






一、机器学习
1.1 机器学习简介
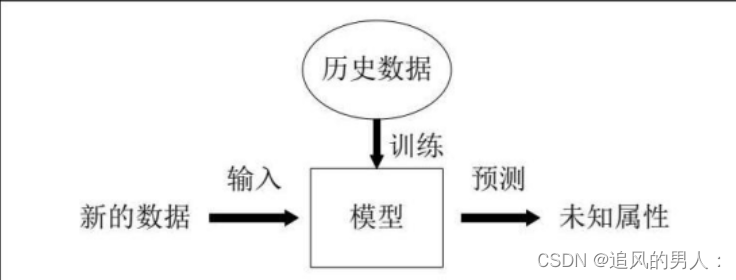
所谓机器学习,通俗的来讲就是让机器拥有学习的能力,从而改善系统自身的性能。所谓学习,就是从数据中进行学习,从数据中产生模型的算法,即学习算法,有了学习算法,只要把经验数据提供给他,他就能基于这些数据产生模型,而模型在面对新的情况时,能够提供相应的判断,进行预测。
1.2 机器学习应用前景
1.数据分析与挖掘
数据挖掘是“识别出巨量数据中有效的、新颖的、潜在有用的、最终可理解的模式的过程”
数据分析则通常被定义为“指用适当的统计方法对收集来的大量第一手资料和第二手资料进行分析,以求最大化地开发数据资料的功能,发挥数据的作用,是为了提取有用信息和形成结论而对数据加以详细研究和概括总结的过程”。
2.模式识别
模式识别研究主要集中在两个方面:一是研究生物体(包括人)是如何感知对象的,属于认识科学的范畴;二是在给定的任务下,如何用计算机实现模式识别的理论和方法,这些是机器学习的长项。
模式识别的应用领域广泛,包括计算机视觉、医学图像分析、光学文字识别、自然语言处理、语音识别、手写识别、生物特征识别、文件分类、搜索引擎等,而这些领域也正是机器学习大展身手的舞台,因此模式识别与机器学习的关系越来越密切。
3.更广阔的领域
研究和应用机器学习的最终目标是全面模仿人类大脑,创造出拥有人类智慧的机器大脑。
1.3机器学习常见的分类
1.监督学习
监督学习是指利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程,也称为监督训练或有教师学习。 训练集就是带标签的数据。
- 分类
- 广义上基于回归方法的分类(如logistic function,softmax regression)
- 基于密度的方法,如KNN(从最近邻的K个样本中选择分类目标数最多的那一类)
- 基于概率统计的方法,如贝叶斯分类器,Naive Bayes Classifier
- 基于树的方法,如决策树,随机森林等
- 其他,如基于最优间隔分类器的SVM
- 分类也有其他的也可能更加合理的方法:如
- 线性分类器(logistic function,softmax classifier,SVM)
- 非线性分类器(如KNN,Naive Bayes,基于树的方法系列等)
- 回归
2.非监督学习
根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题。
常见的无监督学习有聚类(Clustering)和降维(Dimensionality Reduction)两种。在聚类工作中,由于事先不知道数据类别,因此只能通过分析数据样本在特征空间中的分布,如基于密度或基于统计学概率模型,从而将不同数据分开,把相似数据聚为一类。降维是将数据的维度降低,由于数据本身具有庞大的数量和各种属性特征,若对全部数据信息进行分析,则会增加数据训练的负担和存储空间。因此可以通过主成分分析等其他方法,考虑主要因素,舍弃次要因素,从而平衡数据分析的准确度与数据分析的效率。在实际应用中,可以通过一系列的转换将数据的维度降低。
监督学习与非监督学习的区别
(1)监督学习是一种目的明确的训练方式;而非监督学习是没有明确目的的训练方式。
(2)监督学习需要给数据打标签;而非监督学习不需要给数据打标签。
(3)监督学习由于目的明确,因此可以衡量效果;而无监督学习几乎无法衡量效果如
何。
1.4机器学习常用算法
回归算法
回归算法是一种应用极为广泛的数量分析方法。该算法用于分析事物之间的统计关系,侧重考察变量之间的数量变化规律,并通过回归方程的形式描述和反映这种关系,以帮助人们准确把握变量受其他一个或多个变量影响的程度,进而为预测提供科学依据。
回归算法的分类
线性回归(Linear Regression)
逻辑回归(Logistic Regression)
多项式回归(Polynomial Regression)
逐步回归(Step-wise Regression)
岭回归(Ridge Regression)
套索回归(Lasso Regression)
弹性回归(Elastic Net Regression)
聚类算法
聚类就是将相似的事物聚集在一起,将不相似的事物划分到不同类别的过程,是数据挖掘中一种重要的方法。聚类算法的目标是将数据集合分成若干簇,使得同一簇内的数据点相似度尽可能大,而不同簇间的数据点相似度尽可能小。聚类能在未知模式识别问题中,从一堆没有标签的数据中找到其中的关联关系。
1.聚类算法概述
聚类技术是一种无监督学习,是研究样本或指标分类问题的一种统计分析方法。聚类与分类的区别是其要划分的类是未知的。常用的聚类分析方法有系统聚类法、有序样品聚类法、动态聚类法、模糊聚类法、图论聚类法和聚类预报法等。
2.聚类算法的分类
(1)基于划分的聚类算法
K-Means 算法
K-Medoids 算法
CLARANS 算法
(2)基于层次的聚类算法
BIRCH 算法
CURE 算法
Chameleon 算法
(3)基于密度的聚类算法
DBSCAN 算法
OPTICS 算法
DENCLUE 算法


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









