







python get_cfg_relation.py
如果发生报错,删除No_Vul107这个数据

首先关闭数据库neo4j
然后
rm -rf cfg_db
再然后要切到joern中,删除
rm -rf .joernIndex
再再然后,删除这个元素
rm -rf No_vul107
再再再然后重新获取运行joern。
java -jar bin/joern.jar No_vul/
重新这一步的开始
2.生成pdg图
首先创建文件夹
mkdir pdg_db
其次, 执行
python complete_PDG.py
3. 生成函数的图
首先创建文件夹
mkdir dict_call2cfgNodeID_funcID
其次, 执行
python access_db_operate.py
4. 生成四种SyVCs
执行
python points_get.py
5.获取四种切片
mkdir -pv C/test_data/4
执行
python extract_df.py
这里会报错,我们自己写脚本进行处理
比如说对于api切片,首先创建process.py文件
import re
with open(“./output.txt”, “r”) as file:
lines = file.readlines()
regex_pattern = r"\b([^/]+).c\b"
for line in reversed(lines):
match = re.search(regex_pattern, line)
if match:
matched_content = match.group(1)
break
import pickle
file = open(“./pointuse_slice_points.pkl”,“rb”)
info = pickle.load(file)
del info[matched_content]
with open(“./pointuse_slice_points.pkl”,“wb”) as f:
pickle.dump(info,f)
其次,创建process.sh
#!/bin/bash
count=0
while true; do
python2 ./extract_df.py > output.txt 2>&1
exit_status=
?
c
o
u
n
t
=
? count=
?count=((count+1))
echo “number_is $count”
if [ $exit_status -eq 0 ]; then
break
fi
cd /home/SySeVR/Implementation/source2slice/C/test_data/4
rm pointersuse_slices.txt
cd /home/SySeVR/source2slice
python2 ./process.py
done
~
然后对extract_df.py进行处理
coding:utf-8
from joern.all import JoernSteps
from igraph import *
from access_db_operate import *
from slice_op import *
from py2neo.packages.httpstream import http
http.socket_timeout = 9999
def get_slice_file_sequence(store_filepath, list_result, count, func_name, startline, filepath_all):
list_for_line = []
statement_line = 0
vulnline_row = 0
list_write2file = []
for node in list_result:
if node[‘type’] == ‘Function’:
f2 = open(node[‘filepath’], ‘r’)
content = f2.readlines()
f2.close()
raw = int(node[‘location’].split(‘:’)[0])-1
code = content[raw].strip()
new_code = “”
if code.find(“#define”) != -1:
list_write2file.append(code + ’ ’ + str(raw+1) + ‘\n’)
continue
while (len(code) >= 1 and code[-1] != ‘)’ and code[-1] != ‘{’):
if code.find(‘{’) != -1:
index = code.index(‘{’)
new_code += code[:index].strip()
list_write2file.append(new_code + ’ ’ + str(raw+1) + ‘\n’)
break
else:
new_code += code + ‘\n’
raw += 1
code = content[raw].strip()
#print “raw”, raw, code
else:
new_code += code
new_code = new_code.strip()
if new_code[-1] == ‘{’:
new_code = new_code[:-1].strip()
list_write2file.append(new_code + ’ ’ + str(raw+1) + ‘\n’)
#list_line.append(str(raw+1))
else:
list_write2file.append(new_code + ’ ’ + str(raw+1) + ‘\n’)
#list_line.append(str(raw+1))
elif node[‘type’] == ‘Condition’:
raw = int(node[‘location’].split(‘:’)[0])-1
if raw in list_for_line:
continue
else:
#print node[‘type’], node[‘code’], node[‘name’]
f2 = open(node[‘filepath’], ‘r’)
content = f2.readlines()
f2.close()
code = content[raw].strip()
pattern = re.compile(“(?:if|while|for|switch)”)
#print code
res = re.search(pattern, code)
if res == None:
raw = raw - 1
code = content[raw].strip()
new_code = “”
while (code[-1] != ‘)’ and code[-1] != ‘{’):
if code.find(‘{’) != -1:
index = code.index(‘{’)
new_code += code[:index].strip()
list_write2file.append(new_code + ’ ’ + str(raw+1) + ‘\n’)
#list_line.append(str(raw+1))
list_for_line.append(raw)
break
else:
new_code += code + ‘\n’
list_for_line.append(raw)
raw += 1
code = content[raw].strip()
else:
new_code += code
new_code = new_code.strip()
if new_code[-1] == ‘{’:
new_code = new_code[:-1].strip()
list_write2file.append(new_code + ’ ’ + str(raw+1) + ‘\n’)
#list_line.append(str(raw+1))
list_for_line.append(raw)
else:
list_for_line.append(raw)
list_write2file.append(new_code + ’ ’ + str(raw+1) + ‘\n’)
#list_line.append(str(raw+1))
else:
res = res.group()
if res == ‘’:
print filepath_all + ’ ’ + func_name + " error!"
exit()
elif res != ‘for’:
new_code = res + ’ ( ’ + node[‘code’] + ’ ) ’
list_write2file.append(new_code + ’ ’ + str(raw+1) + ‘\n’)
#list_line.append(str(raw+1))
else:
new_code = “”
if code.find(’ for ') != -1:
code = ‘for ’ + code.split(’ for ')[1]
while code != ‘’ and code[-1] != ‘)’ and code[-1] != ‘{’:
if code.find(‘{’) != -1:
index = code.index(‘{’)
new_code += code[:index].strip()
list_write2file.append(new_code + ’ ’ + str(raw+1) + ‘\n’)
#list_line.append(str(raw+1))
list_for_line.append(raw)
break
elif code[-1] == ‘;’ and code[:-1].count(‘;’) >= 2:
new_code += code
list_write2file.append(new_code + ’ ’ + str(raw+1) + ‘\n’)
#list_line.append(str(raw+1))
list_for_line.append(raw)
break
else:
new_code += code + ‘\n’
list_for_line.append(raw)
raw += 1
code = content[raw].strip()
else:
new_code += code
new_code = new_code.strip()
if new_code[-1] == ‘{’:
new_code = new_code[:-1].strip()
list_write2file.append(new_code + ’ ’ + str(raw+1) + ‘\n’)
#list_line.append(str(raw+1))
list_for_line.append(raw)
else:
list_for_line.append(raw)
list_write2file.append(new_code + ’ ’ + str(raw+1) + ‘\n’)
#list_line.append(str(raw+1))
elif node[‘type’] == ‘Label’:
f2 = open(node[‘filepath’], ‘r’)
content = f2.readlines()
f2.close()
raw = int(node[‘location’].split(‘:’)[0])-1
code = content[raw].strip()
list_write2file.append(code + ’ ’ + str(raw+1) + ‘\n’)
#list_line.append(str(raw+1))
elif node[‘type’] == ‘ForInit’:
continue
elif node[‘type’] == ‘Parameter’:
if list_result[0][‘type’] != ‘Function’:
row = node[‘location’].split(‘:’)[0]
list_write2file.append(node[‘code’] + ’ ’ + str(row) + ‘\n’)
#list_line.append(row)
else:
continue
elif node[‘type’] == ‘IdentifierDeclStatement’:
if node[‘code’].strip().split(’ ‘)[0] == “undef”:
f2 = open(node[‘filepath’], ‘r’)
content = f2.readlines()
f2.close()
raw = int(node[‘location’].split(’:‘)[0])-1
code1 = content[raw].strip()
list_code2 = node[‘code’].strip().split(’ ')
i = 0
while i < len(list_code2):
if code1.find(list_code2[i]) != -1:
del list_code2[i]
else:
break
code2 = ’ '.join(list_code2)
list_write2file.append(code1 + ’ ’ + str(raw+1) + ‘\n’ + code2 + ’ ’ + str(raw+2) + ‘\n’)
else:
list_write2file.append(node[‘code’] + ’ ’ + node[‘location’].split(‘:’)[0] + ‘\n’)
elif node[‘type’] == ‘ExpressionStatement’:
row = int(node[‘location’].split(‘:’)[0])-1
if row in list_for_line:
continue
if node[‘code’] in [‘\n’, ‘\t’, ’ ', ‘’]:
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数网络安全工程师,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
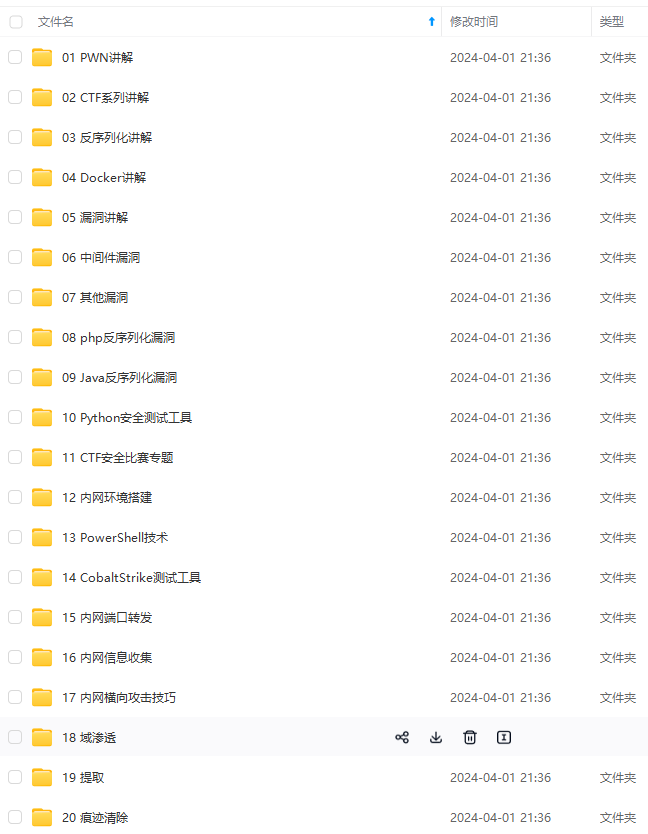
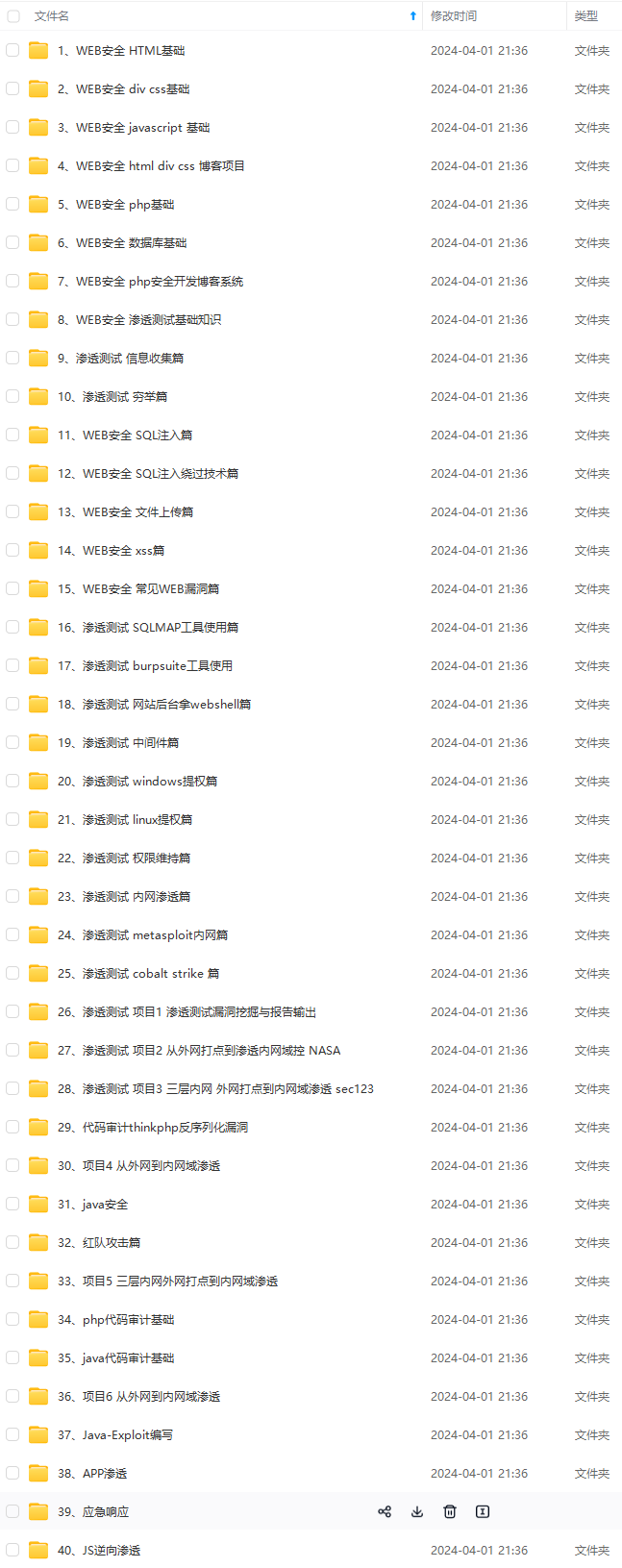
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注网络安全获取)

给大家的福利
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
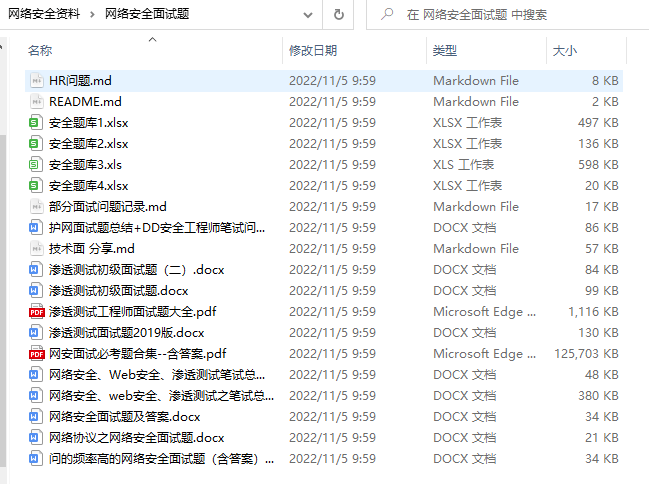
网络安全面试题
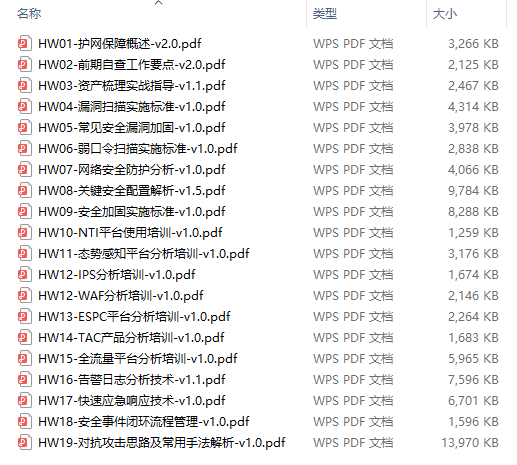
绿盟护网行动
还有大家最喜欢的黑客技术
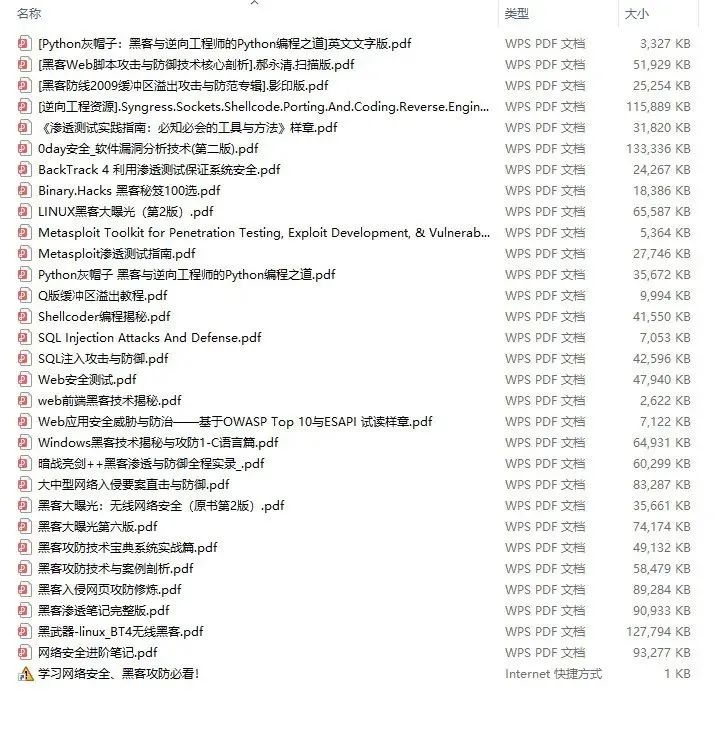
网络安全源码合集+工具包

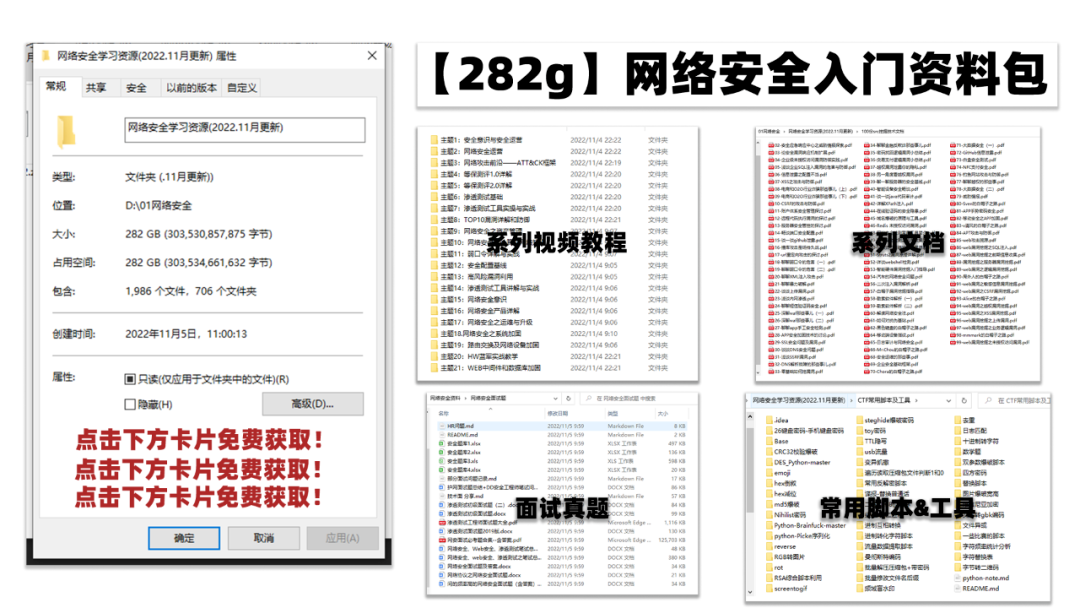
所有资料共282G,朋友们如果有需要全套《网络安全入门+黑客进阶学习资源包》,可以扫描下方二维码领取(如遇扫码问题,可以在评论区留言领取哦)~
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

9406fead3d3f03c.jpeg)
网络安全源码合集+工具包
所有资料共282G,朋友们如果有需要全套《网络安全入门+黑客进阶学习资源包》,可以扫描下方二维码领取(如遇扫码问题,可以在评论区留言领取哦)~
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[外链图片转存中…(img-6GsRGktO-1712719465338)]














 495
495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









