






在神经网络中,有些层是无状态的,但大多数的层是有状态的,即层的权重。
权重是利用随机梯度下降学到的一个或多个张量,包含在网络的知识。
随机梯度下降法(SGD)主要是计算损失相对于网络参数的梯度(梯度是张量运算的导数),将权重参数沿着梯度的反方向移动,这即是学习的过程,最终是为减少数据损失。
下图所示为沿着一维损失函数曲线的随机梯度下降(一个需要学习的参数)
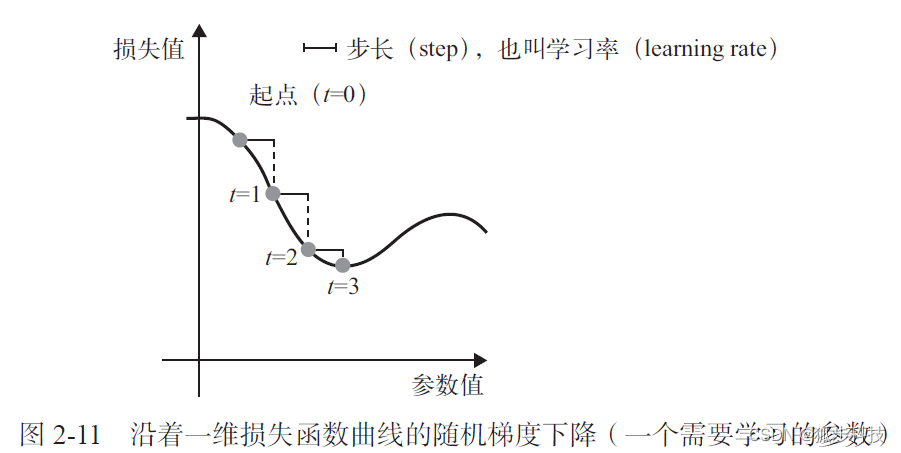
优化器执行的是随机梯度下降的某个变体,决定如何基于损失函数对网络进行更新,是使用损失梯度更新参数的具体方式。
在神经网络中,有些层是无状态的,但大多数的层是有状态的,即层的权重。
权重是利用随机梯度下降学到的一个或多个张量,包含在网络的知识。
随机梯度下降法(SGD)主要是计算损失相对于网络参数的梯度(梯度是张量运算的导数),将权重参数沿着梯度的反方向移动,这即是学习的过程,最终是为减少数据损失。
下图所示为沿着一维损失函数曲线的随机梯度下降(一个需要学习的参数)
优化器执行的是随机梯度下降的某个变体,决定如何基于损失函数对网络进行更新,是使用损失梯度更新参数的具体方式。











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




















 2345
2345





