






一.什么是数据库?
1.关系型数据库的特点
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。
每个数据库都有一个或多个不同的 API 用于创建,访问,管理,搜索和复制所保存的数据。
我们也可以将数据存储在文件中,但是在文件中读写数据速度相对较慢。
所以,现在我们使用关系型数据库管理系统(RDBMS)来存储和管理大数据量。所谓的关系型数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据,它有以下特点:
- 1.数据以表格的形式出现
- 2.每行为各种记录名称
- 3.每列为记录名称所对应的数据域
- 4.许多的行和列组成一张表单
- 5.若干的表单组成database
2.理解mysql数据库是啥
我们在电脑上安装MySQL数据库,实际上就是在主机上安装一个数据库管理系统(DBMS),这个管理系统可以管理多个数据库,每个数据库中又可以管理多个表,我们的数据就存在这些表中。
这是我电脑上安装mysql的目录,里面有个data文件夹,就存放了我们的数据库文件,数据库文件里面又存了各个表、视图等等。


这是一张简单的示意图,显示了mysql数据库的三层结构:

这里特别讲一下表,表是数据库最基本而且最重要的结构,表的一行称之为一条记录,每张表有很多列成员,可以理解为我们在java中定义的数据比如int age(年龄),double price(价钱),这里给一张表给大家看看:

可以看到,列成员有id,name,以及各科成绩,每一行都代表一个人,非常清晰。
3.如何连接MySQL数据库
(由于篇幅问题,这里不讲如何安装MySQL数据库,大家可以在网上找文档视频来查看,切记一步一步细心来,安装出现问题会很麻烦!!!)
1.命令行窗口连接MySQL
我们这里以本地连接举例
首先,以管理员权限启动命令行窗口才能开启我们的MySQL服务
启动MySQL服务:net start mysql
关闭MySQL服务:net stop mysql
###注意不要手快打分号在后面,不然提示服务名无效

登录完后就可以在任务管理器中查看服务,我们看看确实开启了一个叫mysql的服务:

然后就可以连接数据库了:
mysql -h 主机名 -P 端口 -u 用户名 -p 密码
###如果没有写主机名和端口,那么主机名默认是本机,端口默认为你安装mysql时指定的端口
###用户名和密码的话可以用系统的root用户,密码在你安装mysql的时候你自己设置
这样就是连接成功了:

2.各种图形化MySQL管理软件
比如Navicat和SQLyog等等,我们只要在软件里面去输入我们要连接的ip,登录自己的账号就行了,这里不做过多解释。
二.各种SQL语句
1.SQL语句分类
大概了解一下sql语句分为哪几种就好了,这个不重要,记住select查询语句是最重要也是最复杂的就行了
- DDL:数据定义语句(create数据库或者表)
- DML: 数据操作语句(insert、update、delete)
- DQL:数据查询语句(select)--》最重要最常用
- DCL:数据控制语句(grant、revoke等等)
2.创建数据库和表(DDL)
eg:比如我要建立一个数据库叫football_player专门用来存放足球运动员的信息,为了简单,里面我只创建一张表:
首先建立数据库:

创建数据库:create database 数据库名;
查看当前数据库: show databases;
使用数据库:use 数据库名;
显示数据库创建语句:show create database 数据库名;
##这个会显示数据库的字符集(默认utf8),这点我们后面说
删除数据库:drop database 数据库名; -->慎用!!!
然后创建一张表(Premier_League代表英超联赛):

创建表:create table 表名(列名 数据类型......);
###这里要注意,编写sql语句的时候,不是像我们在程序里面一样把数据类型写在前面,这里恰恰相反,要写在后面。
查看当前数据库有哪些表:show tables;
查看表结构:desc 表名字; -->这个很常用
可以看到表已经建立起来了(左图),我们顺便看看表结构(右图):


1.MySQL常用数据类型
在继续讲解sql语句之前,来谈谈MySQL的数据类型,因为我们后面要说的插入语句(insert)就要以这些数据类型为基础来建立我们的列成员,来看三张图(数值类型,日期类型,字符串类型):

###关于数值型,注意几点:
1.如果你的列非负(比如年龄),那么再定义的时候写成 age int unnsigned,就代表是无符号的。
2.如果一个值只有0、1,考虑使用bit(M),M指定位数。
3.如果希望小数精度很高,使用decimal。其中decimal(M,D),M是小数位数的总数,D是小数点后面的位数。


###字符串类型中的char和varchar用的比较多,有几点需要注意:
1.char()和varchar()后面的填的都是字符数而不是字节数,不管你存的是字母还是中文都是按照字符计算,具体怎么计算按照你创建表时指定的字符集来。
2.char是定长,而varchar是变长,char的大小你指定后就固定了,而varchar会根据你存实际长度来分配。
3.一般数据是定长使用char,如身份证号这些,如果一个字段的长度不确定,就用varchar。
4.查询速度:char比varchar更快。
3. 插入语句(insert)
前面我们已经建立了一张英超表,但是里面一条数据都没有,我们来看看:

查看表内容:select * from 表名,*代表查看全部列的信息
现在我们插入数据:

插入数据:insert into 表名 values(列名 列数据类型....) ;
再查一下表:

可以看到确实添加成功了。
###关于insert插入语句的细节:
1.可以同时插入多条语句,只需要用 , 分隔:(同时插入两条语句)

*乱入:Alter语句
写到这里,我发现一个问题,就是咱们这个表居然没有一个叫name的列,这怎么行,那我们很难区分各个球员啊,有两种办法解决:
- 直接重新创建表,把name字段加上去
- 使用alter命令修改表结构
我相信大部分人都会觉得第一个办法很麻烦吧,但是出于一些原因考虑(比如我们这个表要改的东西太多了,我们重建表反而更省事),这里我还是来说说怎么做:
1.先把原来的表删除:
DROP TABLE table_name ;
这里可以看出其实删除表和删除数据库大同小异嘛...
2.再创建新表(加上新的或者删除不要的):
CREATE TABLE table_name (column_name column_type.......);
好了,我们现在来谈谈alter语句怎么修改表吧,这里我先演示要添加球员名字这个列:

添加成功,但还是空值啊,别急,我们还没加入球员名字呢,我们讲完alter后再回去谈别的。
添加新列:
ALTER TABLE table_name
ADD column_name data_type;细节:1.可以在最后加上first或者after column,一个代表加到第一列(也即这里我插入的name列使用了first),另一个代表插入到指定列的后面。
2.如果first和after都不加,默认加在最后。
下面这几个就不演示了(因为我现在不需要用这些),其实都大同小异。
删除列:
ALTER TABLE table_name
DROP column_name;修改列名称:
ALTER TABLE table_name
MODIFY column_name new_data_type;修改列定义:(比如把tinyint修改为int)
ALTER TABLE table_name
CHANGE old_column_name new_column_name data_type;
如果你跟着我一起建立了这张表,你就会发现这个表名有点烦(有点长),导致我们操作起来不是很方便,所以我这里再使用alter语句改变表名:

修改成功,改成了简单的est,理解为(England Football Table 英国足球表)
修改表名(两种方式都可以):
1. RENAME table 表名 to 新表名(我这里就是用这种)
2.ALTER TABLE old_table_name RENAME TO new_table_name;
*关于插入语句的细节
好的,我们又回来了,继续谈谈一些细节,这些细节用多了就知道了,不必死记硬背(此处从第二点开始写,上面有第一点细节)。
2.插入的数据应与字段的数据类型相同。
#这点很好理解吧,比如有一列是 name varchar(4),你插入的时候填个数字进去,肯定不允许。
3.数据的长度应在列的规定范围内
#比如上面的varchar(4),你规定最大为4个字符,你不能填个>4的字符。
4.在values中列出的数据位置必须与被加入的列的排列顺序一致,比如现在我这个表:
它是先名字,再年龄,你insert的时候,不能把年龄写在名字前面,这和我们在java中调用函数传参的时候,形参和实参顺序一致是一样的。
5.字符和日期类型数据要包含在单引号中(否则报错):
6.列可以插入空值,前提是该字段允许为空
那我怎么样控制我的字段能否为空呢?有时候我还想给他一个默认值,怎么做?
做法如下:
在创建表的时候,比如我们这里的age字段,你不想让他为空,你在 age int 后面加上 not null即可,同时再加上 default 18,也即: age int not null default 18,这个写法的意思就是,这个字段不能为空,当你插入的时候不填这个数据的时候,默认给你设置为18


4.更新语句(update)
上面我们的est表添加了名字这个列,但是前面几个数据的名字我们还没添加呢(目前为空值),怎么办呢?
这个时候就要用的我们的update语句了,他可以修改表的数据:
更新语句:UPDATE table_name SET field1=new-value1, field2=new-value2
[WHERE Clause]
比如我这里修改我们前三行的名字,把null改为对应的球员名字:

细节:
- 你可以同时更新一个或多个字段(比如你还可以同时更新score)。
- set子句指示要修改哪些列和要给予哪些值。
- 你可以在 WHERE 子句中指定任何条件。
- 如果没有where语句,则更新所有行的数据(小心)。
可以看到,我这里where条件后面写的是年龄,你可以这样理解update语句,就是我要update的列是name,把他改为‘C罗’,where(当)age(年龄)为39的时候。
但是这就有个问题了,如果我有两个球员都是39岁怎么办,那我还怎么改?
解决办法有很多,第一就是你多加几个条件不就行了,总不能每个条件都一样吧,用and连接每个条件即可。
*where语句
关于where语句:
- 查询语句中你可以使用一个或者多个表,表之间使用逗号, 分割,并使用WHERE语句来设定查询条件。
- 你可以在 WHERE 子句中指定任何条件。
- 你可以使用 AND 或者 OR 指定一个或多个条件。
- WHERE 子句也可以运用于 SQL 的 DELETE 或者 UPDATE 命令。
- WHERE 子句类似于程序语言中的 if 条件,根据 MySQL 表中的字段值来读取指定的数据。
- 当你想修改或删除数据表中指定的记录时 WHERE 子句是非常有用的。
- 常见的where:

* 主键约束
还有个办法就是设置主键(primary key),主键是什么呢?
主键,又叫主键约束,每张表只能有一个主键,用于唯一的标识表行的数据,当定义主键约束后,该列不可重复,你可以把他理解为区分每一条数据的一个字段,比如我们可以在这里把名字设置成主键,当然你可能会说名字也可能一样,解决办法是可以把多列放在一起形成主键约束(也叫复合主键),当这些列都一样的时候就会产生约束,以防止你插入相同的数据;
添加主键约束:
1.添加主键约束可以再创建表的时候在某个字段后面写primary key
也可以在表定义最后写primary key(列名....)
2.如果表已经建好了,可以使用alter语句:
ALTER TABLE table_name
ADD PRIMARY KEY (column_name);
那这里我就不搞那么复杂了,我只设置一个主键,就是名字这个字段:

可以看到name这一列确实变成了主键(primary key),这个时候我就可以根据名字来去修改他们的信息了,而且还会限制我不能添加两个一模一样名字的人进去,以防我一次性更新了多条数据。
5.删除语句(delete)
使用 SQL 的 DELETE FROM 命令来删除 MySQL 数据表中的记录。
DELETE FROM table_name [WHERE Clause]
比如我这里要删除name = 姆巴佩这一行的数据:

细节:
- 如果没有指定 WHERE 子句,MySQL 表中的所有记录将被删除(小心)。
- 你可以在 WHERE 子句中指定任何条件
- 您可以在单个表中一次性删除记录。
- delete语句只能删除表中的每行数据,不能删除表,删除表用 drop table
- delete 语句不能删除某列,也就是说你不能让name这一列消失,但是你可以删除某个name的一行数据,要删除列用alter语句
6.查询语句(select)
1.最基本的select语句
1.0基础版本
前面的都是小试牛刀,真正重要的东西来了!
为此我们这里用另一张表来讨论,这是张学生表(student),结构和数据如下:

解释一下,主键有两个,学号和名字,也就是说学号和名字都同的时候插入失败。
数据有学号,姓名,还有语数英的成绩。
查询语句:SELECT【distinct】 column_name,column_name
FROM table_name
[WHERE Clause]1.distinct可选,它会过滤表中重复的数据,但我们设置了主键约束,也就不存在重复数据了
2.where语句可以写你要查询者的条件,eg:我现在要查语文成绩不合格的人,而且只打印它的学号、姓名和语文成绩:
3.可以在显示的时候给列名起别名(便于查看),比如我们要求平均分,那么平均分就是语数英相加÷3,但是如果以这个作为列名的话太难看了:
起个别名就好了,用as写在要重命名的后面就行了:
现在清楚多了



1.1.加入order by
order by :
SELECT field1, field2,...fieldN FROM table_name1, table_name2... ORDER BY field1 [ASC [DESC][默认 ASC]], [field2...] [ASC [DESC][默认 ASC]]
order by 用于对我们表中的数据进行排序(eg:对学生总成绩排序):

细节:1.如果我们需要对读取的数据进行排序,我们就可以使用 MySQL 的 ORDER BY 子句来设定你想按哪个字段哪种方式来进行排序,再返回搜索结果。
2.默认是升序排列(ASC),如果希望降序排列,需要在末尾加上DESC
3.如果是数值和日期就按照大小来排,如果是字符串就按照字典顺序来排序。
4.可以再order by后面写多个,它会进行分组排序,比如我还有一列是名字,那么如果我这样写: order by total_score desc,name desc; 意味着会先按照总分排序,然后在此基础上,再按照名字来排序,请大家仔细看下面两个语句和其执行结果的区别:
5.order by指定排序的列,排序的列既可以是表中的别名,也可以是select语句后指定的别名,如上图我用total_score进行排序


*一些常用函数
COUNT函数
count(*)返回行的总数 -> 返回满足条件的记录的行数
count(某列)作用和上面一样但是排除null的情况
eg1:显示现在student表中有多少个学生?(看上图数一下应该是9个)
eg2:显示总分大于250的人数?(上图看来应该是5个人)
当然也可以把列名取为总分大于250的人(可读性更强):



SUM函数 和 AVG函数
sum返回满足where条件行的和,一般用在数值列
avg返回满足where条件的一列平均值
eg:求student表中学生的语文总分和数学平均分:
MAX函数 和 MIN函数
就是返回满足where条件的一列的最大或最小值嘛,大家自己求求这个班语文最高分和数学最低分吧(easy)

1.2加入group by having
GROUP BY 语句根据一个或多个列对结果集进行分组。
在分组的列上我们可以使用 COUNT, SUM, AVG,等函数。
SELECT [column_name], [function(column_name)]
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
我们既然要演示分组,就得有组来给你分,现在我们的表只有id和名字,很难分组,我们新增一列叫班级,有一班和二班,这样通过班级来进行分组:
还记得怎么添加列吗?(alter)

好了,添加了新列,但是全是默认一班可不行,我们update一下几个同学的班级:

我按照班级和id进行了排序,这样看起来非常清楚,我们三国的同学为一班,其余人为二班:
eg:求一班和二班的语文平均分和数学最高分?
这个问题你发现你就不能直接求解了,必须按照班级进行分组才行:

对照一下上图,完全正确,使用group by 进行分组真方便啊
eg:求出英语平均分低于85的班级:
思路,先求出所有班(这里就是一班和二班)的平均分,然后过滤掉不符合条件的就行了:

如果大家去做了的话就会发现很有意思,原来一班平均分只有73,两个班没一个平均分超过85的,所以根本找不到,看了看表,原来是张飞这个老大粗考了三个零鸡蛋....不过无伤大雅,这里可以看到,第一次我按照>30查询,查到两个班了,但第二次按照>60查询,用having就能帮我们过滤掉均分低于60的班级了 。
group by 用于对查询结果分组统计
having 子句用于限制分组显示结果
1.3通配符模糊查询
这玩意有时候确实会用到,比如假设我们现在有一张年级表,我想统计里面湖南人的个数,怎么做,很简单,湖南身份证开头是43,那就可以使用模糊查询来很快的找到。
两种通配符和like:
"%" 百分号通配符: 表示任何字符出现任意次数 (可以是0次)。
"_" 下划线通配符:表示单个字符。
like操作符:LIKE作用是指示mysql后面的搜索模式是利用通配符而不是直接相等匹配进行比较;但如果like后面没出现通配符,则在sql执行优化时将 like 默认为 “=”执行
我还是用student表来演示,我现在要找所有姓张的同学(张无忌,张三丰,张飞):
 可以看到,我用where实现了筛选,挑出了那些姓张的同学,这就是 % 通配符,它不管你后面还有多少字符,只要第一个字是张就行了。
可以看到,我用where实现了筛选,挑出了那些姓张的同学,这就是 % 通配符,它不管你后面还有多少字符,只要第一个字是张就行了。
那假如我要挑出只要名字长度只有两个字,而且还姓张的人呢?

你根本不用重写,直接把通配符改成 _ 就行了,非常好理解吧。
1.4分页查询
有时候表的数据太多了,我们不想一次性全部显示出来,这时候可以用分页查询
select ... limit start,rows
表示从start + 1行开始取,取出rows行,start从0开始计算
eg:我要按照id号降序取出,每页显示三条记录即可(显示两页):

公式:LIMIT 每页显示数 *(第几页 - 1),每页显示记录数
*数据分组小结
如果select语句同时包含group by,having,limit,order by,那么它们的顺序是:group by,having,order by,limit,必须按照这个顺序来写,否则报错,其实想想也知道,你只有先分组后才能排序嘛。
2.进阶select语句
这一部分比之前难,也重要的多,既然都看到这里了,加油吧。
2.1MySQL的多表查询
问题引入:因为在我们日常生活中,我们不可能把所有信息都存到一个表里面去吧,我们肯定是要用到多表的,那么我们在进行查询的时候,也要根据多表之间的联系来进行查询。
那既然我们要来谈多表查询,我们就得有多个表,先不写了,我去建表了......

建完了,简单说一下:menu是菜单表,里面有食物的名字、口味编号(真是家奇怪的餐厅)、价钱、烹饪时间;cuisine是食物表,里面有口味编号和他对应的口味(flavor),以及这种口味主要的描述。
你会发现这两个表都有一个taste(代表口味编号)
下面我插入几条数据给你看看你就更清晰了:
先看食物表(感觉最后一列多余了,不过写都写了就算了)

再看菜单表:
 吐槽:先加这么多吧,越加越饿(此时此刻上午11点).....
吐槽:先加这么多吧,越加越饿(此时此刻上午11点).....
好了,表都看完了,现在假如我要求各位做下面一件事:
eg:查出每道菜的口味和对应描述?
分析:你会发现这张表没有这些东西,它只有几个数字,而这些数字对应的口味在我们的食物表(cuisine)里面,所以此时我们要进行多表查询:
先来看看错误做法:

在from后面我写了两张表名,出现了非常多记录,这是啥情况?
仔细看你会发现,每个菜都有五条记录......
默认情况下,当两个表查询的时候,规则如下:
1.从第一张表中取出一行和第二张表的每一行进行组合,返回结果(含有两张表的所有列)
2.一共返回的记录数:第一张表的行数 * 第二张表的行数
3.这称为笛卡尔积
4.解决办法:关键就是要写出正确的过滤条件 where,需要我们进行分析
那这里其实很简单,我们的menu表和cuisine里面都有个taste,所以我们要找的就是当两个taste相同的时候的那些数据 (这就是两张表的联系)
所以正确做法是:
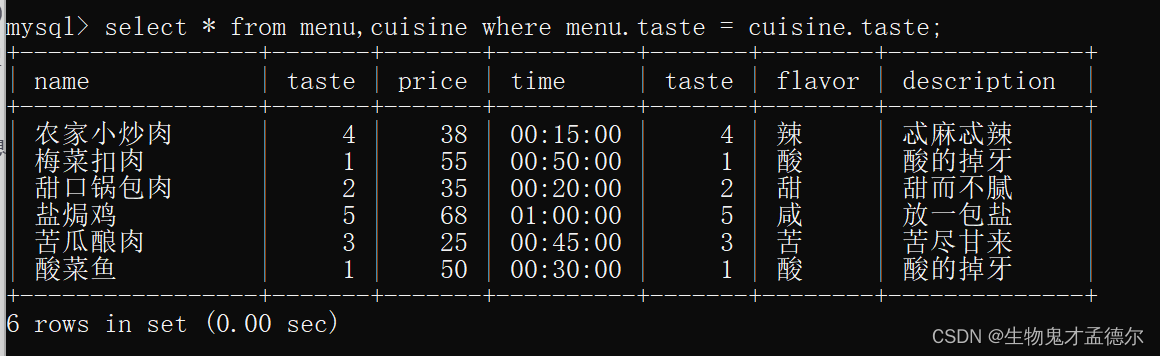
用表名.列可以找到这个表的这一列,但是把两个表的taste都列出来了,我们不需要看两个,只要看一个就行了:

这里的menu.*代表查看menu表的所有字段,而cuisine表我只看口味和口味描述就行了,解决,非常完美,这就是所谓的多表查询。
*外键约束
如果细心的小伙伴会发现一个问题,如果我在加入一道菜的时候,不小心把taste列写成6了怎么办,我们的口味只有1-5(对应酸甜苦辣咸)啊,那么我们在进行多表查询的时候就会出现问题,taste为6的这道菜找不到对应的口味和口味描述,这怎么解决呢?
外检约束:用于定义主表和从表之间的关系,外键约束要定义在从表上,主表必须具有主键约束或者unique约束(唯一约束),当定义外键约束后,要求外键列数据必须在主表的主键列存在或是为null。
在这里,我们的从表就是menu菜单表,主表就是cuisine食物表
理解:如果我们将menu和cuisine的taste做成外键约束,那么在我们添加一道菜的时候,我们必须添加cuisine(主表)里面有的taste或者null,不能添加其他的,这就完美解决了我们无厘头添加个6的问题。
添加外键:
ALTER TABLE table_name
ADD FOREIGN KEY (column_name) REFERENCES referenced_table(ref_column_name);

添加成功,我现在来加入一个cuisine表没有的6,看看会不会成功?

报错,你加不进去,这就是外键约束。
细节:
1.外键指向的表的字段,要求是primary key 或者是unique
2.表的类型是innodb才支持外键(这是存储引擎,默认都是这个)
3.外键字段的类型要和主键字段的类型一致(长度可以不同)
4.外键字段的值,必须在主键字段中出现过,或者为null(前提是你这个字段允许为空,像我这里设置为not null是不行的---看下图)
5.一旦建立了主外键关系,数据不能随意删除
刚刚提到了存储引擎(engine),这里先不说留到后面,但是告诉大家怎么去看:

查看表详细信息 : show create table 表名
你发现可以看到字符集、存储引擎、每个字段以及约束都一目了然,非常方便
* unique约束
上面既然提到了,也在这里聊聊吧
其实顾名思义,unique就是唯一的意思,也就是说当你给一个列设置唯一约束后,该列值不能重复,和主键约束差不多,区别在于主键约束只能有一个(一张表只能有一个但可以是复合主键),而且主键列不能为null,但唯一约束可以有多个,而且可以为null
添加唯一约束:
ALTER TABLE table_name
ADD CONSTRAINT constraint_name UNIQUE (column_name);细节:unique not null 作用类似于 primary key
2.2医师表、门诊表、工资表
由于我们要谈更为复杂的情况,所以这里我准备四张表,为了节约时间,我在图形化界面上面写指令(因为它会把关键字标出来而且很容易修改,dos比较麻烦)

现在插入几条数据到诊所表和医师表里面:

 工资表我们后面再加
工资表我们后面再加
2.3自连接
自连接是指在同一张表的连接查询(也就是将一张表看成两张表)
eg:显示医师和他的上级的名字
(解释一下:我们发现医师表里面有个docno和supno,一个代表自己的编号,一个代表上级的编号,这里可能不太贴合实际,但是意思就是每个医师都有自己的上级,姑且这么理解吧)
分析:我们发现每位医师和它的上级是通过docno和supno关联的,这里就要用到自连接:

解释:可以看到,我们给我们的doctor起了两个别名,一个doc,一个sup,然后进行自连接,where条件找出docno和supno相同的那些人,然后打出名字就行了。
自连接特点:
1.把一张表当做两张表使用
2.需要给表取别名(不然你没法区分两张表啊)
2.4子查询
子查询是指嵌入在其他sql语句中的select语句,也叫做嵌套查询。
子查询又分为单行子查询和多行子查询,单行子查询是指只返回一行数据的子查询语句,多行子查询是指返回多行数据的子查询
1.单行子查询
我们先说单行子查询,直接以例子来讲:
先看看现在表长啥样:

eg:如何显示和张三同一诊所的所有医生?
分析:1.先找到张三是哪个诊所的
2.把上面的select语句当做一个子查询使用
3.因为张三只可能在一个诊所,所以这个子查询只有一行,就是单行子查询
先看第一步:

这条select语句精准的找到了张三的诊所编号:3
第二步:
我就是要找诊所号是3的嘛,所以把这条语句当成一个where条件就行了:

但是我这条语句还包含了张三自己,怎么办?
很简单啊,后面加个条件把张三排除不就行了:
 还记得<>和!=都是不等于的意思吧,这里还有一个细节,就是你在写分号之前可以随时回车换行,确保你的语句逻辑清晰,不然你写一长条不容易检查错误,等你写完了再写分号回车就可以了。
还记得<>和!=都是不等于的意思吧,这里还有一个细节,就是你在写分号之前可以随时回车换行,确保你的语句逻辑清晰,不然你写一长条不容易检查错误,等你写完了再写分号回车就可以了。
2.多行子查询
eg:显示工资比诊所3所有医生工资高的医生的姓名,工资和诊所号
分析:1.我们得先找出诊所3所有医生的工资
2.然后筛选出那些比1工资都要大的人就行了
3.这里可以使用all操作符
第一步:

可以看到这条语句找出了clino为3时所有医生的工资,然后把这个多行数据当做子查询即可
第二步:
 这条语句找到了其他诊所所有大于诊所3工资的人,可以看到我们在where条件中用 sal > all(多行子查询) ,这代表着我们查询的结果是大于多行子查询中所有的sal的数据.
这条语句找到了其他诊所所有大于诊所3工资的人,可以看到我们在where条件中用 sal > all(多行子查询) ,这代表着我们查询的结果是大于多行子查询中所有的sal的数据.
其实也可以不用多行子查询,直接求出诊所3的最大值,再把它当成一个子查询就行了:

这个语句求出了诊所3的医生的最大工资(看选中部分即可)

最后可以看到其实结果都是一样的,看你喜欢用哪种了。
exe:显示工资比诊所3其中一个医生工资高的医生的姓名,工资和诊所号

大于其中一个,把all改成any不就行了,可以看到多了一些数据,当然也有第二种做法,和上面刚好相反,大家去试试吧(提示:用min)
3.多列子查询
有些时候我们不只是希望找到一个共同点,我们希望有很多字段(或者说列)都相同,比如说我不仅想找到和张三同一个诊所的医生,我还想找到和他同一诊所并且和他同一职称的人,这时候怎么办呢?
可以使用多列子查询来实现,其实和上面的子查询非常像,只是把条件变为多列罢了:
分析:1.先得到张三的诊所和职称

2.然后查找两个都和他相同的人就行了(把上面当成一个子查询)
找到了,只有一个人,注意这条语句的写法,在wher条件后面加上括号,里面写出我们要查询的列(这里有两列要比较),然后和前面的子查询比较就行了 ,这就是多列子查询。
4.练习(子查询当做临时表)
exe1:查找每个诊所高于本诊所平均工资的人的信息
分析:1.先得到每个诊所的诊所号和对应的平均工资

解读:我们按照诊所号进行分组,然后求出了每一组的平均工资。
2.最重要的一步,就是把这张表当做临时表,临时表起名为temp,然后在这两张表中查询,条件是两个表的clino要一样,而且查询的人的sal要大于它所在诊所的平均工资

*表复制
有些时候,我们需要对某个sql语句进行效率测试,需要海量的数据,可以用此方法为表创建海量数据。
eg:比如我这里有一张商品表

我现在要进行表的自我复制,有两步:
1.先把Goods表的数据复制到一个新表中(temp):

解读:这里我先创建了一张结构和Goods表一样的temp表,然后把Goods表里面的信息全部复制到temp表中
复制表table1数据到另一张表table2中:insert into table2(table2列......) select (table1列.....) from table1
2.进行自我复制
 可以看到多了三条一模一样的数据,如果在java程序中,我们就可以通过循环来控制复制次数,进而达到海量数据,然后进行效率测试,非常方便。
可以看到多了三条一模一样的数据,如果在java程序中,我们就可以通过循环来控制复制次数,进而达到海量数据,然后进行效率测试,非常方便。
但其实你要是不嫌麻烦,多执行几次这条语句,你会发现它是指数级增长的,非常之快
自我复制:insert into table select * from table;
*如何删除一张表的重复记录?
我们现在有一张Goods表,里面有几条数据是重复的:

分析:1.我们先创建一张temp表:
 这条语句用like创建了temp表,创建出来的表和Goods表的结构一模一样
这条语句用like创建了temp表,创建出来的表和Goods表的结构一模一样
2.然后把Goods表的数据复制temp中,同时进行去重(distinct):

这条语句上面讲过了,就是把一张表的数据复制到另一张(前提是结构得一样才行)
3.删除Goods表的记录:

4.把temp已经去重的数据复制给Goods表,然后删除temp表即可:
 可以看到现在Goods表在借助temp表的帮助下,已经完成了去重。
可以看到现在Goods表在借助temp表的帮助下,已经完成了去重。
5.合并查询
有时在实际应用中,为了合并多个select语句的结果,可以使用集合操作符号union和union all
1.union all 该操作符用于取得两个结果集的并集,当使用该操作符时,不会取消重复行
2.union 与union all相似,但是会自动去掉结果集中重复行
先来看看union all ,下面我在两个select查询语句之间加上了union all,结果就是他会把工资大于2000的和所有中级的人显示出来,也就是两条查询语句的结果合并,但问题是可能找到重复的,因为有的人可能工资大于2000的同时,职位也是中级的。

使用union就可以把重复数据去掉,只保留一个:

2.5表连接(JOIN)
JOIN 按照功能大致分为如下三类
- INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。
- LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。
- RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
下面有三张图非常形象的说明了三种表连接的意义(来自菜鸟教程)



那我这里用力扣里面的一道题来讲讲上面的三个连接:
题目:

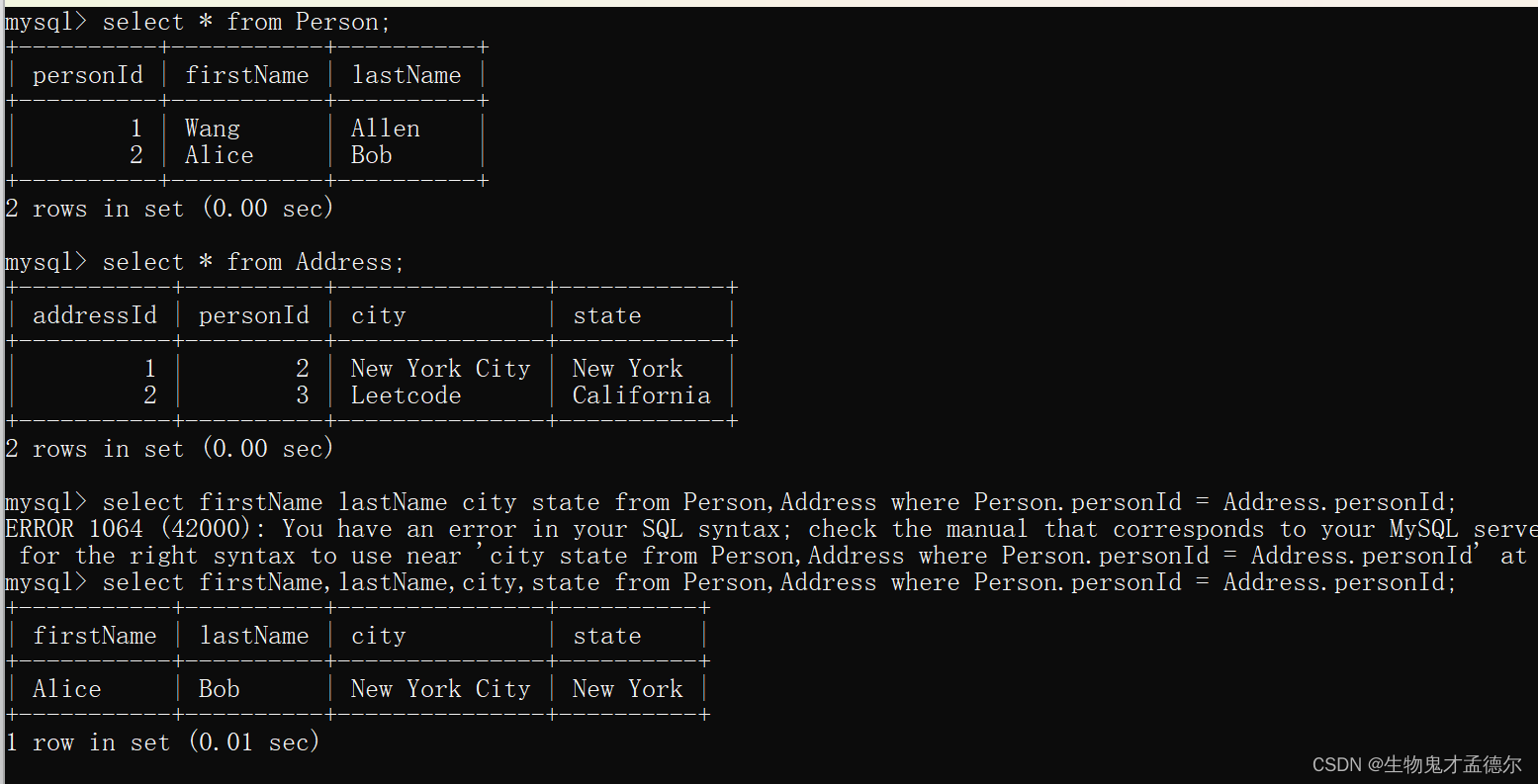
题目给了两张表,一张Person一张Address,他让你求出每个人的姓名,城市和州,如果这个人的地址不在Address表中,就显示null。
分析:我们先用以前的方法做一下,这里有两张表,我们在前面说过多表查询,那么这两张表的联系就是personId对吧,所以我应该这样写:
使用普通多表查询解决:
select firstName lastName city state from Person,Address where Person.personId = Address.personId;
结果:
大家可以看到,他只把Alice给找出来了,因为在Address表中,personId的取值只有2和3,而Person表中的是1和2,所以如果采取这种多表查询的老办法我们只能关联到personId为2的Alice,这和题目中的要求是不一致的
所以我们这里不能用以往的方法解决,那我们看看上面的三张图,对应的三个连接,该用哪个呢?
首先我们就可以排除第一个内连接(inner join),可以看到它就是求一个交集嘛,那不就是我们以往的这种方法吗,所以我们只能使用左外连接和右外连接
使用外连接解决:
我这里用左外连接来分析,再来看看这张图:
你会发现,它实际上是吧table1的所有东西都考虑进去了,然后再加上交集部分,这就是外连接,更通俗来说就是:如果左侧的表完全显示我们就说是左外连接
那么此题的意思实际上就是这样,它要报告Persion表中的所有信息,即使在Address表中没有对应也要显示null,这完全可以用左外连接来实现:
这条语句我们来分析一下:
mysql> select firstName,lastName,city,state from Person left join Address on
-> Person.personId = Address.personId;这里用到left join on,这就是左外连,在左侧的Person表会完全显示,on后面写上条件,这里两张表用personId关联,这个条件会找出两表personId相同的记录,然后把名字、地址给找出来,但是如果第一张表的personId无法与第二张表对应,这里也会显示出来

*mysql约束小结
这里把前面讲的所有约束做一个总结:
约束用于确保数据库的数据满足特定的规则,在MySQL中,约束包括not null,unique,primary key,foreign key,check五种,其实我们前面已经把前四种都讲了,我们现在做个小结:
primary key(主键)
- primary key不能重复而且不能为null
- 一张表最多只能有一个主键,但可以是复合主键
- 使用 desc 表名可以看到primary key的情况
- 主键的指定方式有两种:
1.直接在字段名后面指定:字段名 primary key
2.在表定义最后写 primary key(列名)
not null(非空)
- 如果在列上定义了not null,那么当插入数据的时候,必须为列提供数据
- 一般我们还会和default配合使用指定默认值,当你不提供列数据的时候,就会初始化为默认值
字段名 字段类型 not null default....
unique(唯一)
- 当定义了唯一约束后,该列值是不能重复的
- 如果没有指定not null,则unique字段可以有多个null
- 一张表可以有多个unique字段
字段名 字段类型 unique
check(检查)
- 用于强制数据必须满足的条件
* 自增长
某张表中,存在一个id列(整数),我们有时候希望它就是自然排列(1,2,3....),也就是说他可以自动的增长这一列的值,这里就可以用自增长
字段名 整形 primary key auto_increment
也可以修改自增长的开始取值:
ALTER TABLE table_name auto_increment = xxx
注意点:
1.一般来说自增长是和primary key配合使用的
2.也可以单独使用,但要加上unique
3.自增长的修饰字段为整形(小数很少用到)
简单来说就是不能让他重复

我们分别举例子:
第一种添加方式:

这是一张学生表,其中id被我设置为自增长,现在我来添加数据:

从这里可以发现两点:
第一,如果我设置了自增长,这一列数据直接填写null他就会自增长
第二,自增长默认从1开始逐一递增
第二种添加方式:

这里也很有趣,第一次我写错了,所以添加了个null进去,然后我把id为3的记录删除后,使用第二种方式添加:也就是不写自增长的列,但其他列名都要写出来而且给值。但是我再次添加的时候直接跳过3了,所以得出结论:自增长会一直进行下去,即使你其中有删除元素的操作。
解决办法就是你重新设置自增长的开始取值:ALTER TABLE table_name auto_increment = xxx,这里就不演示了。
*mysql索引
MySQL 索引是一种数据结构,用于加快数据库查询的速度和性能。
MySQL 索引的建立对于 MySQL 的高效运行是很重要的,索引可以大大提高 MySQL 的检索速度。
MySQL 索引类似于书籍的索引,通过存储指向数据行的指针,可以快速定位和访问表中的特定数据。
打个比方,如果合理的设计且使用索引的 MySQL 是一辆兰博基尼的话,那么没有设计和使用索引的 MySQL 就是一个人力三轮车。
拿汉语字典的目录页(索引)打比方,我们可以按拼音、笔画、偏旁部首等排序的目录(索引)快速查找到需要的字。
这里我先带大家看看索引的威力,看看它究竟可以提高多少速度 :

我建了一张表,里面有80万条数据,现在我按照emp的empno来进行查询,看看耗时多少(这张表怎么建起来的不重要,你只需要知道这里面数据量非常大就行了):

注意看下面的时间:2.662秒,这对于计算机来说是非常慢的,而且如果连接你这张表的程序有很多,那么就会耗费很多时间,索引就是用来解决这个问题的。
我们在建立索引之前来看看这个:
这是没有建立前,emp表的大小,那么下面我就在empno列上面创建索引:
首先看看大小:
![]()
可以看到由原来的520变到655,所以索引的增加并不是只有利而没有缺点,这就是一个缺点
索引可能带来的缺点:
- 索引需要占用额外的存储空间。
- 对表进行插入、更新和删除操作时,索引需要维护,可能会影响性能。
- 过多或不合理的索引可能会导致性能下降,因此需要谨慎选择和规划索引。
那我们现在再来查询empno=1234567这个人的信息,看看这次用时多少?
提升了不是一点半点,现在已经非常快了。
这里来简单说一下索引的基本原理,首先我们要知道,没有索引的时候,用Select语句进行查询的话,是会进行全表扫描的,而创建索引后,其实是会创建一个二叉树这样的数据结构,进而提升查询效率。

比如我随便画了个二叉树,可以这样理解,当你在某列建立索引后,当我要查找9的时候,我就会去进行比较,这里的两个子树,7>2,所以我就不会去左边去找,我就直接在右边这个树找,然后8 > 6,我又把6给舍弃了,直接去8下面找。
大概理解就行了,这涉及到数据结构的知识
说完了索引的优缺点,我们来看看具体怎么用:
1.查询表是否有索引:
SHOW INDEXES FROM t_name;
2.1添加普通索引1:
CREATE INDEX index_name ON t_name(column_name)
解释一下上面,第一个蓝色是索引名字,ON后面写表名,括号里面写你要在哪一列添加索引。
2.2添加普通索引2:
ALTER TABLE t_name ADD INDEX index_name(column_name)
其实就是前面说过的ALTER命令,两种都可以为某一列添加普通索引
如果某列的值,是不会重复的,比如班级里面学生的id,这是唯一的,则我们有限考虑使用unique索引,也就是唯一索引,否则才使用上面的普通索引
3添加唯一索引:
很简单,比上面多加一个unique就行了:
CREATE UNIQUE INDEX index_name ON t_name(column_name)
4.删除索引
DROP INDEX index_name ON t_name
ALTER TABLE t_name DROP index_name
比较特别的,如果是在主键上面建立的索引,我们称为主键索引,它的删除方式是:
ALTER TABLE t_name DROP PRIMARY KEY
5.查询索引的三种方式
有时候你需要查看这张表哪些列建立了索引,有三种方法:
SHOW INDEX FROM t_name
SHOW INDEXES FROM t_name
SHOW KEYS FROM t_name
6.哪些列上适合使用索引?
- 较频繁的作为查询条件的字段应该创建索引,比如一张学生表的id,这是唯一的,所以我们经常会这样查询:select * from student where id = xxx;像这样的列应该建立索引提高查询效率
- 唯一性太差的字段不适合单独创建索引,即使它可能也频繁作为查询条件,比如说性别,人的性别就分为男和女,虽然我们可能经常用这个去查询数据,但是不是男就是女,你也就没必要在这种列上建立索引了。
- 更新非常频繁的字段不适合创建索引
- 不会出现在WHERE子句的字段不要建立索引,你都不用它去查询,你建立索引只会白费资源
7.一些细节:
主键直接就是索引,也就是说你在该列写个Primary key,它就自动为你添加索引在这一列了
看个大概就行了,不用死记硬背,多用几次就熟练了
索引练习:
e1:建立索引(主键)创建一个订单表(id,商品名,订购人,数量),要求id为主键,你能用多少种方式来创建主键?
题解:第一种方法:直接在创建表的时候在某列后面加primary key就行了

法二:建完表之后用ALTER指令去增加主键索引:
 *mysql事务
*mysql事务
1.事物是什么?有什么作用?
事物用于保证数据的一致性,它由一组dml语句组成,这些语句要么全部生效,要么全部不生效,举个非常容易理解的例子:转账操作,比如张三找李四借了100块钱,那么要执行的操作就是张三的钱-100,然后李四的钱+100,如果因为某些原因,导致只执行了前面,而后面没执行成功,这个时候张三少了100块钱,而李四又没借到钱,你说说这找谁去说理去?
为了解决这类问题,我们就得使用到事物这个机制,事物操作的示意图如下:

解释一下:在a点开启事物,然后设置保存点(savepoint),在b点也设置保存点,当我执行到最后的时候,假如发现没有问题,就可以执行提交操作(commit),如果我发现有问题,比如张三给的钱李四没拿到,那我就可以进行回滚操作(rollback) ,回滚到之前保存点的位置,其实这就是游戏的回档操作嘛,很多游戏都有这个操作,像我玩过的比如饥荒(Don‘t starve)还要森林(the forest)都可以设置存档点进行回档,以弥补玩家之前犯的错误(比如作死)
2.事物和锁

事物还有个特点,就是当我们对表进行事物操作的时候,只要还没有进行commit操作,其他用户就不能修改表的数据,这种安全机制挺不错的
3.通过例子讲解事物操作
下面列出了mysql数据库进行事物控制的几个操作,我们用一个例子来讲解:
第一步,创建测试表,然后使用start transaction 开启事务,之后马上设置一个保存点 savepoint a,然后执行两条插入操作,此时查询是这样的:


第二步,设置保存点b,然后再插入数据,此时表中是这样的:

下面就要开始回退了:

第三步:使用rollback to b回退到之前的savepoint b 这个保存点,我们还可以回退到a:
结果完全正确,开启事务后,设置保存点然后在必要的时候进行回退操作,就真的可以回到当初的样子,你以为这就结束了吗?千万要记得,开启事务后一定要提交!!!!!!! 不然你等于啥也没干
第四步:进行提交,这里我还必须指出一点,这里我们的保存点的顺序是a—》b,我们给刚刚先跳到b然后又跳到a,如果你此时再想回到b,是不可以的,也就是说这个rollback to 操作只能进行回滚,不能往前去查,你从a到b是错误的

提交完毕,这个时候这个事物就算完成了,其实实操起来还是很简单的,做个总结:
事物操作具体步骤:
1.开启事务 start transaction
2.在必要的地方设置保存点 savepoint a | b....
3.必要时进行回退 rollback to a | b....
4.在全部事都做完后,进行整体的提交 commit
事物细节:
这里不做演示了,很简单,可以自己试试
4.事物隔离级别

因为在一个程序中,可能有多个地方在同时并发的操作同一张表,只是查询倒没什么问题,但是如果进行某些操作的时候,就会出现问题,比如可能A程序还没有把全部数据添加进去,也就是还没有把这个事物进行commit,B程序就用select全部读取出来了,这就会出现脏读,所以必须要了解mysql的事物隔离级别,才能解决这类问题
下面是脏读、不可重复读、幻读的简要说明,这些都是比较大的问题,而隔离级别可以解决这些问题

mysql的隔离级别:

我这里写一个案例程序,去测试每一种隔离级别会产生的问题,在这个过程中对隔离级别的指令进行讲解
我们来看看默认隔离级别是什么:

可以看到MySQL默认的隔离级别其实已经很安全了,是可重复读的隔离级别,也就是多用户多线程是可以重复读的
隔离级别的指令:
 这个默认隔离级别可以去mysql安装目录下的配置文件中修改,但没必要。
这个默认隔离级别可以去mysql安装目录下的配置文件中修改,但没必要。














 4373
4373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









