







1. CopyOnWriteArrayList
我们知道ArrayList以及HashSet,HashMap都是线程不安全的,并发执行的时候会报并发修改异常错误。

使其线程安全的方法有如下几种:
1.使用java.util包下提供的Collections工具类,使其变成一个线程安全的集合类
List<String> list = Collections.synchronizedList(new ArrayList<>());
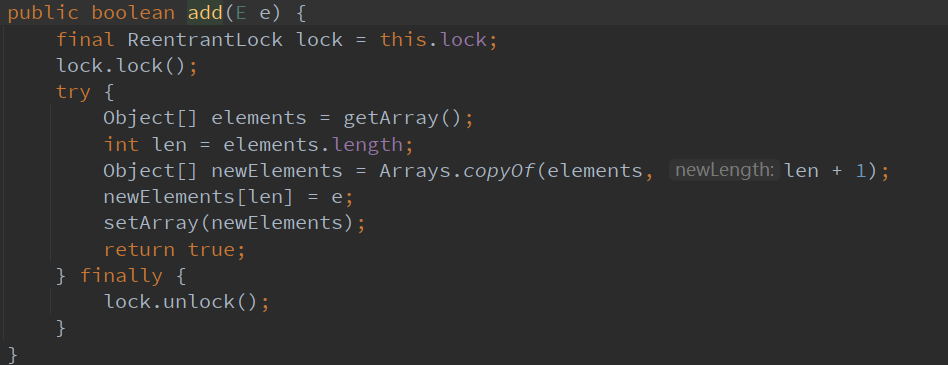
2.使用JUC并发编程包下提供的线程安全的集合类 CopyOnWriteArrayList
CopyOnWriteArrayList 即写入时复制,写入的时候复制了一份,避免了多线程下add覆盖的问题。
List<String> list1 = new CopyOnWriteArrayList<>();
那Vector也是线程安全的,Vector和CopyOnWriteArrayList有什么区别?
使用的锁不同
- Vector的add方法上是用Synchronized同步锁
- CopyOnWriteAyyayList的add方法使用了Lock锁,相比来说后者的细粒度更加容易控制。

2. CopyOnWriteArraySet
HashSet也是线程不安全的,HashSet的底层是HashMap,其底层是new了一个HashMap。
1.使用java.util包下提供的Collections工具类
Set<String> set = Collections.synchronizedSet(new HashSet<>());
使用JUC并发编程包下提供的线程安全的集合类 CopyOnWriteArraySet
Set<String> set = new CopyOnWriteArraySet<>();
3. ConcurrentHashMap
HashMap也是线程不安全的,其多线程下也会发生并发修改异常
1.使用java.util包下提供的Collections工具类
Map<String,Object> map = new HashMap<>();
Map<String, Object> objectMap = Collections.synchronizedMap(map);
2.使用JUC报下提供的线程安全ConcurrentHashMap类
Map<String,Object> map = new ConcurrentHashMap<>();
4. Callable
与Runnable类似,不同的是Runnable并不能返回结果和抛出异常,这两点Callable都可以做到,但是如何将Thread与Callable关联起来呢?因为新创建一个线程,其参数里并不能传入Callable,只能传入Runnable,那该如何解决?
通过观察源码,我们会发现存在一个FutureTask类型可以充当中间人角色,一方面创建一个FutureTask对象的时候,Callable可以作为一个参数传进来。另一方面其间接实现了Runnable接口,就可以作为Thread的参数传入。而且通过FutureTask的get方法会得到返回值。
![]()
![]()
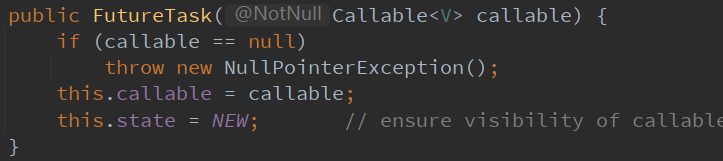
// 创建一个 FutureTask 对象
FutureTask futureTask = new FutureTask(new Callable() {
@Override
public Object call() throws Exception {
return "123";
}
});
// 开启线程,传入的FutureTask对象实际上还是一个Runnable接口实现的类
new Thread(futureTask).start();
// 通过 FutureTask 对象的get方法获取Callable接口的返回值
Object ret = futureTask.get();5. CountDownLatch
实现线程间的计数等待,减法计数器,简单来说就是人走完了再关门。
其主要有两个方法:
countDownLatch. countDown() 计数器减1
countDownLatch.await() 计数器非0是阻塞等待,计数器为0时继续执行
private static void demo1() throws InterruptedException {
// 创建一个计数器
CountDownLatch count = new CountDownLatch(10);
for (int i = 1; i <= 10; i++) {
new Thread(() -> {
System.out.println("线程"+Thread.currentThread().getName()+"执行完毕!");
count.countDown(); // 计数器减1
},String.valueOf(i)).start();
}
count.await(); // 阻塞等待,直到计数器为0,才向下执行
System.out.println("全部执行关闭!");
}
6. CyclicBarrier
实现线程间的计数等待,对线程计数,加法计数器,简单来说就是人来齐了再开饭 。
其主要有两个方法:
cyclicBarrier.await(); 也是阻塞等待,等待计数线程达到后,解除阻塞。
private static void demo2() {
// 创建一个加法计数器,对线程计数,当计数为0时,执行后面的Runnable的代码
CyclicBarrier cyclicBarrier = new CyclicBarrier(5,() -> System.out.println("人到齐了"));
// 创建五个线程分别模拟五个客人
for (int i = 1; i <= 5; i++) {
// 匿名内部类调用外部变量,该变量必须被final修饰
int tmp = i;
new Thread(() -> {
System.out.println("客人"+Thread.currentThread().getName()+"第"+tmp+"个到了!");
try {
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
},String.valueOf(i)).start();
}
}
如上,我在创建CyclicBarrier对象的时候,参数中传入了5,即5个线程,后面的lambda表达式就是Runnable接口,意思就是等待执行完五个线程后,后面的run方法才开始执行。cyclicBarrier.await()方法就体现在这五个线程都执行完了,才会执行Runnable接口中System.out.println("人到齐了") 语句。如果执行的线程数少于传入的参数,那么就会一直阻塞等待。
7. Semaphore信号量
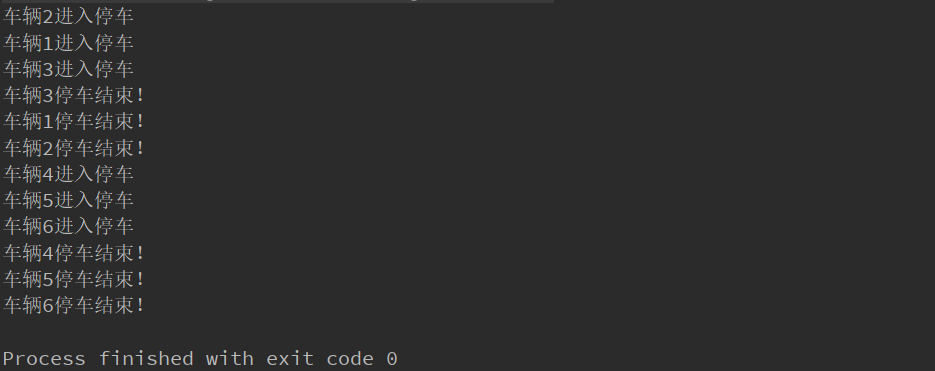
在有限的情况下保持秩序,比如我只有3个停车位,6辆车都需要停车,那么在信号量下就会先停三辆车,没抢到车位的车在人家停的时候只能等待,不能抢。等有空位了,才能去停车。比如说限流的时候可以用。
其主要有两个方法:
semaphore.acquire() 获得
semaphore.release() 释放
private static void demo3() {
// 创建信号量 , 传入参数为线程数量,一次性只能操作该数量的线程,其他线程则等待
Semaphore semaphore = new Semaphore(3);
// 模拟6辆车停车
for (int i = 1; i <= 6; i++) {
new Thread(() -> {
try {
// 获得
semaphore.acquire();
System.out.println("车辆"+Thread.currentThread().getName()+"进入停车");
// 假设每辆车停2秒
TimeUnit.SECONDS.sleep(2);
System.out.println("车辆"+Thread.currentThread().getName()+"停车结束!");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 释放
semaphore.release();
}
},String.valueOf(i)).start();
}
}
8. ReentrantLock
ReentrantLock是Lock锁接口下实现的一个类
Lock lock = new ReentrantLock(); 创建一个ReentrantLock锁
lock.lock(); // 加锁
lock.unlock(); // 释放锁
9. ReadWriteLock读写锁
顾名思义,读写锁,ReadWriteLock是一个接口,没有继承自其它接口。
// 创建读写锁
ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
readWriteLock.readLock().lock(); // 读锁加锁 读锁规定可以有多个线程同时执行
readWriteLock.readLock().unlock(); // 读锁释放锁
readWriteLock.writeLock().lock(); // 写锁加锁 写锁规定只能有一个线程执行
readWriteLock.writeLock().unlock(); // 写锁释放锁
ReadWriteLock与ReentrantLock锁与Synchronized锁的区别?
首先ReadWriteLock(读写锁)是一个(顶级)接口,其没有继承任何接口,而ReentrantLock是一个实现类,其实现了Lock接口。synchronized是一个修饰关键词。相比于synchronized而言,其他两个锁的细粒度更加小,synchronized锁可以修饰普通方法,实则加锁的对象是调用者,即调用的对象。也可以修饰静态变量,实则加锁的对象是类对象,全局唯一。
ReadWriteLock的特殊之处在于规定添加读锁可以多个线程同时执行,而写锁则是只能有一个线程执行。更加细粒度的控制。所以这种读锁相当于独占锁,写锁相当于共享锁。
10. BlockingQueue 阻塞队列
BlockingQueue 阻塞队列,首先它是一个队列,先入先出,当队列满的的时候进行入队列操作或者当队列空的时候出队列操作。不同的方法会有不同的结果。
BlockingQueue 是一个接口,其继承了queue接口。其实现类有ArrayBlockingQueue(利用数组实现),LinkedBlockingQueue(利用链表实现),PriorityBlockingQueue(优先级队列,底层数据结构是堆),SynchronousQueue等类。
其可以用来实现生产者消费者模型:
private static int foodNumber = 0;
private static void demo18() throws InterruptedException {
// 生产者消费者模型
// 创建一个容量为1000的阻塞队列
BlockingQueue<Integer> blockingQueue = new ArrayBlockingQueue<>(1000);
// 生产者
Runnable producer = new Runnable() {
@Override
public void run() {
while (true) {
try {
blockingQueue.put(++foodNumber);
System.out.println(Thread.currentThread().getName()+"生产了第"+foodNumber+"个");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
// 消费者
Runnable consumer = new Runnable() {
@Override
public void run() {
while (true) {
try {
Integer ret = blockingQueue.take();
System.out.println(Thread.currentThread().getName()+"生产了第"+ret+"个");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
// 创建线程并启动
new Thread(producer,"生产者").start();
Thread.sleep(1000);
new Thread(consumer,"消费者").start();
}
10.1 ArrayBlockingQueue,LinkedBlockingQueue
ArrayBlockingQueue是用数组实现的阻塞队列 ,LinkedBlockingQueue是使用链表实现的阻塞队列。
如下有四种常用的api,即对于空队列或者满队列进行操作时的四种不同处理结果。可以根据实际需要来选择用哪个。
| 方式 | 抛出异常 | 不抛异常,返回null | 阻塞等待 | 超时等待 |
| 添加 | add | offer | put | offer(...) |
| 移除 | remove | poll | take | poll(..) |
| 查看队首元素 | element | peek | - | - |
10.2 PriorityBlockingQueue 优先级阻塞队列
优先级阻塞队列是有序的,可以自己根据某一数据进行排序,数据是按照大根堆小根堆排列的。
实现一个容量为4的升序的优先级阻塞队列:
private static void demo15() throws InterruptedException {
PriorityBlockingQueue<String> priorityQueue =
new PriorityBlockingQueue<>(4,(o1,o2) -> o1.compareTo(o2));
priorityQueue.put("a");
priorityQueue.put("d");
priorityQueue.put("b");
priorityQueue.put("f");
System.out.println(priorityQueue.take());
System.out.println(priorityQueue.take());
System.out.println(priorityQueue.take());
System.out.println(priorityQueue.take());
}
10.3 SynchronousQueue 同步队列
该队列是一个容量为 0 的队列,所以它不存储任何元素。也就是说每当进行 put 入队列操作时,都要等待 take 出队列操作。反过来,每一次出队列操作时,都要等待入队列操作。
11. 线程池
由于线程频繁地被创建和销毁也会浪费CPU资源,于是人们想出使用线程池解决,即提前创建好一些线程,使用的时候不需要创建,而是直接使用线程池中已经创建好的线程,使用完也不会急着销毁,而是归还给线程池,通过线程池对多个线程集中管理,集中创建与销毁。从而提高cpu的效率。并且线程与任务分离,提升系统响应速度。
总结使用线程池的优点有以下几种:
- 对多个线程集中管理,控制线程并发数量
- 线程与任务分离,提高线程的可重用性
- 多个线程被集中创建与销毁,提升系统响应速度
线程池有两种创建方式:
第一种通过 Executors 创建
三大方法
1.创建一个单线程
ExecutorService thread = Executors.newSingleThreadExecutor();
缺点:其请求队列长度为 Integer.MAX_VALUE,就有可能会堆积大量的请求,造成OOM。

2.创建固定线程数的线程池
ExecutorService thread = Executors.newFixedThreadPool(6);
缺点:其请求队列长度也为 Integer.MAX_VALUE,就有可能会堆积大量的请求,也造成OOM。
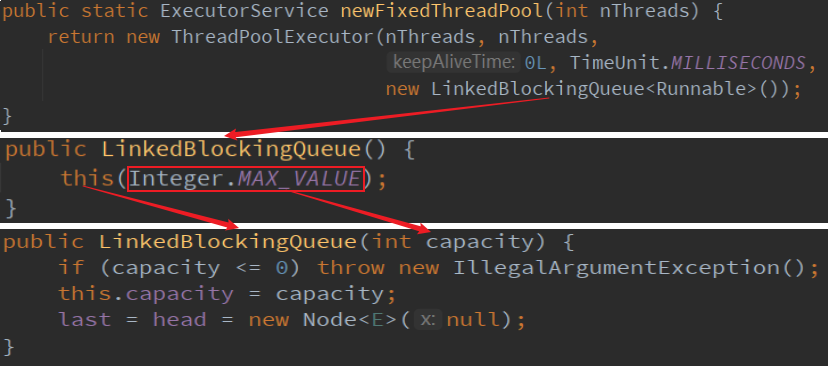
3.创建一个无限大线程数的线程池,容易造成OOM
ExecutorService thread = Executors.newCachedThreadPool();
缺点:其线程池最大线程数为 Integer.MAX_VALUE,就有可能那会创建大量的线程,造成OOM。

4.启动线程池,有两种方法
- 无返回值的任务使用 thread.execute() 方法,对应接口就是Runnable
- 有返回值的任务使用 thread.submit() 方法,对应接口就是Callable
- 关闭线程池,使用调用 shutdown() 方法,并且线程池会在执行完正在执行的任务和工作队列中等待的任务后才彻底关闭。调用 shutdown() 方法后如果还有新的任务被提交,线程池则会根据拒绝策略直接拒绝后续新提交的任务。
// 启动线程池,提交任务 thread.execute(new Runnable() { @Override public void run() { System.out.println("hello world"); } }); thread.execute(() -> System.out.println("hello world"));thread.submit(); // 关闭线程池
上面的创建方式通过源码观察发现,本质上还是属于第二种由ThreadPoolExecutor方式创建。并且在阿里巴巴Java开发手册中也强调了建议使用第二种ThreadPoolExecutor创建方式。
第二种通过ThreadPoolExecutor创建,首先来看创建ThreadPoolExecutor的七大参数:
七大参数

首先执行核心线程,当阻塞队列中的请求满了后,就会执行最大线程数,然后最大线程数都在执行且阻塞队列又满了,就会进行拒绝策略。当请求少了,线程空闲下来,超过指定时间就会释放。
拒绝策略就是当线程池最大线程这些数量都在工作(满了),且阻塞队列中请求已经占满的情况下还有请求进来,就会执行拒绝策略。
四种拒绝策略
1. 默认的拒绝策略,工作队列满了还有请求就会抛出异常
ThreadPoolExecutor.AbortPolicy()
2. 哪里来的,在那里执行
ThreadPoolExecutor.CallerRunsPolicy()
3. 工作队列满了,还有请求,就会丢掉请求任务,不会抛出异常,直接忽略请求,不处理
ThreadPoolExecutor.DiscardPolicy()
4. 代替队列中最老的请求任务,代替它的位置进入队列里
ThreadPoolExecutor.DiscardOldestPolicy()
创建一个线程池
private static void demo() {
// 使用 ThreadPoolExecutor 创建线程池
ExecutorService executorService = new ThreadPoolExecutor(
3, // 核心线程数为3
5, // 最大线程数为5
5, // 多余的线程存活时间
TimeUnit.SECONDS, // 多余的线程存活时间单位
new LinkedBlockingDeque<>(3), // 参数3即队列的容量为3
Executors.defaultThreadFactory(), //默认的线程工厂
new ThreadPoolExecutor.AbortPolicy() // 使用的第一种抛出异常的拒绝策略
);
for (int i = 1; i <= 8; i++) {
// execute方法执行线程
executorService.execute(() -> {
System.out.println(Thread.currentThread().getName()+"正在执行!");
});
}
// 关闭线程池
executorService.shutdown();
}如何合理的设置线程池最大线程数
目的还是为了使CPU的效率最高。关键看你的程序是CPU密集型还是IO密集型,CPU密集型是指程序中含有大量的逻辑元素与算术运算。IO密集型是指打开关闭文件等资源,会造成阻塞。若是CPU密集型,则设置的最大线程数应等于虚拟处理器数,比如一个系统的最大线程数是16,那就设置最大线程数为16。若是IO密集型,因为IO操作会造成阻塞,则至少得空出一条线程执行其他操作,可以将最大线程数设置为15或小于15。即首先要判断你程序中执行IO的线程有多少个,最大线程数至少比他小1。
获取本机处理器数(线程数)
由于不同服务器之间CPU不同,所以一般使用代码获取本机处理器数,而不是写死。
int i = Runtime.getRuntime().availableProcessors(); 返回Java虚拟机可用的处理器数
12. ForkJoin 分支合并
并行执行任务时使用,为提高效率,主要用于大数据,是把一个大任务拆分成多个小任务。多个小任务并发执行,执行完后将结果合并,效率更高。
特点:工作窃取
举个例子,假如有两个线程A,B都在执行各自队列中的任务,当A已经执行完如果B线程队列任务中还有任务,就会去B的队列中"窃取"一个任务来执行。原因就是ForkJoin中的队列是一个双端队列。两头都可以取任务。
13. Volatile
Volatile是Java虚拟机提供的轻量级的同步机制,是一个关键词,可以修饰变量。
Volatile有三大特点:
- 内存可见性
- 不保证原子性
- 有序性(禁止指令重排序)
内存可见与JMM(Java内存模型)有关,在多线程中,每个线程都有自己的工作内存,多个线程共用一个主内存。当多个线程共同修改一个共享变量时,都需要先将变量从主内存拷贝到自己的工作内存中,在工作内存中修改变量后,再修改主内存中的变量。如果不使用Volatile,就会造成内存不可见。
此外,Volatile是不能保证原子性的,要想保证原子性,可以加锁(Synchronized或Lock),还可以不加锁,使用JUC下提供的atomic(原子)类,其底层使用了CAS。
比如i++操作,就不是原子性操作,通过 javap -c 反编译操作,可以看出i++在底层是需要分三步的。
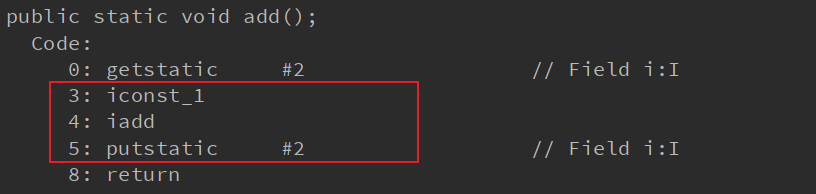
14.atomic 原子类的包
是JUC并发编程包下提供的原子类的包,其中包含许多可替换的原子性的基本或引用数据类型。

15. 指令重排序
指令重排序是指程序在执行的时候,为了提高效率,编译器就会优化重排,指令重排序依据的是数据之间的依赖性,两条语句之间没有依赖,就可以重排序的。可以使用Volatile关键字禁止指令重排序。
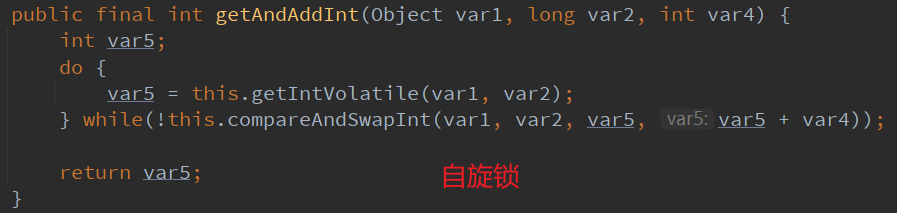
16. CAS 原子指令 自旋锁
CAS是CPU的一条指令,是一种乐观锁,自旋锁,是通过比较内存值与预期值是否匹配,如果匹配,就更新值,如果不匹配,则不做任何操作,继续自旋重试。多个线程同时执行一个CSA,只有一个会成功。
Java中有一个Unsafe类提供的 compareAndSet() 方法的底层实现即为CPU指令CAS。
上面的atomic原子类包中就用到了Unsafe类。

public class CSADemo {
public static void main(String[] args) {
AtomicInteger atomicInteger = new AtomicInteger(1024);
//第一个参数期望值,第二个参数更新值
System.out.println(atomicInteger.compareAndSet(1024, 2049));
System.out.println(atomicInteger);
System.out.println(atomicInteger.compareAndSet(1024, 4399));
System.out.println(atomicInteger);
}
}
ABA问题
ABA 问题是指在 CAS 操作时,其他线程将变量值 A 改为了 B,但是又被改回了 A,等到本线程使用期望值 A 与当前变量进行比较时,发现变量 A 没有变,于是 CAS 就将 A 值进行了交换操作,但是实际上该值已经被其他线程改变过。
举个代码例子:
public class CSADemo {
public static void main(String[] args) {
// 假设我要将 1024 改为 4399
AtomicInteger atomicInteger = new AtomicInteger(1024);
// 假设中间插进来一个线程,改成2049后又给改回来
atomicInteger.compareAndSet(1024, 2049);
atomicInteger.compareAndSet(2049,1024);
// 执行修改目标的线程
atomicInteger.compareAndSet(1024, 4399);
System.out.println(atomicInteger);
}
}
通过结果发现,修改成功,解决这种问题,一个办法是加版本号,将ABA问题变成1A-2B-3A。使用 AtomicStampedReference类 解决。
public class CSADemo {
public static void main(String[] args) {
// 模拟一个线程将 49 修改为 59 时其他线程也修改,初始版本号为1,
AtomicStampedReference<Integer> stampedReference = new AtomicStampedReference<>(49,1);
// 插入者
new Thread(() -> {
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
stampedReference.compareAndSet(49,100,
stampedReference.getStamp(), stampedReference.getStamp()+1);
System.out.println("插入一个线程进行修改,修改结果:"+stampedReference.getReference()+" 版本号"+stampedReference.getStamp());
stampedReference.compareAndSet(100,49,
stampedReference.getStamp(), stampedReference.getStamp()+1);
System.out.println("插入一个线程进行修改,修改结果:"+stampedReference.getReference()+" 版本号"+stampedReference.getStamp());
}).start();
// 执行者
new Thread(() -> {
int stamp = stampedReference.getStamp();
System.out.println("期望版本号是"+stamp);
try {
// 模拟延时,让上面线程先执行,放大问题
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("修改结果:"+stampedReference.compareAndSet(49, 59, stamp, stamp + 1));
System.out.println("实际版本号是"+stampedReference.getStamp());
}).start();
}
}
















 292
292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











