






这里我们将重点讲一讲最出名的快排~~~
一、总体思路(升序)
快排的总体思路是每趟从一端中选取一个数作为基准,把大于基准的数往右边放,小于基准的数往左边放,最后剩下的位置放基准值,以达到在基准左边的数都比基准小,在基准右边的值都比基准值大。因此下一趟就不用动基准的位置了。
二、hoare版(传统)
1、思路
首先,我们要以数组的左端(或右端)作基准,因此这里将用 keyi 下标来记录基准的位置;然后用 left 和 right 两个指针来遍历数组,当 left 和 right 相遇时,再把 left 位置的元素和 keyi 位置的元素交换,此时 left 左边的元素虽然无序,但都是比 a[left] 小,而 left 右边的元素虽然无序,但都比 a[left] 大。然后再通过递归对 left 两边的元素排序。
但要注意的是:
(1)当左端作为 keyi 时,一定要让 right 先走;当右端作为 keyi 时,一定要让 left 先走。
(2)以升序为例,left 负责找比 a[keyi] 大的数,right 负责找比 a[keyi] 小的数。

2、代码
int PartSort1(int* a, int left, int right)
{
int keyi = left; // 0
int l = left; //0
int r = right; /* keyi在左,右兵先走 */
while (l < r)
{
//右兵找小,左兵找大
while ((l < r) && (a[r] >= a[keyi])) /* 防越界 */
{
r--;
}
while ((l < r) && (a[l] <= a[keyi]))
{
l++;
}
Swap(&a[l], &a[r]);
}
Swap(&a[keyi], &a[l]);
return l;
}
void QuickSort(int* a, int left, int right)
{
if (left >= right)
return;
int ret = PartSort1(a, left, right);
QuickSort(a, left, ret - 1);
QuickSort(a, ret + 1, right);
}3、优点与缺陷
优点:
时间复杂度虽然和堆排、希尔排序是一样,但系数比堆排和希尔排序要小得多,因此时间比堆排和希尔排序都要快一点。
缺陷:
一旦数组本来就是升序或降序的,那么本来双指针走的路程变成了单个指针走,因此时间复杂度就会退化成熟悉的冒泡排序。而且由于递归次数增多,可能会爆栈。
三、hoare版(改进)
1、随机取key法
(1)思路
由于数组越有序,快排的时间消耗就会越长。因此,我们可以通过随机取一个下标,然后和左端(右端)交换,让数组不那么有序,就会大大缩短排序时间。
(2)代码
/* 返回的是随机距离 */
int GetRandomKey(int left, int right)
{
return rand() % (right - left + 1);
}
int PartSort1(int* a, int left, int right) // 2 1
{
int ran = GetRandomKey(left, right);
Swap(&a[left], &a[left + ran]);
int keyi = left; // 0
int l = left; //0
int r = right; /* keyi在左,右兵先走 */ //-2
while (l < r)
{
//右兵找小,左兵找大
while ((l < r) && (a[r] >= a[keyi]))
{
r--;
}
while ((l < r) && (a[l] <= a[keyi]))
{
l++;
}
Swap(&a[l], &a[r]);
}
Swap(&a[keyi], &a[l]);
return l;
}
void QuickSort(int* a, int left, int right)
{
if (left >= right)
return;
int ret = PartSort1(a, left, right);
QuickSort(a, left, ret - 1);
QuickSort(a, ret + 1, right);
}2、三数取中法(力推!!!)
(1)思路
为了避免 keyi 的值是整个数组的最值,因此分别从数组的两端和中间的三个值中选出中间大的那个数的下标,然后让 a[keyi] 和 这个下标的值交换。
(2)代码
//三数取中
int GetThreeMid(int* a, int left, int right)
{
int mid = (left + right) / 2;
if (a[left] < a[mid])
{
if (a[mid] < a[right])
{
return mid;
}
else
{
if (a[left] < a[right])
{
return right;
}
else
{
return left;
}
}
}
else /* a[left] > a[mid] */
{
if (a[right] < a[mid])
{
return mid;
}
else /* a[right] > a[mid] */
{
if (a[left] > a[right])
{
return right;
}
else
{
return left;
}
}
}
}
int PartSort1(int* a, int left, int right) // 2 1
{
int mid = GetThreeMid(a, left, right);
Swap(&a[left], &a[mid]);
int keyi = left; // 0
int l = left; //0
int r = right; /* keyi在左,右兵先走 */ //-2
while (l < r)
{
//右兵找小,左兵找大
while ((l < r) && (a[r] >= a[keyi]))
{
r--;
}
while ((l < r) && (a[l] <= a[keyi]))
{
l++;
}
Swap(&a[l], &a[r]);
}
Swap(&a[keyi], &a[l]);
return l;
}四、挖坑法
1、思路
背景:这个方法其实就是霍尔大佬的方法,只不过有人觉得霍尔大佬的方法太难理解了,才发明的填坑法。
思路:跟 hoare 版的一样,先在数组两端分别设置左右指针。然后设置一个 key 变量保存左端(右端)的值,于是左端就形成一个坑位,因此左指针就动不了了,只能右指针往左遍历。当右指针找到比 key 小的值时,把右指针的值放到坑里,于是右指针的位置变成一个坑,动不了;而左指针的坑被填了,因此左指针可以向右遍历,当找到比 key 大的值时就把这个值填到坑里,由此循环往复,直到左右指针相遇时,把 key 的值填到坑里。
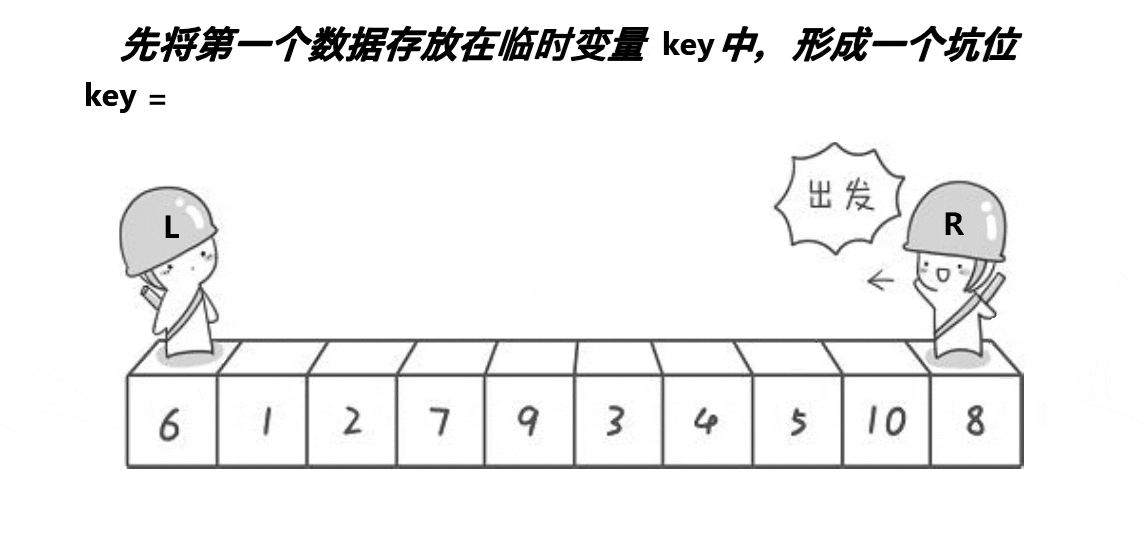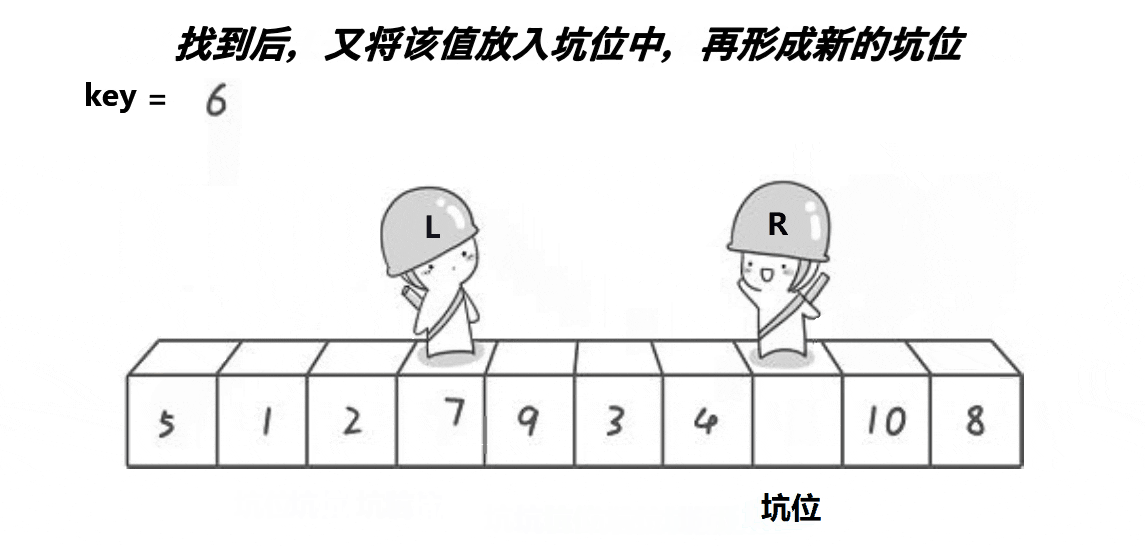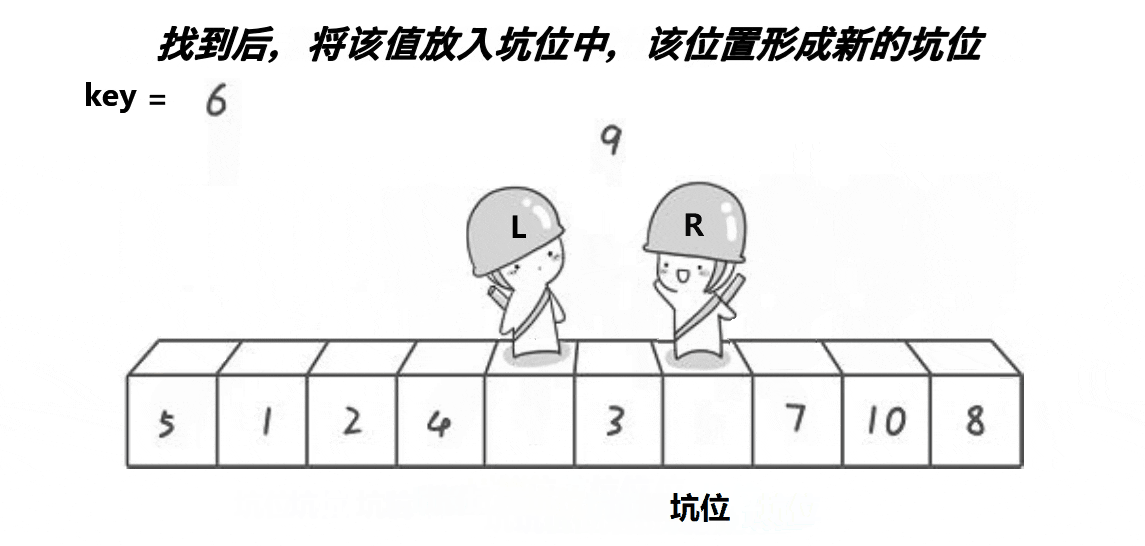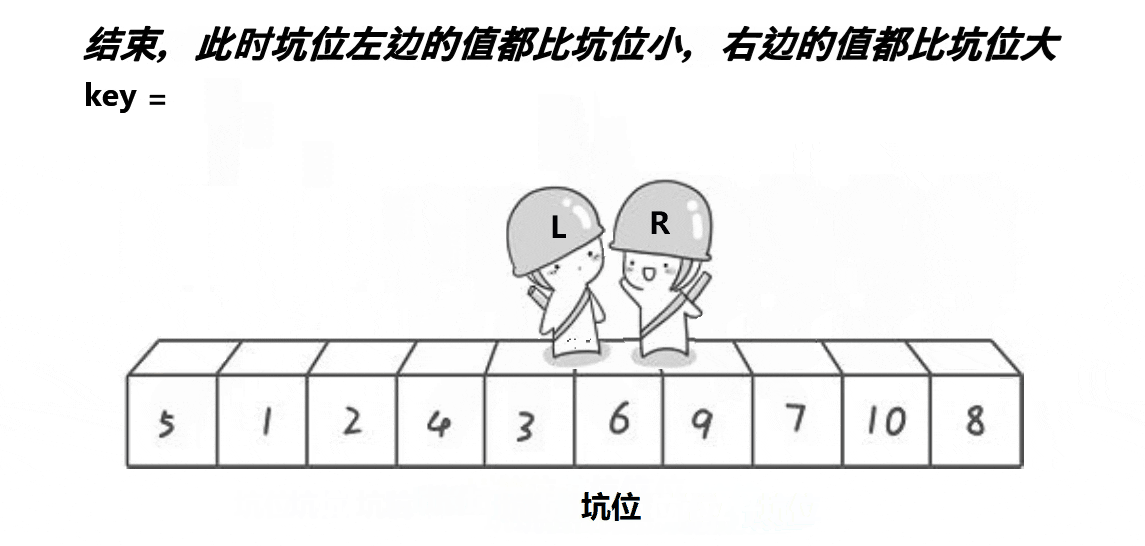
2、代码
int PartSort2(int* a, int left, int right)
{
/*int ret = GetThreeMid(a, left, right);
Swap(&a[ret], &a[left]);*/
int key = a[left];
int hole = left;
int l = left, r = right;
while (l < r)
{
while ((l < r) && (a[r] >= key))
{
r--;
}
a[hole] = a[r];
hole = r;
while ((l < r) && (a[l] <= key))
{
l++;
}
a[hole] = a[l];
hole = l;
}
a[l] = key;
return l;
}五、双指针法
1、思路
也是和 hoare 版的一样,先把一端设成基准,然后设置两个指针 prev 和 cur。然后 cur 开始遍历,当 cur 遇到比 key 小的值时,就把这个值往后甩。甩给谁呢?没错,就是甩给 prev。当 cur 遍历完时,再把 prev 的值和 key 的值互换,整个过程就结束了。
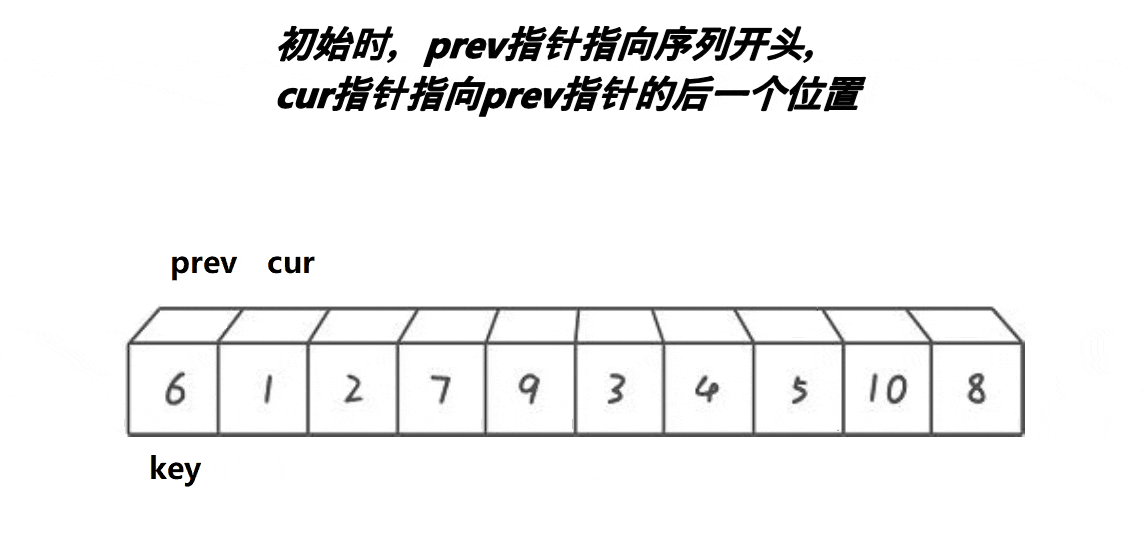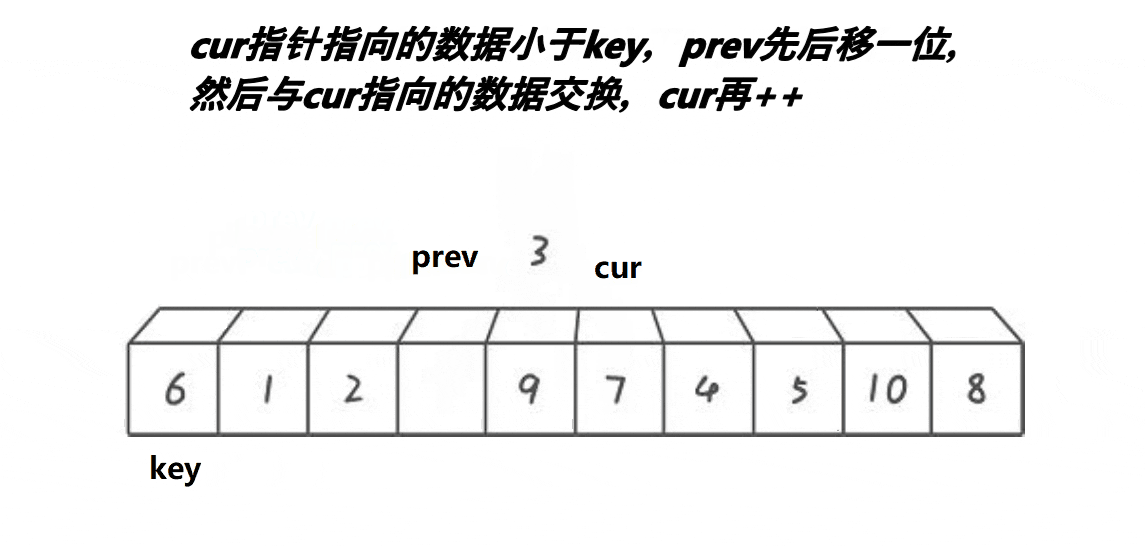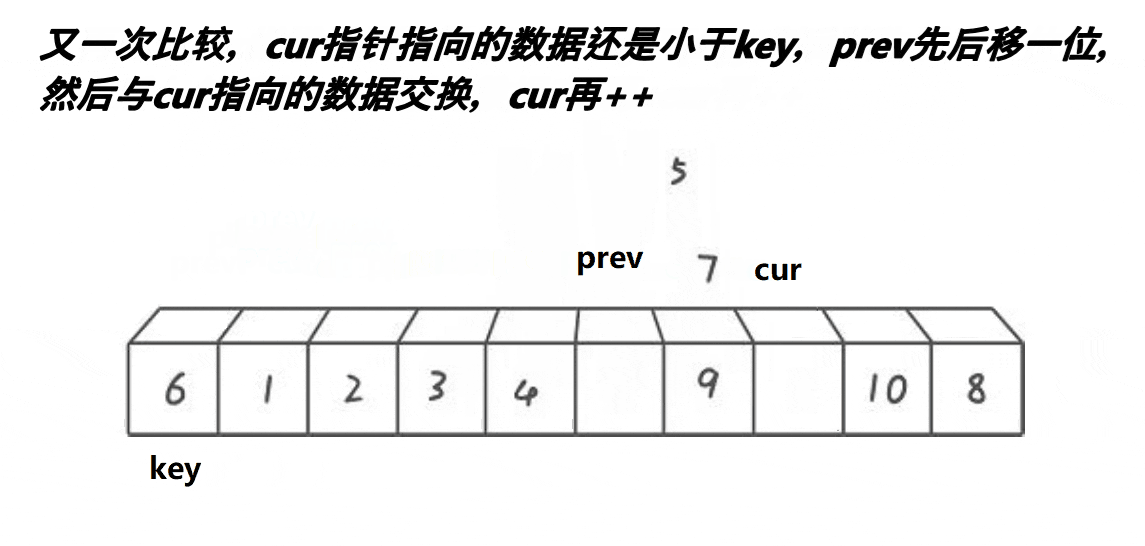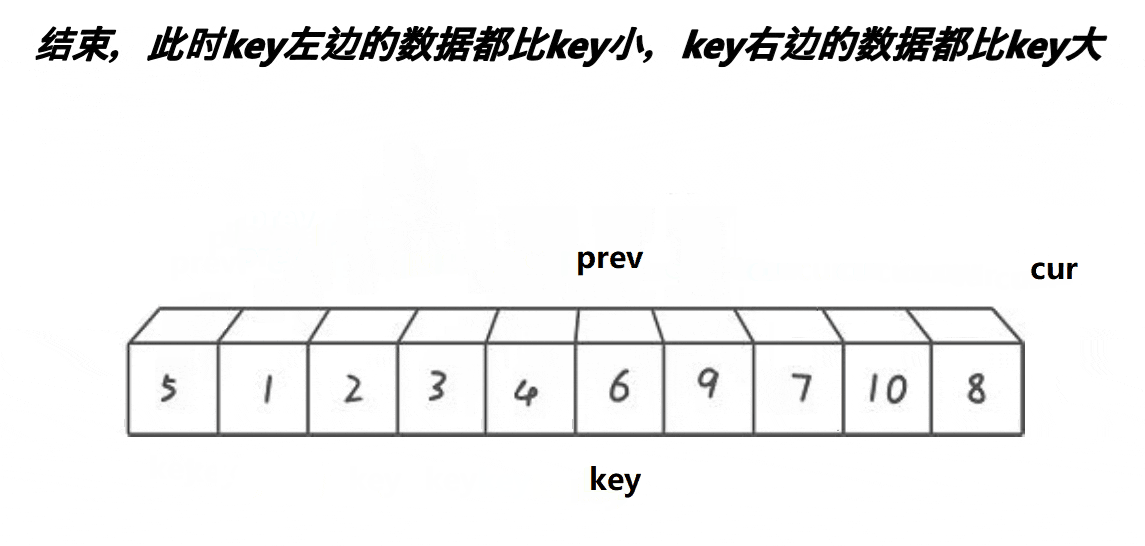
为了更便于大家理解,我画了下面这幅图:

从这福图不难看出,双指针实际就是不断把 7 和 9 像滚雪球一样滚到最后的位置。
2、代码
int PartSort3(int* a, int left, int right)
{
int keyi = left;
int prev = left;
int cur = prev + 1;
while (cur <= right)
{
if (a[cur] < a[keyi]) /* cur找小 */
{
prev++;
Swap(&a[cur], &a[prev]);
}
cur++;
}
Swap(&a[prev], &a[keyi]);
return prev;
}六、快排时间复杂度计算(N*log(N))
关于快排的递归展开图如下:

看到这里,大家很容易就想到二叉树了。没错,因为递归次数是 log(n),而每层都要遍历 n 次。因此时间复杂度是 n*log(n).
















 3007
3007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











