







简介
Redis是一个使用C语言编写的,开源、支持网络、基于内存、分布式、可选持久性的键值对存储数据库,性能极高——Redis能读的速度是110000次/s,写的速度是81000次/s。从2015年6月开始,Redis的开发由Redis Labs赞助,而2013年5月至2015年6月期间,其开发由Pivotal赞助。在2013年5月之前,其开发由VMware赞助。根据月度排行网站DB-engines.com的数据,Redis是最流行的键值对存储数据库。
缓存使用原则
什么时候,什么样的数据能够保存在Redis中?
数据量不能太大
使用越频繁,Redis保存这个数据越值得
保存在Redis中的数据一般不会是数据库中频繁修改的
数据类型
Redis的外围由一个键、值映射的关联数组构成。与其他非关系型数据库主要不同在于: Redis中值的类型不仅限于字符串,还支持如下抽象数据类型:
· 字符串列表
· 无序不重复的字符串集合
· 有序不重复的字符串集合
· 键、值都为字符串的哈希表
值得类型决定了值本身的操作。Redis支持不同无序、有序的列表,无序、有序的集合间的交集、并集等高级服务器端原子操作。
即5大数据类型分别是: String、List、Set、Hash和Zset(sorted set有序集合)
缓存淘汰策略
Redis将数据保存在内存中,内存的容量是有限的
如果服务器的内存已经全满,现在还需要向Redis中保存新的数据,如何操作,就是缓存淘汰策略
noeviction: 返回错误(默认)
如果不想让它发生错误,就可以把它设置成将满足某些条件的信息删除后,再将新的信息保存
allkeys-random: 所有数据中随机删除数据
volatile-random: 有过期时间的数据中随机删除数据
volatile-ttl: 删除剩余有效时间最少的数据
allkeys-lru: 所有数据中删除上次使用的时间距离现在最久的数据
volatile-lru: 有过期时间的数据中删除上次使用的时间距离现在最久的数据
allkeys-lfu: 所有数据中删除使用频率最低的数据
volatile-lfu: 有过期时间的数据中删除使用频率最低的数据
Time To Live (ttl)
Least Recently Used (lru)
Least Frequently Used (lfu)
缓存穿透
所谓缓存穿透,就是一个业务请求先查询Redis,Redis没有这个数据,就去查询数据库,但是数据库也没有的情况
正常业务下,一个请求查询到数据后,我们可以将这个数据保存在Redis
之后的请求都可以直接从Redis查询,就不需要再连接数据库了
但一旦发生前面的穿透现象,仍然需要连接数据库,一旦连接数据库,项目的整体效率就会被影响
如果有恶意的请求,高并发地访问数据库中不存在的数据,严重的,当前服务器可能出现宕机的情况
业界主流解决方案: 布隆过滤器
bloomfilter的使用步骤
针对现有所有数据,生成布隆过滤器保存在Redis中
在业务逻辑层,判断Redis之前先检查这个id是否在布隆过滤器中
如果布隆过滤器判断这个id不存在,直接返回,如果存在,再进行后面业务执行
缓存击穿
一个计划在Redis保存的数据,业务查询,查询到的数据Redis中没有,但是数据库中有
这种情况要从数据库中查询后再保存到Redis,这就是缓存击穿
但是这个情况也不是异常情况,因为我们大多数数据都需要设置过期时间,而过期时间到时,这个数据就会从Redis中移除,再有请求查询这个数据,就一定会从数据库中再次同步
缓存击穿本身并不是灾难性的问题,也不是不允许发生的情况
缓存雪崩
同一时间发生少量击穿是正常的
但是如果同一时间大量击穿现象就会发生如下图
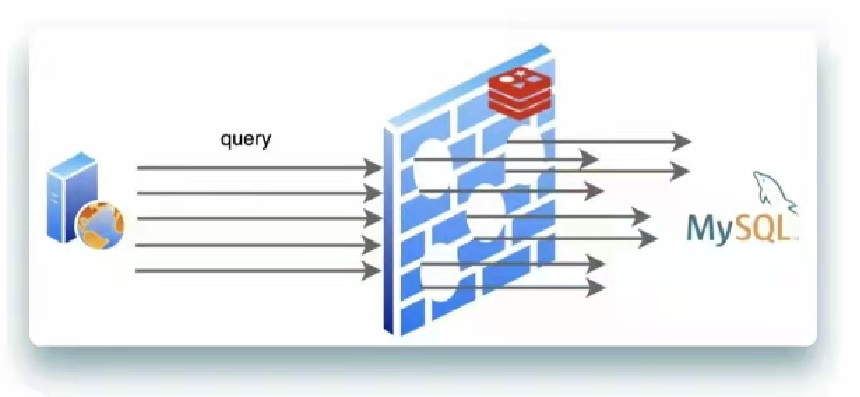
所谓缓存雪崩,指的是Redis中保存的数据,短时间内有大量数据同时到期的情况
本该由Redis反馈的信息,由于雪崩都去访问了Mysql,Mysql承担不了,非常可能导致异常
避免这种情况,就要避免大量缓存同时失效
大量缓存同时失效的原因: 通常是同时加载的数据设置了相同的有效期导致的
我们可以在设置有效期时添加一个随机数,这样就能够防止大量数据同时失效了
持久化
Redis将信息保存在内存
内存的特征就是一旦断电,所有信息都丢失,对于Redis来讲,所有数据丢失后,再重新加载数据,就需要从数据库重新查询所有数据,这个操作不但耗费时间,而且对数据库的压力也非常大
而且有些业务是先将数据保存在Redis,隔一段时间和数据库同步的
如果Redis断电,这段时间的数据就完全丢失了!
为了防止Redis的重启对数据库带来额外的压力和数据的丢失,Redis支持了持久化的功能
所谓持久化就是将Redis中保存的数据,以指定方式保存在Redis当前服务器的硬盘上
如果存在硬盘上,那么断电数据也不会丢失,再启动Redis时,利用硬盘中的信息来回复数据
Redis实现持久化有两种策略
使用快照.一种半持久耐用模式,不时地将数据集以异步方式从内存以RDB格式写入硬盘
### RDB:(Redis Database Backup)
RDB本质上就是数据库快照(就是当前Redis中所有数据转换成二进制的对象,保存在硬盘上)
默认情况下,每次备份会生成一个dump.rdb的文件
当Redis断电或宕机后,重新启动时,会从这个文件中恢复数据,获得dump.rdb中所有内容
实现这个效果我们可以在Redis的配置文件中添加如下信息
```
save 60 5
```
上面配置中60表示秒
5表示Redis的key被修改的次数
配置效果:1分钟内如果有5个key以上被修改,就启动rdb数据库快照程序
优点:
* 因为是整体Redis数据的二进制格式,数据恢复是整体恢复的
缺点:
* 生成的rdb文件是一个硬盘上的文件,读写效率是较低的
* 如果突然断电,只能恢复最后一次生成的rdb中的数据
1.1版本开始使用更安全的AOF格式替代,一种只能追加的日志类型。将数据集修改操作记录起来。Redis能够在后台对只可追加的记录进行修改,从而避免日志的无限增长。
### AOF(Append Only File):
AOF策略是将Redis运行过的所有命令(日志)备份下来,保存在硬盘上
这样即使Redis断电,我们也可以根据运行过的日志,恢复为断电前的样子
我们可以在Redis的配置文件中添加如下配置信息
```
appendonly yes
```
经过这个设置,就能保存运行过的指令的日志了
理论上任何运行过的指令都可以恢复
但是实际情况下,Redis非常繁忙时,我们会将日志命令缓存之后,整体发送给备份,减少io次数以提高备份的性能 和对Redis性能的影响
实际开发中,配置一般会采用每秒将日志文件发送一次的策略,断电最多丢失1秒数据
优点:
相对RDB来讲,信息丢失的较少
缺点:
因为保存的是运行的日志,所以占用空间较大
实际开发中RDB和AOF是可以同时开启的,也可以选择性开启
> Redis的AOF为减少日志文件的大小,支持AOF rewrite
>
> 简单来说就是将日志中无效的语句删除,能够减少占用的空间
Redis存储原理
我们在编写java代码业务时,如果需要从多个元素的集合中寻找某个元素取出,或检查某个Key在不在的时候,推荐我们使用HashMap或HashSet,因为这种数据结构的查询效率最高,因为它内部使用了
**"散列表"**
下图就是散列表的存储原理
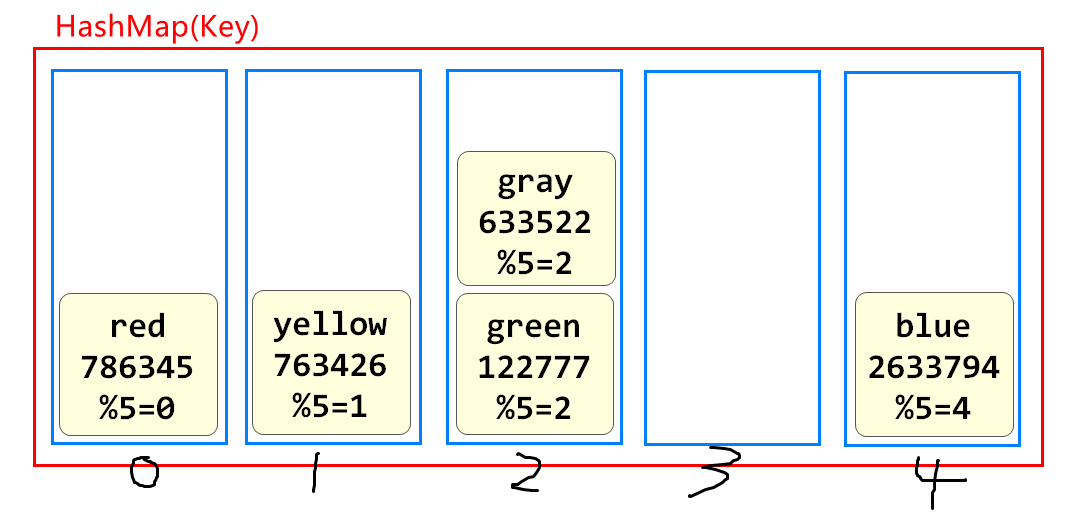
槽位越多代表元素多的时候,查询性能越高,HashMap默认16个槽
Redis底层保存数据用的也是这样的散列表的结构
Redis将内存划分为16384个区域(类似hash槽)
将数据的key使用CRC16算法计算出一个值,取余16384
得到的结果是0~16383
这样Redis就能非常高效的查找元素了
同步
Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。
Redis集群
Redis最小状态是一台服务器
这个服务器的运行状态,直接决定Redis是否可用
如果它离线了,整个项目就会无Redis可用
系统会面临崩溃
为了防止这种情况的发生,我们可以准备一台备用机
**主从复制**
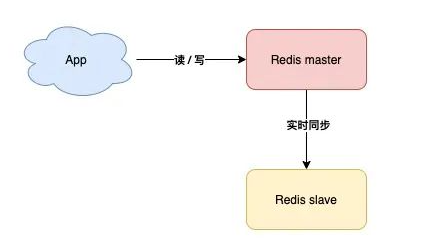
也就是主机(master)工作时,安排一台备用机(slave)实时同步数据,万一主机宕机,我们可以切换到备机运行
缺点,这样的方案,slave节点没有任何实质作用,只要master不宕机它就和没有一样,没有体现价值
**读写分离**
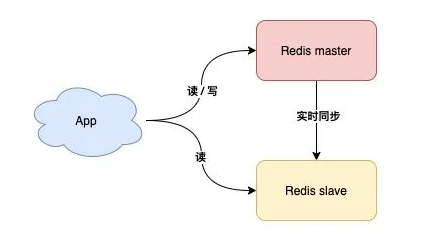
这样slave在master正常工作时也能分担Master的工作了
但是如果master宕机,实际上主备机的切换,实际上还是需要人工介入的,这还是需要时间的
那么如果想实现发生故障时自动切换,一定是有配置好的固定策略的
**哨兵模式**:故障自动切换
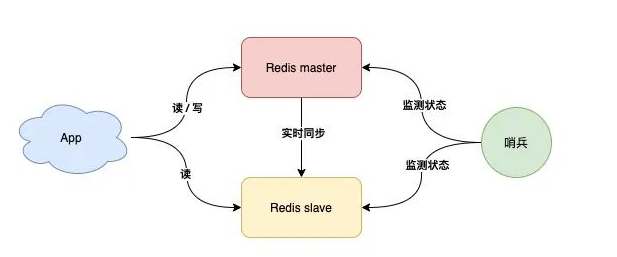
哨兵节点每隔固定时间向所有节点发送请求
如果正常响应认为该节点正常
如果没有响应,认为该节点出现问题,哨兵能自动切换主备机
如果主机master下线,自动切换到备机运行
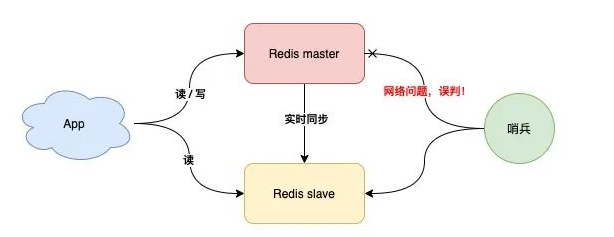
但是如果哨兵判断节点状态时发生了误判,那么就会错误将master下线,降低整体运行性能
所以要减少哨兵误判的可能性
**哨兵集群**
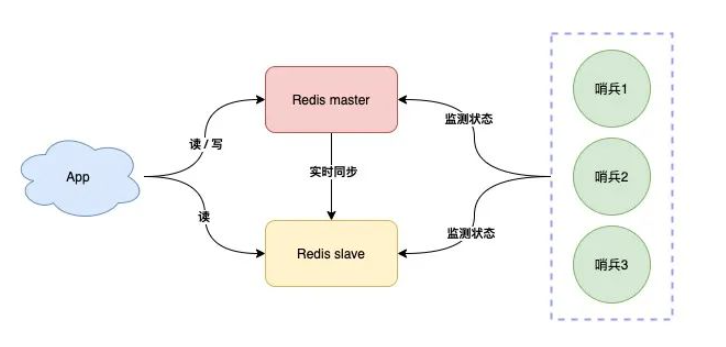
我们可以将哨兵节点做成集群,由多个哨兵投票决定是否下线某一个节点
哨兵集群中,每个节点都会定时向master和slave发送ping请求
如果ping请求有2个(集群的半数节点)以上的哨兵节点没有收到正常响应,会认为该节点下线
当业务不断扩展,并发不断增高时
**分片集群**
只有一个节点支持写操作无法满足整体性能要求时,系统性能就会到达瓶颈
这时我们就要部署多个支持写操作的节点,进行分片,来提高程序整体性能
分片就是每个节点负责不同的区域
Redis0~16383号槽,
例如
MasterA负责0~5000
MasterB负责5001~10000
MasterC负责10001~16383
一个key根据CRC16算法只能得到固定的结果,一定在指定的服务器上找到数据
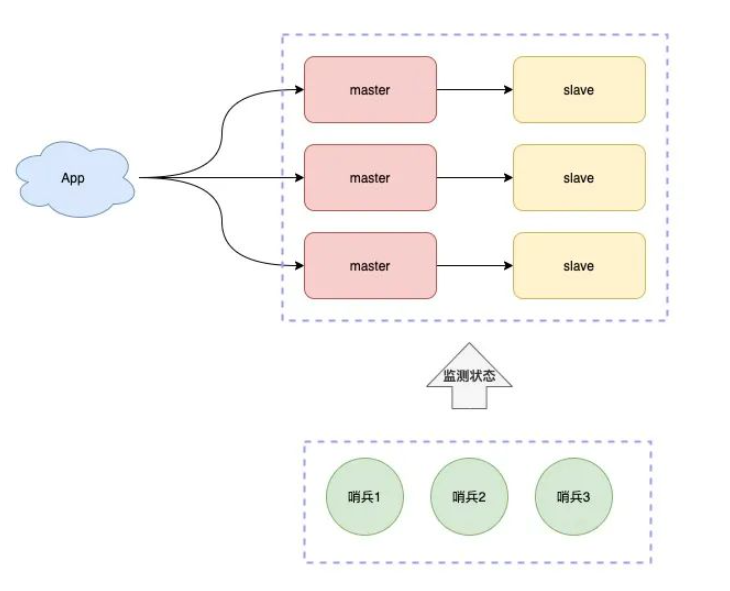
有了这个集群结构,我们就能更加稳定和更加高效的处理业务请求了
**为了节省哨兵服务器的成本,有些公司在Redis集群中直接添加哨兵功能,既master/slave节点完成数据读写任务的同时也都互相检测它们的健康状态**
关于Redis分布式锁的解决方案(Redission)
关于分布式锁的解决方案因为篇幅较大我准备单独写一篇文章
点这里可以跳转Redis官网关于红锁的描述https://redis.io/topics/distlock
翻到最下面,你能看到著名的关于红锁的神仙打架事件
即Martin Kleppmann和antirez的redLock辩论. 一个是很有资历的分布式架构师,一个是redis之父。
Martin Kleppmann的质疑贴
以及
antirez的反击贴
即便看不懂,也大受震撼
















 1589
1589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











