






问题
给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。
子数组是数组中元素的连续非空序列。
示例 1:
输入:nums = [1,1,1], k = 2 输出:2
示例 2:
输入:nums = [1,2,3], k = 3 输出:2
提示:
1 <= nums.length <= 2 * 104-1000 <= nums[i] <= 1000-107 <= k <= 107
思路
-
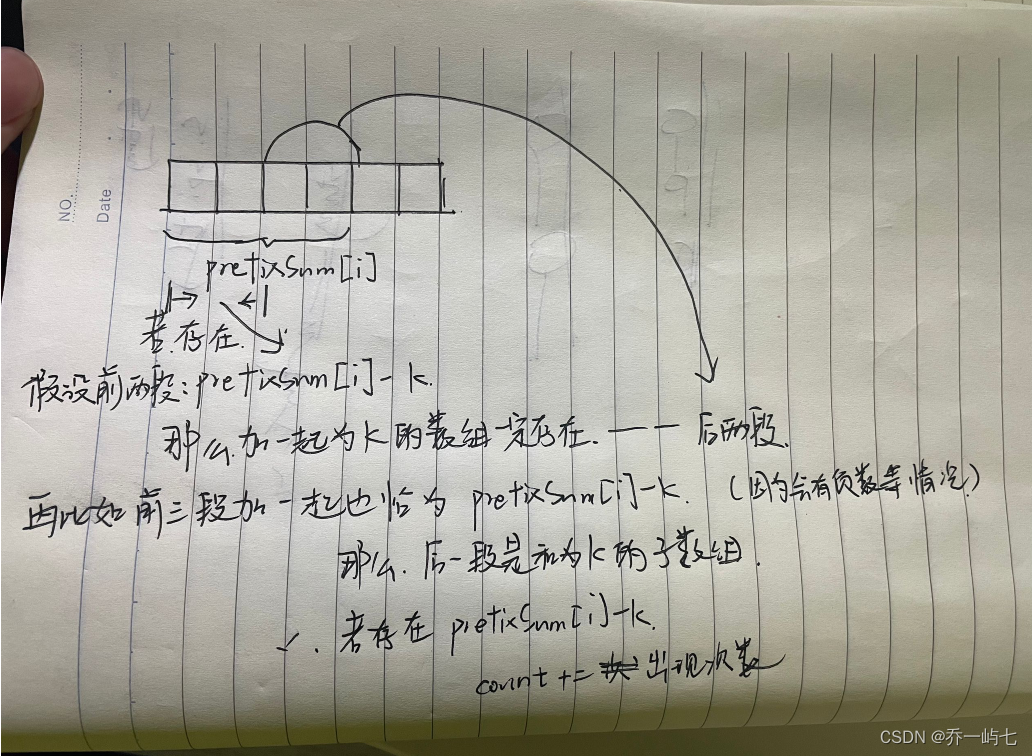
前缀和(Prefix Sum):
前缀和是一个数组处理技巧,用于快速计算数组中任意区间的和。对于数组nums,我们定义prefixSum[i]为nums中前i个元素的和,即prefixSum[i] = nums[0] + nums[1] + ... + nums[i-1]。通过前缀和,我们可以快速计算任意区间[i, j]的和,即sum[i, j] = prefixSum[j+1] - prefixSum[i]。 -
哈希表(HashMap):
哈希表是一种高效的数据结构,用于存储键值对。在这个问题中,我们使用哈希表来记录前缀和的出现次数。键是前缀和的值,值是该前缀和出现的次数。 -
算法步骤:
-
初始化一个哈希表
prefixSumCount,用于记录前缀和的出现次数。初始时,我们将0作为键,1作为值放入哈希表,表示前缀和为0的情况已经出现了一次。 -
初始化一个变量
count,用于记录和为k的子数组的个数。 -
初始化一个变量
prefixSum,用于记录当前的前缀和。 -
遍历数组
nums,对于每个元素num,更新prefixSum为prefixSum + num。 -
检查
prefixSum - k是否在哈希表中。如果在,说明存在一个子数组,其和为k,因为prefixSum - (prefixSum - k) = k。我们将哈希表中prefixSum - k对应的值加到count上。 -
更新哈希表中当前前缀和
prefixSum的出现次数,如果prefixSum已经存在,则将其值加1,如果不存在,则将其值设为1。 -
遍历结束后,
count即为和为k的子数组的个数。
-
-
时间复杂度:
该算法的时间复杂度为O(n),其中n是数组nums的长度。这是因为我们只对数组进行了一次遍历,并且在哈希表中的操作都是常数时间的。 -
空间复杂度:
空间复杂度为O(n),这是因为我们使用了一个哈希表来存储前缀和的出现次数,在最坏的情况下,每个前缀和都不同,哈希表的大小将和数组的长度成正比。
图解
代码
public static int subarraySum(int[] nums, int k) {
HashMap<Integer,Integer> map = new HashMap<>();
/*目的是如果第一个元素就是目标值,那么我们找prefixSum - k的时候,可以得到1,也就是让次数可以++。
如果没有这行代码 我们将无法找到前缀和为0的记录,从而无法正确地增加 count 的值*/
map.put(0,1);
int prefixSum = 0;
int count = 0;
for(int i: nums){
prefixSum += i;
//之所以是这种顺序是因为,是因为从之前的前缀数组中的某个点到当前点的子数组的和等于 k
//至于具体为什么,如果先更新map,更新完成后,判断map中是否存在prefixSum - k ,恰好存在,且值恰好为当前的前缀和,并不能得出一定会有相加为K的子数组,
// 只有在map中没有当前前缀和的时候,才能判断出有相加为K的子数组
if(map.containsKey(prefixSum - k)){
count += map.get(prefixSum);
}
map.put(prefixSum,map.getOrDefault(prefixSum,0)+1);
}
return count;
}问题
顺序问题
在这里讲讲 为什么要先 if 条件判断,再往 map 添加键值对。
始终注意一点:
当我们计算当前的前缀和 prefixSum 时,我们检查是否存在一个前缀和 prefixSum - k 在哈希表中。如果存在,这意味着在原数组 nums 中,从某个点到当前点的子数组的和等于 k。
说的再精确一点,就是从不包括当前节点的前缀和中的某个点,到当前点的子数组和为K。
具体表现就在于:如果先更新map,更新完成后,判断map中是否存在prefixSum - k ,如果恰好存在,且值恰好为算上当前节点的前缀和,但是这样并不能得出一定会有和相加为K的子数组,只有在map中没有当前前缀和的时候,才能判断出有相加和为K的子数组。
count 累加问题
举个例子来说明:
假设我们有数组 nums = [1, 2, 3, -1, 2],我们要找和为 k = 3 的子数组。
-
当我们遍历到索引2(值为3)时,
prefixSum是6,prefixSum - k是3,而哈希表中已经有前缀和3的记录,且出现次数为1。这意味着从索引0到索引2的子数组和为3,所以我们增加count的值为1。 -
当我们继续遍历到索引4(值为2)时,
prefixSum是8,prefixSum - k是5,而哈希表中已经有前缀和5的记录,且出现次数为1。这意味着从索引1到索引4的子数组和为3,所以我们再次增加count的值为1。
因此,count 的值反映了和为 k 的子数组的总数量,而不是每次发现一个子数组就简单地加1。
初始化问题
举个例子来说明:
假设我们有数组 nums = [3, 2, 1, 2],我们要找和为 k = 3 的子数组。
-
当我们遍历到索引0(值为3)时,
prefixSum是3,prefixSum - k是0,而哈希表中已经有前缀和0的记录,且出现次数为1。这意味着从索引0到索引0的子数组和为3,所以我们增加count的值为1。
如果没有 prefixSumCount.put(0, 1); 这一行,那么在第一次迭代时,我们将无法找到前缀和为0的记录,从而无法正确地增加 count 的值。















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









