






视觉之前做无监督分割的时候,经常使用grouping方法:如果有一些聚类的中心点,从这写点开始发散,把周围相似的点逐渐扩充成一个group,这个group就相当是一个segmentation mask
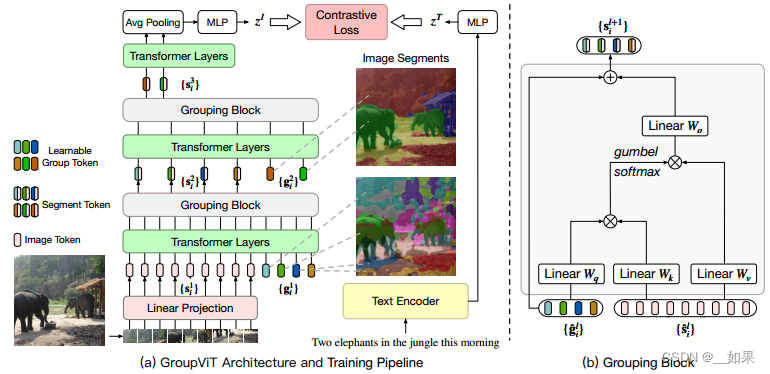
右边是grouping block,左边的两个层之间的小东西表示可学习的group tokens,目的是想要模型在初始学习的时候能慢慢的把相邻的像素点group起来,变成一个又一个的segmentation mask
可以看到浅层时的group token分割效果还不是很好,但经过transformer layers和grouping block的学习,深层的group token的分割效果很好
输入来自原始图像的patch embedding和group tokens,group token的第一维代表聚类中心数量
group token可以理解为cls token,它想要代表整个图片,为什么多个token而不像cls token就一个,是因为分割有很多目标类别
transformer layers将patch embedding与group tokens联系起来
经过一些transformer之后,认为group token学得差不多了,聚类中心也学得差不多了,这时候利用grouping block将group token尝试合并成更大的group,学到一些更有语义的信息;另一个好处是它变相的把序列长度降低了
grouping block先利用类似自注意力的方式,计算量一个相似度矩阵,然后用这个相似度矩阵帮助原来的image token做一些聚类中心的分配,从而把image token降维到group token的维度;做聚类中心分配的过程不可导,所以用了gumbel softmax的trick
训练过程通过对比学习的loss,文本经过text encoder得到文本特征,但是图像经过group
token、group merging得到的是一个序列,第一维是聚类中心个数,第二位是深度,为了把序列的特征融合成整个图像的特征,使用平均池化,然后对比学习
背景类通过设置阈值来区分,这是CLIP的的局限性,背景类太抽象了,可以代表很多很多类
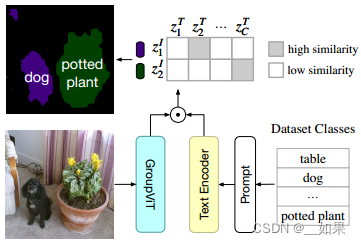
图片喂给GroupViT,文本喂给text encoder,对比学习计算相似度
聚类中心个数是超参数,需要人工设定,作者实验发现8个的效果最好,此时分割最多检测到8类

由图可知,group token确实起了作用
stage1的第五个token代表眼睛,第三十六个token代表四肢,且面积较小,因为此时未经过grouping block,聚类中心多
stage2中明显看到聚类中心减少后,token表示范围增大,且每个token代表不同类别
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









