







与 Microsoft Windows 2000 显示驱动程序模型不同,Windows Vista 显示驱动程序模型允许创建比可用物理视频内存总量更多的视频内存资源,然后根据需要分页进出视频内存。 换句话说,并非所有视频内存资源都同时位于视频内存中。
GPU 的管道中可以有多个 DMA 缓冲区。 这些活动 DMA 缓冲区引用的视频内存资源必须位于视频内存中。 其他空闲视频内存资源可以分页到系统内存。
在 GPU 计划程序调用显示微型端口驱动程序的 DxgkDdiSubmitCommand 函数以将 DMA 缓冲区提交到 GPU 之前,计划程序必须确保 DMA 缓冲区使用的所有视频内存资源实际上都在视频内存中。 如果某些资源不在视频内存中,则必须从系统内存中分页。 GPU 计划程序必须调用视频内存管理器来查找视频内存中的空间,以便将必要的视频内存资源数据从系统内存传输到视频内存。 当视频内存需求较高时,GPU 计划程序必须调用视频内存管理器,以将空闲视频内存资源数据传输到系统内存,以便为所需的视频内存资源数据腾出空间。 包含用于在视频和系统内存之间传输数据的命令的特殊用途 DMA 缓冲区称为分页缓冲区。 视频内存管理器调用显示微型端口驱动程序的 DxgkDdiBuildPagingBuffer 函数来创建分页缓冲区,驱动程序将硬件特定的数据传输命令写入该缓冲区。
1. 内存虚拟化架构对比
Windows 2000 (XPDM) 模型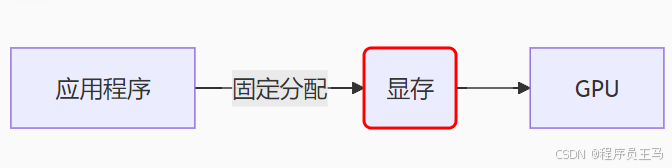
- 静态分配:资源一旦创建即永久占用显存
- 硬性限制:总资源大小 ≤ 物理显存容量
- 问题:多应用竞争显存时需频繁切换上下文
Windows Vista+ (WDDM) 模型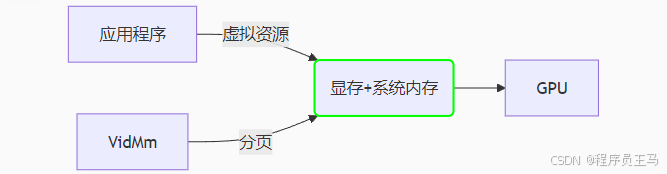
- 虚拟化池:所有应用共享的虚拟显存空间(物理显存 + 系统内存)
- 按需分页:仅活跃资源占用物理显存
- 优势:支持的总资源量 >> 物理显存容量
2. 关键组件协作流程
(1) 分页触发条件
当 GPU 调度器准备提交 DMA 缓冲区时:
BOOL CheckResourceResidency(DMA_BUFFER* dmaBuffer) {
foreach (Resource* res in dmaBuffer->ReferencedResources) {
if (!res->IsResidentInVRAM()) { // 检查物理显存驻留
TriggerPaging(res); // 触发分页操作
return FALSE;
}
}
return TRUE;
}(2) 分页缓冲区构建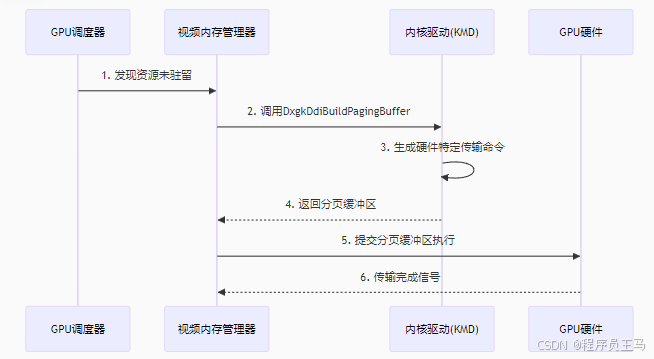
(3) 分页缓冲区示例内容
// AMD GPU 的分页命令示例
struct PAGE_COMMAND {
uint64_t srcSysMemAddr; // 系统内存源地址
uint64_t dstVramAddr; // 显存目标地址
uint32_t size; // 传输数据大小
uint32_t tilingFlags; // 块状排列参数
};
void BuildPagingBuffer(PAGE_COMMAND* buffer, Resource* res) {
buffer->srcSysMemAddr = res->sysMemBacking;
buffer->dstVramAddr = VidMmAllocVram(res->size);
buffer->size = res->size;
buffer->tilingFlags = res->tilingMode;
}3. 内存管理策略
(1) 驻留集管理
- 活动集(Working Set):当前 DMA 缓冲区引用的资源必须驻留
- LRU 策略:非活跃资源按最近使用时间排序逐出
void VidMmEvictResources(uint64_t requiredSize) {
while (freeVram < requiredSize) {
Resource* victim = FindLRUResource();
CopyToSystemMemory(victim); // 回写系统内存
FreeVram(victim->vramAddr);
}
}(2) 并发控制
栅栏(Fence)同步:确保分页操作完成前 GPU 不访问资源
void SubmitPagingBuffer(DMA_BUFFER* pagingBuf) {
uint64_t fenceVal = InsertFence();
QueueToGpu(pagingBuf, fenceVal);
WaitForFence(fenceVal); // 等待传输完成
}4. 开发者注意事项
用户模式驱动(UMD)
// 创建资源时应考虑分页开销
HRESULT CreateTexture(UINT size, bool isFrequentlyUsed) {
D3DDDI_ALLOCATIONINFO info = {0};
if (isFrequentlyUsed) {
info.Flags.PreferContiguous = 1; // 提示VidMm优先驻留
}
return pfnAllocateCb(&info);
}内核模式驱动(KMD)
// 必须正确处理分页失败
NTSTATUS DxgkDdiBuildPagingBuffer(
IN_PDXGKARG_BUILDPAGINGBUFFER pArgs)
{
if (!CheckHwCapability(pArgs->SizeRequired)) {
return STATUS_GRAPHICS_INSUFFICIENT_DMA_BUFFER;
}
// ...生成硬件命令
}5. 性能优化技巧
| 技术 | 适用场景 | 实现方式 |
|---|---|---|
| 预加载(Preload) | 关键帧资源加载 | 在Present前异步提交分页请求 |
| 批量传输 | 大量小资源迁移 | 合并多个资源到单个分页缓冲区 |
| 压缩分页 | 带宽受限系统 | 实现驱动级内存压缩/解压 |
| 智能驻留 | 开放世界游戏地形 | 使用D3DDDI_ALLOCATIONFLG_PERSISTENT标记 |
6. 调试与问题排查
常见问题症状
- GPU 挂起:分页操作未完成导致依赖等待
- 帧率骤降:频繁分页引发带宽瓶颈
- 纹理闪烁:分页同步错误导致部分更新
诊断工具
# Windows Performance Analyzer (WPA)
wpaexporter.exe -d Graphics.gpuperf -o trace.csv
# WinDbg 命令
!dxgkd_ext.vidmm -stats # 显示内存分布统计
!dxgkd_ext.resource 0xADDR # 检查资源状态演进与现状
Windows 10+ 改进:
- 内存优先级:支持资源优先级分层管理
- 直接存储:绕过CPU直接分页(GPU←→NVMe)
- UMA优化:统一内存架构下的零拷贝分页
开发者适配建议:
// 使用DX12内存池提示
D3D12_HEAP_PROPERTIES heapProps = {
.Type = D3D12_HEAP_TYPE_DEFAULT,
.CPUPageProperty = D3D12_CPU_PAGE_PROPERTY_NOT_AVAILABLE,
.MemoryPoolPreference = D3D12_MEMORY_POOL_L1 // 显存优先
};WDDM 的内存虚拟化机制通过精细的分页策略和硬件加速,实现了 GPU 内存资源的弹性管理,为现代图形应用提供了更大的资源池和更高的内存利用率,同时也对驱动开发者的内存管理能力提出了更高要求。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









