







由于程序的转移概率不会很低,数据分布的离散性较大,所以单纯依靠并行主存系统提高主存系统的频宽是有限的。这就必须从系统结构上进行改进,即采用存储体系。
通常将存储系统分为“Cache-主存”层次和“主存-辅存”层次。
1.概述
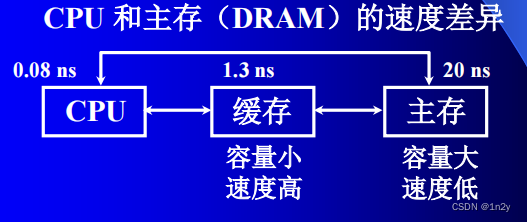
如何避免 CPU“空等”现象?
为什么 Cache 命中率可以高达 99%?
程序访问的局部性原理
-
空间局部性
在最近的未来要用到的信息(指令和数据),很可能与现在正在使用的信息在存储空间上是邻近的。因为指令通常是顺序存放、 顺序执行的,数据一般也是以向量、数组等形式簇聚地存储在一起的。
-
时间局部性
在最近的未来要用到的信息,很可能是现在正在使用的信息;因为程序中存在循环。
-
原因: 数据(数组、结构体)在内存中顺序存放 ;程序各指令的顺序存放,循环体、函数体
高速缓冲技术就是利用局部性原理,把程序中正在使用的部分数据存放在一个高速的、容量较小的Cache 中,使CPU的访存操作大多数针对Cache进行,从而提高程序的执行速度。
体会 Cache 的作用:
void copyij(int d[][1024], int s[][1024])
{
int i, j;
for (i = 0; i < 1024; i++)
for (j = 0; j < 1024; j++)
d[i][j] = s[i][j];
}
void copyji(int d[][1024], int s[][1024])
{
int i, j;
for (j = 0; j < 1024; j++)
for (i = 0; i < 1024; i++)
d[i][j] = s[i][j];
}#include <time.h>
int as[1024][1024], ad[1024][1024];
int main()
{
int i;
clock_t t0; // long (long) int型
for (i = 0; i < 1024*1024; i++)
as[i/1024][i%1024] = i;
t0 = clock(); // clock()返回程序执行至此
copyij(ad, as); // 所花费的CPU时钟数
printf("%ld\n", clock()-t0);
}
假定数组元素按行优先方式存储,对于上面的两个函数:
1)对于数组a的访问,哪个空间局部性更好?哪个时间局部性更好?
A程序的访问数组a的顺序为a[0][0], a[0][1]…, a[0][N-1];a[1][0], a[1][1]…;访问顺序与存放顺序一致,空间局部性好。
B程序的访问数组a的顺序为a[0][0], a[1][0]…, a[M-1][0];a[0][1], a[1][1]…;访问顺序与存放顺序不一致,每次访问都要跳过N个数组元素,即4N个字节,若主存与Cache的交换单位小于4N,则每次访问都要重装Cache,因而
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 928
928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









