






声明
本程序仅供交流学习使用,请勿用作商用,他人使用本程序造成的一切后果需自行承担
程序用意
秉着“懒人程序使世界进步”的想法
对石墨文档进行了一些“核锂”的“研究”
顺便一提 本文内容可用于大多数编程语言,不仅限于python
使用代码进行表单填写
获取石墨表单API
(需注册一个石墨文档账号)
首先要知道,石墨文档是没有API文档的,但是,这并不意味着石墨文档不使用API
经过抓包,填写表单的API是"https://shimo.im/api/newforms/forms/表单/submit"
然后 我创建了一个表单用于测试 每种题型都添加了一个
https://shimo.im/forms/0l3NVa6NRQhL9l3R/fill
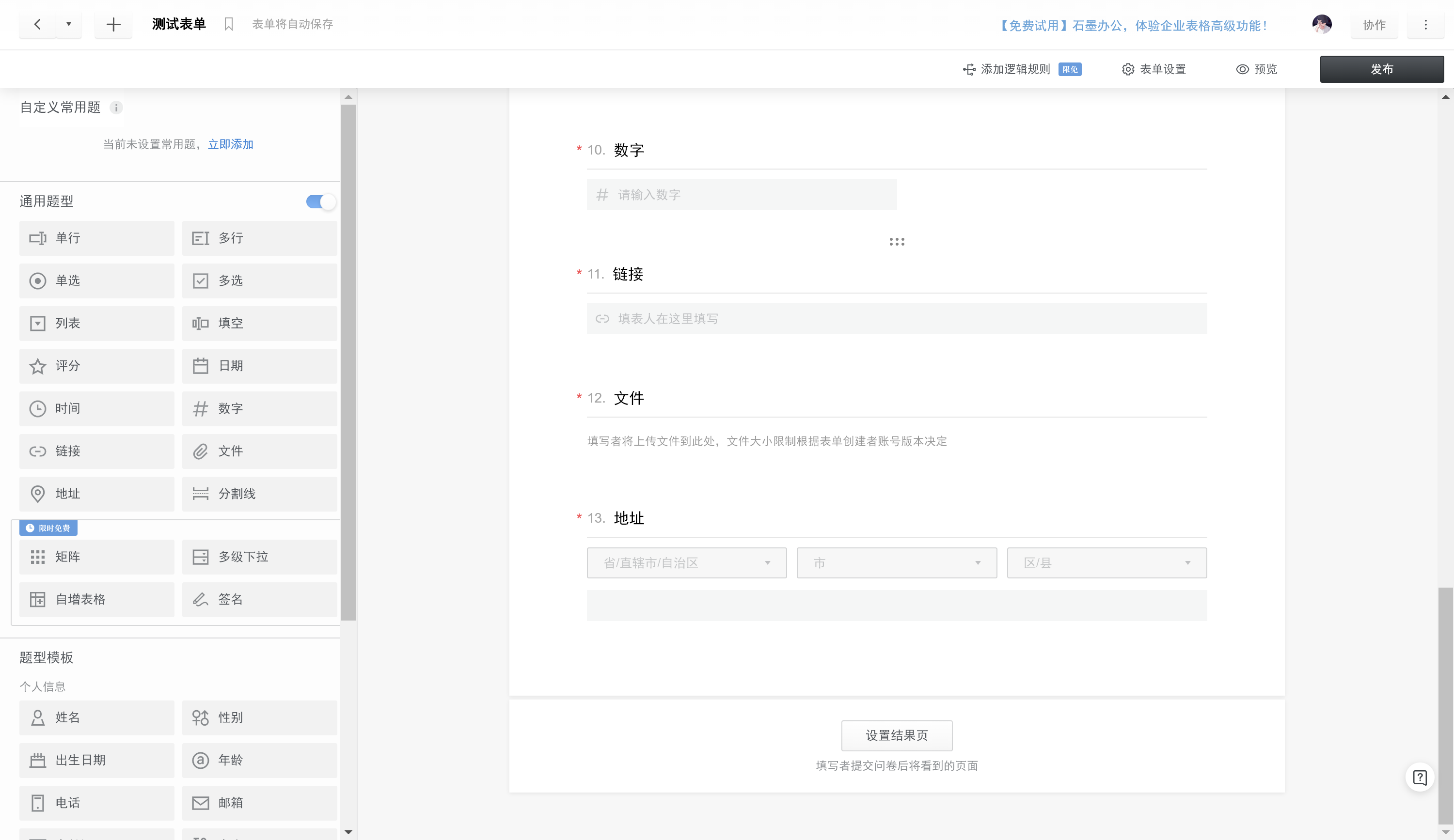
好的 继续
填个表查一下格式
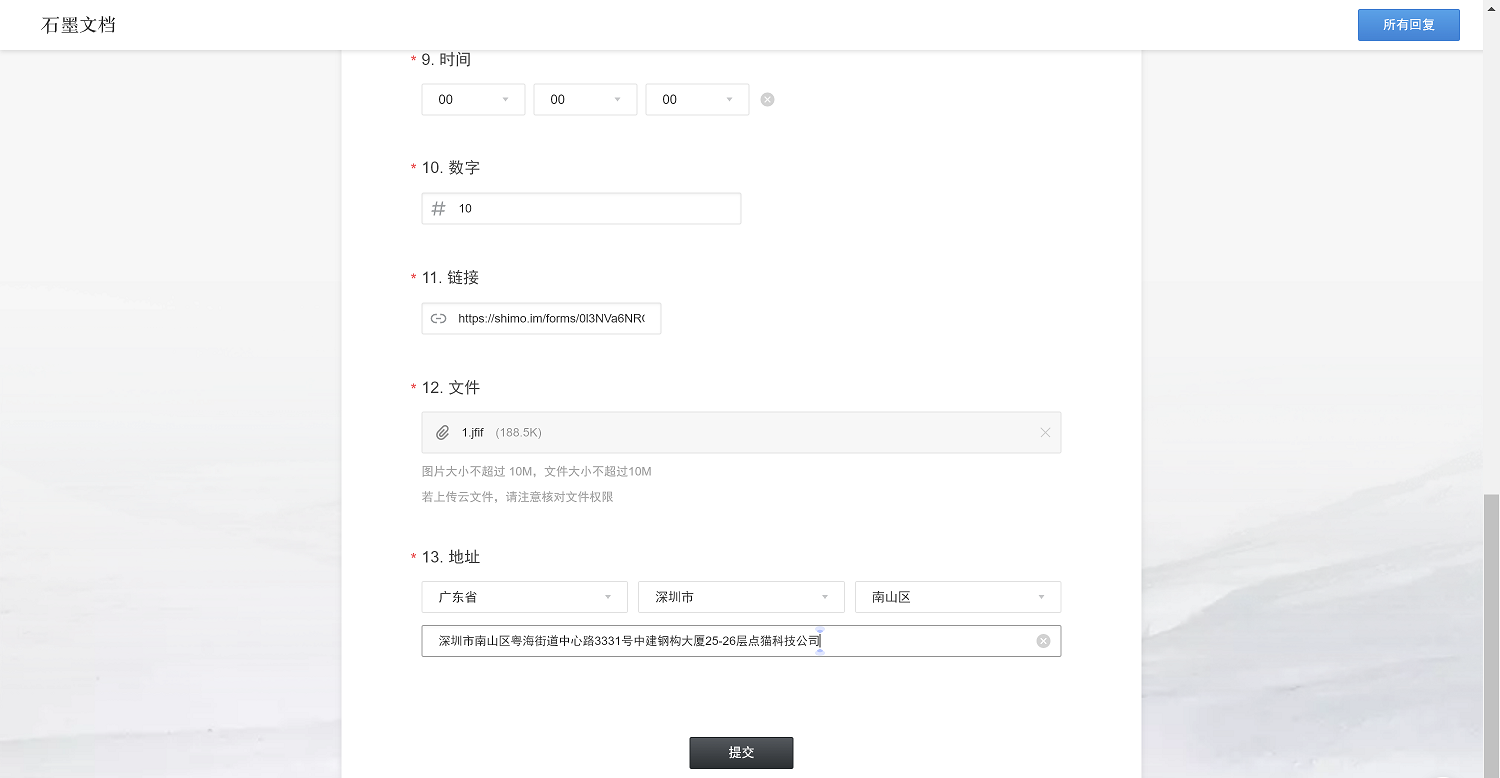
以下是对应格式
{
"formRev": 1,
"userFinger": ,#用户id 必填
"userName": ,#用户名 可以不填
"duration": 242,#填写时间 可以不填
"responseContent": [
{
"type": 0,
"guid": "pJEXfPkW",
"text": {
"content": "单行输入"
}
},
······#在此省略
]
}这样可以整理出以下内容
填表API
内容 | 填表API |
url | https://shimo.im/api/newforms/forms/表单/submit |
访问方法 | post |
数据格式 | json |
发送数据格式如下:
{
"formRev": 1,
"userFinger": 用户id,
"userName": 用户昵称,
"duration": 填写用时,
"responseContent": list(题目回答内容)
}responseContent内容
列表格式,元素为json格式
把一下字典按题目顺序传入列表即可
以下需要修改的内容自己抓包试一下即可
根据不同表单修改guid,value和id即可 实际应用中需要自行修改
类型0:单行输入
数据格式:
{
"type": 0,
"guid": guid,#字符串
"text": {
"content": 回答的内容#字符串
}
}类型1:单选
数据格式:
{
"type": 1,
"guid": guid,#字符串
"choice": {
"type": "normal",
"value": value#字符串
}
}类型2:多选
数据格式:
{
"type": 2,
"guid": ,
"choices": [
{
"type": "normal",
"value":
},
{
"type": "normal",
"value":
}
]
}类似于单选
类型3:列表
数据格式:
{
"type": 3,
"guid": guid,#字符串
"choice": {
"type": "normal",
"value": value#字符串
}
}基本等同于单选
类型4:多行输入
数据格式:
{
"type": 4,
"guid": ,
"text": {
"content": 输入内容
}
},基本等同于单行输入
类型5:评分
数据格式:
{
"type": 5,
"guid": ,
"rate": {
"value": 分值 满分10
}
},value可填1-10或2/4/6/8/10(根据发布者设置)
类型6:日期
数据格式:
{
"type": 6,
"guid": "",
"date": {
"date": ""
}
},日期可用如下字符串格式化
"{}-{}-{}T{}:{}:{}.{}Z".format(year,month,day,hour,minute,second,millisecond)类型7:时间
数据格式:
{
"type": 7,
"guid": "",
"date": {
"date": ""
}
},日期可用如下字符串格式化
"{}-{}-{}T{}:{}:{}.{}Z".format(year,month,day,hour,minute,second,millisecond)与日期基本一致
类型8:输入数字
数据格式:
{
"type": 8,
"guid": "",
"number":
},输入任意数字
类型12:地址
数据格式:
{
"type": 12,
"guid": ,
"address": {
"province": {
"code": "44",
"name": "广东省"
},
"city": {
"code": "4403",
"name": "深圳市"
},
"district": {
"code": "440305",
"name": "南山区"
},
"detail": "深圳市南山区粤海街道中心路3331号中建钢构大厦25-26层点猫科技公司"
}
}code为邮政编码
类型13:文件
{
"type": 13,
"guid": ,
"image": {
"image": {
"type": "",
"name": "1.png",
"size": 193051,
"url": "https://******.png",
"width": 0,
"height": 0
}
}
},type: attachment,shimofile等
size:大小
url: url
······
类型15:链接
{
"type": 15,
"guid": ,
"text": {
"content": "https://shimo.im/forms/0l3NVa6NRQhL9l3R/fill"
}
},content:链接
类型20:填空
{
"type": 20,
"guid": "",
"blanks": [
{
"content": "填空1",
"id":
},
{
"content": "填空2",
"id":
}
]
},现在我们就来开始写代码 完成程序的编写
编写python程序
一些准备工作
下载python3.10.6
安装requests
下载pycharm(个人喜好)
注册石墨账号
再建一个表单 https://shimo.im/forms/8Nk6Mg009xi8Y8qL/fill
简易填表代码
import requests,json
cookie =
userAgent = "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Mobile Safari/537.36"
header = {"User-Agent": userAgent.encode("UTF-8"), "cookie": cookie.encode("UTF-8"), "content-type": "application/json;charset=UTF-8"}
url="https://shimo.im/api/newforms/forms/8Nk6Mg009xi8Y8qL/submit"
data={
"formRev": 1,
"userFinger": ,
"responseContent": [
{
"type": 0,
"guid": "Rt8F9D07",
"text": {
"content": "1"
}
}
]
}
text = json.dumps(data).encode("UTF-8")
w = requests.post(url=url, data=text, headers=header)
print(w.text)图片:

填写成功了
没错 就这么简单
不过 这就是极限了吗?
当然不是
拓展应用
获取表单内容
dic_type={"text":0,"single_choice":1,"multiple_choice":2,"dropdown_list":3,"multiple_text":4,"rate":5,"date":6,"time":7",number":8,"address":12,"image":13,"link":15,"multiple_blank":20,
}
dic_text={0:"单行输入",1:"单选",2:"多选",3:"列表",4:"多行输入",5:"评分",6:"日期",7:"时间",8:"数字",12:"地址",13:"图片",15:"链接",20:"填空",
}
def get_publications(code):
userAgent = "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Mobile Safari/537.36"
header = {"User-Agent": userAgent.encode("UTF-8")}
url=f"https://shimo.im/api/newforms/forms/{code}/publications"
w=requests.get(url,headers=header)
data=json.loads(json.loads(w.text)["publishedContent"])["questions"]
lst=[]
for i in data:
q=i["subject"]
try:
d=i['description']
except:
d=""
t=i["type"]
guid=i["guid"]
print(f"问题{data.index(i) + 1}:{q}")
print(f"问题{data.index(i) + 1}说明:{d}")
print(f"问题{data.index(i) + 1}类型:{dic_text[dic_type[t]]}")
print(f"问题{data.index(i) + 1}guid:{guid}")
print()
lst.append([dic_type[t],q,d,guid])
return lst运行:get_publications("8Nk6Mg009xi8Y8qL")
输出:
问题1:未命名问题
问题1说明:<p>12345</p><p><br></p>
问题1类型:单行输入
问题1guid:Rt8F9D07
问题2:未命名问题
问题2说明:
问题2类型:单选
问题2guid:VLTetnnx
问题3:未命名问题
问题3说明:
问题3类型:多选
问题3guid:wmv9ImDO
······返回:
[[0, '未命名问题', '<p>12345</p><p><br></p>', 'Rt8F9D07'], [1, '未命名问题', '', 'VLTetnnx'], [2, '未命名问题', '', 'wmv9ImDO'], [3, '未命名问题', '', 'U7EH8srx'], [4, '未命名问题', '', 'JQIIsdyk'], [5, '未命名问题', '', 'vQ24BHh3'], [6, '未命名问题', '', 'EdPg4qKQ'], [7, '未命名问题', '', 'VZMo4ZrL'], [8, '未命名问题', '', 'XBKkpfvF'], [12, '未命名问题', '', '6p524ArD'], [13, '未命名问题', '', 'g0Zjq4QK'], [15, '未命名问题', '', '2IjyoJXV'], [20, '未命名问题', '', 'wLCtUR6s']]生成回答
生成单行输入
def generate_text(text,guid):
dic={
"type": 0,
"guid": guid,
"text": {
"content": text
}
}
return dic生成单选
def generate_single_choice(guid,value):
dic={
"type": 1,
"guid": guid,
"choice": {
"type": "normal",
"value": value
}
}
return dic生成多选
def generate_multiple_choice(guid,values):
dic={
"type": 2,
"guid":guid,
"choices":[{"type": "normal","value":i} for i in values]#列表生成式
}
return dic生成列表
def generate_dropdown_list(guid,value):
dic={
"type": 3,
"guid": guid,
"choice": {
"type": "normal",
"value": value
}
}
return dic生成多行输入
def generate_multiple_text(text,guid):
dic={
"type": 4,
"guid": guid,
"text": {
"content": text
}
}
return dic生成评分
def generate_rate(guid,value):
dic={
"type": 5,
"guid":guid,
"rate": {
"value":value
}
}
return dic生成日期&时间
def generate_date(guid,,month,day,hour=0,minute=0,second=0,millisecond=0,year=time.ctime()[-4:]):
date="{}-{}-{}T{}:{}:{}.{}Z".format(year,month,day,hour,minute,second,millisecond)
dic={
"type": 7,
"guid": guid,
"date": {
"date": date
}
}
return dic
generate_time=generate_date生成数字
def generate_number(guid,num):
dic={
"type": 8,
"guid": guid,
"number":num
}
return dic生成地址
def generate_address(guid,code,province,city,district,detail):
dic={
"type": 12,
"guid":guid,
"address":{
"province": {
"code": str(code)[:2],
"name": province
},
"city": {
"code": str(code)[:4],
"name": city
},
"district": {
"code": str(code),
"name": district
},
"detail": detail
},
}
return dic生成图片文件
def generate_image(guid,name,img_url,size=(0,0)):
dic={
"type": 13,
"guid":guid,
"image": {
"image": {
"type": "shimofile",
"name": name,
"size": size[0]*size[1],
"url": img_url,
"width": size[0],
"height": size[1]
}
}
}
return dic生成链接
def generate_link(guid,url):
dic={
"type": 15,
"guid": guid,
"text": {
"content": url
}
}
return dic生成填空
def generate_multiple_blank(guid,ids,texts):
dic={
"type": 20,
"guid": guid,
"blanks": [{"content": texts[i],"id":ids[i]} for i in range(len(ids))]
}
return dic其他编程语言
我不会 谁来帮帮我 在线等 挺急的
写在最后
好的 本期教程由于篇幅的限制就到这里 下一期(如果有)将会封装完整模块进行表单填写(Python)或者试试用其他编程语言()
感谢大家的阅读
谢谢大家

















 1670
1670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











