






本文旨在说明Java中Stream API的常用方法。
1、概述
相信学习Java语言开发的朋友们对Java8(又叫jdk1.8)都不陌生,Java8是oracle公司于2014年3月发布,虽然目前Java版本在不断更迭,目前最新版本应该已经到了Java19(Java Archive | Oracle),但还是有不少企业在开发、生产过程中使用jdk1.8,本文对jdk1.8不做过多的介绍,有兴趣的朋友可以自行百度了解,本文主要是围绕jdk1.8中的新特性Stream的使用展开,了解什么是Stream流,Stream流有哪些特性,stream操作的分类以及通过代码学会常见的API的使用。
2、Stream流简介
Stream是java8的新特性,也是java8的一大亮点,和java.io中的inputstream、outputstream是不一样的概念,它是对集合和数组对象功能的增强(专注于对集合对象和数组进行非常高效的遍历操作)。它具有几个特性:不存储数据;不改变数据源;具有延迟执行的特性,只有调用终端操作时,中间操作才会执行。
当我们使用Stream流,通常基于获取一个数据源(source)→ 数据转换 → 执行操作获取想要的结果这个步骤,每次转换原有 Stream 对象不改变,返回一个新的 Stream 对象(可以有多次转换)。
当然说到Stream流,不得不提一嘴Lambda 表达式,Lambda 表达式也是Java8中出现的,函数式编程使代码更加简洁,极大的提高了编程效率和程序可读性(这里的可读性建立在理解的基础上)。
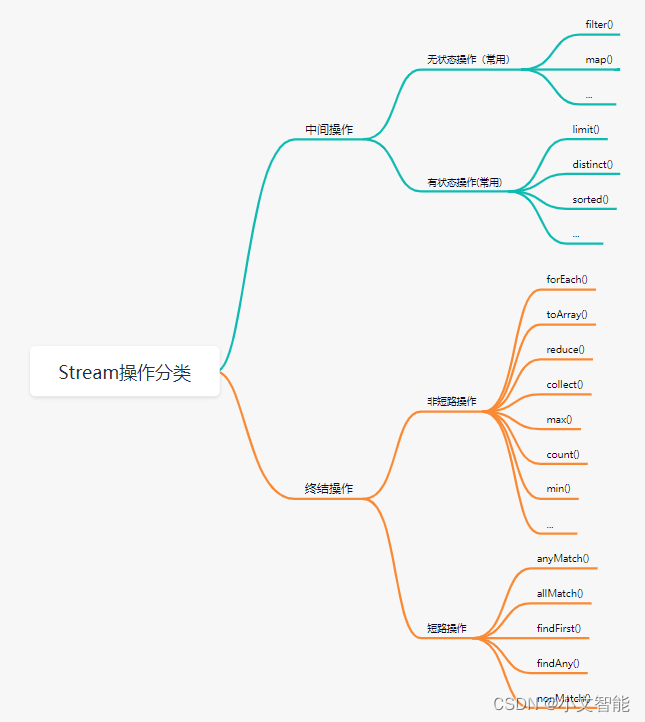
3、Stream操作分类
Stream的操作大致可以分为中间操作和终结操作两大类,其中中间操作分为无状态操作和有状态操作,总结操作分为短路操作和非短路操作。
· 无状态操作:元素的处理不受之前元素的影响。
· 有状态操作:该操作只有拿到所有元素之后才能继续。
· 短路操作:遇到某些符合条件的元素直接得到最终结果。
· 非短路操作:必须处理完所有元素才能得到最终结果。
4、Stream的使用(API)
好了说了这么多废话,可能表述的也不一定那么准确,可能很多人也不会细看,
好吧,下面还是通过代码来直观的了解一些开发过程中经常使用的API吧。
看代码之前,先了解下Optional类,Optional类是一个可以为null的容器对象。如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象。
防止有些不熟悉的朋友对实体类和Map类型的处理有疑问,我先定义一个实体类Person和Map,针对List<Person>和List<Map>的操作,后续的操作都会基于这两个List分别进行。
/**
* 实体类
*/
@Data
public class Person {
private String name; //姓名
private Integer age; //年龄
private String sex; //性别
private Integer salary;//薪水
}//构建List<Person>
List<Person> personList = new ArrayList<>();
Person person1 = new Person();
person1.setName("张三");
person1.setAge(30);
person1.setSex("男");
person1.setSalary(10000);
personList.add(person1);
Person person2 = new Person();
person2.setName("如花");
person2.setAge(20);
person2.setSex("女");
person2.setSalary(5000);
personList.add(person2);
//构建List<Map<String, Object>>
List<Map<String, Object>> personMapList = new ArrayList<>();
Map<String, Object> personMap1 = new HashMap<>();
personMap1.put("name", "张三");
personMap1.put("age", 30);
personMap1.put("sex", "男");
personMap1.put("salary", 10000);
personMapList.add(personMap1);
Map<String, Object> personMap2 = new HashMap<>();
personMap2.put("name", "如花");
personMap2.put("age", 20);
personMap2.put("sex", "女");
personMap2.put("salary", 5000);
personMapList.add(personMap2);
4.1、 流的创建
/**
* 流的创建
* stream是顺序流,由主线程按顺序对流执行操作,
* parallelStream是并行流,内部以多线程并行执行的方式对流进行操作
*/
public void testCreate() {
// 1、 java.util.Collection.stream() 方法用集合创建流
// 创建一个集合
List<String> list = Arrays.asList("a", "b", "c");
// 创建顺序流
Stream<String> stream = list.stream();
// 创建并行流
Stream<String> parallelStream1 = list.parallelStream();
// 也可以通过parallel()把顺序流转换成并行流
Stream<String> parallelStream2 = list.stream().parallel();
// 2、java.util.Arrays.stream(T[] array)方法用数组创建流
String[] array = {"a", "b", "c"};
Stream<String> arrayStream = Arrays.stream(array);
// 3、Stream的静态方法 of()、iterate()、generate()
Stream<Integer> stream1 = Stream.of(1, 2, 3);
Stream<Integer> stream2 = Stream.iterate(0, (x) -> x + 3).limit(4);
Stream<Double> stream3 = Stream.generate(Math::random).limit(3);
}
4.2、forEach
/**
* forEach的用法
* 遍历出所有姓名
*/
public static void main(String[] args) {
personList.stream()
.forEach(person -> System.out.println(person.getName()));
personMapList.stream()
.forEach(person -> System.out.println(MapUtil.getStringValue(person, "name")));
}
4.2、find
/**
* find用法
*/
public static void main(String[] args) {
// 匹配第一个
Optional<Person> findFirst1 = personList.stream().findFirst();
Person person = findFirst1.get();
System.out.println("匹配第一个值:" + person.getName());
Optional<Map<String, Object>> findFirst2 = personMapList.stream().findFirst();
Map<String, Object> personMap = findFirst2.get();
System.out.println("匹配第一个值:" + MapUtil.getStringValue(personMap, "name"));
// 匹配任意(适用于并行流)
Optional<Person> findAnyPerson = personList.parallelStream().filter(p -> p.getAge() > 10).findAny();
Person person1 = findAnyPerson.get();
System.out.println("匹配任意一个值:" + person1.getName());
Optional<Map<String, Object>> findAnyMap = personMapList.parallelStream().filter(p -> MapUtil.getIntegerValue(personMap, "age") > 10).findAny();
Map<String, Object> personMap1 = findAnyMap.get();
System.out.println("匹配任意一个值:" + MapUtil.getStringValue(personMap1, "name"));
}
4.3、match
/**
* anyMatch用法
*/
public static void main(String[] args) {
// 是否包含符合特定条件的元素
boolean anyMatch1 = personList.stream().anyMatch(p -> p.getAge() > 10);
System.out.println("是否存在年龄大于10岁的:" + anyMatch1);
boolean anyMatch2 = personMapList.stream().anyMatch(p -> MapUtil.getIntegerValue(personMap, "age") > 10);
System.out.println("是否存在年龄大于10岁的:" + anyMatch2);
}
4.3、filter
filter其实在上述几个例子中均有所使用,即筛选
/**
* filter用法
*/
public static void main(String[] args) {
//输出性别是男的元素
personList.stream().filter(p->"男".equals(p.getSex())).forEach(System.out::println);
personMapList.stream().filter(p->"男".equals(MapUtil.getStringValue(p, "sex"))).forEach(System.out::println);
}
4.4、max/min/count
/**
* max,min,count用法
*/
public static void main(String[] args) {
//max
Optional<Person> max1 = personList.stream().max(Comparator.comparing(Person::getAge));
Person person = max1.get();
System.out.println(person.getName()+","+person.getAge());
Optional<Map<String,Object>> max2 = personMapList.stream().max(Comparator.comparing(p->MapUtil.getIntegerValue(p, "age")));
Map<String, Object> personMap = max2.get();
System.out.println(MapUtil.getStringValue(personMap,"name")+","+MapUtil.getIntegerValue(personMap,"age"));
//min
Optional<Person> min1 = personList.stream().min(Comparator.comparing(Person::getAge));
Person person1 = min1.get();
System.out.println(person1.getName()+","+person1.getAge());
Optional<Map<String,Object>> min2 = personMapList.stream().min(Comparator.comparing(p->MapUtil.getIntegerValue(p, "age")));
Map<String, Object> personMap1 = min2.get();
System.out.println(MapUtil.getStringValue(personMap1,"name")+","+MapUtil.getIntegerValue(personMap1,"age"));
//count
long nanCount1 = personList.stream().filter(p->"男".equals(p.getSex())).count();
System.out.println(nanCount1);
long nanCount2 = personMapList.stream().filter(p->"男".equals(MapUtil.getStringValue(p,"sex"))).count();
System.out.println(nanCount2);
}
4.5、map和peek
public static void main(String[] args) {
//map,提取姓名形成新的list
List<String> collect1 = personList.stream().map(Person::getName).collect(Collectors.toList());
collect1.forEach(System.out::println);
List<String> collect2 = personMapList.stream().map(p->MapUtil.getStringValue(p,"name")).collect(Collectors.toList());
collect2.forEach(System.out::println);
//peek, salary字段全部加1000
List<Person> collect3 = personList.stream().peek(p -> {
p.setSalary(p.getSalary() + 1000);
}).collect(Collectors.toList());
collect3.forEach(System.out::println);
List<Map<String, Object>> collect4 = personMapList.stream().peek(p -> {
p.put("salary", MapUtil.getIntegerValue(p,"salary")+1000);
}).collect(Collectors.toList());
collect4.forEach(System.out::println);
}
4.6、collect
public static void main(String[] args) {
//toList
List<Person> toList1 = personList.stream().filter(p -> p.getAge() > 10).collect(Collectors.toList());
List<Map<String, Object>> toList2 = personMapList.stream().filter(p -> MapUtil.getIntegerValue(p, "age") > 10).collect(Collectors.toList());
//toSet
Set<Person> toSet1 = personList.stream().filter(p -> p.getAge() > 10).collect(Collectors.toSet());
Set<Map<String, Object>> toSet2 = personMapList.stream().filter(p -> MapUtil.getIntegerValue(p, "age") > 10).collect(Collectors.toSet());
//toMap
Map<String, Person> toMap1 = personList.stream().filter(p -> p.getSalary() > 5000).collect(Collectors.toMap(Person::getName, p -> p));
Map<String, Map<String, Object>> toMap2 = personMapList.stream().filter(p -> MapUtil.getIntegerValue(p, "salary") > 5000)
.collect(Collectors.toMap(p -> MapUtil.getStringValue(p, "name"), p -> p));
//统计所有信息(总数量, 总和, 最大值, 最小值,平均值)
DoubleSummaryStatistics statistics1 = personList.stream().collect(Collectors.summarizingDouble(Person::getSalary));
//DoubleSummaryStatistics{count=2, sum=15000.000000, min=5000.000000, average=7500.000000, max=10000.000000}
DoubleSummaryStatistics statistics2 = personMapList.stream().collect(Collectors.summarizingDouble(p -> MapUtil.getIntegerValue(p, "salary")));
//分组
// partitioningBy
Map<Boolean, List<Person>> part1 = personList.stream().collect(Collectors.partitioningBy(p -> p.getSalary() > 5000));
Map<Boolean, List<Map<String, Object>>> part2 = personMapList.stream().collect(Collectors.partitioningBy(p -> MapUtil.getIntegerValue(p, "salary") > 5000));
//groupingBy 按性别分组
Map<String, List<Person>> group1 = personList.stream().collect(Collectors.groupingBy(Person::getSex));
Map<String, List<Map<String, Object>>> group2 = personMapList.stream().collect(Collectors.groupingBy(p -> MapUtil.getStringValue(p, "sex")));
//groupingBy 先性别,再按姓名分组
Map<String, Map<String, List<Person>>> a = personList.stream().collect(Collectors.groupingBy(Person::getSex, Collectors.groupingBy(Person::getName)));
//joining
String names = personList.stream().map(Person::getName).collect(Collectors.joining(","));
}
4.7、sorted
public static void main(String[] args) {
//sorted
List<String> sortList1 = personList.stream().sorted(Comparator.comparing(Person::getSalary).reversed())
.map(Person::getName).collect(Collectors.toList());
List<String> sortList2 = personList.stream()
.sorted(Comparator.comparing(Person::getSalary).thenComparing(Person::getAge)).map(Person::getName)
.collect(Collectors.toList());
}
4.8、distinct/limit/skip
public static void main(String[] args) {
//distinct
String[] arr1 = { "a", "b", "c" };
String[] arr2 = { "b", "c", "d", "e" };
Stream<String> stream1 = Stream.of(arr1);
Stream<String> stream2 = Stream.of(arr2);
List<String> distinct = Stream.concat(stream1, stream2).distinct().collect(Collectors.toList());
//limit
List<Integer> limit = Stream.iterate(1, s -> s + 2).limit(10).collect(Collectors.toList());
//skip
List<Integer> skip = Stream.iterate(1, s -> s + 2).skip(1).limit(5).collect(Collectors.toList());
}
上文仅是介绍了部分平时开发中经常需要使用到的方法,抛砖引玉,可自行通过代码实现联系,若遇到本文没有介绍的方法,可以通过官方API查看学习。















 2222
2222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











