






一、弹幕爬取
本文在这里主要使用的是正则来爬取弹幕,爬取代码放在文中并附带注释,关于文中正则表达式的疑惑可以自行谷歌。爬虫的代码已给出,基本步骤不再赘述,但这里涉及到多个视频的爬取,因此详细说一下爬取原理。视频一共有200p,在视频网址的response中我找到了每一个视频的cid和part值,其中part值很明显是视频标题,cid经过比对发现是与弹幕地址中的oid值匹配;
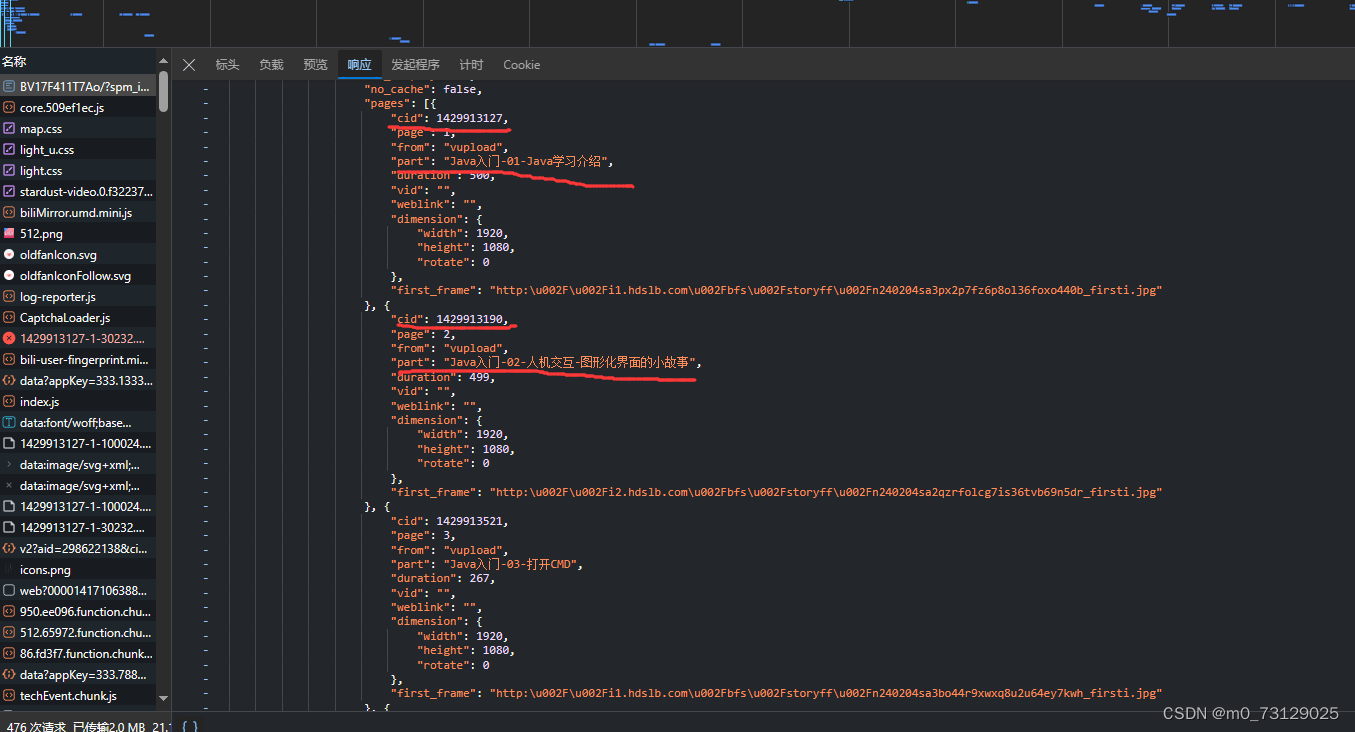
因此,首先第一步我们先爬取到response中所有的cid与part值,并存入列表中;因为
url = 'https://www.bilibili.com/video/BV17F411T7Ao/?spm_id_from=333.337.search-card.all.click&vd_source=55dd75efcade4511a5a130a17e9fd405'
headers = {
"User-Agent": "...",
"Cookie":"...",
"Referer":"...",
}
response = requests.get(url=url, headers=headers)
js_text = response.text
# 假设 js_text 是包含 JavaScript 数据的文本
# 使用正则表达式匹配 window.__INITIAL_STATE__ 字典
pattern = re.compile(r'window\.__INITIAL_STATE__\s*=\s*({.*?});', re.DOTALL)
match = pattern.search(js_text)
cid_list=[]
part_list=[]
if match:
# 获取匹配到的 JavaScript 数据
js_data = match.group(1)
# 解析 JavaScript 数据为字典
initial_state = json.loads(js_data)
# 获取 videoData 字典中的 pages 列表
pages = initial_state.get('videoData', {}).get('pages', [])
# 提取每个页面的 cid 值
for page in pages:
cid = page.get('cid')
course=page.get('part')
# print("CID:", cid)
cid_list.append(cid)
part_list.append(course)
print(cid_list)
print(part_list)接下来我们可以设置for循环爬取,给出你所要爬取的视频个数,代码会根据cid值爬取不同的视频弹幕,然后利用正则匹配出其中弹幕的发布时间戳,发布者id,弹幕唯一id等信息,当然最重要的是弹幕内容,然后将这些写入事先创建好的csv文件中。
for i in range(200):
# 循环爬取每个视频页(每个视频都有不同的oid)
# 首先给出requests的三件套
url = f"https://api.bilibili.com/x/v1/dm/list.so?oid={cid_list[i]}"
headers = {
"User-Agent": "...",
}
response = requests.get(url=url, headers=headers)
response.encoding = 'utf-8'
xml_text = response.text
print(xml_text)
# 利用正则匹配到所有的表头
pattern = r'<d p="([\d.]+),(\d),(\d+),(\d+),(\d+),(\d+),(\w+),(\d+),(\d+)">(.*?)</d>'
kecheng = part_list[i]
matches = re.findall(pattern, xml_text) # 返回的是一个列表中包含了很多元祖[(...,...,...,...,)()()()] ,元祖中的第一个元素用match[0]表示,和列表一样
for match in matches:
time_stamp = match[4]
danmu_time = match[0]
# font_size = match[2] # 字体大小
# color = match[3] # 字体颜色
sender_id = match[6]
danmu_id = str(match[7])
print(danmu_id)
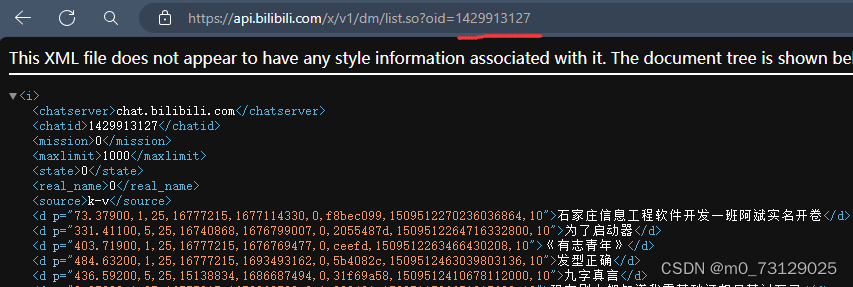
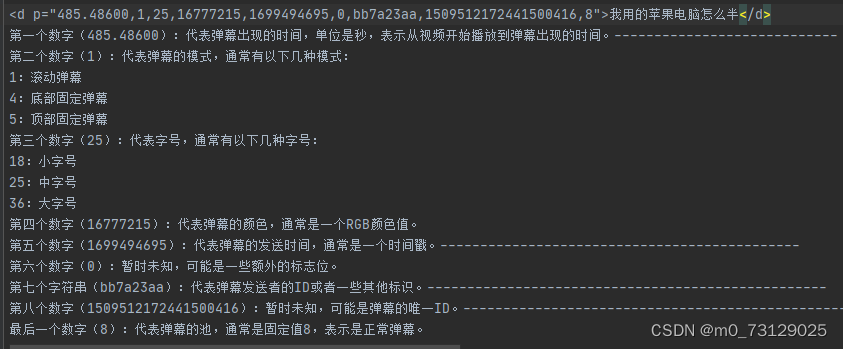
danmu_content = match[9]在这里解释一下:在弹幕网址中的d标签中有九个数字,在网上搜索得知他们分别代表了不同的意思;因此我们可以取出每次循环中的match中对应的元素,将其赋给我们指定的参数,最后将其写入csv文件中。
二、使用pandas库处理数据
由于所爬取到的弹幕发布时间是时间戳的形式,因此可以使用map(datetime.fromtimestamp)方法将其转换为日期,辅助其他方法进一步得到具体的年月日甚至是小时;(map方法通常是对series列的操作,可以传入函数或字典形式,更多的是使用函数,例如:danmu['年'] = danmu['弹幕发布时间日期'].map(lambda x:x.year),它使用map函数将danmu['弹幕发布时间日期']这一列的日期数据中的年份取出来,并赋予给新的一列danmu['年'] )
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 能够让图表中的中文正常显示
import pandas as pd
from datetime import datetime
file1=pd.read_csv('弹幕爬取模版_02.csv')
# 可以加入参数更改数据类型, file1=pd.read_csv('弹幕爬取模版_02.csv',converters={'uid':str,'id':str}) 会将CSV文件的内容读取到一个DataFrame对象中,并赋值给变量file1
# print(file1)
danmu=pd.DataFrame
danmu=file1
# print(danmu) # 将得到的表格命名为danmu,并转化为dataframe
danmu['弹幕发布时间日期'] = danmu['发布时间'].map(datetime.fromtimestamp) # datetime数据类型,具有年月日时分秒等多个属性 将时间戳转换为日期
# map() 方法被用于对 DataFrame 中的某一列(例如 '发布时间')中的每个元素应用一个函数,然后将结果存储到新的列中(例如 '弹幕发布时间日期')。
danmu['年'] = danmu['弹幕发布时间日期'].map(lambda x:x.year)
danmu['月'] = danmu['弹幕发布时间日期'].map(lambda x:x.month)
danmu['小时'] = danmu['弹幕发布时间日期'].map(lambda x:x.hour)
danmu['星期']= danmu['弹幕发布时间日期'].map(datetime.isoweekday)
danmu['用户弹幕数']=danmu.groupby('uid')[['弹幕唯一ID']].transform('count')
# danmu.groupby('uid')[['弹幕唯一ID']] 表示对 'uid' 这一列进行分组,并且选择了 '弹幕唯一ID' 这一列。
# 然后,.transform('count') 将对每个分组的 '弹幕唯一ID' 列进行计数操作,并将结果广播回原始数据的相应位置在Python中使用pandas库将所爬取到的弹幕csv文件转化为dataframe格式并命名为danmu,这里我选取了2023一整年的数据,将其保存为csv文件
danmu_year = danmu[danmu['年']==2023] # 取出满足条件‘年’==2023年的所有数据 这里的danmu_year 也是一个dataframe
danmu_year.to_csv('JAVA弹幕数据分析用.csv', encoding='utf-8-sig', index=False)我们可以去jupyter中更加清晰地查看这个csv文件,它是一个dataframe类型。(pandas里面主要有两种类型dataframe和series,dataframe的结构与Excel很相似,series可以看成是dataframe中的一列)
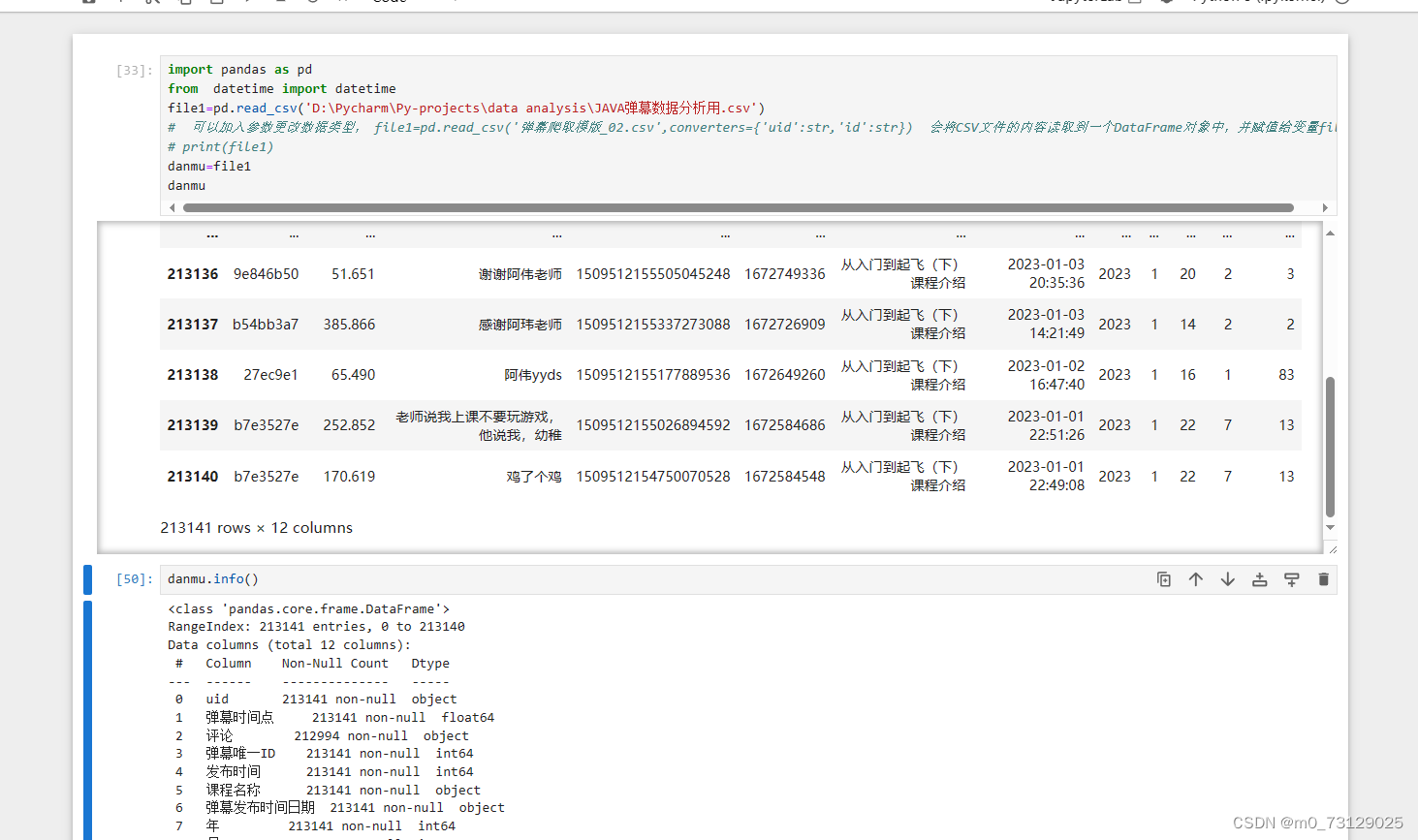
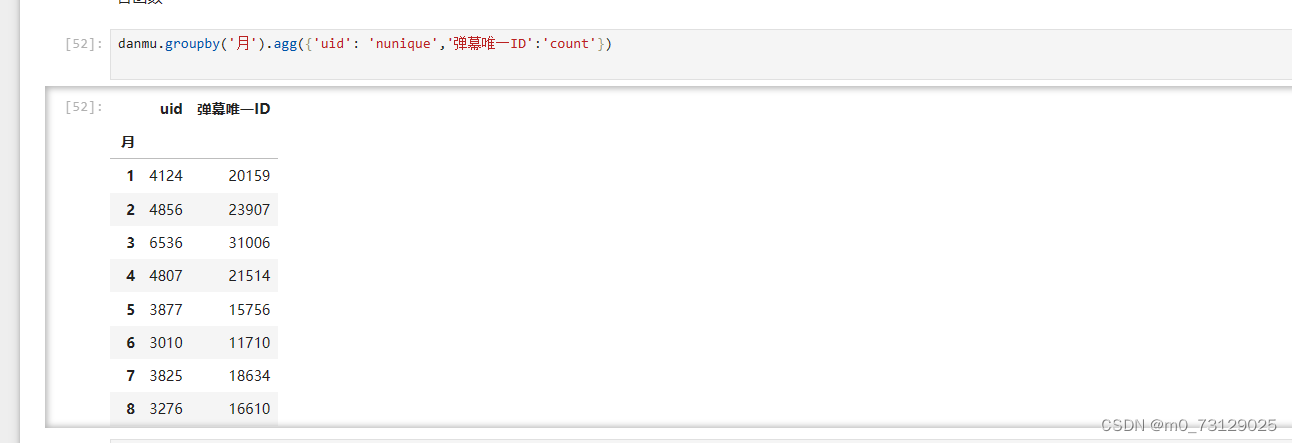
我们可以看到2023年一共装载了21万条的弹幕,继续使用jupyter执行一些数据处理操作:
使用groupby对月份进行分组
查看每个月的用户数和弹幕数,count执行计数功能,用户数这里需要使用nunique进行去重,因为一个用户可能存在多条发言。(对小时和星期的分组分析类似)
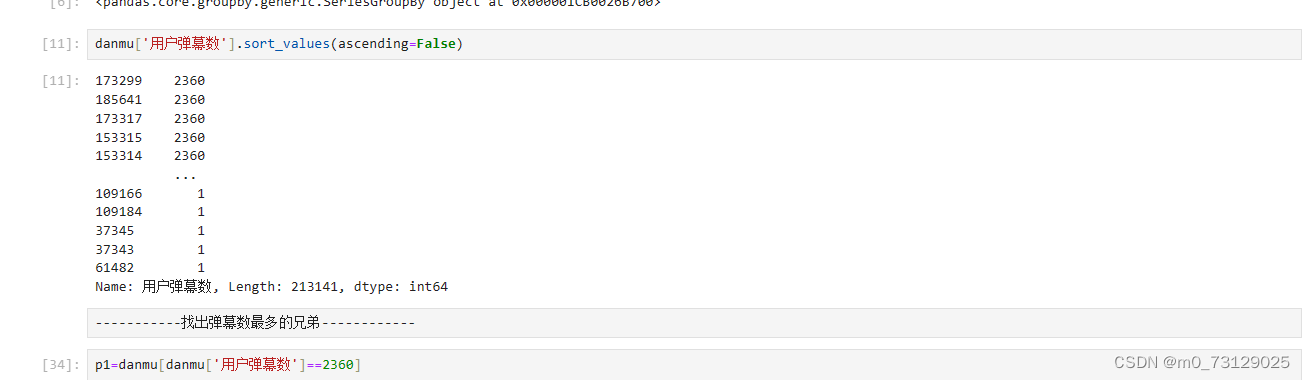
我们还可以查看发言数最多的哥们
将用户弹幕数字段按照降序顺序排序(这里没有进行去重),可以看出发言最多数达到了2300条,视频一共有200p,平均下来这位老哥每个视频都要发10条弹幕~
我们可以选取前五十条弹幕看看他都说了啥:
我们还可以对基于小时,星期的数据进行分析,下面在pycharm里面演示。
三、折线图绘制
我们转到Python里面进行操作绘图,取出过去一整年(2023)里的所有数据,查看每个月份的弹幕数量以及发言的用户数,图中可以看到2、3月份的弹幕数量最多。另外还可以看到一个有趣的现象,弹幕的数量基本上保持在用户数量的四至五倍,也就是平均一个人每个月会发四或五条弹幕。
danmu_year = danmu[danmu['年']==2023] # 取出满足条件‘年’==2023年的所有数据 这里的danmu_year 也是一个dataframe
print(danmu_year)
danmu_year.groupby('月')[['弹幕唯一ID']].count().plot() # 查看每个月份的弹幕数量
danmu_year.groupby('月')[['uid']].nunique().plot() # 查看每个月份的用户发言数量,一个人可能出现多次,所以用nunique
# # 结论:3月份的弹幕数量最多,3月份开学
(推测:对于学生来说可能是开学季,对于工作的人来说,春节刚过,大部分人都投入到了一个比较好的学习状态,导致这个时间段的学习人数激增,金三银四对于找工作的人来说也是一个福音;因此,对于学习类视频up主,可以在二三月份或者9月份左右上传比较系统的学习视频,理论上有更多的机会会获得更好的自然流量。)
我们可以继续对星期进行分析,以此来观测大家的学习时间分布,以星期来分组并计算每个星期的弹幕数和发言用户数,从图中可以很明显的看出周一周二周三的学习人数最多,但后面呈现下滑趋势,周五周六降至最低点,周日又有回归趋势;不难看出到了周末,大部分人可能都选择放松下来;因此学习类的视频可以避开周五周六发布。
danmu_year.groupby('星期')[['弹幕唯一ID']].count().plot()
danmu_year.groupby('星期')[['uid']].nunique().plot()
# 结论: 周一二三四的人最多,周五周六急剧下滑 因此学习类视频可以避开周五周六发布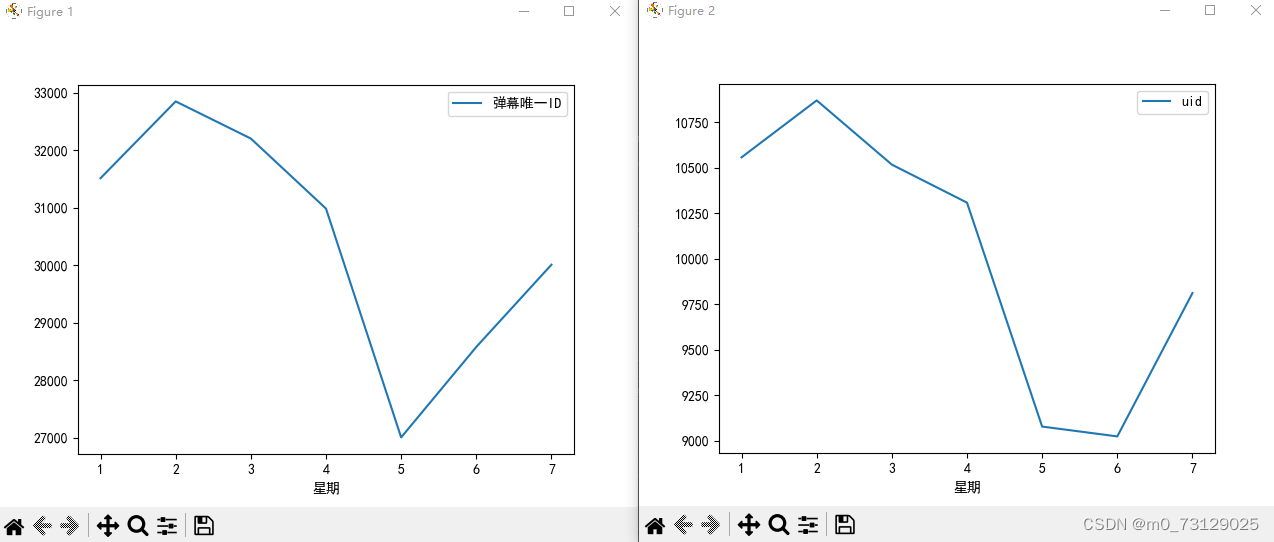
最后我们再来看一下观看的具体时间段(以小时分布),下午三四点观看的人数较多,但在晚上八点达到了巅峰,这也与我本人学习的时间段相符合;以此来看,学习区的up主可以选择在下午或者是晚上八点左右开通直播课程增加互动,为课程增加更多的潜在播放量。
danmu_year.groupby('小时')[['弹幕唯一ID']].count().plot()
danmu_year.groupby('小时')[['uid']].nunique().plot()
# 结论:晚上八点人看的最多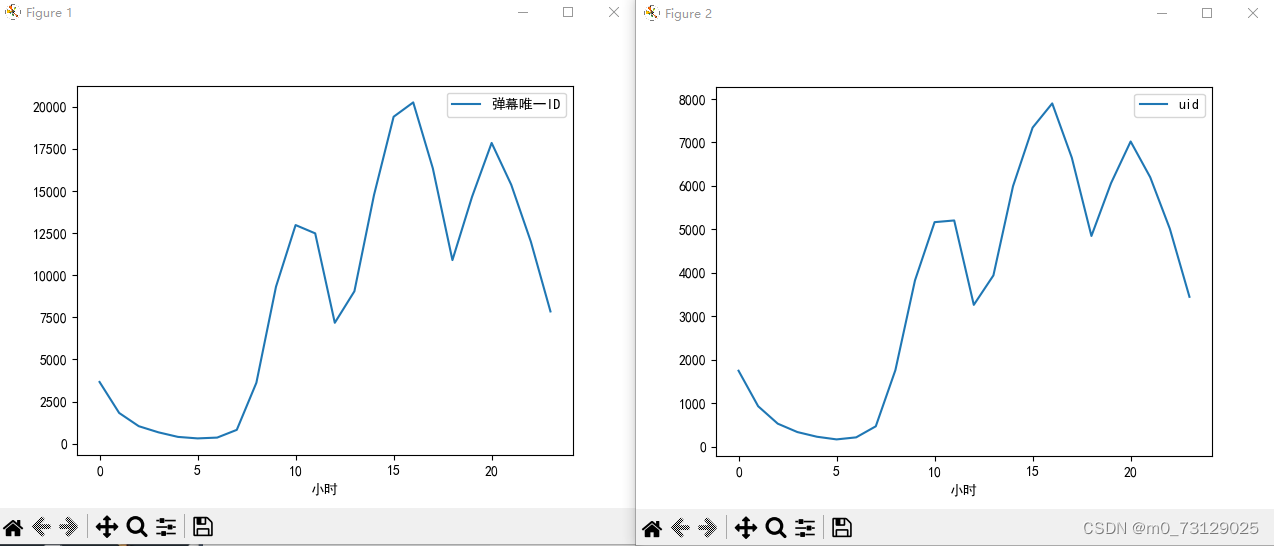
四、利用Tableau观测数据
我们在tableau中还可以更加详细的展示每个课程的详细信息,由于课程数量有200个较多,因此我们可以利用tableau筛选出弹幕数和用户数最多的几个课程或者是随机筛选若干个课程,观测视频的弹幕变化趋势。
我们把使用pandas处理过的数据danmu_year(dataframe)导出csv格式并使用tableau打开,
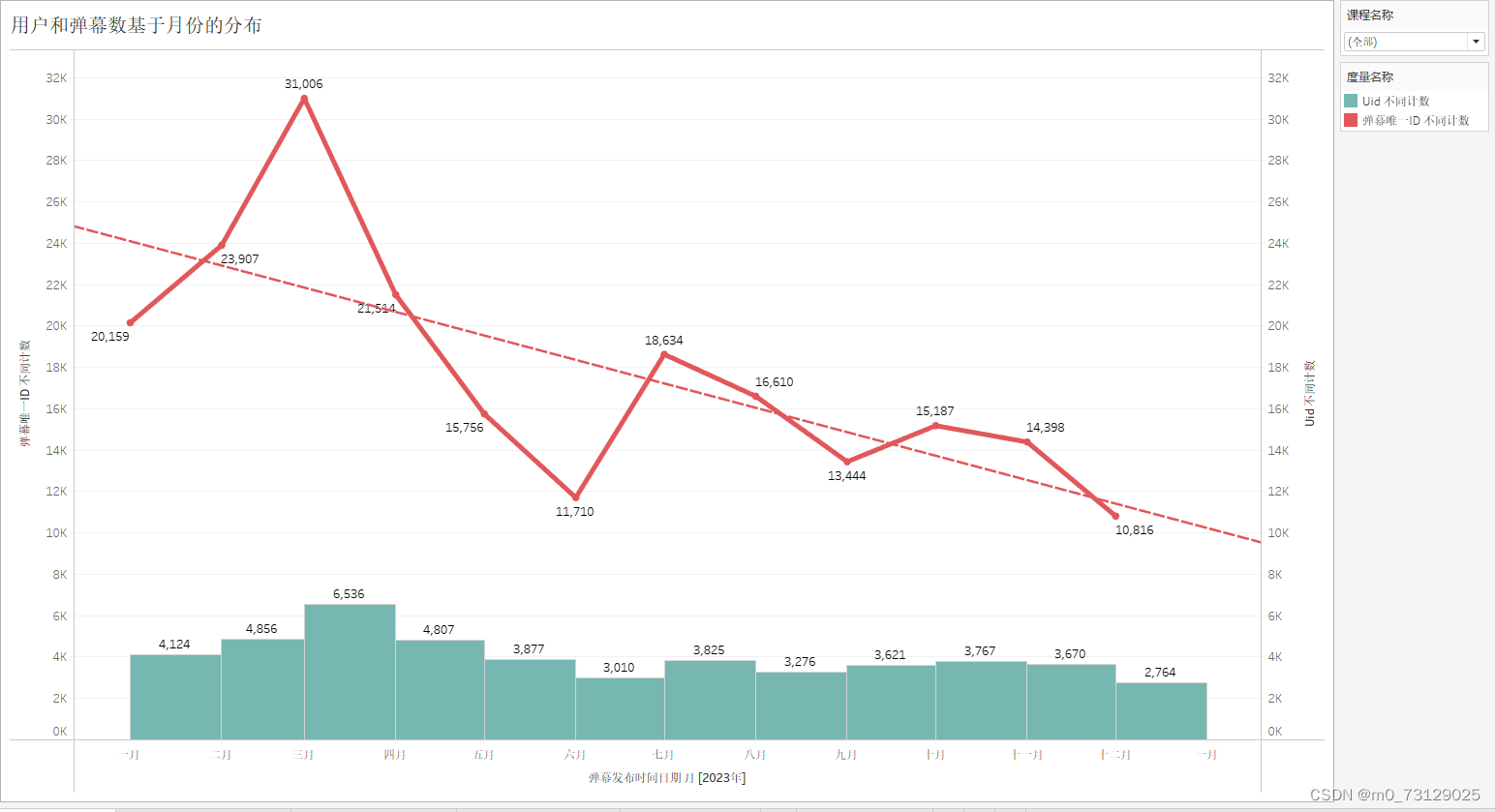
danmu_year.to_csv('JAVA弹幕数据分析用.csv', encoding='utf-8-sig', index=False)将课程名称添加为筛选器,并在tableau中绘制了弹幕数量基于月份的弹幕分布,可以看出弹幕数量最高点依然在三月份,另外两个小高峰在七月份和九十月份。

此外我们还可以观测总体的发言人数和弹幕数量两者基于月份的分布,并且绘制条形图和折线图,依然可以得到每个月的弹幕数量约是发言人数的五倍。
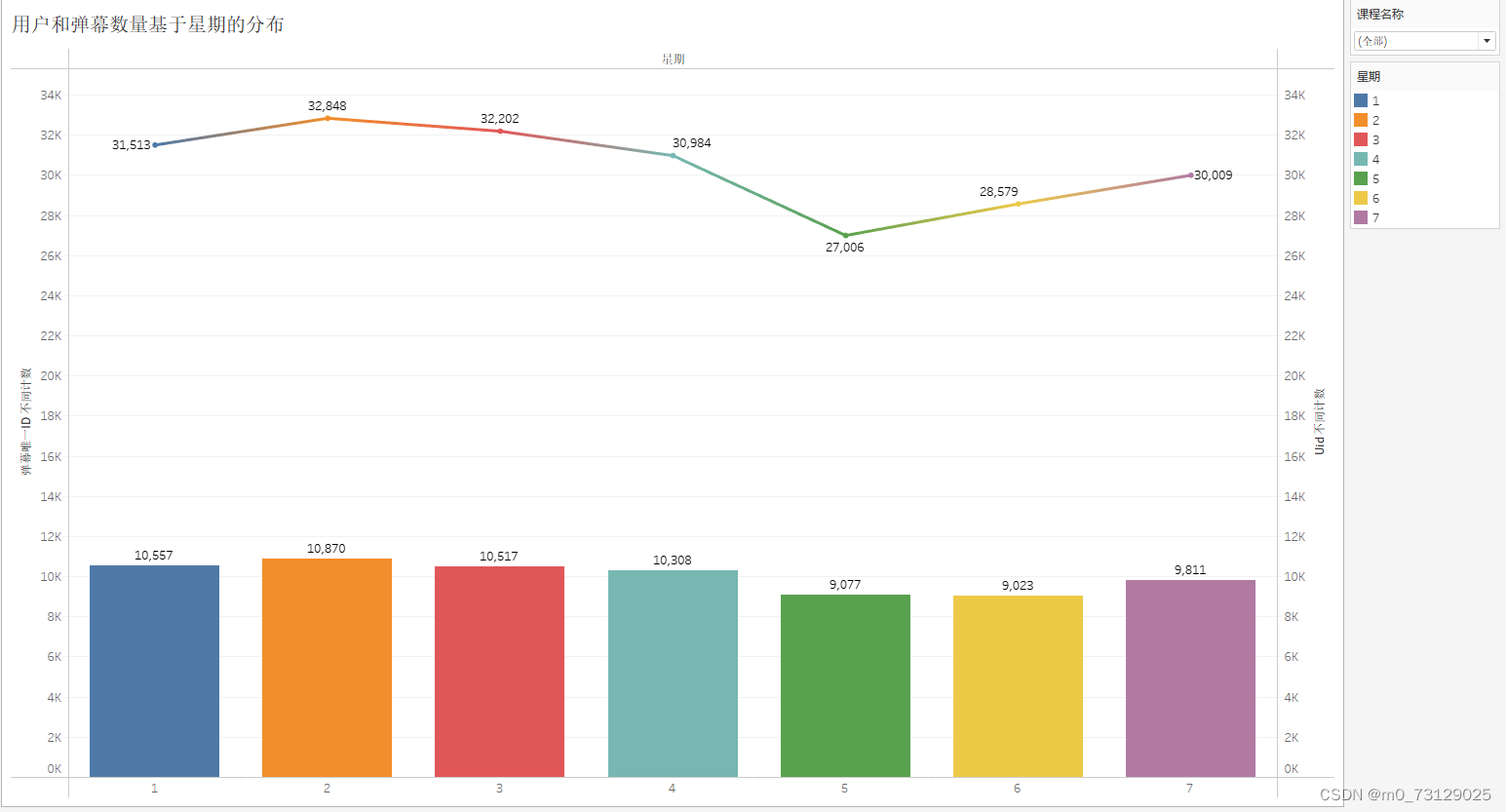
下面是基于星期和随机筛选的几个课程中基于小时的分布,可以看出其主要特征均与之前绘制的图形保持一致(学习人数高峰在周一周二周三,学习时间段在下午的三四点和晚上八点居多)

可以以饼图形式查看学习时间段较密集的部分: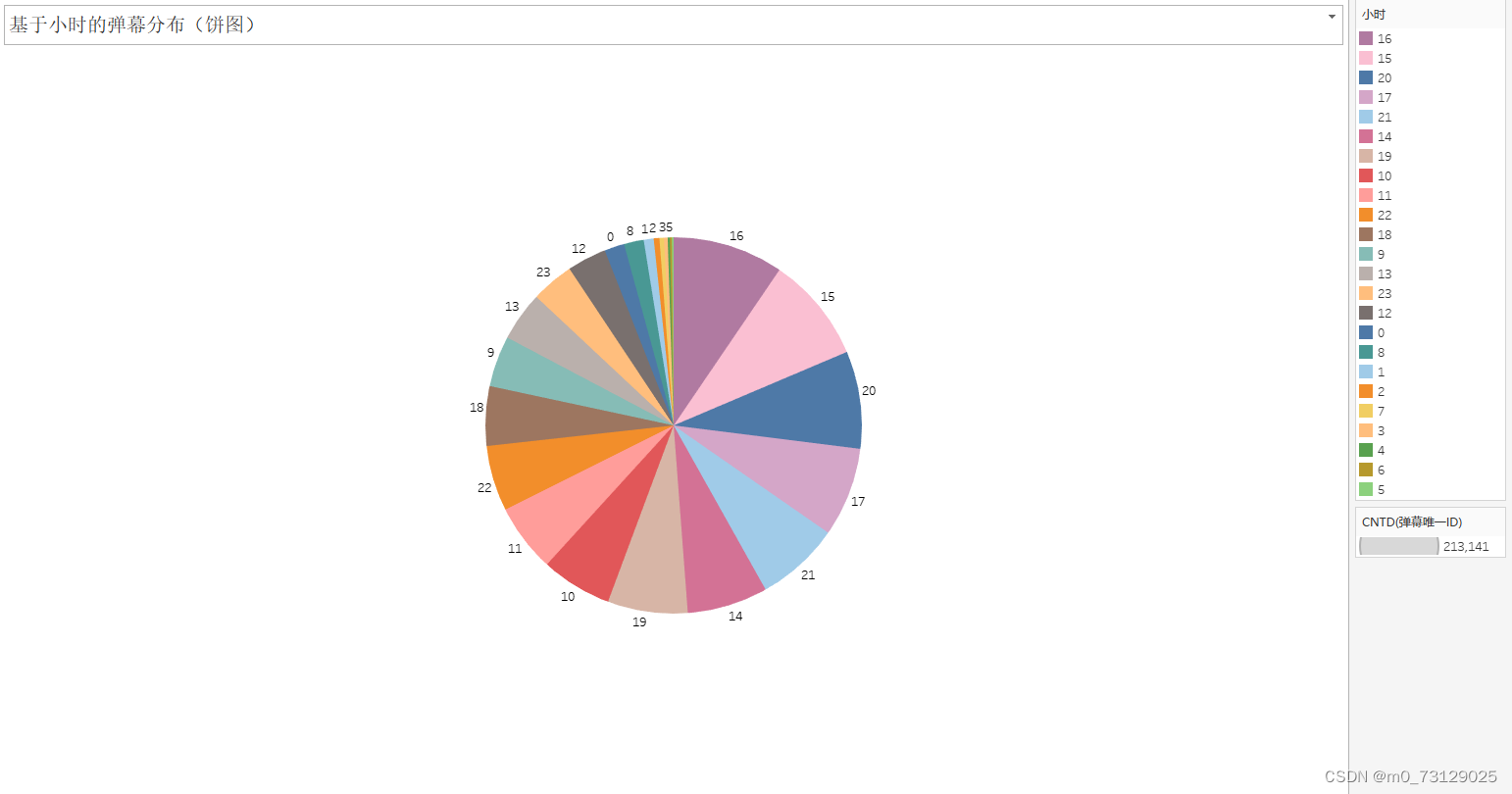
最后,我们还可以基于所有的课程进行分类,观测弹幕数量和发言人数最多的视频部分:
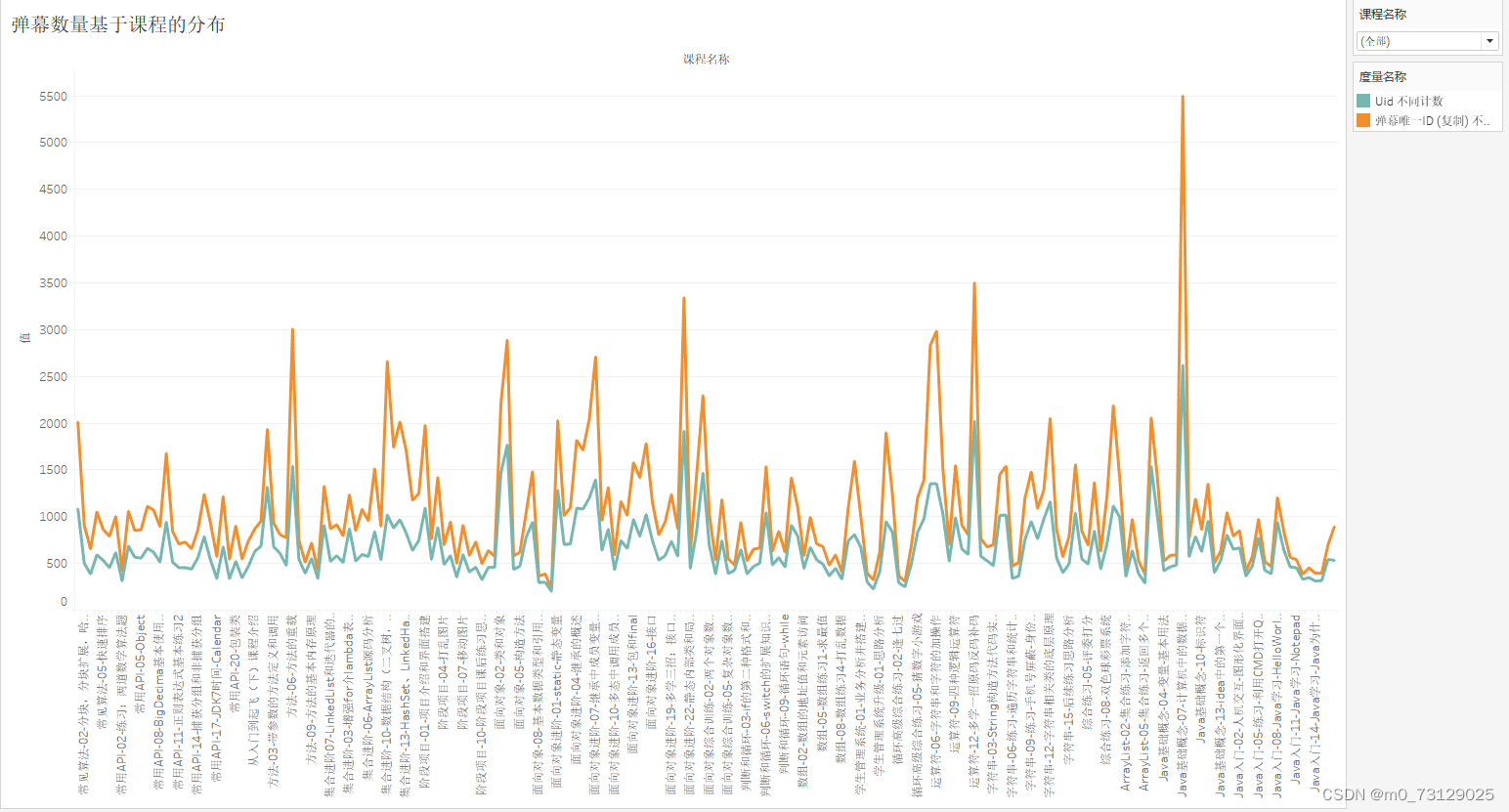
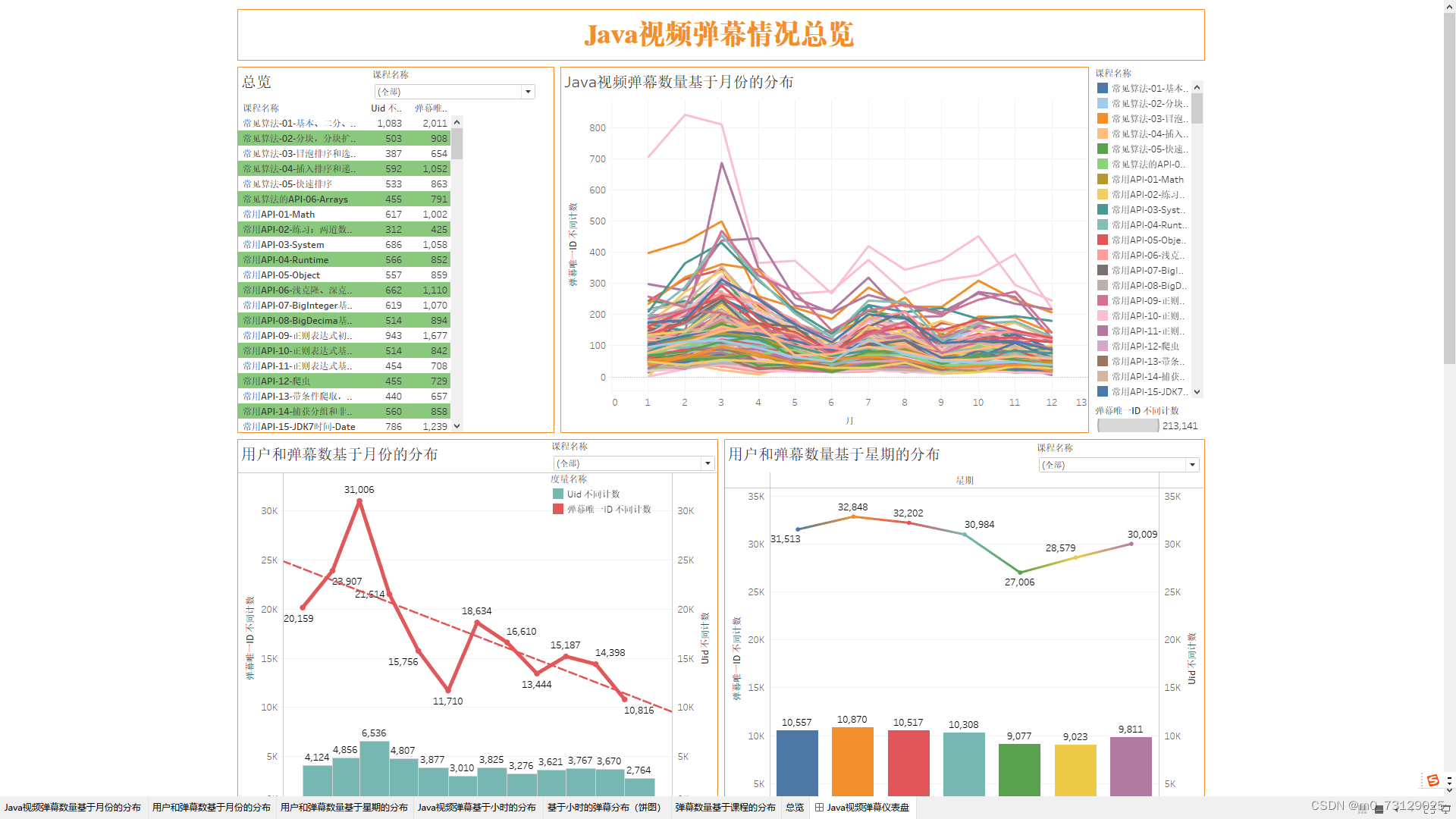
将所有图表汇总到一起搭建一个仪表盘,并且可以根据里面的筛选标签进行联动筛选并查看。
















 4026
4026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









