










本教程的知识点为:爬虫概要 爬虫基础 爬虫概述 知识点: 1. 爬虫的概念 requests模块 requests模块 知识点: 1. requests模块介绍 1.1 requests模块的作用: 数据提取概要 数据提取概述 知识点 1. 响应内容的分类 知识点:了解 响应内容的分类 Selenium概要 selenium的介绍 知识点: 1. selenium运行效果展示 1.1 chrome浏览器的运行效果 Selenium概要 selenium的其它使用方法 知识点: 1. selenium标签页的切换 知识点:掌握 selenium控制标签页的切换 反爬与反反爬 常见的反爬手段和解决思路 学习目标 1 服务器反爬的原因 2 服务器常反什么样的爬虫 反爬与反反爬 验证码处理 学习目标 1.图片验证码 2.图片识别引擎 反爬与反反爬 JS的解析 学习目标: 1 确定js的位置 1.1 观察按钮的绑定js事件 Mongodb数据库 介绍 内容 mongodb文档 mongodb的简单使用 Mongodb数据库 介绍 内容 mongodb文档 mongodb的聚合操作 Mongodb数据库 介绍 内容 mongodb文档 mongodb和python交互 scrapy爬虫框架 介绍 内容 scrapy官方文档 scrapy的入门使用 scrapy爬虫框架 介绍 内容 scrapy官方文档 scrapy管道的使用 scrapy爬虫框架 介绍 内容 scrapy官方文档 scrapy中间件的使用 scrapy爬虫框架 介绍 内容 scrapy官方文档 scrapy_redis原理分析并实现断点续爬以及分布式爬虫 scrapy爬虫框架 介绍 内容 scrapy官方文档 scrapy的日志信息与配置 利用appium抓取app中的信息 介绍 内容 appium环境安装 学习目标
全套笔记资料代码移步: 前往gitee仓库查看
感兴趣的小伙伴可以自取哦~
全套教程部分目录:


部分文件图片:
requests模块
本阶段主要学习requests这个http模块,该模块主要用于发送请求获取响应,该模块有很多的替代模块,比如说urllib模块,但是在工作中用的最多的还是requests模块,requests的代码简洁易懂,相对于臃肿的urllib模块,使用requests编写的爬虫代码将会更少,而且实现某一功能将会简单。因此建议大家掌握该模块的使用
requests模块
知识点:
- 掌握 headers参数的使用
- 掌握 发送带参数的请求
- 掌握 headers中携带cookie
- 掌握 cookies参数的使用
- 掌握 cookieJar的转换方法
- 掌握 超时参数timeout的使用
- 掌握 ip参数proxies的使用
- 掌握 使用verify参数忽略CA证书
- 掌握 requests模块发送post请求
- 掌握 利用requests.session进行状态保持
前面我们了解了爬虫的基础知识,接下来我们来学习如何在代码中实现我们的爬虫
1. requests模块介绍
requests文档[
1.1 requests模块的作用:
- 发送http请求,获取响应数据
1.2 requests模块是一个第三方模块,需要在你的python(虚拟)环境中额外安装
pip/pip3 install requests
1.3 requests模块发送get请求
- 需求:通过requests向百度首页发送请求,获取该页面的源码
- 运行下面的代码,观察打印输出的结果
# 1.2.1-简单的代码实现
import requests
# 目标url
url = '
# 向目标url发送get请求
response = requests.get(url)
# 打印响应内容
print(response.text)
知识点:掌握 requests模块发送get请求
2. response响应对象
观察上边代码运行结果发现,有好多乱码;这是因为编解码使用的字符集不同早造成的;我们尝试使用下边的办法来解决中文乱码问题
# 1.2.2-response.content
import requests
# 目标url
url = '
# 向目标url发送get请求
response = requests.get(url)
# 打印响应内容
# print(response.text)
print(response.content.decode()) # 注意这里!
- response.text是requests模块按照chardet模块推测出的编码字符集进行解码的结果
- 网络传输的字符串都是bytes类型的,所以response.text = response.content.decode('推测出的编码字符集')
- 我们可以在网页源码中搜索
charset,尝试参考该编码字符集,注意存在不准确的情况
2.1 response.text 和response.content的区别:
-
response.text
-
类型:str
-
解码类型: requests模块自动根据HTTP 头部对响应的编码作出有根据的推测,推测的文本编码
-
response.content
-
类型:bytes
- 解码类型: 没有指定
知识点:掌握 response.text和response.content的区别
2.2 通过对response.content进行decode,来解决中文乱码
response.content.decode()默认utf-8response.content.decode("GBK")-
常见的编码字符集
-
utf-8
- gbk
- gb2312
- ascii (读音:阿斯克码)
- iso-8859-1
知识点:掌握 利用decode函数对requests.content解决中文乱码
2.3 response响应对象的其它常用属性或方法
response = requests.get(url)中response是发送请求获取的响应对象;response响应对象中除了text、content获取响应内容以外还有其它常用的属性或方法:
response.url响应的url;有时候响应的url和请求的url并不一致response.status_code响应状态码response.request.headers响应对应的请求头response.headers响应头response.request._cookies响应对应请求的cookie;返回cookieJar类型response.cookies响应的cookie(经过了set-cookie动作;返回cookieJar类型response.json()自动将json字符串类型的响应内容转换为python对象(dict or list)
# 1.2.3-response其它常用属性
import requests
# 目标url
url = '
# 向目标url发送get请求
response = requests.get(url)
# 打印响应内容
# print(response.text)
# print(response.content.decode()) # 注意这里!
print(response.url) # 打印响应的url
print(response.status_code) # 打印响应的状态码
print(response.request.headers) # 打印响应对象的请求头
print(response.headers) # 打印响应头
print(response.request._cookies) # 打印请求携带的cookies
print(response.cookies) # 打印响应中携带的cookies
知识点:掌握 response响应对象的其它常用属性
3. requests模块发送请求
3.1 发送带header的请求
我们先写一个获取百度首页的代码
import requests
url = '
response = requests.get(url)
print(response.content.decode())
# 打印响应对应请求的请求头信息
print(response.request.headers)
3.1.1 思考
-
对比浏览器上百度首页的网页源码和代码中的百度首页的源码,有什么不同?
-
查看网页源码的方法:
- 右键-查看网页源代码 或
- 右键-检查
-
对比对应url的响应内容和代码中的百度首页的源码,有什么不同?
-
查看对应url的响应内容的方法:
- 右键-检查
- 点击
Net work - 勾选
Preserve log - 刷新页面
- 查看
Name一栏下和浏览器地址栏相同的url的Response
-
代码中的百度首页的源码非常少,为什么?
-
需要我们带上请求头信息
回顾爬虫的概念,模拟浏览器,欺骗服务器,获取和浏览器一致的内容
-
请求头中有很多字段,其中User-Agent字段必不可少,表示客户端的操作系统以及浏览器的信息
3.1.2 携带请求头发送请求的方法
requests.get(url, headers=headers)
- headers参数接收字典形式的请求头
- 请求头字段名作为key,字段对应的值作为value
3.1.3 完成代码实现
从浏览器中复制User-Agent,构造headers字典;完成下面的代码后,运行代码查看结果
import requests
url = '
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 在请求头中带上User-Agent,模拟浏览器发送请求
response = requests.get(url, headers=headers)
print(response.content)
# 打印请求头信息
print(response.request.headers)
知识点:掌握 headers参数的使用
3.2 发送带参数的请求
我们在使用百度搜索的时候经常发现url地址中会有一个
?,那么该问号后边的就是请求参数,又叫做查询字符串
3.2.1 在url携带参数
直接对含有参数的url发起请求
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
url = '
response = requests.get(url, headers=headers)
3.2.2 通过params携带参数字典
1.构建请求参数字典
2.向接口发送请求的时候带上参数字典,参数字典设置给params
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 这是目标url
# url = '
# 最后有没有问号结果都一样
url = '
# 请求参数是一个字典 即wd=python
kw = {'wd': 'python'}
# 带上请求参数发起请求,获取响应
response = requests.get(url, headers=headers, params=kw)
print(response.content)
知识点:掌握发送带参数的请求的方法
3.3 在headers参数中携带cookie
网站经常利用请求头中的Cookie字段来做用户访问状态的保持,那么我们可以在headers参数中添加Cookie,模拟普通用户的请求。我们以github登陆为例:
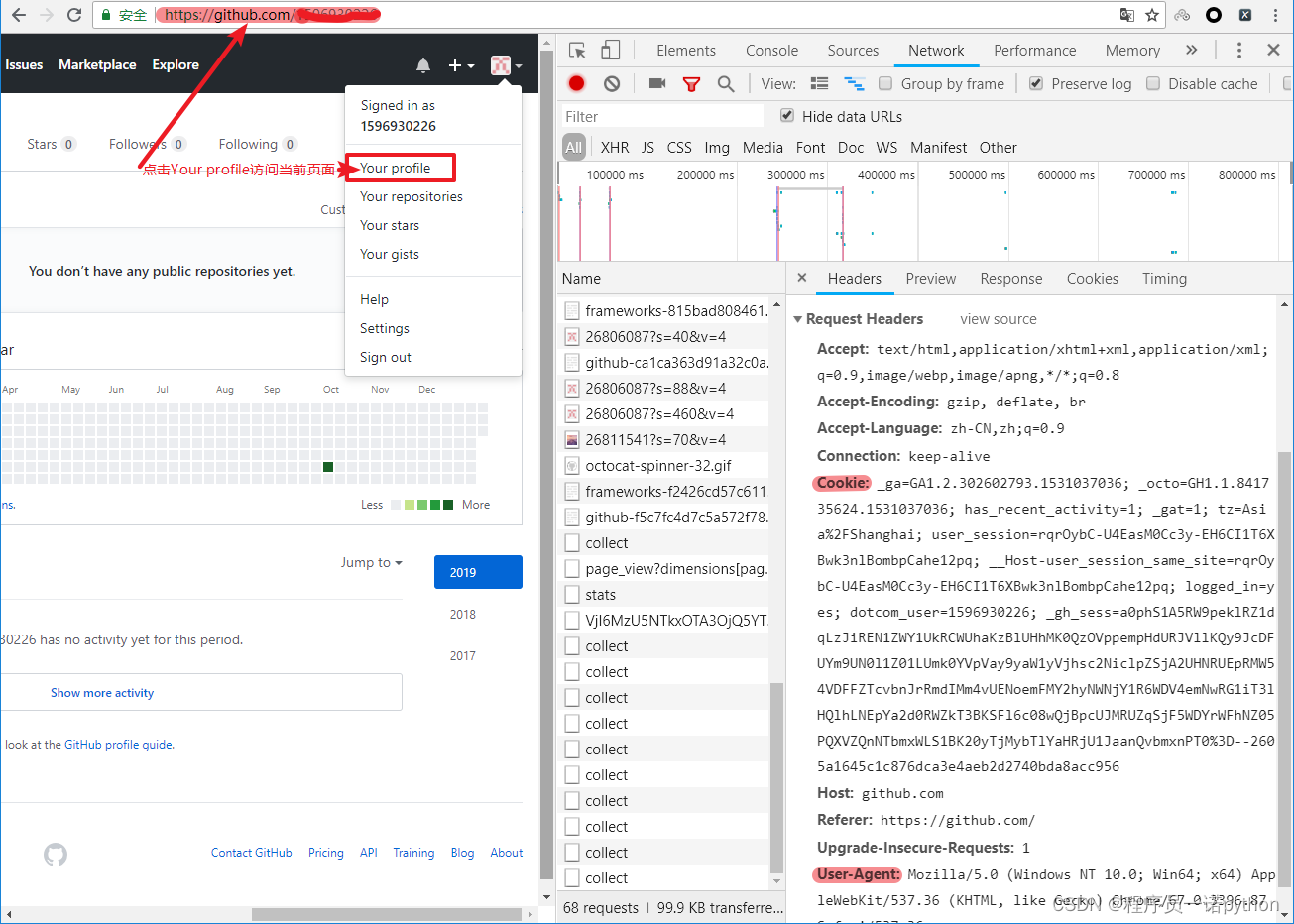
3.3.1 github登陆抓包分析
- 打开浏览器,右键-检查,点击Net work,勾选Preserve log
- 访问github登陆的url地址 `
- 输入账号密码点击登陆后,访问一个需要登陆后才能获取正确内容的url,比如点击右上角的Your profile访问`
- 确定url之后,再确定发送该请求所需要的请求头信息中的User-Agent和Cookie
3.3.2 完成代码
- 从浏览器中复制User-Agent和Cookie
- 浏览器中的请求头字段和值与headers参数中必须一致
- headers请求参数字典中的Cookie键对应的值是字符串
import requests
url = '
# 构造请求头字典
headers = {
# 从浏览器中复制过来的User-Agent
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36',
# 从浏览器中复制过来的Cookie
'Cookie': 'xxx这里是复制过来的cookie字符串'
}
# 请求头参数字典中携带cookie字符串
resp = requests.get(url, headers=headers)
print(resp.text)
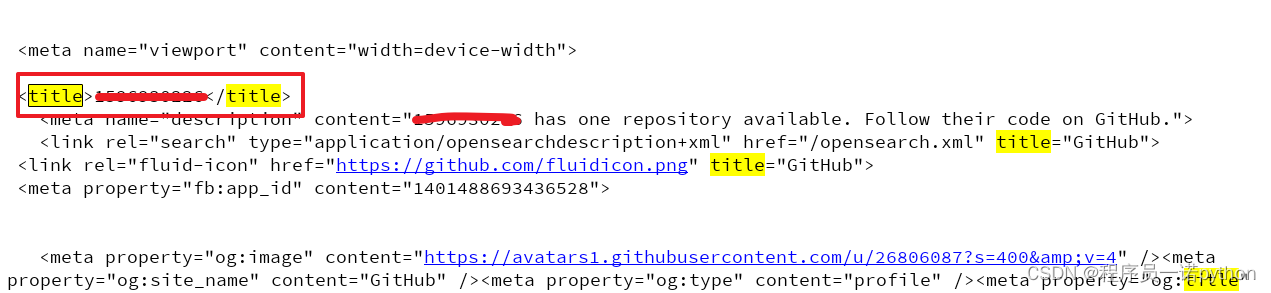
3.3.3 运行代码验证结果
在打印的输出结果中搜索title,html中的标题文本内容如果是你的github账号,则成功利用headers参数携带cookie,获取登陆后才能访问的页面
知识点:掌握 headers中携带cookie
3.4 cookies参数的使用
上一小节我们在headers参数中携带cookie,也可以使用专门的cookies参数
- cookies参数的形式:字典
cookies = {"cookie的name":"cookie的value"}
- 该字典对应请求头中Cookie字符串,以分号、空格分割每一对字典键值对
- 等号左边的是一个cookie的name,对应cookies字典的key
-
等号右边对应cookies字典的value
-
cookies参数的使用方法
response = requests.get(url, cookies)
- 将cookie字符串转换为cookies参数所需的字典:
cookies_dict = {cookie.split('=')[0]:cookie.split('=')[-1] for cookie in cookies_str.split('; ')}
- 注意:cookie一般是有过期时间的,一旦过期需要重新获取
import requests
url = '
# 构造请求头字典
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'
}
# 构造cookies字典
cookies_str = '从浏览器中copy过来的cookies字符串'
cookies_dict = {cookie.split('=')[0]:cookie.split('=')[-1] for cookie in cookies_str.split('; ')}
# 请求头参数字典中携带cookie字符串
resp = requests.get(url, headers=headers, cookies=cookies_dict)
print(resp.text)
知识点:掌握 cookies参数的使用
3.5 cookieJar对象转换为cookies字典的方法
使用requests获取的resposne对象,具有cookies属性。该属性值是一个cookieJar类型,包含了对方服务器设置在本地的cookie。我们如何将其转换为cookies字典呢?
- 转换方法
cookies_dict = requests.utils.dict_from_cookiejar(response.cookies)
-
其中response.cookies返回的就是cookieJar类型的对象
-
requests.utils.dict_from_cookiejar函数返回cookies字典
知识点:掌握 cookieJar的转换方法
3.6 超时参数timeout的使用
在平时网上冲浪的过程中,我们经常会遇到网络波动,这个时候,一个请求等了很久可能任然没有结果。
在爬虫中,一个请求很久没有结果,就会让整个项目的效率变得非常低,这个时候我们就需要对请求进行强制要求,让他必须在特定的时间内返回结果,否则就报错。
- 超时参数timeout的使用方法
response = requests.get(url, timeout=3)
- timeout=3表示:发送请求后,3秒钟内返回响应,否则就抛出异常
import requests
url = '
response = requests.get(url, timeout=3) # 设置超时时间
知识点:掌握 超时参数timeout的使用
3.7 了解以及proxy参数的使用
proxy参数通过指定ip,让ip对应的正向服务器转发我们发送的请求,那么我们首先来了解一下ip以及服务器
3.7.1 理解使用的过程
- ip是一个ip,指向的是一个服务器
- 服务器能够帮我们向目标服务器转发请求
图片无法加载
3.7.2 正向和反向的区别
前边提到proxy参数指定的ip指向的是正向的服务器,那么相应的就有反向服务器;现在来了解一下正向服务器和反向服务器的区别
- 从发送请求的一方的角度,来区分正向或反向
-
为浏览器或客户端(发送请求的一方)转发请求的,叫做正向
-
浏览器知道最终处理请求的服务器的真实ip地址,例如VPN
-
不为浏览器或客户端(发送请求的一方)转发请求、而是为最终处理请求的服务器转发请求的,叫做反向
-
浏览器不知道服务器的真实地址,例如nginx
3.7.3 ip(服务器)的分类
-
根据ip的匿名程度,IP可以分为下面三类:
-
透明(Transparent Proxy):透明虽然可以直接“隐藏”你的IP地址,但是还是可以查到你是谁。目标服务器接收到的请求头如下:
REMOTE_ADDR = Proxy IP
HTTP_VIA = Proxy IP
HTTP_X_FORWARDED_FOR = Your IP
- 匿名(Anonymous Proxy):使用匿名,别人只能知道你用了,无法知道你是谁。目标服务器接收到的请求头如下:
REMOTE_ADDR = proxy IP
HTTP_VIA = proxy IP
HTTP_X_FORWARDED_FOR = proxy IP
- 高匿(Elite proxy或High Anonymity Proxy):高匿让别人根本无法发现你是在用,所以是最好的选择。毫无疑问使用高匿效果最好。目标服务器接收到的请求头如下:
REMOTE_ADDR = Proxy IP
HTTP_VIA = not determined
HTTP_X_FORWARDED_FOR = not determined
-
根据网站所使用的协议不同,需要使用相应协议的服务。从服务请求使用的协议可以分为:
-
http:目标url为http协议
- https:目标url为https协议
-
socks隧道(例如socks5)等:
- socks 只是简单地传递数据包,不关心是何种应用协议(FTP、HTTP和HTTPS等)。
- socks 比http、https耗时少。
- socks 可以转发http和https的请求
3.7.4 proxies参数的使用
为了让服务器以为不是同一个客户端在请求;为了防止频繁向一个域名发送请求被封ip,所以我们需要使用ip;那么我们接下来要学习requests模块是如何使用ip的
- 用法:
response = requests.get(url, proxies=proxies)
-
proxies的形式:字典
-
例如:
proxies = {
"http": "
"https": "
}
- 注意:如果proxies字典中包含有多个键值对,发送请求时将按照url地址的协议来选择使用相应的ip
知识点:掌握 ip参数proxies的使用
3.8 使用verify参数忽略CA证书
在使用浏览器上网的时候,有时能够看到下面的提示(2018年10月之前的12306网站):
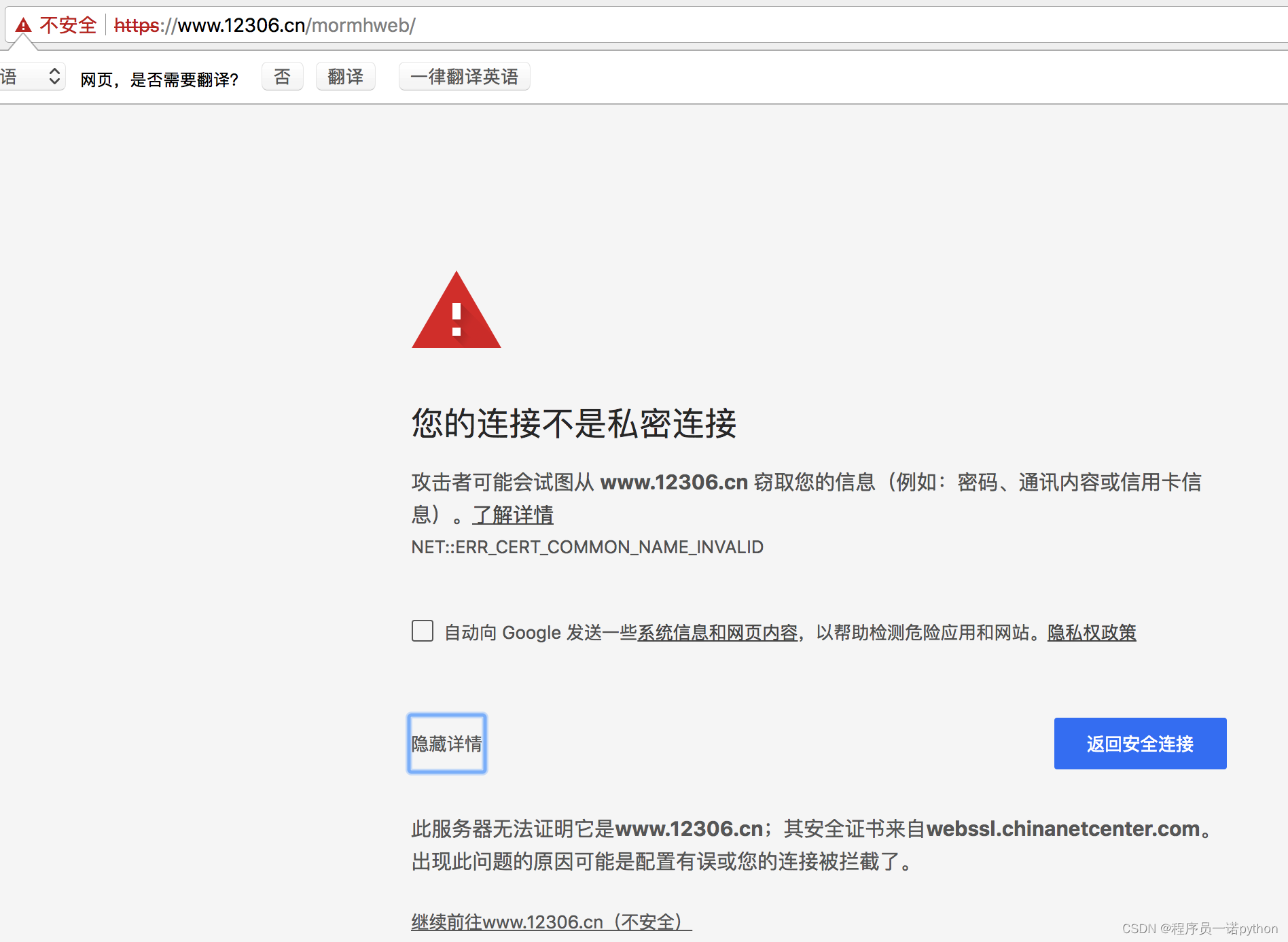
- 原因:该网站的CA证书没有经过【受信任的根证书颁发机构】的认证
- **[关于CA证书以及受信任的根证书颁发机构点击了解更多](
3.8.1 运行代码查看代码中向不安全的链接发起请求的效果
运行下面的代码将会抛出包含
ssl.CertificateError ...字样的异常
import requests
url = "
response = requests.get(url)
3.8.2 解决方案
为了在代码中能够正常的请求,我们使用
verify=False参数,此时requests模块发送请求将不做CA证书的验证:verify参数能够忽略CA证书的认证
import requests
url = "
response = requests.get(url,verify=False)
知识点:掌握 使用verify参数忽略CA证书
4. requests模块发送post请求
思考:哪些地方我们会用到POST请求?
- 登录注册( 在web工程师看来POST 比 GET 更安全,url地址中不会暴露用户的账号密码等信息)
- 需要传输大文本内容的时候( POST 请求对数据长度没有要求)
所以同样的,我们的爬虫也需要在这两个地方回去模拟浏览器发送post请求
4.1 requests发送post请求的方法
-
response = requests.post(url, data) -
data参数接收一个字典 -
requests模块发送post请求函数的其它参数和发送get请求的参数完全一致
4.2 POST请求练习
下面面我们通过金山翻译的例子看看post请求如何使用:
- 地址:[
思路分析
- 抓包确定请求的url地址
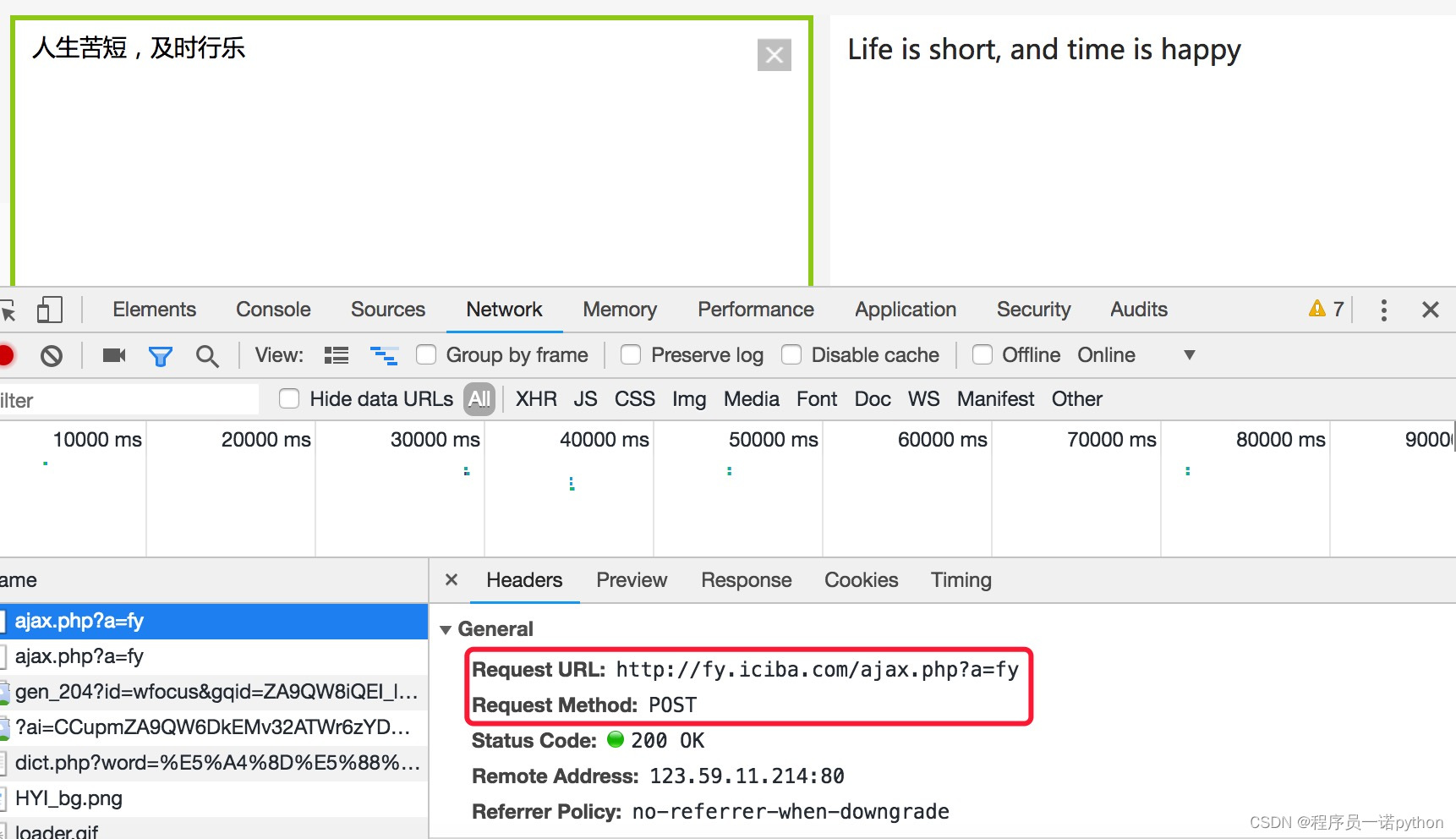
- 确定请求的参数
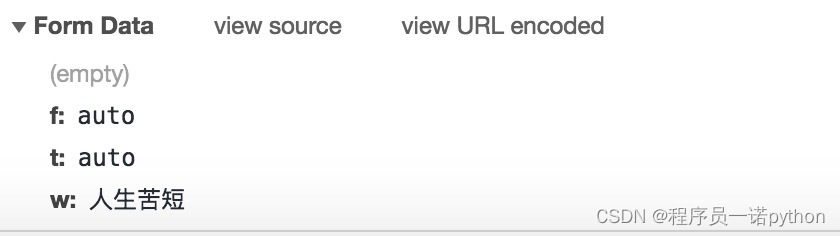
- 确定返回数据的位置
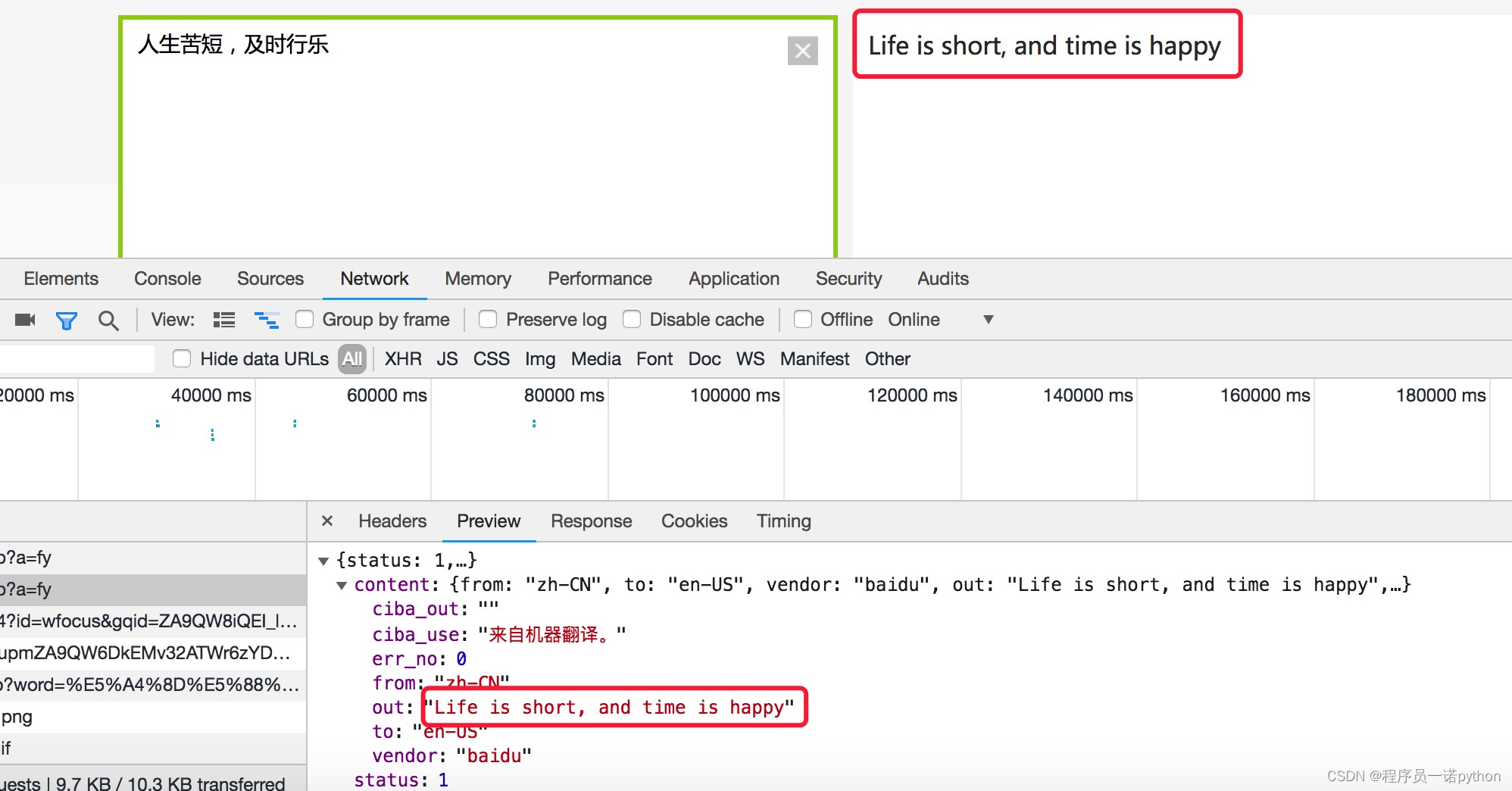
- 模拟浏览器获取数据
4.2.3 抓包分析的结论
-
url地址:`
-
请求方法:POST
-
请求所需参数:
data = {
'f': 'auto', # 表示被翻译的语言是自动识别
't': 'auto', # 表示翻译后的语言是自动识别
'w': '人生苦短' # 要翻译的中文字符串
}
- pc端User-Agent:
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36
4.2.4 代码实现
了解requests模块发送post请求的方法,以及分析过移动端的百度翻译之后,我们来完成代码
import requests
import json
class King(object):
def __init__(self, word):
self.url = "
self.word = word
self.headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"
}
self.post_data = {
"f": "auto",
"t": "auto",
"w": self.word
}
def get_data(self):
response = requests.post(self.url, headers=self.headers, data=self.post_data)
# 默认返回bytes类型,除非确定外部调用使用str才进行解码操作
return response.content
def parse_data(self, data):
# 将json数据转换成python字典
dict_data = json.loads(data)
# 从字典中抽取翻译结果
try:
print(dict_data['content']['out'])
except:
print(dict_data['content']['word_mean'][0])
def run(self):
# url
# headers
# post——data
# 发送请求
data = self.get_data()
# 解析
self.parse_data(data)
if __name__ == '__main__':
# king = King("人生苦短,及时行乐")
king = King("China")
king.run()
# python标准库有很多有用的方法,每天看一个标准库的使用
知识点:掌握 requests模块发送post请求
5. 利用requests.session进行状态保持
requests模块中的Session类能够自动处理发送请求获取响应过程中产生的cookie,进而达到状态保持的目的。接下来我们就来学习它
5.1 requests.session的作用以及应用场景
-
requests.session的作用
-
自动处理cookie,即 下一次请求会带上前一次的cookie
-
requests.session的应用场景
-
自动处理连续的多次请求过程中产生的cookie
5.2 requests.session使用方法
session实例在请求了一个网站后,对方服务器设置在本地的cookie会保存在session中,下一次再使用session请求对方服务器的时候,会带上前一次的cookie
session = requests.session() # 实例化session对象
response = session.get(url, headers, ...)
response = session.post(url, data, ...)
- session对象发送get或post请求的参数,与requests模块发送请求的参数完全一致
5.3 课堂测试
使用requests.session来完成github登陆,并获取需要登陆后才能访问的页面
5.3.1 提示
- 对github登陆以及访问登陆后才能访问的页面的整个完成过程进行抓包
-
确定登陆请求的url地址、请求方法和所需的请求参数
-
部分请求参数在别的url对应的响应内容中,可以使用re模块获取
-
确定登陆后才能访问的页面的的url地址和请求方法
- 利用requests.session完成代码
5.3.2 参考代码
import requests
import re
# 构造请求头字典
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36',
}
# 实例化session对象
session = requests.session()
# 访问登陆页获取登陆请求所需参数
response = session.get(' headers=headers)
authenticity_token = re.search('name="authenticity_token" value="(.*?)" />', response.text).group(1) # 使用正则获取登陆请求所需参数
# 构造登陆请求参数字典
data = {
'commit': 'Sign in', # 固定值
'utf8': '✓', # 固定值
'authenticity_token': authenticity_token, # 该参数在登陆页的响应内容中
'login': input('输入github账号:'),
'password': input('输入github账号:')
}
# 发送登陆请求(无需关注本次请求的响应)
session.post(' headers=headers, data=data)
# 打印需要登陆后才能访问的页面
response = session.get(' headers=headers)
print(response.text)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









