







从零到一学习C++(基础篇) 作者:羡鱼肘子
温馨提示1:本篇是记录我的学习经历,会有不少片面的认知,万分期待您的指正。
温馨提示2:本篇会尽量避免一些术语,尽量用更加通俗的语言介绍c++的基础,但术语也是很重要的。
温馨提示3:看本篇前可以先了解前篇的内容,知识体系会更加完整哦。
初识变量
变量就像“储物柜”
想象你有一个带标签的储物柜:
-
柜子本身:能存放东西(比如数字、文字、真假值等)。
-
标签名字:你给柜子贴个标签(比如叫
age),方便找到它。 -
柜子类型:柜子专门放某类东西(比如“只能放整数”或“只能放小数”)。
在 C++ 中,变量就是程序里的“储物柜”,用来存数据,并且可以随时修改里面的内容。
(简单理解)变量就是给数据贴个名字、分个类,方便随时存、取、改的“储物柜” 🗄️!
变量的关键特点
-
有名字:比如
score、name,方便你记住里面存了什么。 -
有类型:定义时就要告诉电脑这个柜子放什么类型的数据(比如整数、小数、文字)。
-
可以修改:存进去的数据之后能改(比如把
age从 20 改成 21)。
举个栗子 :
// 声明一个叫 age 的“储物柜”,专门存整数(int)
int age = 20;
// 使用变量
cout << "我今年 " << age << " 岁" << endl;
// 修改柜子里的内容
age = 21;
cout << "明年我就 " << age << " 岁了!" << endl; 输出:
我今年 20 岁
明年我就 21 岁了!变量的使用步骤
-
声明:告诉电脑“我要一个放什么类型东西的柜子”
-
格式:
类型 名字;(比如int score;)。
-
-
赋值:往柜子里放东西。
-
可以直接声明时赋值:
int score = 100; -
也可以后来再放:
score = 100;
-
-
使用:用名字随时读取或修改数据。
// 存小数
double price = 9.99;
price = 8.5; // 降价了!
// 存一个字符
char grade = 'A';
// 存一句话(字符串)
string message = "Hello World!";
// 存真假值
bool isRaining = true;
isRaining = false; // 雨停了!要注意哦:
-
先声明,再使用:不能直接用没定义的柜子。
-
名字要合法:比如不能以数字开头(
2name是错的),区分大小写(Age和age是不同变量)。 -
类型要对:不能往“整数柜”里塞小数(除非强制转换)。
变量的定义
在 C++ 中,变量的定义是指为一个数据存储空间分配内存,并为其赋予名称和类型的过程。通俗来说,就是告诉计算机:
-
我要存什么类型的数据(比如整数、小数、字符等)。
-
这个数据叫什么名字(方便后续使用)。
-
初始值是什么(可选,但建议明确赋值)。
变量定义的语法
数据类型 变量名; // 只定义,不初始化(不推荐)
数据类型 变量名 = 初始值; // 定义并初始化(推荐)具体解释
-
数据类型:
决定变量能存储什么类型的数据(例如int、double、char)。int age; // 定义一个整数类型的变量 double price; // 定义一个小数类型的变量 -
变量名:
为变量起一个有意义的名字(需符合命名规则)。int studentCount; // 变量名通常用驼峰命名法或下划线分隔 double total_price; -
初始值(可选但推荐):
在定义时直接赋值,避免未初始化的变量带来意外结果。int score = 100; // 初始化为 100 char grade = 'A'; // 初始化为字符 'A' bool isPassed = true; // 初始化为布尔值 true
举个栗子:
#include <iostream>
using namespace std;
int main() {
// 定义变量并初始化
int apples = 5; // 存储苹果数量
double weight = 3.75; // 存储重量(千克)
char symbol = '$'; // 存储货币符号
// 使用变量
cout << "我有 " << apples << " 个苹果,总重量 " << weight << "kg" << endl;
cout << "单价:" << symbol << "10" << endl;
// 修改变量的值
apples = 10;
cout << "现在有 " << apples << " 个苹果!" << endl;
return 0;
}输出:
我有 5 个苹果,总重量 3.75kg
单价:$10
现在有 10 个苹果!温馨小贴士:
-
先定义,后使用:
int x = 10; cout << x; // ✅ 正确 cout << y; // ❌ 错误:y 未定义 -
避免未初始化:
int num; cout << num; // ❌ 危险:num 的值不确定! -
作用域限制:
{ int temp = 42; cout << temp; // ✅ } cout << temp; // ❌ temp 已超出作用域
小结
变量的定义是编程中的“声明存储空间”行为,相当于告诉计算机:
类型:“我要存一个整数(
int)。”名字:“这个空间叫
count。”初始值:“现在里面放数字 0。”
通过定义变量,程序才能安全、高效地操作数据。 🖥️
变量定义和声明的关系
变量的声明(Declaration)
-
作用:告诉编译器“存在这样一个变量”,包括它的类型和名字。
-
语法:使用
extern关键字(表示“这个变量在其他地方定义”)。 -
特点:
-
不分配内存。
-
可以多次声明同一个变量(但通常不建议)。
-
// 声明一个变量 age(告诉编译器它存在,但内存尚未分配)
extern int age;
变量的定义(Definition)
-
作用:实际创建变量,分配内存,并可初始化。
-
特点:
-
分配内存。
-
只能定义一次(否则会引发“重复定义”错误)。
-
int age = 20; // 定义变量 age(分配内存并初始化)关键区别
| 声明(Declaration) | 定义(Definition) | |
|---|---|---|
| 内存分配 | ❌ 不分配内存 | ✅ 分配内存 |
| 允许次数 | 可多次声明(需用 extern) | 只能定义一次 |
| 初始化 | 不能初始化(因为没内存) | 可以初始化 |
| 代码示例 | extern int age; | int age = 20; |
实际应用场景(现在不理解没关系,后边我会讲到,目前有个印象就行)
场景 1:多文件编程
-
头文件(
.h):通过extern声明变量(告诉其他文件变量存在)。 -
源文件(
.cpp):定义变量(分配内存)。
// 在 header.h 中声明变量
extern int globalCount; // 声明(不分配内存)
// 在 source.cpp 中定义变量
int globalCount = 0; // 定义(分配内存并初始化)场景 2:避免重复定义
如果多个文件直接定义同一个全局变量,会导致链接错误:
// file1.cpp
int globalVar = 42; // ❌ 定义(分配内存)
// file2.cpp
int globalVar = 42; // ❌ 重复定义!正确做法:
// file1.cpp
int globalVar = 42; // ✅ 定义(分配内存)
// file2.cpp
extern int globalVar; // ✅ 声明(告诉编译器变量在其他文件定义)小结
声明是“预告”,定义是“实现”。
定义会分配内存,声明不会。
在大型项目中,通过
extern声明共享变量,通过定义确保唯一性。一句话:声明是“我知道它存在”,定义是“我创造了它”。 🛠️
标识符
是为变量、函数、类、结构体、命名空间等程序元素自定义的名称。它相当于代码中的“名字标签”,用于唯一标识某个实体
标识符的核心规则
-
允许的字符:
-
字母(A-Z, a-z)、数字(0-9)、下划线(
_)。 -
首字符不能是数字(如
2name❌,name2✅)。 -
区分大小写(
Age和age是两个不同的标识符)。
-
-
禁止使用关键字:
-
不能用 C++ 的保留关键字(如
int、class、return❌)。
-
-
命名规范(非强制,但建议遵守):
-
有意义:
studentAge比sa更清晰。 -
驼峰命名法:
calculateTotalPrice(函数名、变量名)。 -
下划线分隔:
MAX_SIZE(常用于常量)。
-
合法 vs 非法标识符的栗子
| 合法标识符 | 非法标识符 | 原因 |
|---|---|---|
age | 3rd_place | 以数字开头 |
_tempValue | class | 使用关键字 class |
calculateAverage | total-price | 包含非法字符 - |
MAX_LENGTH | user name | 包含空格 |
温馨小贴士:
-
长度限制:
C++ 标准不限制标识符长度,但编译器可能有内部限制(一般足够长)。 -
作用域冲突:
同一作用域内不能重复定义同名标识符。int value = 10; int value = 20; // ❌ 错误:重复定义 -
Unicode 支持(C++11 起):
允许使用非英文字符(如中文、日文),但需谨慎(真的很不推荐)。int 年龄 = 20; // ✅ 合法,但不推荐
小结
标识符就像代码里的“身份证”——名字要合法、清晰、唯一(在作用域内)! 🏷️
变量的作用域
通俗来说,作用域就像一个个“房间”,房间内的东西只能在这个房间内被看到和使用,超出房间就无效了。
全局作用域(Global Scope)
-
范围:整个程序(所有文件)。
-
定义位置:在所有函数和代码块之外。
-
特点:
-
生命周期:从程序启动到结束。
-
默认初始化为 0(未显式初始化时)。
-
容易被滥用(可能导致命名冲突)。
-
#include <iostream>
int globalVar = 10; // 全局变量(全局作用域)
int main() {
std::cout << globalVar; // ✅ 可以访问
return 0;
}局部作用域(Local Scope)
-
范围:函数内部或代码块(如
{}内部)。 -
定义位置:函数体内或代码块内。
-
特点:
-
生命周期:进入作用域时创建,离开时销毁。
-
未初始化时值为随机(垃圾值)。
-
void myFunction() {
int localVar = 20; // 局部变量(局部作用域)
std::cout << localVar; // ✅
}
int main() {
myFunction();
std::cout << localVar; // ❌ 错误:localVar 在此不可见
return 0;
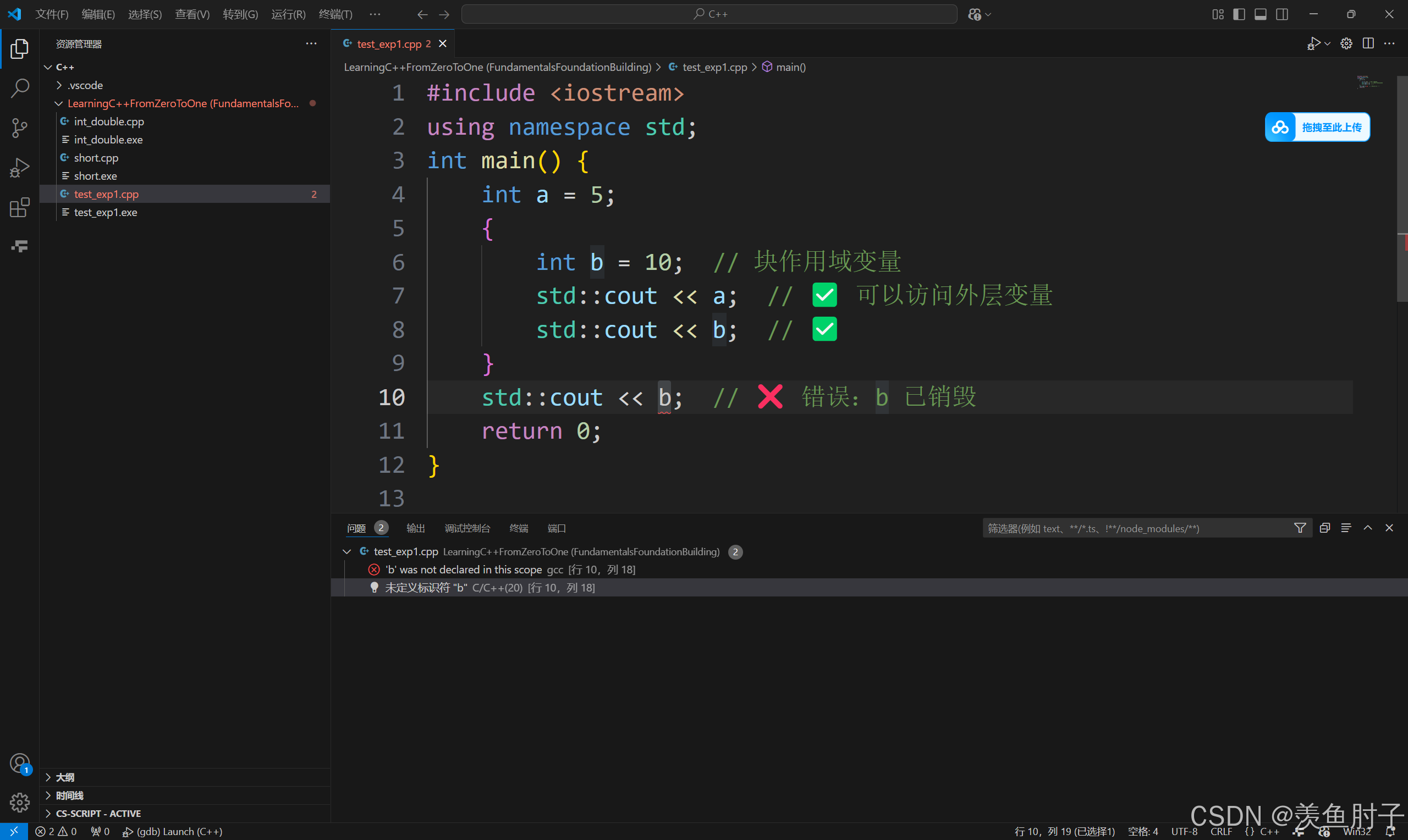
}块作用域(Block Scope)
-
范围:由
{}包裹的代码块(如if、for、while)。 -
定义位置:代码块内部。
-
特点:
-
常用于临时变量(如循环计数器)。
-
变量在代码块结束时销毁。
-
int main() {
int a = 5;
{
int b = 10; // 块作用域变量
std::cout << a; // ✅ 可以访问外层变量
std::cout << b; // ✅
}
std::cout << b; // ❌ 错误:b 已销毁
return 0;
}看看结果
命名空间作用域(Namespace Scope)
-
范围:命名空间内部。
-
定义位置:在
namespace关键字定义的区域内。 -
特点:
-
解决全局作用域的命名冲突。
-
通过
命名空间::标识符访问。
-
namespace MyLib {
int value = 30; // 命名空间作用域
}
int main() {
std::cout << MyLib::value; // ✅ 通过命名空间访问
return 0;
}类作用域(Class Scope)
-
范围:类的内部(成员变量、成员函数)。
-
定义位置:类定义的大括号
{}内。 -
特点:
-
成员变量和函数需要通过对象或类名访问。
-
静态成员属于类作用域,但生命周期可能更长。
-
class MyClass {
public:
static int staticVar; // 类作用域(静态成员)
int memberVar; // 类作用域(成员变量)
};
int MyClass::staticVar = 40;
int main() {
MyClass obj;
obj.memberVar = 50;
std::cout << MyClass::staticVar; // ✅ 通过类名访问
return 0;
}作用域的嵌套与遮蔽(Shadowing)
-
规则:内层作用域可以定义与外层同名的标识符,此时外层标识符被暂时“遮蔽”。
-
小贴士:遮蔽可能导致代码可读性下降,一定要谨慎使用哦。
int x = 100; // 全局变量
int main() {
int x = 200; // 局部变量遮蔽全局变量
std::cout << x; // 输出 200(访问局部变量)
std::cout << ::x; // 输出 100(通过 :: 访问全局变量)
return 0;
}小结
-
作用域是变量的“有效区域”,超出区域则无法访问。
-
合理使用作用域能写出更安全、清晰的代码。
-
全局变量少用,局部变量多用,块变量按需使用! 🚪
复合类型
是由基本类型(如
int、double)或其他复合类型组合而成的数据类型,用于表示更复杂的数据结构。通俗来说,它们像是“容器”或“盒子”,可以将多个数据打包在一起,方便统一操作。目前先介绍两种引用和指针,其他的会在后边介绍。
引用和指针
引用(Reference) 和 指针(Pointer) 都是用于间接操作数据的工具,但它们的设计目标、语法和用途有显著区别。
我认为对比学习一种比较好的学习方法,所以我把引用和指针这两个c++中比较难理解的概念对比学习
1. 基本概念
指针(Pointer)
-
是什么:指针是一个变量,存储另一个变量的 内存地址。
-
特点:
-
需要显式解引用(用
*)访问数据。 -
可以指向
nullptr(空指针)。 -
支持重新指向其他地址。
-
-
语法:
int num = 10; int* ptr = # // ptr 存储 num 的地址 *ptr = 20; // 通过指针修改 num 的值为 20
引用(Reference)
-
是什么:引用是变量的 别名,与原始变量共享同一内存地址。
-
特点:
-
必须在定义时初始化,且不能重新绑定到其他变量。
-
操作引用就像操作原变量(无需解引用)。
-
不存在空引用。
-
-
语法:
int num = 10; int& ref = num; // ref 是 num 的别名 ref = 20; // 直接修改 num 的值为 20
2. 核心区别
| 特性 | 指针(Pointer) | 引用(Reference) |
|---|---|---|
| 初始化 | 可以不初始化(但危险) | 必须初始化 |
| 空值 | 支持 nullptr | 不能为空 |
| 重绑定 | 可以指向其他地址 | 绑定后不可更改 |
| 内存占用 | 占用内存(存储地址) | 不额外占用内存(别名) |
| 操作语法 | 用 * 解引用,-> 访问成员 | 直接操作,像普通变量 |
| 多级间接访问 | 支持多级指针(如 int**) | 不支持多级引用 |
3. 使用场景
(看不懂没关系的,目前可以跳过,将所有基础篇学完之后回来再看就会很清楚啦)
适合用指针的场景:
-
动态内存管理:如使用
new和delete分配堆内存。int* arr = new int[10]; delete[] arr; -
可选参数:允许函数参数为空。
void print(int* ptr) { if (ptr != nullptr) cout << *ptr; } -
数据结构:如链表、树等需要灵活指向的场合。
struct Node { int data; Node* next; // 指向下一个节点 };
适合用引用的场景:
-
函数参数传递:避免拷贝大型对象。
void modifyValue(int& ref) { ref *= 2; // 直接修改原变量 } -
返回值优化:返回容器或大型对象的引用(如
std::vector<T>&)。std::string& getLongName() { static std::string name = "Alice"; return name; } -
操作符重载:如
<<、>>的实现。ostream& operator<<(ostream& os, const MyClass& obj) { os << obj.data; return os; }
4. 代码示例对比
修改原变量
// 使用指针
void changeViaPointer(int* ptr) {
*ptr = 100;
}
// 使用引用
void changeViaReference(int& ref) {
ref = 200;
}
int main() {
int a = 10;
changeViaPointer(&a); // 需传递地址
changeViaReference(a); // 直接传递变量
cout << a; // 输出 200
return 0;
}空值安全性(这是个重点呢)
int* ptr = nullptr; // 合法,但解引用会崩溃
int& ref; // ❌ 错误:引用必须初始化一句话记忆:
指针是“可以指向任何地址的遥控器”。
引用是“固定绑定到某个对象的快捷方式”。
合理选择引用和指针,能写出既高效又安全的代码! 🛠️
下一篇会学习有关const 限定符相关的内容



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











