAY = 3
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'askdoctor.middlewares.AskdoctorDownloaderMiddleware': 543,
}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'askdoctor.pipelines.AskdoctorPipeline': 300,
}
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#开启本地缓存
HTTPCACHE_ENABLED = True
#将http缓存延迟时间
HTTPCACHE_EXPIRATION_SECS = 1
HTTPCACHE_DIR = 'httpcache'
HTTPCACHE_IGNORE_HTTP_CODES = []
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
作者也说出了缺陷,爬取的过程中遇到一个问题就是,如果爬取页面设置为从page1到page10000,爬取的结果有很多漏掉的。然后将设置修改为如上,还是会有漏掉的。
最后我的解决办法是将DOWNLOAD_DELAY 时间设置的更大一些。
保存,乱码的解决,和多页数的爬虫方法(和巧妙利用for)
然后就给个保存的方法:和乱码的办法,还有朋友告诉我的多页数查询法。
filename = '名字.html'
f = open(filename, 'w', encoding='utf-8')
f.write(info)
f.close()
#可以做个提示
print('OK数据保存已完成')当然有时候会乱码:原因就是编码。你可以用txt测试一下
那就向他询问响应变量.encoding = 响应变量.apparent_encoding就OK了代码如下:
x = requests.get(url=movie_url, headers=h)
x.encoding=r.apparent_encoding
info = x.text
print(info)
filename = '1.html'
f = open(filename,'w', encoding='utf-8')
f.write(info)
f.close()
print('保存HTML文件成功')那假设页数不止一个呢?我做个例子如果要第一,第二页的话:
import requests
url1 = '第一页网址'
url2 = '第二页网址'
r = requests.get(url=url1, headers=h)
r.encoding = r.apparent_encoding
info = r.text
filename = '1.html'
f = open(filename,'w', encoding='utf-8')
f.write(info)
f.close()
print('1号HTML保存完成')
r2 =requests.get(url=movie_url2,headers=h)
r2.encoding = r.apparent_encodinginfo2=r2.text
info2 = r2.text
filename2 = '2.html'
f = open(filename2,'w', encoding='utf-8')
f.write(info2)
f.close()
print('2号html保存完成')50页呢就用for当然要发现网址的规律再弄哦。
转载最好申明下哦,不声明也不追究。
百度的robots:
User-agent: Baiduspider
Disallow: /baidu
Disallow: /s?
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
User-agent: Googlebot
Disallow: /baidu
Disallow: /s?
Disallow: /shifen/
Disallow: /homepage/
Disallow: /cpro
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
User-agent: MSNBot
Disallow: /baidu
Disallow: /s?
Disallow: /shifen/
Disallow: /homepage/
Disallow: /cpro
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
User-agent: Baiduspider-image
Disallow: /baidu
Disallow: /s?
Disallow: /shifen/
Disallow: /homepage/
Disallow: /cpro
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
User-agent: YoudaoBot
Disallow: /baidu
Disallow: /s?
Disallow: /shifen/
Disallow: /homepage/
Disallow: /cpro
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
User-agent: Sogou web spider
Disallow: /baidu
Disallow: /s?
Disallow: /shifen/
Disallow: /homepage/
Disallow: /cpro
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
User-agent: Sogou inst spider
Disallow: /baidu
Disallow: /s?
Disallow: /shifen/
Disallow: /homepage/
Disallow: /cpro
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
User-agent: Sogou spider2
Disallow: /baidu
Disallow: /s?
Disallow: /shifen/
Disallow: /homepage/
Disallow: /cpro
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
User-agent: Sogou blog
Disallow: /baidu
Disallow: /s?
Disallow: /shifen/
Disallow: /homepage/
Disallow: /cpro
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
User-agent: Sogou News Spider
Disallow: /baidu
Disallow: /s?
Disallow: /shifen/
Disallow: /homepage/
Disallow: /cpro
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
User-agent: Sogou Orion spider
Disallow: /baidu
Disallow: /s?
Disallow: /shifen/
Disallow: /homepage/
Disallow: /cpro
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
User-agent: ChinasoSpider
Disallow: /baidu
Disallow: /s?
Disallow: /shifen/
Disallow: /homepage/
Disallow: /cpro
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
User-agent: Sosospider
Disallow: /baidu
Disallow: /s?
Disallow: /shifen/
Disallow: /homepage/
Disallow: /cpro
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
User-agent: yisouspider
Disallow: /baidu
Disallow: /s?
Disallow: /shifen/
Disallow: /homepage/
Disallow: /cpro
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
User-agent: EasouSpider
Disallow: /baidu
Disallow: /s?
Disallow: /shifen/
Disallow: /homepage/
Disallow: /cpro
Disallow: /ulink?
Disallow: /link?
Disallow: /home/news/data/
Disallow: /bh
User-agent: *
Disallow: /















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









